点云处理:PointNet分割任务
项目说明
①数据集
本次用到的数据集是ShapeNet(16881个形状,50种零件)储存格式是.h5文件。
.h5储存的key值分别为:
1、data:这一份数据中所有点的xyz坐标,
2、label:这一份数据所属类别,如airplane等,
3、pid:这一份数据中所有点所属的类型,如这一份数据属airplane类,则它包含的所有点的类型有机翼、机身等类型。
!unzip data/data67117/shapenet_part_seg_hdf5_data.zip
!mv hdf5_data dataset②PointNet简介
一、PointNet是斯坦福大学研究人员提出的一个点云处理网络,与先前工作的不同在于这一网络可以直接输入无序点云进行处理,而无序将数据处理成规则的3Dvoxel形式进行处理。输入点云顺序对于网络的输出结果没有影响,同时也可以处理旋转平移后的点云数据。
二、几个重要的知识点:
1、将点云体素化会改变点云数据的原始特征,造成不必要的数据损失,并且额外增加了工作量,而 PointNet 采用了原始点云的输入方式,最大限度地保留了点云的空间特征,并在最终的测试中取得了很好的效果。
2、基本思想:对输入点云中的每一个点学习其对应的空间编码,之后再利用所有点的特征,得到一个全局的点云特征。
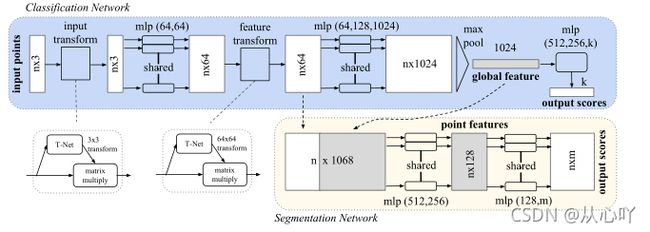
3、第一次input transform(T-Net)是对空间中点云进行调整,直观上理解是旋转出一个有利于分类或分割的角度(点云的刚性变化),第二次feature transform(T-Net)是对提取出的特征进行变换,类似点的刚性变化,想利用这个得到一个有利于分类的特征角度。
4、分割任务的完成:将n * 64局域特征和 1024 维的全局特征结合在一起进行融合,在每一个点的 64 维特征后接续 1024 全局特征,随后利用一个 mlp(512,512,128) 对n ∗ 1088维的特征维度进行学习,生成n ∗ 128的向量,再利用 (128,m) 的感知机对最后的特征进行分类(分割任务实质上是对点进行分类)从而完成分割任务。
5、分割任务依赖于点云中点与点之间的位置关系,所以输入点的xyz入网络,充分挖掘点坐标之间的关系进行分割。
三、网络结构:
项目主体
①导入需要的库
import os
import numpy as np
import random
import h5py #对h5文件进行读写操作的Ptython包
import paddle
import paddle.nn.functional as F
from paddle.nn import Conv2D, MaxPool2D, Linear, BatchNorm, Dropout, ReLU, Softmax, Sequential②数据处理
1、生成训练和测试样本的list
train_list = ['ply_data_train0.h5', 'ply_data_train1.h5', 'ply_data_train2.h5', 'ply_data_train3.h5', 'ply_data_train4.h5', 'ply_data_train5.h5']
test_list = ['ply_data_test0.h5', 'ply_data_test1.h5']
val_list = ['ply_data_val0.h5']补充注释:
h5是HDF5文件格式的后缀。
h5文件中有两个核心的概念:组“group”和数据集“dataset”。
dataset :简单来讲类似数组组织形式的数据集合,像 numpy 数组一样工作,一个dataset即一个numpy.ndarray。具体的dataset可以是图像、表格,甚至是pdf文件和excel。
group:包含了其它 dataset(数组) 和 其它 group ,像字典一样工作。
一个h5文件被像linux文件系统一样被组织起来:dataset是文件,group是文件夹,它下面可以包含多个文件夹(group)和多个文件(dataset)。
# Reading h5 file
import h5py
with h5py.File('cat_dog.h5',"r") as f:
for key in f.keys():
#print(f[key], key, f[key].name, f[key].value) # 因为这里有group对象它是没有value属性的,故会异常。另外字符串读出来是字节流,需要解码成字符串。
print(f[key], key, f[key].name) # f[key] means a dataset or a group object. f[key].value visits dataset' value,except group object.
