百度千言-中文文本相似度实战
文章目录
- 百度千言-中文文本相似度实战
-
-
- 任务1:报名比赛,下载比赛数据集并完成读取
- 任务2:对句子对提取TFIDF以及统计特征,训练和预测
- 任务3:加载中文词向量,自己训练中文词向量
- 任务4:使用中文词向量完成mean/max/sif句子编码
- 任务5:搭建SiamCNN/LSTM模型,训练和预测
- 任务6:搭建InferSent模型,训练和预测
-
- 6.1 模型搭建与训练
- 6.2 使用不同交叉方法训练结果
- 任务7:搭建ESIM模型,训练和预测
-
- 7.1 ESIM模型搭建与训练
- 7.2 结果分析
- 任务8:使用BERT或ERNIE完成NSP任务
- 任务9:Bert-flow、Bert-white、SimCSE
-
百度千言-中文文本相似度实战
任务1:报名比赛,下载比赛数据集并完成读取
- 步骤1 :登录&报名比赛:https://aistudio.baidu.com/aistudio/competition/detail/45/0/task-definition
已报名 - 步骤2 :下载比赛数据集
- 步骤3 :使用Pandas完成数据读取。
数据读取:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings('ignore')
def read_tsv(input_file,columns):
with open(input_file,"r",encoding="utf-8") as file:
lines = []
count = 1
for line in file:
if len(line.strip().split("\t")) != 1:
lines.append([count]+line.strip().split("\t"))
count += 1
df = pd.DataFrame(lines)
df.columns = columns
return df
bq_train = read_tsv('data/bq_corpus/train.tsv',['index','sentences1','sentences2','label'])
bq_train.head()

任务2:对句子对提取TFIDF以及统计特征,训练和预测
参考代码:kaggle参考案例
- 步骤1 :对句子对(句子A和句子B统计)如下特征:
- 句子A包含的字符个数、句子B包含的字符个数
- 句子A与句子B的编辑距离
- 句子A与句子B共有单词的个数
- 句子A与句子B共有字符的个数
- 句子A与句子B共有单词的个数 / 句子A字符个数
- 句子A与句子B共有单词的个数 / 句子B字符个数
文本预处理:
- 1、文本中的表情符号去除
- 2、大写字母转化为小写字母
- 3、仅保留中文(这个未尝试)
#大写字母转为小写字母
def upper2lower(sentence):
new_sentence=sentence.lower()
return new_sentence
bq_train['chinese_sentences1'] = bq_train['sentences1'].apply(upper2lower)
bq_train['chinese_sentences2'] = bq_train['sentences2'].apply(upper2lower)
#去除文本中的表情字符(只保留中英文和数字)
import re
def clear_character(sentence):
pattern1= '\[.*?\]'
pattern2 = re.compile('[^\u4e00-\u9fa5^a-z^A-Z^0-9]')
line1=re.sub(pattern1,'',sentence)
line2=re.sub(pattern2,'',line1)
new_sentence=''.join(line2.split()) #去除空白
return new_sentence
bq_train['chinese_sentences1'] = bq_train['chinese_sentences1'].apply(clear_character)
bq_train['chinese_sentences2'] = bq_train['chinese_sentences2'].apply(clear_character)
#统计句子长度分布:
sentenses1 = pd.Series(bq_train['chinese_sentences1'].tolist()).astype(str)
sentences2 = pd.Series(bq_train['chinese_sentences2'].tolist()).astype(str)
dist1 = sentenses1.apply(len)
dist2 = sentences2.apply(len)
plt.figure(figsize=(15,10))
plt.hist(dist1, bins=200, range=[0,200], color='red', label='sentences1')
plt.hist(dist2, bins=200, range=[0,200], color='blue', label='sentences2')
plt.title('Sentences length', fontsize=15)
plt.legend()
plt.xlabel('Number of characters', fontsize=15)
plt.ylabel('Frequency', fontsize=15)
plt.show()
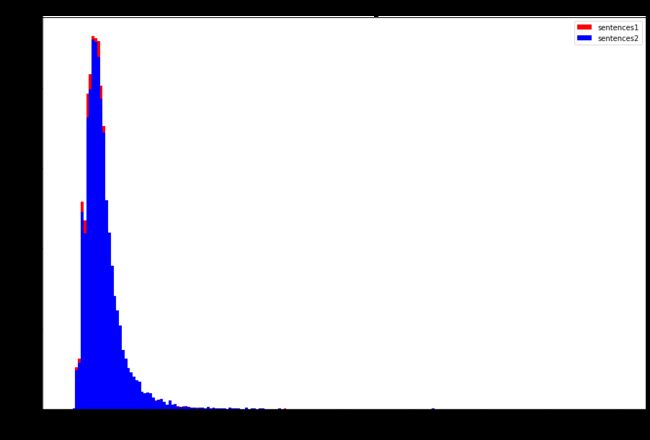
统计句子A和句子B的符号数量:
bq_train['sentences1_length'], bq_train['sentences2_length'] = pd.DataFrame(dist1), pd.DataFrame(dist2)
句子A与句子B的编辑距离
# Compute edit dstance
import distance
def edit_distance(s1, s2):
return distance.levenshtein(s1, s2)
bq_train["edit_distance"] = bq_train.apply(lambda x: edit_distance(x["chinese_sentences1"], x["chinese_sentences2"]), axis=1)
plt.hist(bq_train['edit_distance'])
plt.xlabel("Edit distance")
plt.ylabel('Frequency')
plt.title('the Edit Distance of Chinese Sentences 1 and Chinese Sentences2')
plt.show();
#可见,sentence1和sentence2的编辑距离大部分落在1~20之间

句子A与句子B共有单词(word)的个数
句子A和句子B共有字符(char)的个数
#计算共有字符chars/Word
from collections import Counter
#计算两个句子相同在字符个数
def count_sample_char(sentence1, sentence2, WORD=False):
if WORD:
#说明此时输入的是'jieba_sen_{1/2}',要以','拆分成列表,再建词汇表。
sentence1 = sentence1.split(',')
sentence2 = sentence2.split(',')
#构造两个句子的词汇表
vocab1 = Counter(list(sentence1))
vocab2 = Counter(list(sentence2))
samekey_num = 0
#判断keys()有没有相同的
for key in vocab1.keys():
if key in vocab2.keys():
samekey_num += min(vocab1[key], vocab2[key])
else:
continue
return samekey_num
def count_df_char(sentences1, sentences2, WORD=False):
length = sentences1.shape[0]
num_char = []
for i in range(length):
num_char.append(count_sample_char(sentences1[i], sentences2[i], WORD))
return pd.DataFrame(num_char)
bq_train['same_char_num'] = count_df_char(bq_train['chinese_sentences1'], bq_train['chinese_sentences2'])
bq_train['same_word_num'] = count_df_char(bq_train['jieba_sen1'], bq_train['jieba_sen2'], WORD=True)
句子A与句子B共有单词的个数 / 句子A字符个数
句子A与句子B共有单词的个数 / 句子B字符个数
#句子A与句子B共有单词的个数 / 句子A字符个数
#句子A与句子B共有单词的个数 / 句子B字符个数
bq_train['sen1&sen2/sen1'] = bq_train['same_char_num']/bq_train['sentences1_length']
bq_train['sen1&sen2/sen2'] = bq_train['same_char_num']/bq_train['sentences2_length']
数据处理完毕!
