ICCV2021 频域图像翻译 Frequency Domain Image Translation: More Photo-realistic, Better Identity-preserving
Frequency Domain Image Translation:
More Photo-realistic, Better Identity-preserving

[pdf] [github]

Figure 1: Image translation results of the Flicker mountains dataset. From left column to right: we show the source images, reference images, the generated images using Swapping Autoencoder [48] and FDIT (ours), respectively. SwapAE over-adapt to the reference image. FDIT better preserves the composition and identity with respect to the source image.
目录
Abstract
1. Introduction
3. Frequency Domain Image Translation
3.1. Pixel Space Loss
3.2. Fourier Frequency Space Loss
3.3. Overall Loss
4. Experiments
4.1. Autoencoder
4.2. Ablation Study
4.3. GAN Inversion
4.4. StarGAN v2
Abstract
Image-to-image translation has been revolutionized with GAN-based methods. However, existing methods lack the ability to preserve the identity of the source domain. As a result, synthesized images can often over-adapt to the reference domain, losing important structural characteristics and suffering from suboptimal visual quality.
To solve these challenges, we propose a novel frequency domain image translation (FDIT) framework, exploiting frequency information for enhancing the image generation process. Our key idea is to decompose the image into low-frequency and high-frequency components, where the high-frequency feature captures object structure akin to the identity. Our training objective facilitates the preservation of frequency information in both pixel space and Fourier spectral space.
We broadly evaluate FDIT across five large-scale datasets and multiple tasks including image translation and GAN inversion. Extensive experiments and ablations show that FDIT effectively preserves the identity of the source image, and produces photo-realistic images. FDIT establishes stateof-the-art performance, reducing the average FID score by 5.6% compared to the previous best method.
研究方向与问题
基于 GAN 的方法使图像到图像的翻译发生了革命性的变化(点明研究对象:基于 GAN 的图像翻译)。然而,现有的方法缺乏保留源域标识的能力(问题原因)。因此,合成的图像往往会过度适应参考域,失去重要的结构特征,导致视觉质量不佳(问题现象)。
研究方法和优点
为了解决这些挑战,本文提出了一种新的频域图像翻译 (FDIT) 框架,利用频率信息增强图像生成过程(研究方法)。本文的主要想法是将图像分解为低频和高频成分,其中高频特征捕获类似于 identity 的对象结构(核心思想)。本文的训练目标有利于在像素空间和傅里叶频谱空间中保持频率信息(方法优/特点)。
研究结论和成就
本文在 5 个大规模数据集和多个任务中广泛评估 FDIT,包括图像翻译和 GAN 反演。大量的实验和消融实验表明,FDIT 能有效地保持了源图像 identity,并产生了逼真的图像(方法能力的结论)。FDIT 建立了最先进的性能,与之前的最佳方法相比,平均 FID 评分降低了 5.6%(方法成就的结论)。
1. Introduction
Image-to-image translation [70, 9, 4, 59, 56] has attracted great research attention in computer vision, which is tasked to synthesize new images based on the source and reference images (see Figure 1). This task has been revolutionized since the introduction of GAN-based methods [30, 69]. In particular, a plethora of literature attempts to decompose the image representation into a content space and a style space [11, 48, 40, 27]. To translate a source image, its content representation is combined with a different style representation from the reference domain.
图像到图像翻译在计算机视觉领域引起了极大的研究关注,该领域的任务是基于源和参考图像合成新的图像 (见图 1)。自基于 GAN 的方法引入以来,这一任务发生了革命性进展。特别是,大量的文献试图将图像表征分解为内容空间和风格空间。要转换源图像,将其内容表示与来自参考域的不同样式表示相结合。
Despite exciting progress, existing solutions suffer from two notable challenges.
First, there is no explicit mechanism that allows preserving the identity, and as a result, the synthesized image can over-adapt to the reference domain and lose the original identity characteristics. This can be observed in Figure 1, where Swapping Autoencoder [48] generates images with identity and structure closer to the reference rather than the source image. For example, in the second row, the tree is absent from the source image yet occurs in the translation result.
Second, the generation process may lose important fine-grained details, leading to suboptimal visual quality. This can be prohibitive for generating photo-realistic high-resolution images.
The challenges above raise the following important question: how can we enable photo-realistic image translation while better preserving the identity?
尽管取得了令人欣慰的进展,但现有的解决方案面临着两个显著的挑战。
首先,没有明确的机制来保留 identity(原因),导致合成图像过度适应参考域而失去原有的身份特征(现象)。这可以在图 1 中观察到,其中交换自编码器(Swapping Autoencoder [48] )生成的图像标识和结构更接近参考图像而不是源图像。例如,在第二行中,源映像中没有树,但在转换结果中出现。
其次,生成过程可能会失去重要的细粒度细节(原因),导致不理想的视觉质量(现象)。这可能不利于生成逼真的高分辨率图像。
上述挑战提出了以下重要问题:如何在更好地保存 identity 的同时实现逼真的图像翻译?
