End-to-End Visual Editing with aGeneratively Pre-Trained Artist(2022 ECCV)
1.通过Generatively Pre-Trained Artist进行端到端的视觉编辑,End-to-End Visual Editing with aGeneratively Pre-Trained Artist。
2.作者:Facebook(meta AI)2022年

3. paper:https://www.robots.ox.ac.uk/~abrown/E2EVE/resources/E2EVE.pdf
github地址:https://github.com/Andrew-Brown1/E2EVE
4.介绍:


将源图像中的区域与指定所需更改的驱动程序图像混合。与之前的工作不同,我们通过端到端学习编辑的条件概率分布来解决这个问题。
5.摘要 Abstract.
回避了以前基于类 GAN 先验的方法的困难,获得了明显更好的编辑,并且效率很高。可以通过对增强过程的直观控制来学习不同的混合效果,而无需对模型架构进行其他更改。
6.method 方法

E2EVE方法 :
( i) VAE预训练: 我们训练两个量化的VAE (一个用于整个图像,一个用于图像补丁),每个都由编码器E和解码器D组成 。
(ii) 训练: 每个数据样本产生一个掩蔽的源图像 (通过操作R) 和驱动图像 (通过掩蔽区域上的随机变换T)。给定这些条件输入,该模型可以自我监督以预测数据样本。
(iii) 推理:当源和驱动程序从不同的图像中独立采样时,E2EVE 会生成编辑后的图像
主要方法函数:
(一)端到端条件生成数据集
我们将问题视为学习条件概率分布 P(x|x, y, R) 的问题之一,然后以源图像 x、驾驶员图像 y 和编辑区域 R 为条件对输出图像 ˆx 进行采样。
在我们的方法中,我们直接学习了最小化标准负对数似然损失的模型p θ (x | x,y,R):

x 是原始图像。 ![]() 是原始图像的RGB输出。
是原始图像的RGB输出。![]() 是驱动图像的RGB输出。R是编码区域的掩码。
是驱动图像的RGB输出。R是编码区域的掩码。
其中 T 是训练四元组的大量集合。一旦学会了,我们就可以直接抽取样本^x∼Pθ∗(^x|x,y,R)。主要挑战是如何获得训练集 T。我们方法的关键是一种以自动方式从 X 构建 T 的方法,无需额外成本。
(二)合成有意义的编辑数据集
我们提出如下构建这样的四元组(图4)。我们对未编辑的集合X中的输出图像进行采样,从而假装后者是编辑操作的结果。然后,我们为这个虚拟编辑定义源和驱动程序图像,如下所示:

其中R是随机图像区域的掩模,⊙ 是元素乘积 (根据需要使用广播),T:是随机图像变换,也称为 “增强”
通过优化方程中的对数似然损失。(1),模型p θ (Χ x | x,y,R) 学习从x (掩蔽区域R) 预测完整图像 ﹐ 而y则保留了一些关于缺失区域的信息。因为 “x” 最初是未经编辑的图像,所以模型学会了预测看起来自然的输出。

(三)两阶段条件自回归图像生成
为了实现条件分布p θ (x | x,y,R),我们使用自回归 (AR) 模型。AR模型已被证明对图像生成具有很高的表现力 [21,60],它们可以优雅地以多个信号为条件,而无需进行架构更改,并且与GANs [62] 不同,它们是模式覆盖的。在实践中,这导致更多样化的生成结果,并能够以更多的变化对数据集进行建模。
7.实验:
评估标准:
(1)自然性(编辑 ^x 看起来像来自先前 P(x) 的样本);
(2) 局部性(x 在编辑区域 R 之外接近 x 尽管需要一定量的松弛才能让编辑自然地融入其中);
(3) 忠实度(x 在编辑区域 R 内与 y 相似)。
采用标准 FID 度量来衡量自然度
数据集:我们在三个数据集上进行了实验:(1)私有 Dresses-7m 数据集,包含 700 万张主要描绘穿着连衣裙的女性的图像; (2) 包含 300 万张卧室图像的 LSUN 卧室 [85]; (3) FFHQ [38],包含 70K 对齐的面脸。
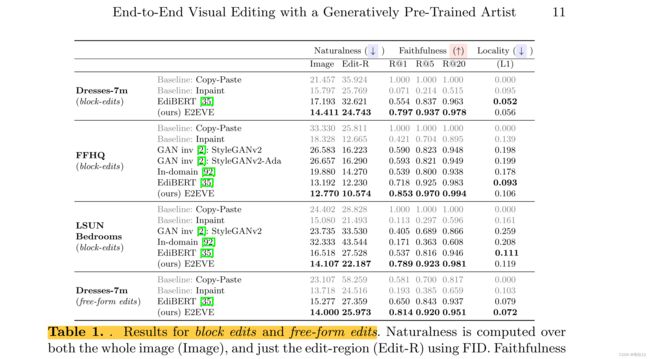
实验结果。

8.Conclusions, Limitations and Future work(结论和局限性和未来工作)
我们介绍了E2EVE,一种用于有针对性的视觉图像编辑的新方法。关键创新是仅基于未标记的自然图像集合来自我监督模型端到端的有效方法。使用此功能,我们可以训练一个有条件的图像生成器网络,该网络可以很好地响应各种用户输入,尽管无需人工监督,但在质量和数量上都大大超过了先前的工作。
局限性仍然存在: 我们的数据生成技术可能难以扩展到基于文本的编辑,并且该模型提出的某些编辑是不合理的 (请参阅sup. mat。),因为该模型缺乏对图像语义内容的充分理解。此外,由于我们的模型是无监督的和数据驱动的,它可能包含令人惊讶的不必要的偏差。
下一步包括将E2EVE扩展到图像之外的3D场景中的空间编辑和视频中的时空编辑