- 步骤2 :计算TFIDF,并对句子A和句子B进行特征转换
- 步骤3 :计算句子A与句子B的TFIDF向量的内积距离
#将两个句子转换为tfidf向量,并计算两个tfidf向量内积
from sklearn.feature_extraction.text import TfidfVectorizer
def sentences_tfidf_inner(sentences1, sentences2):
length = sentenses1.shape[0]
tfidf_segment1, tfidf_segment2, inner_sens= [], [], []
for i in range(length):
tfidf_sen12_vector = TfidfVectorizer(analyzer="char").fit_transform([sentences1[i], sentences2[i]]).toarray()
tfidf_segment1.append(tfidf_sen12_vector[0])
tfidf_segment2.append(tfidf_sen12_vector[1])
inner_sens.append(np.inner(tfidf_sen12_vector[0], tfidf_sen12_vector[1]))
return tfidf_segment1, tfidf_segment2, pd.DataFrame(inner_sens)
tfidf_sentences1, tfidf_sentences2, bq_train['sentences_inner']= sentences_tfidf_inner(bq_train['chinese_sentences1'], bq_train['chinese_sentences2'])
- 步骤4 :将上述特征送入分类模型,训练并预测,将结果预测提交到比赛网站。
# 构建lightgbm二分类模型
#在这里尝试使用lightgbm二分类进行训练
import lightgbm as lgb
params_lgb ={
'learning_rate':0.1,
'boosting_type':'gbdt',
'objective':'binary',
'nthread':4,
'metric':'auc',
'max_depth':5,
'num_leaves': 30,
'subsample':0.8, # 数据采样
'colsample_bytree': 0.8, # 特征采样
}
lgb_train = lgb.Dataset(train_bq, train_bq_y)
cv_results = lgb.cv(params_lgb, lgb_train, num_boost_round=200, nfold=5, stratified=False, shuffle=True, metrics='auc', callbacks=[lgb.early_stopping(stopping_rounds=50)], seed=420)
print('best n_estimators:', len(cv_results['auc-mean']))
print('best cv score:', pd.Series(cv_results['auc-mean']).max())
任务3:加载中文词向量,自己训练中文词向量
- 步骤1 :使用jieba对中文句子进行分词
import jieba
#使用jieba进行分词
def segment_sen(sen):
sen_list = []
try:
sen_list = jieba.lcut(sen)
except:
pass
return sen_list
sen1_list = [segment_sen(i) for i in bq_train['chinese_sentences1']]
sen2_list = [segment_sen(i) for i in bq_train['chinese_sentences2']]
- 步骤2 :使用gensim中Word2Vec训练分词后的句子,得到词向量。
from gensim.models import word2vec
model1 = word2vec.Word2Vec(sen1_list, min_count=1)
model2 = word2vec.Word2Vec(sen2_list, min_count=1)
model1.save('word2vec_1.model')
model2.save('word2vec_2.model')
生成词向量:
#将词向量保存为txt文件
def word_dict(model_name, filename):
word_vector_dict = {}
for word in model_name.wv.index_to_key:
word_vector_dict[word] = list(model_name.wv[word])
with open(filename, 'w', encoding='UTF-8') as f:
f.write(str(word_vector_dict))
word_dict(model1, "sentence1_word_vector.txt")
word_dict(model2, "sentence2_word_vector.txt")
任务4:使用中文词向量完成mean/max/sif句子编码
- 步骤1 :单词通过word2vec编码为100维向量,则句子编码为N∗100N∗100的矩阵,N为句子单词个数。
- 步骤2 :将N*100的矩阵进行max-pooling编码,转为100维度。
#将N*100的矩阵进行max-pooling编码,转为100维度。
def build_sentence_vector_max(sentence, size, w2v_model):
sen_vec = np.zeros(size).reshape((1,size))
for word in sentence:
try:
#使用maximum来进行max-pooling
sen_vec = np.maximum(sen_vec, w2v_model.wv[word].reshape((1,size)))
except KeyError:
continue
return sen_vec
- 步骤3 :将N*100的矩阵进行mean-pooling编码,转为100维度。
#对每个句子的所有向量去平均值,来生成一个句子的vector
def build_sentence_vector(sentence, size, w2v_model):
sen_vec = np.zeros(size).reshape((1,size))
count = 0
for word in sentence:
try:
sen_vec += w2v_model.wv[word].reshape((1,size))
count += 1
except KeyError:
continue
if count != 0:
sen_vec = sen_vec/count
return sen_vec
- 步骤4 :将N*100的矩阵与单词的IDF进行矩阵相乘,即按照单词的词频进行加权,进行tfidf-pooling编码,转为100维度。
from nltk.text import TextCollection
from nltk.tokenize import word_tokenize
#构建sentences1和sentences2的语料库corpus1和corpus2
corpus1=TextCollection(sen1_list) #构建语料库
corpus2 = TextCollection(sen2_list)
根据tfidf词频权重对句子进行编码
import math
def build_sentence_vector_tfidf_weight(sentence,size,w2v_model,corpus):
#得到词的权重
tfidf_weight = {}
for word in sentence:
tfidf_weight[word] = corpus.tf_idf(word, sentence)
sen_vec=np.zeros(size).reshape((1,size))
count=0
for word in sentence:
try:
if word in tfidf_weight.keys():
sen_vec+=(np.dot(w2v_model.wv[word],math.exp(tfidf_weight[word]))).reshape((1,size))
count+=1
else:
sen_vec+=w2v_model[word].reshape((1,size))
count+=1
except KeyError:
continue
if count!=0:
sen_vec/=count
return sen_vec
- 步骤5 :学习SIF编码的原理,进行sif编码,转为100维度。
https://github.com/PrincetonML/SIF/blob/master/src/SIF_embedding.py#L30
https://openreview.net/pdf?id=SyK00v5xx
这篇博客是我看SIF论文时记的笔记:【论文阅读】SIF:一种简单却很有效的句子编码方法
SIF编码如下:
from nltk.text import TextCollection
#构建sentences1和sentences2的语料库corpus1和corpus2
corpus1 = TextCollection(sen1_list)
corpus2 = TextCollection(sen2_list)
#得到sif权重
def get_SIF_weight(a, sentences, corpus):
SIF_weight = {}
for sentence in sentences:
for word in sentence:
SIF_weight[word] = a / a + corpus.tf_idf(word, sentence)
return SIF_weight
a = 0.001
SIF_weight1 = get_SIF_weight(a, sen1_list, corpus1)
SIF_weight2 = get_SIF_weight(a, sen2_list, corpus2)
#获得基于SIF改进后的句子向量-->句子列表,返回的由所有句子组成的sentences metrix
import math
def build_sentences_vector_sif_weight(sentences,size,w2v_model,sif_weight):
all_sentences_metrix = np.zeros((1, size))
sen_vec=np.zeros(size).reshape((1,size))
for index, sentence in enumerate(sentences):
count=0
for word in sentence:
try:
if word in sif_weight.keys():
sen_vec+=(np.dot(w2v_model.wv[word],math.exp(sif_weight[word]*0.001))).reshape((1,size))
count+=1
else:
sen_vec+=w2v_model[word].reshape((1,size))
count+=1
except KeyError:
continue
if count!=0:
sen_vec/=count
if index == 0:
all_sentences_metrix = sen_vec
else:
all_sentences_metrix = np.vstack((all_sentences_metrix, sen_vec))
return all_sentences_metrix
import numpy as np
from sklearn.decomposition import TruncatedSVD
def compute_pc(X,npc=1):
"""
Compute the principal components. DO NOT MAKE THE DATA ZERO MEAN!