【 好的论文,首先是要提出好的问题。本段提出了两个非常合理的问题,读者一读就明白这些问题,并迫不及待的想要了解作者是怎么解决这些问题的。】
Motivated by this, we propose a novel framework–Frequency Domain Image Translation (FDIT)–exploiting frequency information for enhancing the image generation process.
Our key idea is to decompose the image into lowand high-frequency components, and regulate the frequency consistency during image translation.
Our framework is inspired by and grounded in signal processing [15, 5, 22]. Intuitively, the low-frequency component captures information such as color and illumination; whereas the highfrequency component corresponds to sharp edges and important details of objects. For example, Figure 2 shows the resulting images via adopting the Gaussian blur to decompose the original image into low- vs. high-frequency counterparts (top vs. bottom). The building identity is distinguishable based on the high-frequency components.
本文方法介绍:整体简介
基于此,我们提出了一种新的框架——频域图像翻译 (FDIT)——利用频率信息来增强图像生成过程。
核心思想是将图像分解为低频和高频分量,并在图像平移过程中调节频率一致性。
本文的框架受到信号处理的启发和基础。低频部分直观地捕捉颜色和照明等信息;而高频分量对应的是物体的尖锐边缘和重要细节。例如,图 2 显示了采用高斯模糊将原始图像分解为低、高频(上、下) 对应的结果图像。基于高频成分,可以使得 构建 identity 是可解耦的。
Formally, FDIT introduces novel frequency-based training objectives, which facilitates the preservation of frequency information during training. The frequency information can be reflected in the visual space as identity characteristics and important fine details.
Formally, we impose restrictions in both pixel space as well as the Fourier spectral space.
In the pixel space, we transform each image into its high-frequency and low-frequency components by applying the Gaussian kernel (i.e., low-frequency filter). A loss term regulates the high-frequency components to be similar between the source image and the generated image.
Furthermore, FDIT directly regulates the consistency in the frequency domain by applying Fast Fourier Transformation (FFT) to each image. This additionally ensures that the original and translated images share a similar highfrequency spectrum.
本文方法介绍:关键描述
在形式上,FDIT 引入了新的基于频率的训练目标,这有助于在训练期间保存频率信息。频率信息可以作为 identity 特征和重要的精细细节体现在视觉空间中。
形式上,本文在像素空间和傅里叶频谱空间都施加了限制。
在像素空间中,通过高斯核 (即低频滤波器) 将每幅图像转换为其高频和低频分量。损耗项调节源图像和生成图像之间的高频分量相似。
此外,FDIT 通过对图像进行快速傅里叶变换 (FFT),直接在频域上调节一致性。这还确保了原始图像和翻译图像共享相似的高频频谱。
Extensive experiments demonstrate that FDIT is highly effective, establishing state-of-the-art performance on image translation tasks. Below we summarize our key results and contributions:
• We propose a novel frequency-based image translation framework, FDIT, which substantially improves the identity-preserving generation, while enhancing the image hybrids realism. FDIT outperforms competitive baselines by a large margin, across all datasets considered. Compared to the vanilla Swapping Autoencoder (SwapAE) [48], FDIT decreases the FID score by 5.6%.
• We conduct extensive ablations and user study to evaluate the (1) identity-preserving capability and (2) image quality, where FDIT constantly surpasses previous methods. For example, user study shows an average preference of 75.40% and 64.39% for FDIT over Swap AE in the above two aspects. We also conduct the ablation study to understand the efficacy of different loss terms and frequency supervision modules.
• We broadly evaluate our approach across five largescale datasets (including two newly collected ones). Quantitative and qualitative evaluations on image translation and GAN-inversion tasks demonstrate the superiority of our method.
大量的实验证明 FDIT 是非常有效的,在图像翻译任务中建立了 SOTA 的性能。
• 提出了一种新的基于频率的图像翻译框架 FDIT,该框架极大地改进了保持 identity 的生成,同时增强了图像的混合真实感。在考虑的所有数据集上,FDIT 的性能都大大优于竞争性基线。与交换自动编码器 (SwapAE)[48] 相比,FDIT 降低了 5.6% 的 FID 得分。
• 进行了广泛的消融和用户研究,以评估 (1) identity 保持能力和 (2) 图像质量,其中 FDIT 不断超越以前的方法。例如,用户研究显示,FDIT 在上述两个方面的平均偏好分别为7 5.40% 和 64.39%。还进行了消融研究,以了解不同损失条件和频率监控模块的有效性。
• 在 5 个大型数据集 (包括两个新收集的数据集) 上对本文的方法进行了广泛评估。对图像平移和GAN 反演任务的定量和定性评价证明了本文方法的优越性。
3. Frequency Domain Image Translation
Our novel frequency-based image translation framework is illustrated in Figure 3. In what follows, we first provide an overview and then describe the training objective. Our training objective facilitates the preservation of frequency information during the image translation process. Specifically, we impose restrictions in both pixel space (Section 3.1) as well as the Fourier spectral space (Section 3.2).