:param X: X[i,:] is a data point
:param npc: number of principal components to remove
:return: component_[i,:] is the i-th pc
"""
svd = TruncatedSVD(n_components=npc, n_iter=7, random_state=0)
svd.fit(X)
return svd.components_
def remove_pc(X, npc=1):
"""
Remove the projection on the principal components
:param X: X[i,:] is a data point
:param npc: number of principal components to remove
:return: XX[i, :] is the data point after removing its projection
"""
pc = compute_pc(X, npc)
if npc==1:
XX = X - X.dot(pc.transpose()) * pc
else:
XX = X - X.dot(pc.transpose()).dot(pc)
return XX
def SIF_embedding(sentences, size, w2v_model, sif_weight, npc):
"""
Compute the scores between pairs of sentences using weighted average + removing the projection on the first principal component
:param We: We[i,:] is the vector for word i
:param x: x[i, :] are the indices of the words in the i-th sentence
:param w: w[i, :] are the weights for the words in the i-th sentence
:param params.rmpc: if >0, remove the projections of the sentence embeddings to their first principal component
:return: emb, emb[i, :] is the embedding for sentence i
"""
emb = build_sentences_vector_sif_weight(sentences,size,w2v_model,sif_weight)
if npc > 0:
emb = remove_pc(emb, npc)
return emb
调用上面的函数,获得句子的sif_enbedding向量:
sif_embedding_1= SIF_embedding(sen1_list, 100, model1, SIF_weight1, 1)
sif_embedding_2= SIF_embedding(sen2_list, 100, model2, SIF_weight2, 1)
结果如下:
array([[ 0.1631529 , 0.68570732, -0.56345899, ..., 0.05019303,
0.08823364, 0.73780842],
[ 0.1631529 , 0.68570732, -0.56345899, ..., 0.05019303,
0.08823364, 0.73780842],
[-0.45038705, 0.14196152, -0.29118772, ..., -0.94526421,
0.30650289, 0.00765647],
...,
[-0.17717167, -0.1151685 , 0.64575971, ..., 0.43572011,
-0.2061713 , -0.20033421],
[-0.24399607, -0.0214033 , 0.93929948, ..., 0.97110859,
-0.61965028, -0.61955608],
[ 0.11829696, -0.06113644, -0.26674104, ..., -0.30710764,
0.16443198, -0.07984093]])
- 步骤6(可选) :通过上述步骤2-步骤5的编码,计算相似句子的相似度 vs 不相似句子的相似度, 绘制得到分布图,哪一种编码最优?
任务5:搭建SiamCNN/LSTM模型,训练和预测
- 步骤1 :将训练好的word2vex作为深度学习embeeding层的初始化参数。
数据准备:
from collections import Counter
from keras.preprocessing.sequence import pad_sequences
import numpy as np
from gensim.models import Word2Vec
def select_best_length(train,limit_ratio=0.95):
"""
根据数据集的句子长度,选择最佳的样本max-length
:param limit_ratio:句子长度覆盖度,默认覆盖95%以上的句子
:return:
"""
len_list = []
max_length = 0
cover_rate = 0.0
for q1, q2 in zip(train['q1'], train['q2']):
len_list.append(len(q1))
len_list.append(len(q2))
all_sent = len(len_list)
sum_length = 0
len_dict = Counter(len_list).most_common()
for i in len_dict:
sum_length += i[1] * i[0]
average_length = sum_length / all_sent
for i in len_dict:
rate = i[1] / all_sent
cover_rate += rate
if cover_rate >= limit_ratio:
max_length = i[0]
break
print('average_length:', average_length)
print('max_length:', max_length)
return max_length
# select_best_length()
def build_data(train):
"""
构建数据集
:return:
"""
sample_x_left = train.q1.apply(lambda x: [char for char in x if char]).tolist()
sample_x_right = train.q2.apply(lambda x: [char for char in x if char]).tolist()
vocabs = {'UNK'}
for x_left, x_right in zip(sample_x_left, sample_x_right):
for char in x_left + x_right:
vocabs.add(char)
sample_x = [sample_x_left, sample_x_right]
sample_y = train.label.tolist()
print(len(sample_x_left), len(sample_x_right))
datas = [sample_x, sample_y]
word_dict = {wd: index for index, wd in enumerate(list(vocabs))}
vocab_path = 'model/vocab.txt'
with open(vocab_path, 'w', encoding='utf-8') as f:
f.write('\n'.join(list(vocabs)))
return datas, word_dict
def convert_data(datas, word_dict, MAX_LENGTH):
"""
将数据转换成keras所能处理的格式
:return:
"""
sample_x = datas[0]
sample_y = datas[1]
sample_x_left = sample_x[0]
sample_x_right = sample_x[1]
left_x_train = [[word_dict[char] for char in data] for data in sample_x_left]
right_x_train = [[word_dict[char] for char in data] for data in sample_x_right]
y_train = [int(i) for i in sample_y]
left_x_train = pad_sequences(left_x_train, MAX_LENGTH, padding='pre')
right_x_train = pad_sequences(right_x_train, MAX_LENGTH, padding='pre')
y_train = np.expand_dims(y_train, 1)
return left_x_train, right_x_train, y_train
def train_w2v(datas):
"""
训练词向量
:return:
"""
sents = datas[0][0] + datas[0][1]
model = Word2Vec(sentences=sents, vector_size=300, min_count=1)
model.wv.save_word2vec_format('model/token_vec_300.bin', binary=False)
def load_pretrained_embedding():
"""
加载预训练的词向量
:return:
"""
embedding_file = 'model/token_vec_300.bin'
embeddings_dict = {}
with open(embedding_file, 'r', encoding='utf-8') as f:
for line in f:
values = line.strip().split(' ')
if len(values) < 300:
continue
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_dict[word] = coefs
print('Found %s word vectors.' % len(embeddings_dict))
return embeddings_dict
def build_embedding_matrix(word_dict, embedding_dict, VOCAB_SIZE, EMBEDDING_DIM):
"""
加载词向量矩阵
:return:
"""
embedding_matrix = np.zeros((VOCAB_SIZE + 1, EMBEDDING_DIM))
for word, i in word_dict.items():
embedding_vector = embedding_dict.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
return embedding_matrix
- 步骤2 :搭建SiamCNN(Word2Vec句子编码 + 1D CNN +FC)的孪生网络结构,完成训练和预测,提交测试集预测结果。
搭建SiamCNN网络
def create_cnn_base_network(input_shape):
"""搭建CNN编码层网络,用于权重共享"""
input = Input(shape=input_shape)
cnn1 = Conv1D(64, 3, padding='valid', input_shape=(25, 100), activation='relu', name='conv_1d_layer1')(input)
cnn1 = Dropout(0.2)(cnn1)
cnn2 = Conv1D(32, 3, padding='valid', input_shape=(25, 100), activation='relu', name='conv_1d_layer2')(cnn1)
cnn2 = Dropout(0.2)(cnn2)
return Model(input, cnn2)
def train_model():
'''训练模型'''
#训练siamcnn模型
model = bilstm_siamcnn_model()
#训练siamLSTM模型
# model = bilstm_siamese_model()
# from keras.utils import plot_model
# plot_model(model, to_file='model/model.png', show_shapes=True)
history = model.fit(
x=[left_x_train, right_x_train],
y=y_train,
validation_split=0.2,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
)
draw_train(history)
model.save(model_path)
return model
train_model()
结果如下:
average_length: 11.859765
max_length: 25
100000 100000
Found 1527 word vectors.
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
left_x (InputLayer) [(None, 25)] 0 []
right_x (InputLayer) [(None, 25)] 0 []
embedding (Embedding) (None, 25, 100) 152900 ['left_x[0][0]',
'right_x[0][0]']
model (Functional) (None, 21, 32) 25440 ['embedding[0][0]',
'embedding[1][0]']
lambda (Lambda) (None, 1, 32) 0 ['model[0][0]',
'model[1][0]']
==================================================================================================
Total params: 178,340
Trainable params: 25,440
Non-trainable params: 152,900
结果有点奇怪???再改改看!
- 步骤3 :搭建SiamLSTM(Word2Vec句子编码 + LSTM + FC)的孪生网络结构,完成训练和预测,提交测试集预测结果。
搭建SiamLSTM模型如下:
from keras import backend as K
from keras.models import Model
from keras.layers import Input, Embedding, LSTM, Dropout, Lambda, Bidirectional
import matplotlib.pyplot as plt
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
from bulid_input import *
from load_data import *
# 参数设置
BATCH_SIZE = 512
EMBEDDING_DIM = 300
EPOCHS = 20
model_path = 'model/tokenvec_bilstm2_siamese_model.h5'
# 数据准备
train = read_bq('data/bq_corpus/train.tsv',['line_num','q1','q2','label'])
MAX_LENGTH = select_best_length(train)
datas, word_dict = build_data(train)
train_w2v(datas)
VOCAB_SIZE = len(word_dict)
embeddings_dict = load_pretrained_embedding()
embedding_matrix = build_embedding_matrix(word_dict, embeddings_dict,
VOCAB_SIZE, EMBEDDING_DIM)
left_x_train, right_x_train, y_train = convert_data(datas, word_dict, MAX_LENGTH)
def create_base_network(input_shape):
'''搭建编码层网络,用于权重共享'''
input = Input(shape=input_shape)
lstm1 = Bidirectional(LSTM(128, return_sequences=True))(input)
lstm1 = Dropout(0.5)(lstm1)
lstm2 = Bidirectional(LSTM(32))(lstm1)
lstm2 = Dropout(0.5)(lstm2)
return Model(input, lstm2)
def exponent_neg_manhattan_distance(sent_left, sent_right):
'''基于曼哈顿空间距离计算两个字符串语义空间表示相似度计算'''
return K.exp(-K.sum(K.abs(sent_left - sent_right), axis=1, keepdims=True))
def bilstm_siamese_model():
'''搭建网络'''
embedding_layer = Embedding(VOCAB_SIZE + 1,
EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_LENGTH,
trainable=False,
mask_zero=True)
left_input = Input(shape=(MAX_LENGTH,), dtype='float32', name="left_x")
right_input = Input(shape=(MAX_LENGTH,), dtype='float32', name='right_x')
encoded_left = embedding_layer(left_input)
encoded_right = embedding_layer(right_input)
shared_lstm = create_base_network(input_shape=(MAX_LENGTH, EMBEDDING_DIM))
left_output = shared_lstm(encoded_left)
right_output = shared_lstm(encoded_right)
distance = Lambda(lambda x: exponent_neg_manhattan_distance(x[0], x[1]),
output_shape=lambda x: (x[0][0], 1))([left_output, right_output])
model = Model([left_input, right_input], distance)
model.compile(loss='binary_crossentropy',
optimizer='nadam',
metrics=['accuracy'])
model.summary()
return model
def draw_train(history):
'''绘制训练曲线'''
# Plot training & validation accuracy values
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.savefig("model/result_atec.png")
plt.show()
def train_model():
'''训练模型'''
model = bilstm_siamese_model()
# from keras.utils import plot_model
# plot_model(model, to_file='model/model.png', show_shapes=True)
history = model.fit(
x=[left_x_train, right_x_train],
y=y_train,
validation_split=0.2,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
)
draw_train(history)
model.save(model_path)
return model
train_model()
结果如下:
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
left_x (InputLayer) [(None, 25)] 0
__________________________________________________________________________________________________
right_x (InputLayer) [(None, 25)] 0
__________________________________________________________________________________________________
embedding (Embedding) (None, 25, 100) 152900 left_x[0][0]
right_x[0][0]
__________________________________________________________________________________________________
model (Functional) (None, 16) 908048 embedding[0][0]
embedding[1][0]
__________________________________________________________________________________________________
lambda (Lambda) (None, 1) 0 model[0][0]
model[1][0]
==================================================================================================
Total params: 1,060,948
Trainable params: 908,048
Non-trainable params: 152,900
__________________________________________________________________________________________________
Epoch 1/20
157/157 [==============================] - 110s 559ms/step - loss: 0.6208 - accuracy: 0.6481 - val_loss: 0.5626 - val_accuracy: 0.7121
Epoch 2/20
157/157 [==============================] - 95s 603ms/step - loss: 0.5633 - accuracy: 0.7096 - val_loss: 0.5576 - val_accuracy: 0.7219
Epoch 3/20
157/157 [==============================] - 96s 614ms/step - loss: 0.5362 - accuracy: 0.7325 - val_loss: 0.4977 - val_accuracy: 0.7618
Epoch 4/20
157/157 [==============================] - 90s 576ms/step - loss: 0.5189 - accuracy: 0.7492 - val_loss: 0.5009 - val_accuracy: 0.7671
Epoch 5/20
157/157 [==============================] - 86s 545ms/step - loss: 0.5043 - accuracy: 0.7591 - val_loss: 0.4736 - val_accuracy: 0.7817
Epoch 6/20
157/157 [==============================] - 87s 555ms/step - loss: 0.4905 - accuracy: 0.7697 - val_loss: 0.4637 - val_accuracy: 0.7908
Epoch 7/20
157/157 [==============================] - 85s 543ms/step - loss: 0.4912 - accuracy: 0.7690 - val_loss: 0.4680 - val_accuracy: 0.7881
Epoch 8/20
157/157 [==============================] - 87s 554ms/step - loss: 0.4747 - accuracy: 0.7798 - val_loss: 0.4486 - val_accuracy: 0.7979
Epoch 9/20
157/157 [==============================] - 87s 555ms/step - loss: 0.4847 - accuracy: 0.7772 - val_loss: 0.4511 - val_accuracy: 0.7969