基于频率的图像翻译框架如图 3 所示。在接下来的内容中,首先提供一个概述,然后描述训练目标。本文的训练目标是在图像翻译过程中保持频率信息。具体来说,在像素空间 (第3.1节) 和傅里叶频谱空间 (第3.2节) 都施加了限制。
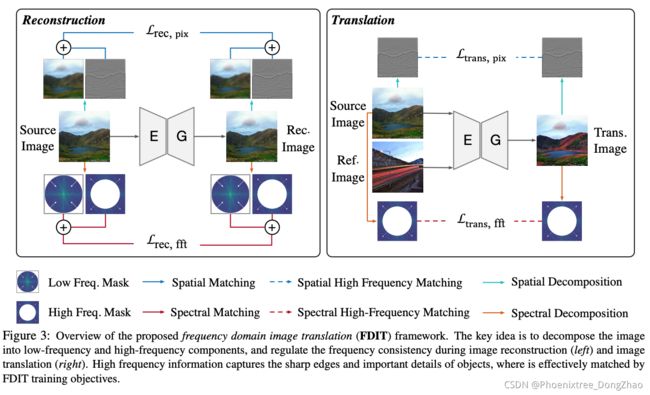
3.1. Pixel Space Loss
High- and low-frequency images
We transform each input x into two images xL ∈ X and xH ∈ X , which correspond to the low-frequency and high-frequency images respectively. Note that both xL and xH are in the same spatial dimension as x. Specifically, we employ the Gaussian kernel, which filters the high frequency feature and keeps the low frequency information:
where [i, j] denotes the spatial location within the image, and σ^2 denotes the variance of the Gaussian function. Following [22], the variance is increased proportionally with the Gaussian kernel size . Using convolution of the Gaussian kernel on input x, we obtain the low frequency (blurred) image xL:
where m, n denotes the index of an 2D Gaussian kernel, i.e.,
To obtain xH, we first convert color images into grayscale, and then subtract the low frequency information:
where the rgb2gray function converts the color image to the grayscale. This removes the color and illumination information that is unrelated to the identity and structure. The resulting high frequency image xH contains the sharp edges, i.e. sketch of the original image.
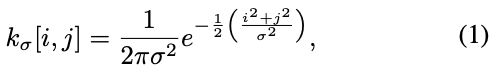
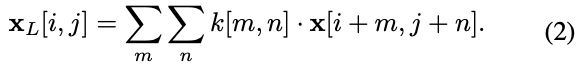
获得高、低频图像
将每个输入 x 变换为两幅图像 xL∈x 和 xH∈x,分别对应低频图像和高频图像。注意 xL和 xH 与 x 在同一个空间维数。
低频:具体来说,采用高斯核如公式(1),滤波高频特征,保留低频信息。
其中 [i, j] 为图像内的空间位置,σ^2 为高斯函数的方差。方差随高斯核大小成比例增加。利用高斯核对输入 x 的卷积公式(2),得到低频 (模糊) 图像 xL。其中 m, n 为二维高斯核的指标,即
![]()
高频:为了得到 xH,首先将彩色图像转换为灰度,然后减去低频信息,如公式(3)。
其中 rgb2gray 函数将彩色图像转换为灰度。这就去掉了与 identity 和结构无关的颜色和照明信息。得到的高频图像 xH 包含了尖锐的边缘,即原始图像的草图。
Reconstruction loss in the pixel space
We now employ the following reconstruction loss term, which enforces the similarity between the input and generator’s output, for both low-frequency and high-frequency components:
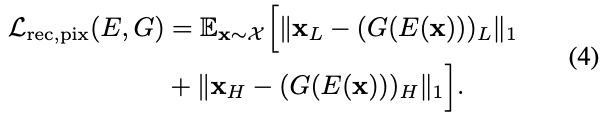
像素空间重构损失
对低频和高频分量使用 (4)的重构损耗项,这加强了输入和输出之间的相似性。
Translation matching loss in the pixel space
In addition to reconstruction loss, we also employ the translation matching loss:
where
and
are the content code of the source image and the style code of the reference image, respectively. Intuitively, the translated images should adhere to the identity of the original image. We achieve this by regulating the high frequency components, and enforce the generated image to have the same high frequency images as the original source image.