Epoch 10/20
157/157 [==============================] - 84s 535ms/step - loss: 0.4617 - accuracy: 0.7909 - val_loss: 0.4681 - val_accuracy: 0.8005
Epoch 11/20
157/157 [==============================] - 79s 505ms/step - loss: 0.4416 - accuracy: 0.8028 - val_loss: 0.4258 - val_accuracy: 0.8114
Epoch 12/20
157/157 [==============================] - 81s 517ms/step - loss: 0.4378 - accuracy: 0.8045 - val_loss: 0.4330 - val_accuracy: 0.8141
Epoch 13/20
157/157 [==============================] - 85s 539ms/step - loss: 0.4255 - accuracy: 0.8113 - val_loss: 0.4397 - val_accuracy: 0.8103
Epoch 14/20
157/157 [==============================] - 78s 499ms/step - loss: 0.4481 - accuracy: 0.7992 - val_loss: 0.4367 - val_accuracy: 0.8079
Epoch 15/20
157/157 [==============================] - 84s 536ms/step - loss: 0.4439 - accuracy: 0.8047 - val_loss: 0.4453 - val_accuracy: 0.8080
Epoch 16/20
157/157 [==============================] - 86s 548ms/step - loss: 0.4424 - accuracy: 0.8033 - val_loss: 0.4273 - val_accuracy: 0.8127
Epoch 17/20
157/157 [==============================] - 79s 504ms/step - loss: 0.4373 - accuracy: 0.8065 - val_loss: 0.4493 - val_accuracy: 0.8127
Epoch 18/20
157/157 [==============================] - 77s 490ms/step - loss: 0.4226 - accuracy: 0.8146 - val_loss: 0.4395 - val_accuracy: 0.8109
Epoch 19/20
157/157 [==============================] - 76s 484ms/step - loss: 0.4182 - accuracy: 0.8156 - val_loss: 0.4337 - val_accuracy: 0.8113
Epoch 20/20
157/157 [==============================] - 76s 484ms/step - loss: 0.3997 - accuracy: 0.8296 - val_loss: 0.4159 - val_accuracy: 0.8220
Process finished with exit code 0
最后验证集的准确度有0.82,还算不错,后面可是尝试将所有数据组合在一起进行训练,或许准确率还会有所提升。
任务6:搭建InferSent模型,训练和预测
- 步骤1 :将训练好的word2vex作为深度学习embeeding层的初始化参数。
- 步骤2 :搭建InferSent模型,尝试不同的交叉方法。
- 步骤3 :训练InferSent模型,提交测试集预测结果。
由于篇幅有限,因此将InferSent的结构介绍写在另一篇博客中InferSent模型介绍,,根据论文中给出的模型结构图,使用keras,搭建InferSent网络,其中编码器使用BiLSTM-Maxpooling。

6.1 模型搭建与训练
import warnings
warnings.filterwarnings('ignore')
from keras import backend as K
from keras.models import Model
from keras.layers import Input, Embedding, LSTM, Dropout, Lambda, Bidirectional, Dense, Flatten, merge
import tensorflow as tf
import matplotlib.pyplot as plt
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
from bulid_input import *
from load_data import *
# 参数设置
BATCH_SIZE = 512
EMBEDDING_DIM = 100
EPOCHS = 20
model_path = 'model/tokenvec_bilstm2_siamese_model.h5'
# 数据准备
train = read_bq('data/bq_corpus/train.tsv',['line_num','q1','q2','label'])
MAX_LENGTH = select_best_length(train)
datas, word_dict = build_data(train)
train_w2v(datas)
VOCAB_SIZE = len(word_dict)
embeddings_dict = load_pretrained_embedding()
embedding_matrix = build_embedding_matrix(word_dict, embeddings_dict,
VOCAB_SIZE, EMBEDDING_DIM)
left_x_train, right_x_train, y_train = convert_data(datas, word_dict, MAX_LENGTH)
# 搭建InferSent模型
def create_bilstm_base_network(input_shape):
'''搭建Bi-LSTM编码层网络,用于权重共享'''
input = Input(shape=input_shape)
lstm1 = Bidirectional(LSTM(128, return_sequences=True))(input)
lstm1 = Dropout(0.5)(lstm1)
lstm2 = Bidirectional(LSTM(32))(lstm1)
lstm2 = Dropout(0.5)(lstm2)
return Model(input, lstm2)
def exponent_neg_manhattan_distance(sent_left, sent_right):
'''基于曼哈顿空间距离计算两个字符串语义空间表示相似度计算'''
return K.exp(-K.sum(K.abs(sent_left - sent_right), axis=1, keepdims=True))
def cross_layer(vector_left, vector_right, cross_method):
vector = None
if cross_method == 'L1':
vector = K.abs(vector_left - vector_right)
elif cross_method == 'concat':
vector = K.concatenate(vector_left, vector_right, axis=1)
elif cross_method == ' multi':
vector = tf.multiply(vector_left, vector_right)
else:
print("Cross_method input error!")
return vector
def infersent_bilstm_model():
'''搭建网络'''
# embedding层,其中使用word2vec向量先进行embedding
embedding_layer = Embedding(VOCAB_SIZE + 1,
EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_LENGTH,
trainable=False,
mask_zero=True)
left_input = Input(shape=(MAX_LENGTH,), dtype='float32', name="left_x")
right_input = Input(shape=(MAX_LENGTH,), dtype='float32', name='right_x')
encoded_left = embedding_layer(left_input)
encoded_right = embedding_layer(right_input)
shared_lstm = create_bilstm_base_network(input_shape=(MAX_LENGTH, EMBEDDING_DIM))
left_output = shared_lstm(encoded_left)
right_output = shared_lstm(encoded_right) # (None, 64)
cross_vector = Lambda(lambda x: cross_layer(x[0], x[1], 'multi'),
output_shape=lambda x: (x[0][0], 1))([left_output, right_output]) # (None, 64)
# 加上三层全连接神经网络
fc1 = Dense(1024, activation='relu', name='fc1')(cross_vector)
fc2 = Dense(512, activation='relu', name='fc2')(fc1)
fc3 = Dense(16, activation='relu', name='fc3')(fc2)
sigmoid_layer = Dense(1, activation='sigmoid', name='sigmoid')(fc3)
model = Model([left_input, right_input], sigmoid_layer)
model.compile(loss='binary_crossentropy',
optimizer='nadam',
metrics=['accuracy'])
model.summary()
return model
def draw_train(history):
'''绘制训练曲线'''
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.savefig("model/result_atec.png")
plt.show()
def train_model():
'''训练模型'''
# 训练siamcnn模型
# model = bilstm_siamcnn_model()
# 训练siamLSTM模型
model = bilstm_siamese_model()
from keras.utils import plot_model
plot_model(model, to_file='model/model.png', show_shapes=True)
history = model.fit(
x=[left_x_train, right_x_train],
y=y_train,
validation_split=0.2,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
)
draw_train(history)
model.save(model_path)
return model
train_model()
模型结果如下:
# 使用两句子向量矩阵对应位置相乘的交叉特征方法,得到的模型结果如下:
average_length: 11.859765
max_length: 25
100000 100000
Found 1527 word vectors.
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
left_x (InputLayer) [(None, 25)] 0
__________________________________________________________________________________________________
right_x (InputLayer) [(None, 25)] 0
__________________________________________________________________________________________________
embedding (Embedding) (None, 25, 100) 152900 left_x[0][0]
right_x[0][0]
__________________________________________________________________________________________________
model (Functional) (None, 64) 308480 embedding[0][0]
embedding[1][0]
__________________________________________________________________________________________________
lambda (Lambda) (None, 64) 0 model[0][0]
model[1][0]
__________________________________________________________________________________________________
fc1 (Dense) (None, 1024) 66560 lambda[0][0]
__________________________________________________________________________________________________
fc2 (Dense) (None, 512) 524800 fc1[0][0]
__________________________________________________________________________________________________
fc3 (Dense) (None, 16) 8208 fc2[0][0]
__________________________________________________________________________________________________
sigmoid (Dense) (None, 1) 17 fc3[0][0]
==================================================================================================
Total params: 1,060,965
Trainable params: 908,065
Non-trainable params: 152,900
__________________________________________________________________________________________________
Epoch 1/20
157/157 [==============================] - 116s 598ms/step - loss: 0.5817 - accuracy: 0.6871 - val_loss: 0.5459 - val_accuracy: 0.7078
Epoch 2/20
157/157 [==============================] - 78s 499ms/step - loss: 0.5141 - accuracy: 0.7454 - val_loss: 0.4991 - val_accuracy: 0.7438
Epoch 3/20
157/157 [==============================] - 86s 547ms/step - loss: 0.4793 - accuracy: 0.7706 - val_loss: 0.4536 - val_accuracy: 0.7732
Epoch 4/20
157/157 [==============================] - 79s 503ms/step - loss: 0.4493 - accuracy: 0.7903 - val_loss: 0.4569 - val_accuracy: 0.7728
Epoch 5/20
157/157 [==============================] - 79s 506ms/step - loss: 0.4234 - accuracy: 0.8052 - val_loss: 0.4196 - val_accuracy: 0.7958
Epoch 6/20
157/157 [==============================] - 83s 529ms/step - loss: 0.4006 - accuracy: 0.8182 - val_loss: 0.4271 - val_accuracy: 0.7977
Epoch 7/20
157/157 [==============================] - 81s 516ms/step - loss: 0.3824 - accuracy: 0.8294 - val_loss: 0.3913 - val_accuracy: 0.8094
Epoch 8/20
157/157 [==============================] - 76s 486ms/step - loss: 0.3638 - accuracy: 0.8393 - val_loss: 0.3763 - val_accuracy: 0.8211
Epoch 9/20
157/157 [==============================] - 79s 501ms/step - loss: 0.3462 - accuracy: 0.8493 - val_loss: 0.3713 - val_accuracy: 0.8278
Epoch 10/20
157/157 [==============================] - 82s 525ms/step - loss: 0.3351 - accuracy: 0.8544 - val_loss: 0.3881 - val_accuracy: 0.8314
Epoch 11/20
157/157 [==============================] - 78s 498ms/step - loss: 0.3205 - accuracy: 0.8631 - val_loss: 0.3438 - val_accuracy: 0.8446
Epoch 12/20
157/157 [==============================] - 84s 535ms/step - loss: 0.3075 - accuracy: 0.8693 - val_loss: 0.3349 - val_accuracy: 0.8515
Epoch 13/20
157/157 [==============================] - 80s 511ms/step - loss: 0.2942 - accuracy: 0.8766 - val_loss: 0.3312 - val_accuracy: 0.8572
Epoch 14/20
157/157 [==============================] - 80s 509ms/step - loss: 0.2859 - accuracy: 0.8796 - val_loss: 0.3210 - val_accuracy: 0.8580
Epoch 15/20
157/157 [==============================] - 77s 489ms/step - loss: 0.2738 - accuracy: 0.8856 - val_loss: 0.3004 - val_accuracy: 0.8706
Epoch 16/20
157/157 [==============================] - 85s 539ms/step - loss: 0.2647 - accuracy: 0.8898 - val_loss: 0.3114 - val_accuracy: 0.8724
Epoch 17/20
157/157 [==============================] - 76s 485ms/step - loss: 0.2566 - accuracy: 0.8948 - val_loss: 0.3065 - val_accuracy: 0.8722
Epoch 18/20
157/157 [==============================] - 76s 486ms/step - loss: 0.2482 - accuracy: 0.8971 - val_loss: 0.2850 - val_accuracy: 0.8791
Epoch 19/20
157/157 [==============================] - 82s 523ms/step - loss: 0.2432 - accuracy: 0.8992 - val_loss: 0.2847 - val_accuracy: 0.8816
Epoch 20/20
157/157 [==============================] - 83s 529ms/step - loss: 0.2327 - accuracy: 0.9049 - val_loss: 0.2914 - val_accuracy: 0.8787
Process finished with exit code 0
其中句子编码器encode使用BiLSTM-Maxpooling,原论文中提到的几种交叉验证方法,(我的理解是三种选一种分别进行实验),实验结果如下:
6.2 使用不同交叉方法训练结果
- 使用vector对应位置相乘的交叉特征方法在验证集上的准确率有88.16%。
- 使用两句子向量concatenate的交叉方法,查看验证集准确是91.43%,分析其比对应相乘准确率高的原因可能有:1、在concatenate时,vector的维度由原来的64变为128维,后接FC层时需要使用更多的参数进行训练,模型的网络更大,可以学习到语义中更复杂的信息,因此准确率高;2、使用两句子向量concatenate的交叉方法比对应相乘的交叉方法更能够提取出两句子向量的异同,对后续进行分类效果更好。
- 使用两句子向量相减后取绝对值的交叉方法,结果不如上面两种交叉方法好(只有78.%多),且存在比较严重的过拟合。
综上,使用两句子向量concatenate的交叉方法可以使模型在验证集的准确率更高,模型更快收敛。
任务7:搭建ESIM模型,训练和预测
- 步骤1 :将训练好的word2vex作为深度学习embeeding层的初始化参数。
- 步骤2 :搭建ESIM模型,尝试不同的交叉方法。
- 步骤3 :训练ESIM模型,提交测试集预测结果。
由于本博客篇幅有限,关于ESIM模型的详细结构见我的另一篇博客:ESIM模型详解
7.1 ESIM模型搭建与训练
import warnings
warnings.filterwarnings('ignore')
from keras.layers import *
from keras.activations import softmax
from keras.models import Model
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
from bulid_input import *
from load_data import *
def StaticEmbedding(embedding_matrix):
# Embedding metrix
in_dim, out_dim = embedding_matrix.shape
return Embedding(in_dim, out_dim, weights=[embedding_matrix], trainable=False)
def subtract(input_1, input_2):
minus_input_2 = Lambda(lambda x: -x)(input_2)
return add([input_1, minus_input_2])
def aggregate(input_1, input_2, num_dense=300, dropout_rate=0.5):
feat1 = concatenate([GlobalAvgPool1D()(input_1), GlobalMaxPool1D()(input_1)])
feat2 = concatenate([GlobalAvgPool1D()(input_2), GlobalMaxPool1D()(input_2)])
x = concatenate([feat1, feat2])
x = BatchNormalization()(x)
x = Dense(num_dense, activation='relu')(x)
x = BatchNormalization()(x)
x = Dropout(dropout_rate)(x)
x = Dense(num_dense, activation='relu')(x)
x = BatchNormalization()(x)
x = Dropout(dropout_rate)(x)
return x
def align(input_1, input_2):
attention = Dot(axes=-1, name='attention-layer')([input_1, input_2])
w_att_1 = Lambda(lambda x: softmax(x, axis=1))(attention)
w_att_2 = Permute((2, 1))(Lambda(lambda x: softmax(x, axis=2))(attention))
in1_aligned = Dot(axes=1)([w_att_1, input_1])
in2_aligned = Dot(axes=1)([w_att_2, input_2])
return in1_aligned, in2_aligned
def build_model(embedding_matrix, num_class=1, max_length=30, lstm_dim=300):
q1 = Input(shape=(max_length,))
q2 = Input(shape=(max_length,))
# Embedding
embedding = StaticEmbedding(embedding_matrix)
q1_embed = BatchNormalization(axis=2)(embedding(q1))
q2_embed = BatchNormalization(axis=2)(embedding(q2))
# Encoding
encode = Bidirectional(LSTM(lstm_dim, return_sequences=True))
q1_encoded = encode(q1_embed)
q2_encoded = encode(q2_embed)
# Alignment
q1_aligned, q2_aligned = align(q1_encoded, q2_encoded)
# Compare
q1_combined = concatenate(
[q1_encoded, q2_aligned, subtract(q1_encoded, q2_aligned), multiply([q1_encoded, q2_aligned])])
q2_combined = concatenate(
[q2_encoded, q1_aligned, subtract(q2_encoded, q1_aligned), multiply([q2_encoded, q1_aligned])])
compare = Bidirectional(LSTM(lstm_dim, return_sequences=True))
q1_compare = compare(q1_combined)
q2_compare = compare(q2_combined)
# Aggregate
x = aggregate(q1_compare, q2_compare)
x = Dense(num_class, activation='sigmoid')(x)
model = Model(inputs=[q1, q2], outputs=x)
model.compile(loss='binary_crossentropy',
optimizer='nadam',
metrics=['accuracy'])
model.summary()
return model
if __name__ == "__main__":
# 参数设置
BATCH_SIZE = 512
EMBEDDING_DIM = 100
EPOCHS = 20
model_path = 'model/tokenvec_esim_model.h5'
# 数据准备
train = read_bq('data/bq_corpus/train.tsv', ['line_num', 'q1', 'q2', 'label'])
MAX_LENGTH = select_best_length(train)
datas, word_dict = build_data(train)
train_w2v(datas)
VOCAB_SIZE = len(word_dict)
embeddings_dict = load_pretrained_embedding()
embedding_matrix = build_embedding_matrix(word_dict, embeddings_dict,
VOCAB_SIZE, EMBEDDING_DIM)
left_x_train, right_x_train, y_train = convert_data(datas, word_dict, MAX_LENGTH)
model = build_model(embedding_matrix, max_length=MAX_LENGTH, lstm_dim=128)
from keras.utils.vis_utils import plot_model
plot_model(model, to_file='model/model_esim.png', show_shapes=True)
history = model.fit(
x=[left_x_train, right_x_train],
y=y_train,
validation_split=0.2,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
)
model.save(model_path)
7.2 结果分析
根据原论文,应该是同时使用相减,点积等交叉方法,结果如下:
average_length: 11.859765
max_length: 25
100000 100000
Found 1527 word vectors.