像素空间中的平移匹配损失
除了重构损失外,本文还采用了(5)平移匹配损失。
其中,![]() and
and ![]() 分别是源图像的内容代码和参考图像的样式代码。直觉上,翻译后的图像应该坚持原图像的 identity。本文通过调节高频分量来实现这一点,并强制生成的图像具有与原始源图像相同的高频图像。
分别是源图像的内容代码和参考图像的样式代码。直觉上,翻译后的图像应该坚持原图像的 identity。本文通过调节高频分量来实现这一点,并强制生成的图像具有与原始源图像相同的高频图像。
3.2. Fourier Frequency Space Loss
Transformation from pixel space to the Fourier spectral space
In addition to the pixel-space constraints, we introduce loss terms that directly operate in the Fourier domain space. In particular, we use Fast Fourier Transformation (FFT) and map x from the pixel space to the Fourier spectral space. We apply the Discrete Fourier Transform F on a real 2D image I of size H × W:
For the ease of post processing, we then transform F from the complex number domain to the real number domain. Additionally, we take the logarithm to stabilize the training:
where
is a term added for numerical stability; Re and Im denote the real part and the imaginary part of F(I)(a, b) respectively. Each point in the Fourier spectrum would utilize information from all pixels according to the discrete spatial frequency, which would represent the frequency features in the global level.
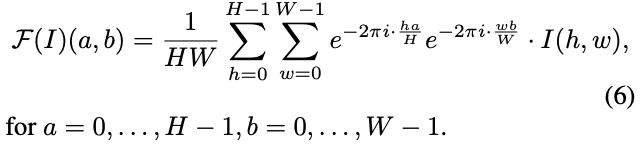

从像素空间到傅里叶频谱空间的变换
除了像素空间约束之外,本文还引入了直接作用于傅里叶域空间的损失项。
使用快速傅里叶变换 (FFT),将 x 从像素空间映射到傅里叶频谱空间。将离散傅里叶变换 F 应用于尺寸为 H × W 的真实二维图像 I,即公式(6)。
为了便于后期处理,将 F 从复数域转换为实数域。另外,本文使用对数来稳定训练,即公式(7)。其中,![]() 为数值稳定性增加的项; Re 和 Im 分别表示 F(I)(a, b) 的实部和虚部。傅里叶频谱中的每个点将根据离散的空间频率利用来自所有像素的信息,这将代表全局水平的频率特征。
为数值稳定性增加的项; Re 和 Im 分别表示 F(I)(a, b) 的实部和虚部。傅里叶频谱中的每个点将根据离散的空间频率利用来自所有像素的信息,这将代表全局水平的频率特征。
Reconstruction loss in the Fourier space
We then regulate the reconstruction loss in the frequency spectrum:
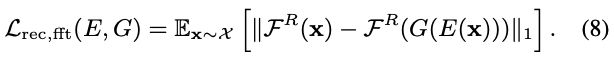
傅里叶空间的重构损失
然后调节频谱中的重构损耗为(8)。
Translation matching loss in the Fourier space
In a similar spirit as Equation 5, we devise a translation matching loss in the Fourier frequency domain:
where
. M_H is the frequency mask, for which we provided detailed explanation below. The loss constrains the high frequency components of the generated images for better identity preserving.
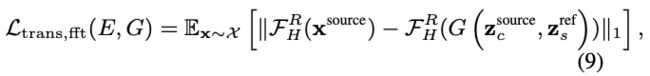
傅里叶空间中的平移匹配损失
与式 5 类似,傅里叶频域设计一个平移匹配损失(9)。
式中 ![]() 。M_H 是频率 mask,在下面详细说明。
。M_H 是频率 mask,在下面详细说明。
损失约束了生成图像的高频成分,以更好地保持身份。
Frequency mask
As illustrated in Figure 3, the low-frequency mask is a circle with radius r, whereas the high-frequency mask is the complement region. The frequency masks M_H and M_L can be estimated empirically from the distribution of F^R on the entire training dataset. We choose the radius to be 21 for images with resolution 256×256. The energy within the low-frequency mask accounts for 97.8% of the total energy in the spectrum.

如图 3 所示,低频 mask 是一个半径为 r 的圆,而高频 mask 是其补区域。频率掩模 M_H 和 M_L 可以从 F^R在整个训练数据集上的分布进行经验估计。对于分辨率为 256×256 的图像,本文选择半径为 21。低频掩模内的能量占频谱总能量的 97.8%。
3.3. Overall Loss
Considering all the aforementioned losses, the overall loss is formalized as:
where Lorg is the orginal loss function of any image translation model. For simplicity, we use λ1 = λ2 = λ3 = λ4 = 1 in this paper.