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 25)] 0
__________________________________________________________________________________________________
input_2 (InputLayer) [(None, 25)] 0
__________________________________________________________________________________________________
embedding (Embedding) (None, 25, 100) 152900 input_1[0][0]
input_2[0][0]
__________________________________________________________________________________________________
batch_normalization (BatchNorma (None, 25, 100) 400 embedding[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 25, 100) 400 embedding[1][0]
__________________________________________________________________________________________________
bidirectional (Bidirectional) (None, 25, 256) 234496 batch_normalization[0][0]
batch_normalization_1[0][0]
__________________________________________________________________________________________________
dot (Dot) (None, 25, 25) 0 bidirectional[0][0]
bidirectional[1][0]
__________________________________________________________________________________________________
lambda_1 (Lambda) (None, 25, 25) 0 dot[0][0]
__________________________________________________________________________________________________
permute (Permute) (None, 25, 25) 0 lambda_1[0][0]
__________________________________________________________________________________________________
lambda (Lambda) (None, 25, 25) 0 dot[0][0]
__________________________________________________________________________________________________
dot_2 (Dot) (None, 25, 256) 0 permute[0][0]
bidirectional[1][0]
__________________________________________________________________________________________________
dot_1 (Dot) (None, 25, 256) 0 lambda[0][0]
bidirectional[0][0]
__________________________________________________________________________________________________
lambda_2 (Lambda) (None, 25, 256) 0 dot_2[0][0]
__________________________________________________________________________________________________
lambda_3 (Lambda) (None, 25, 256) 0 dot_1[0][0]
__________________________________________________________________________________________________
add (Add) (None, 25, 256) 0 bidirectional[0][0]
lambda_2[0][0]
__________________________________________________________________________________________________
multiply (Multiply) (None, 25, 256) 0 bidirectional[0][0]
dot_2[0][0]
__________________________________________________________________________________________________
add_1 (Add) (None, 25, 256) 0 bidirectional[1][0]
lambda_3[0][0]
__________________________________________________________________________________________________
multiply_1 (Multiply) (None, 25, 256) 0 bidirectional[1][0]
dot_1[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 25, 1024) 0 bidirectional[0][0]
dot_2[0][0]
add[0][0]
multiply[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 25, 1024) 0 bidirectional[1][0]
dot_1[0][0]
add_1[0][0]
multiply_1[0][0]
__________________________________________________________________________________________________
bidirectional_1 (Bidirectional) (None, 25, 256) 1180672 concatenate[0][0]
concatenate_1[0][0]
__________________________________________________________________________________________________
global_average_pooling1d (Globa (None, 256) 0 bidirectional_1[0][0]
__________________________________________________________________________________________________
global_max_pooling1d (GlobalMax (None, 256) 0 bidirectional_1[0][0]
__________________________________________________________________________________________________
global_average_pooling1d_1 (Glo (None, 256) 0 bidirectional_1[1][0]
__________________________________________________________________________________________________
global_max_pooling1d_1 (GlobalM (None, 256) 0 bidirectional_1[1][0]
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (None, 512) 0 global_average_pooling1d[0][0]
global_max_pooling1d[0][0]
__________________________________________________________________________________________________
concatenate_3 (Concatenate) (None, 512) 0 global_average_pooling1d_1[0][0]
global_max_pooling1d_1[0][0]
__________________________________________________________________________________________________
concatenate_4 (Concatenate) (None, 1024) 0 concatenate_2[0][0]
concatenate_3[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 1024) 4096 concatenate_4[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 300) 307500 batch_normalization_2[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 300) 1200 dense[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 300) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 300) 90300 dropout[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 300) 1200 dense_1[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 300) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 1) 301 dropout_1[0][0]
==================================================================================================
Total params: 1,973,465
Trainable params: 1,816,917
Non-trainable params: 156,548
__________________________________________________________________________________________________
Epoch 1/20
157/157 [==============================] - 27s 102ms/step - loss: 0.6268 - accuracy: 0.7018 - val_loss: 0.6260 - val_accuracy: 0.6199
Epoch 2/20
157/157 [==============================] - 14s 91ms/step - loss: 0.4399 - accuracy: 0.7983 - val_loss: 0.4808 - val_accuracy: 0.7659
Epoch 3/20
157/157 [==============================] - 14s 91ms/step - loss: 0.3649 - accuracy: 0.8392 - val_loss: 0.4087 - val_accuracy: 0.8142
Epoch 4/20
157/157 [==============================] - 14s 91ms/step - loss: 0.3029 - accuracy: 0.8706 - val_loss: 0.3541 - val_accuracy: 0.8462
Epoch 5/20
157/157 [==============================] - 14s 91ms/step - loss: 0.2456 - accuracy: 0.8984 - val_loss: 0.3566 - val_accuracy: 0.8507
Epoch 6/20
157/157 [==============================] - 14s 91ms/step - loss: 0.1913 - accuracy: 0.9231 - val_loss: 0.3457 - val_accuracy: 0.8686
Epoch 7/20
157/157 [==============================] - 14s 91ms/step - loss: 0.1468 - accuracy: 0.9427 - val_loss: 0.4154 - val_accuracy: 0.8534
Epoch 8/20
157/157 [==============================] - 14s 91ms/step - loss: 0.1164 - accuracy: 0.9547 - val_loss: 0.3759 - val_accuracy: 0.8827
Epoch 9/20