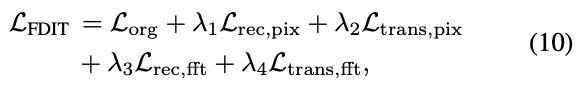
综合上述所有损失,整体损失的形式为 (10)。
其中,L_org 为任意图像平移模型的原始损失函数。为简便起见,本文采用 λ1 = λ2 = λ3 = λ4 = 1。
Gaussian kernel vs. FFT
Gaussian kernel and FFT are complementary for preserving the frequency information.
On one hand, the Gaussian kernel extracts the frequency information via the convolution, therefore representing the frequency features in a local manner.
On the other hand, Fast Fourier Transformation utilizes the information from all pixels to obtain the FFT value for each spatial frequency, characterizing the frequency distribution globally.
Gaussian kernel and FFT are therefore complementary in preserving the frequency information. We show ablation study on this in Section 4.2, where both are effective in enhancing the identity-preserving capability for image translation tasks.
高斯核和 FFT 是互补的,以保持频率信息。
一方面,高斯核通过卷积提取频率信息,以局部方式表示频率特征;
另一方面,快速傅里叶变换利用来自所有像素的信息,得到每个空间频率的 FFT 值,表征全局频率分布。
因此,高斯核和 FFT 在保留频率信息方面是互补的。本文将在 4.2 节对此进行消融研究,这两种方法都能有效地增强图像翻译任务的 identity 保持能力。
Gaussian kernel size
When transforming the images in Figure 2 into the spectrum space, the effects of the Gaussian kernel size could be clearly reflected in Figure 4. To be specific, a large kernel would cause severe distortion on the low-frequency band while a small kernel would not preserve much of the high-frequency information. In this work, we choose the kernel size k = 21 for images with resolution 256×256, which could appropriately separate the high/lowfrequency information, demonstrated in both image space and spectral space distribution. Our experiments also show that FDIT is not sensitive to the selection of k as long as it falls into a mild range.
将图 2 中的图像转换到谱空间时,高斯核大小的影响可以在图 4 中清晰地体现出来。具体来说,大的核会在低频带上造成严重的失真,而小的核不会保留很多高频信息。在本工作中,对于分辨率为 256×256 的图像,我们选择的核大小为 k = 21,可以适当地分离高/低频信息,在图像空间和频谱空间分布上都表现出来。实验也表明,FDIT 对 k 的选择并不敏感,只要它在一个温和的范围内。
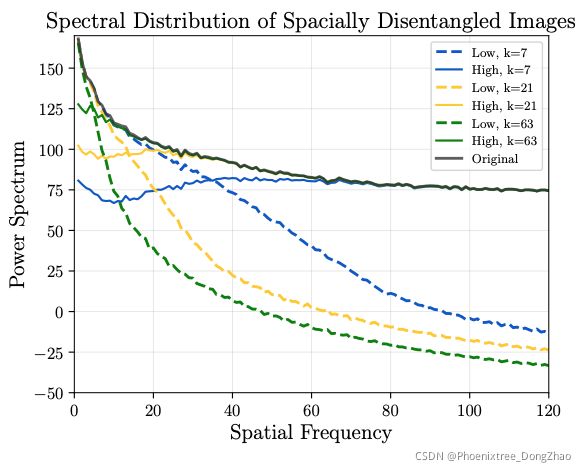
Figure 4: Transforming the resulting high- and low-frequency images in Figure 2 into the frequency power spectrum. The Gaussian kernel with kernel size k = 21 could avoid the distortion in high-frequency and low-frequency regions. The power spectrum represents the energy distribution at each spatial frequency.
4. Experiments
In this section, we evaluate our proposed method on two state-of-the-art image translation architectures, i.e., Swapping Autoencoder [48], StarGAN v2 [11], and one GAN inversion model, i.e., Image2StyleGAN [1]. Extensive experimental results show that FDIT not only better preserves the identity, but also enhances image quality.
在本节中,在两个最先进的图像转换架构上评估提出的方法,即 Swapping 自编码器[48],StarGAN v2 [11],以及一个 GAN 反转模型 Image2StyleGAN [1]。大量的实验结果表明,FDIT不仅能更好地保持图像的一致性,而且能提高图像质量。
[48] Swapping Autoencoder for Deep Image Manipulation NeurIPS 2020
pytorch

[11] StarGAN v2: Diverse Image Synthesis for Multiple Domains CVPR 2020
pytorch
[1] Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space? ICCV 2019
pytoch


Image2StyleGAN++: How to Edit the Embedded Images?


Datasets
We evaluate FDIT on the following five datasets: (1) LSUN Church [65], (2) CelebA-HQ [34], (3) LSUN Bedroom [65], (4) Flickr Mountains (100k selfcollected images), (5) Flickr Waterfalls (100k self-collected images). (6) Flickr Faces HQ (FFHQ) dataset [35]. All the images are trained and tested at 256 × 256 resolution except FFHQ, which is trained at 512 × 512, and finetuned at 1024 × 1024 resolution. For evaluation, we use a validation set that is separate from the training data.