157/157 [==============================] - 14s 91ms/step - loss: 0.0847 - accuracy: 0.9680 - val_loss: 0.3767 - val_accuracy: 0.8822
Epoch 10/20
157/157 [==============================] - 14s 91ms/step - loss: 0.0706 - accuracy: 0.9731 - val_loss: 0.4152 - val_accuracy: 0.8832
Epoch 11/20
157/157 [==============================] - 14s 91ms/step - loss: 0.0588 - accuracy: 0.9777 - val_loss: 0.3578 - val_accuracy: 0.9011
Epoch 12/20
157/157 [==============================] - 14s 91ms/step - loss: 0.0479 - accuracy: 0.9825 - val_loss: 0.3783 - val_accuracy: 0.8989
Epoch 13/20
157/157 [==============================] - 14s 91ms/step - loss: 0.0400 - accuracy: 0.9852 - val_loss: 0.4218 - val_accuracy: 0.8934
Epoch 14/20
157/157 [==============================] - 14s 91ms/step - loss: 0.0368 - accuracy: 0.9867 - val_loss: 0.4127 - val_accuracy: 0.8985
Epoch 15/20
157/157 [==============================] - 14s 91ms/step - loss: 0.0329 - accuracy: 0.9883 - val_loss: 0.4502 - val_accuracy: 0.8981
Epoch 16/20
157/157 [==============================] - 14s 91ms/step - loss: 0.0293 - accuracy: 0.9894 - val_loss: 0.5123 - val_accuracy: 0.8892
Epoch 17/20
157/157 [==============================] - 14s 91ms/step - loss: 0.0314 - accuracy: 0.9888 - val_loss: 0.4081 - val_accuracy: 0.9037
Epoch 18/20
157/157 [==============================] - 14s 91ms/step - loss: 0.0283 - accuracy: 0.9897 - val_loss: 0.4041 - val_accuracy: 0.9062
Epoch 19/20
157/157 [==============================] - 14s 91ms/step - loss: 0.0223 - accuracy: 0.9923 - val_loss: 0.4386 - val_accuracy: 0.9031
Epoch 20/20
157/157 [==============================] - 14s 91ms/step - loss: 0.0198 - accuracy: 0.9929 - val_loss: 0.4379 - val_accuracy: 0.9055
Process finished with exit code 0
ESIM在训练集上准确率接近99%,但是在测试集上最高只有90%,稳定在90%上下1%左右。检查了网络结构,没有写错。可能是存在一定程度的过拟合了。
任务8:使用BERT或ERNIE完成NSP任务
参考代码:
https://aistudio.baidu.com/aistudio/projectdetail/3168859
bert-nsp代码
- 步骤1 :学习Bert模型的使用。
之前看过挺多遍BERT模型,所以这里不再赘述BERT的模型结果,想了解的同学可以看看这篇博客:【NLP】Google BERT模型原理详解。
好!现在开始使用BERT进行句子编码!
- 步骤2 :使用Bert完成NSP任务的训练和预测,提交测试集预测结果。
import warnings
warnings.filterwarnings('ignore') # 隐藏警告!
from transformers import logging
logging.set_verbosity_warning()
import pandas as pd
import torch
from sklearn.model_selection import train_test_split
from torch.utils.data import Dataset, DataLoader, TensorDataset
import numpy as np
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
def read_tsv(input_file,columns):
with open(input_file,"r",encoding="utf-8") as file:
lines = []
count = 1
for line in file:
if len(line.strip().split("\t")) != 1:
lines.append([count]+line.strip().split("\t"))
count += 1
df = pd.DataFrame(lines)
df.columns = columns
return df
# 数据集读取
class bqDataset(Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
# 读取单个样本
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(int(self.labels[idx]))
return item
def __len__(self):
return len(self.labels)
# 精度计算
def flat_accuracy(preds, labels):
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)
# 训练函数
def train():
model.train()
total_train_loss = 0
iter_num = 0
total_iter = len(train_loader)
for batch in train_loader:
# 正向传播
optim.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs[0]
total_train_loss += loss.item()
# 反向梯度信息
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# 参数更新
optim.step()
iter_num += 1
if (iter_num % 100 == 0):
print("epoth: %d, iter_num: %d, loss: %.4f, %.2f%%" % (
epoch, iter_num, loss.item(), iter_num / total_iter * 100))
print("Epoch: %d, Average training loss: %.4f" % (epoch, total_train_loss / len(train_loader)))
def validation():
model.eval()
total_eval_accuracy = 0
total_eval_loss = 0
for batch in val_dataloader:
with torch.no_grad():
# 正常传播
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs[0]
logits = outputs[1]
total_eval_loss += loss.item()
logits = logits.detach().cpu().numpy()
label_ids = labels.to('cpu').numpy()
total_eval_accuracy += flat_accuracy(logits, label_ids)
avg_val_accuracy = total_eval_accuracy / len(val_dataloader)
print("Accuracy: %.4f" % (avg_val_accuracy))
print("Average testing loss: %.4f" % (total_eval_loss / len(val_dataloader)))
print("-------------------------------")
if __name__ == '__main__':
bq_train = read_tsv('data/bq_corpus/train.tsv', ['index', 'question1', 'question2', 'label'])
q1_train, q1_val, q2_train, q2_val, train_label, test_label = train_test_split(
bq_train['question1'].iloc[:],
bq_train['question2'].iloc[:],
bq_train['label'].iloc[:],
test_size=0.1,
stratify=bq_train['label'].iloc[:])
# input_ids:字的编码
# token_type_ids:标识是第一个句子还是第二个句子
# attention_mask:标识是不是填充
# transformers bert相关的模型使用和加载
from transformers import BertTokenizer
# 分词器,词典
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
train_encoding = tokenizer(list(q1_train), list(q2_train),
truncation=True, padding=True, max_length=100)
val_encoding = tokenizer(list(q1_val), list(q2_val),
truncation=True, padding=True, max_length=100)
train_dataset = bqDataset(train_encoding, list(train_label))
val_dataset = bqDataset(val_encoding, list(test_label))
from transformers import BertForNextSentencePrediction, AdamW, get_linear_schedule_with_warmup
model = BertForNextSentencePrediction.from_pretrained('bert-base-chinese')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 单个读取到批量读取
train_loader = DataLoader(train_dataset, batch_size=16, num_workers=6, pin_memory=True, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=16, num_workers=6, pin_memory=True, shuffle=True)
# 优化方法
optim = AdamW(model.parameters(), lr=1e-5)
for epoch in range(20):
print("------------Epoch: %d ----------------" % epoch)
train()
validation()
torch.save(model.state_dict(), f'model_{epoch}.pt')
进行测试:
def predict():
model.eval()
test_predict = []
for batch in test_dataloader:
with torch.no_grad():
# 正常传播
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs[0]
logits = outputs[1]
logits = logits.detach().cpu().numpy()
label_ids = labels.to('cpu').numpy()
test_predict += list(np.argmax(logits, axis=1).flatten())
return test_predict
生成结果:
test_label = predict()
pd.DataFrame({'label':test_label}).to_csv('submit.csv', index=None)
结果还错!在第5个epoch时,验证集准确率达到92%。后面进行细微的调参应该还有更不错的效果。
任务9:Bert-flow、Bert-white、SimCSE
- 步骤1 :学习Bert-white原理和实现
- 步骤2 :学习SimCSE原理和实现
Bert-flow,Bert-whitning和SimCSE三种方法总计记录在我的这篇博客中:文本表达:解决BERT中的各向异性方法总结