本实验评估了以下 5 个数据集:
(1) LSUN Church(官网) [65], (2) CelebA-HQ (知乎链接) [34], (3) LSUN Bedroom(github) [65], (4) Flickr Mountains (100k self-collected images), (5) Flickr Waterfalls (100k self-collected images)。(6) Flickr Faces HQ (FFHQ) 数据集[35]。所有图像都在 256 × 256 分辨率下进行训练和测试,FFHQ 在 512 × 512 分辨率下进行训练,在1024 × 1024分辨率下进行微调。为了进行评估,我们使用一个与训练数据分离的验证集。
[35] A style-based generator architecture for generative adversarial networks. CVPR 2019.
[65] LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
4.1. Autoencoder
Autoencoder is widely used as the backbone of the deep image translation task [1, 27]. We use state-of-the-art Swapping Autoencoder (SwapAE) [48], which is built on the backbone of StyleGAN2 [36]. Swap AE also uses the technique in PatchGAN [31] to further improve the texture transferring performance. We incorporate our proposed FDIT training objectives into the vanilla SwapAE.
自编码器作为深度图像翻译任务的 backbone 被广泛使用 [1,27]。本文使用最先进的 Swapping 自编码器 (SwapAE) [48],它构建在 StyleGAN2 [36] 的 backbone 上。Swap AE 也使用 PatchGAN [31] 中的技术来进一步提高纹理传输性能。本文将提出的 FDIT 训练目标纳入 vanilla SwapAE。
4.1.1 Reference-guided Image Synthesis
FDIT better preserves the identity with respect to the source image
We contrast the image translation performance using FDIT vs. vanilla SwapAE in Figure 1 and Figure 5. The vanilla SwapAE is unable to preserve the important identity of the source images, and over-adapts to the reference image. For example, the face identity is completely switched after translation, as seen in rows 4 of Figure 5. SwapAE also fails to preserve the outline and the local sharp edges in the source image. As shown in Figure 1, the outlines of the mountains are severely distorted. Besides, the overall image composition has a large shift from the original source image.
In contrast, using our method FDIT, the identity and structure of the swapped hybrid images are highly preserved. As shown in Figure 1 and Figure 5, the overall sketches and local fine details are well preserved while the coloring, illumination, and even the weather are well transferred from the reference image (top rows of Figure 1).
Lastly, we compare FDIT with the state-of-the-art image stylization method STROTSS [38] and WCT2 [63]. Image stylization is a strong baseline as it emphasizes on the strict adherence to the source image. However, as shown in Figure 5, WCT2 leads to poor transferability in image generation tasks. Despite strong identity-preservation, STROTSS and WCT2 are less flexible, and generate images that highly resemble the source image. In contrast, FDIT can both preserve the identity of the source image as well as maintain a high transfer capability. This further demonstrates the superiority of FDIT in image translation.
FDIT 较好地保留了相对于源图像的 identity
在图 1 和图 5 中,对比了使用 FDIT 和 SwapAE 的图像转换性能。SwapAE 无法保持源图像的重要 identity,对参考图像过度适应。例如,翻译后的人脸身份完全切换,如图 5 的第 4 行所示。SwapAE 也不能保持源图像中的轮廓和局部锐利边缘。如图 1 所示,山脉的轮廓被严重扭曲。此外,整体的图像构成与原始源图像有较大的偏移。
相比之下,采用 FDIT 方法,交换后的混合图像的 identity 和结构得到了很好的保留。如图 1 和图 5 所示,整体草图和局部精细细节得到了很好的保存,而色彩、照明甚至天气都很好地从参考图像 (图1顶部的行) 转移。
最后,比较了 FDIT 与最先进的图像程式化方法 STROTSS [38] 和 WCT2 [63]。图像风格化是一个强大的 baseline,因为它强调严格遵守源图像。然而,如图 5 所示,WCT2 导致图像生成任务的可移植性较差。尽管 STROTSS 和 WCT2 具有很强的 identity 保存功能,但它们的灵活性较差,并且生成的图像与源图像高度相似。相比之下,FDIT 既能保持源图像的 identity,又能保持较高的传输能力。这进一步证明了 FDIT 在图像翻译中的优越性。
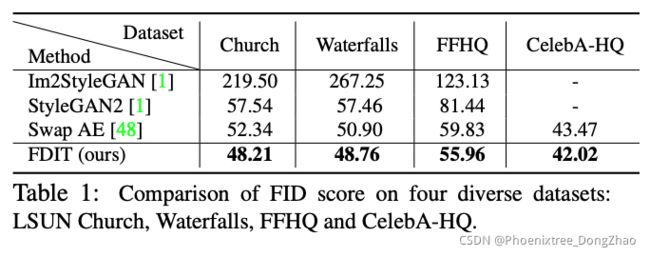
FDIT enhances the image generation quality
We show in Table 1 that FDIT can substantially improve the image quality while preserving the image content. We adopt the Frechet Inception Distance (FID) [23] as the measure of image quality. Small values indicate better image quality. Details about Im2StyleGAN [1] and StyleGAN2 [1] are shown in the supplementary material. FDIT achieves the lowest FID across all datasets. On average, FDIT could reduce the FID score by 5.6% compared to the current state-of-the-art method.
FDIT 提高了图像生成的质量
从表 1 中可以看出,FDIT 可以在保留图像内容的同时显著提高图像质量。本文采用 Frechet Inception Distance (FID) [23] 作为图像质量的度量。数值越小,图像质量越好。Im2StyleGAN [1]和 StyleGAN2 的详细信息在补充材料中显示。FDIT 在所有数据集中实现了最低的 FID。与目前最先进的方法相比,FDIT 平均可以降低 5.6% 的 FID 评分。
4.1.2 Image Attributes Editing
FDIT enables continuous interpolation between different domains
We show that FDIT enables image attribute editing task, which creates a series of smoothly changing images between two sets of distinct images [48, 51]. Vector arithmetic is one commonly used way to achieve this [51]. For example, we can sample n images from each of the two target domains, and then compute the average difference of the vectors between these two sets of images:
where ,
denote the latent code from two domains.
We perform interpolation on the style code while keeping the content code unchanged. The generated images can be formalized as
, where θ is the interpolation parameter. We show results on CelebAHQ dataset in Supplementary material. FDIT performs image editing towards the target domain while strictly adhering to the content of the source image. Compared to the vanilla Swapping Autoencoder and StarGAN v2, our results demonstrate the better disentanglement ability of unique image attributes and identity characteristics. We also verify the disentangled semantic latent vectors using Principal Component Analysis (PCA). The implementation details and the identity-preserving results are shown in the supplementary materials.
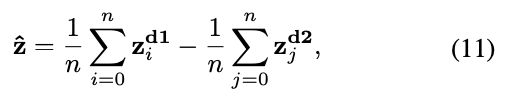
FDIT 允许不同域之间的连续插值
FDIT 可以实现图像属性编辑任务,在两组不同的图像之间创建一系列平滑变化的图像。向量算法是实现 [51] 的一种常用方法。例如,我们可以从两个目标域中分别抽取 n 幅图像,然后计算两组图像之间向量的平均差值,如公式(11)。
其中 , ![]() 为两个域的 latent code 。
为两个域的 latent code 。
在保持内容代码不变的同时对样式代码执行插值。生成的图像可以形式化为![]() ,其中 θ 为插值参数。
,其中 θ 为插值参数。
在补充材料中显示了 CelebAHQ 数据集的结果。
FDIT 对目标域执行图像编辑,同时严格遵守源图像的内容。与 vanilla swap Autoencoder 和 StarGAN v2 相比,FDIT 的结果显示了更好的图像属性和 identity 特征的解耦能力。
本文还利用主成分分析 (PCA) 验证了解耦的语义潜在向量。实现细节和身份保持结果在补充材料中显示。
4.2. Ablation Study
Pixel and Fourier space losses are complementary
To better understand our method, we isolate the effect of pixel space loss and Fourier spectral space loss. The results on the LSUN Church dataset are summarized in Table 2. The vanilla SwapAE is equivalent to having neither loss terms, which yields the FID score of 52.34. Using pixel space frequency loss reduces the FID score to 49.47. Our method is most effective when combining both pixel-space and Fourier-space loss terms, achieving the FID score of 48.21. Our ablation signifies the importance of using frequencybased training objectives.
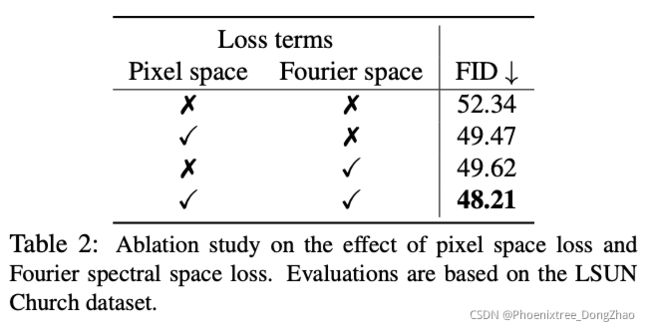
消融实验:像素和傅里叶空间损失是互补的
为了更好地理解本文的方法,本文分离了像素空间损失和傅里叶频谱空间损失的影响。LSUN Church 数据集上的结果如表 2 所示。SwapAE 相当于没有损失项,其 FID 得分为 52.34。使用像素空间频率损失将 FID 评分降低到 49.47。当结合像素空间和傅里叶空间的损失项时,FDIT 方法是最有效的,达到 48.21 分。消融表明了使用基于频率的训练目标的重要性。
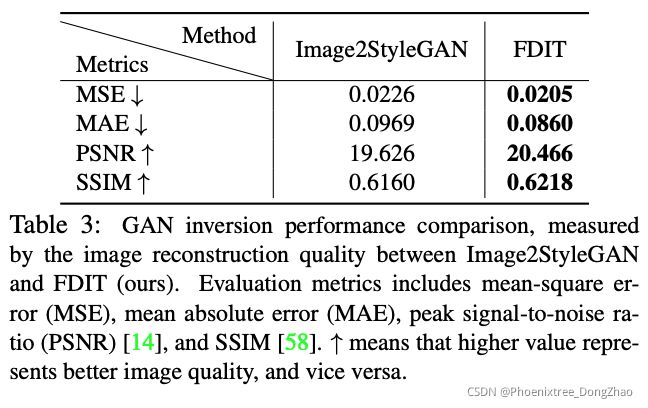
4.3. GAN Inversion
FDIT improves reconstruction quality in GAN inversion
We evaluate the efficacy of FDIT on the GAN inversion task, which maps the real images into the noise latent vectors. In particular, Image2StyleGAN[1] serves as a strong baseline, which performs reconstruction between the real image and the generated images via iterative optimization over the latent vector.
We adopt the same architecture, however impose our frequency-based reconstruction loss. The inversion results are shown in Figure 6. On high-resolution (1024 × 1024) images, the quality of the inverted images is improved across all scenes. FDIT better preserves the overall structure, fine details, and color distribution. We further measure the performance quantitatively, summarizing the results in Table 3. Under different metrics (MSE, MAE, PSNR, SSIM), our method FDIT outperforms Image2StyleGAN.
FDIT 提高了 GAN 反演的重建质量
本文评价了 FDIT 在 GAN 反演任务中的有效性,该任务将真实图像映射到噪声潜在向量中。特别是 Image2StyleGAN[1] 作为一个强 baseline,通过对潜在向量的迭代优化,在真实图像和生成图像之间进行重构。
本文采用相同的架构,但是会造成基于频率的重构损失。反演结果如图 6 所示。在高分辨率 (1024 × 1024) 图像上,所有场景的倒立图像质量都得到了改善。FDIT 更好地保留了整体结构、细节和颜色分布。
进一步定量地度量性能,总结表 3 中的结果。在不同的度量 (MSE, MAE, PSNR, SSIM) 下,FDIT 方法的性能优于 Image2StyleGAN 方法。

4.4. StarGAN v2
StarGAN v2 is another state-of-the-art image translation model which can generate image hybrids guided by either reference images or latent noises. Similar to the autoencoder-based network, we can optimize the StarGAN v2 framework with our frequency-based losses. In order to validate FDIT in a stricter condition, we construct a CelebA-HQ-Smile dataset based on the smiling attribute from CelebA-HQ dataset. The style refers to whether that person smiles, and the content refers to the identity. Several salient observations can be drawn from Figure 7.
First, FDIT can highly preserve the gender identity; whereas the vanilla StarGAN v2 model would change the resulting gender according to the reference image (e.g. first and second row).
Secondly, the image quality of FDIT is better, where FID is improved from 17.32 to 16.86.
Thirdly, our model can change the smiling attribute while maintaining other facial features strictly. For example, as shown in the third row, StarGAN v2 undesirably changes the hairstyle from straight (source) to curly (reference), whereas FDIT maintains the same hairstyle.

StarGAN v2 是另一种先进的图像转换模型,它可以在参考图像或潜在噪声的引导下生成图像混合。与基于自动编码器的网络类似,可以用基于频率的损失优化 StarGAN v2 框架。为了在更严格的条件下验证 FDIT,基于 CelebA-HQ 数据集的 smile 属性构建了一个 CelebA-HQ - Smile 数据集。风格是指那个人是否微笑,内容是指 identity。从图 7 可以得出几个显著的观察结果。
第一,FDIT 可以高度保护性别认同;而 StarGAN v2 模型会根据参考图像 (例如第一行和第二行) 改变结果性别。
其次,FDIT 的图像质量较好,FID 从 17.32 提高到 16.86。
第三,FDIT 模型可以在严格保持其他面部特征的同时改变微笑属性。例如,如第三行所示,StarGAN v2 不希望将发型从直 (来源) 更改为卷曲 (参考),而 FDIT 保持相同的发型。