"""
结果:
dogs /dogs
list_classes /list_classes
train_set_x /train_set_x
train_set_y /train_set_y
代码解析:
文件对象f它表示h5文件的根目录(root group),前面说了group是按字典的方式工作的,通过f.keys()来找到根目录下的所有dataset和group的key,然后通过key
来访问各个dataset或group对象。
结果解析:
1.我们可以发现这个h5文件下有1个叫dogs的文件夹(group)和3个文件(dataset)它们分别叫list_classes,train_set_x,train_set_y它们的shape都可知。
dogs group下有一个成员但我们不知道它是group还是dataset。
2.我们可以发现key和name的区别:
上层group对象是通过key来访问下层dataset或group的而不是通过name来访问的;
因为name属性它是dataset或group的绝对路径并非是真正的"name",key才是真正的"name"。
name绝对路径:比如下文中访问name得到:/dogs/husky,它表示根目录下有dogs这个挂载点,dogs下又挂载了husky。
"""
dogs_group = f["dogs"]
for key in dogs_group.keys():
print(dogs_group[key], dogs_group[key].name)
"""
结果:
/dogs/husky
可见dogs文件夹下有个key为husky的文件dataset
"""
2、数据读取
def pointDataLoader(mode='train'):
path = './dataset/'
BATCHSIZE = 64
MAX_POINT = 1024
datas = []
labels = []
if mode == 'train':
for file_list in train_list:
f = h5py.File(os.path.join(path, file_list), 'r') #例如./dataset/ply_data_train0.h5,
#读取h5文件
#for key in f.keys():
#print("aaaaaaaaaaaaaaaaaaaaaaaa")
#print(f[key], key, f[key].name)
#break
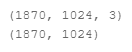
datas.extend(f['data'][:, :1024, :]) #(2048,1024,3)的列表
labels.extend(f['pid'][:, :1024]) #(2048,1024)的列表
f.close()
elif mode == 'test':
for file_list in test_list:
f = h5py.File(os.path.join(path, file_list), 'r')
datas.extend(f['data'][:, :1024, :])
labels.extend(f['pid'][:, :1024])
f.close()
else:
for file_list in val_list:
f = h5py.File(os.path.join(path, file_list), 'r')
datas.extend(f['data'][:, :1024, :])
labels.extend(f['pid'][:, :1024])
f.close()
datas = np.array(datas)
labels = np.array(labels)
index_list = list(range(len(datas)))
def pointDataGenerator():
if mode == 'train':
random.shuffle(index_list)
datas_list = []
labels_list = []
for i in index_list:
data = np.reshape(datas[i], [1, 1024, 3]).astype('float32')
label = np.reshape(labels[i], [1024]).astype('int64')
datas_list.append(data)
labels_list.append(label)
if len(datas_list) == BATCHSIZE: #64个样本为一批
#print(np.array(datas_list).shape) #(64,1,1024,3)
#print(np.array(labels_list).shape) #(64,1024)
yield np.array(datas_list), np.array(labels_list)
datas_list = []
labels_list = []
if len(datas_list) > 0:
yield np.array(datas_list), np.array(labels_list)
return pointDataGenerator
补充注释:
1.
for key in f.keys():
print("aaaaaaaaaaaaaaaaaaaaaaaa")
print(f[key], key, f[key].name)aaaaaaaaaaaaaaaaaaaaaaaadata /data aaaaaaaaaaaaaaaaaaaaaaaa label /label aaaaaaaaaaaaaaaaaaaaaaaa pid /pid
np.array(datas) np.array(labels)的维度变化情况:
训练时:

测试时:

预测时:
2.extend() 函数用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)。
③定义网络
1、定义网络
class PointNet(paddle.nn.Layer):
def __init__(self, name_scope='PointNet_', num_classes=50, num_point=1024):
super(PointNet, self).__init__()
self.num_point = num_point
self.input_transform_net = Sequential(
Conv2D(1, 64, (1, 3)),
BatchNorm(64),
ReLU(),
Conv2D(64, 128, (1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, 1024, (1, 1)),
BatchNorm(1024),
ReLU(),
MaxPool2D((num_point, 1))
)
self.input_fc = Sequential(
Linear(1024, 512),
ReLU(),
Linear(512, 256),
ReLU(),
Linear(256, 9,
weight_attr=paddle.framework.ParamAttr(initializer=paddle.nn.initializer.Assign(paddle.zeros((256, 9)))),
bias_attr=paddle.framework.ParamAttr(initializer=paddle.nn.initializer.Assign(paddle.reshape(paddle.eye(3), [-1])))
)
)
self.mlp_1 = Sequential(
Conv2D(1, 64, (1, 3)),
BatchNorm(64),
ReLU(),
Conv2D(64, 64,(1, 1)),
BatchNorm(64),
ReLU(),
)
self.feature_transform_net = Sequential(
Conv2D(64, 64, (1, 1)),
BatchNorm(64),
ReLU(),
Conv2D(64, 128, (1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, 1024, (1, 1)),
BatchNorm(1024),
ReLU(),
MaxPool2D((num_point, 1))
)
self.feature_fc = Sequential(
Linear(1024, 512),
ReLU(),
Linear(512, 256),
ReLU(),
Linear(256, 64*64)
)
self.mlp_2 = Sequential(
Conv2D(64, 64, (1, 1)),
BatchNorm(64),
ReLU(),
Conv2D(64, 128,(1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, 1024,(1, 1)),
BatchNorm(1024),
ReLU(),
)
self.seg_net = Sequential(
Conv2D(1088, 512, (1, 1)),
BatchNorm(512),
ReLU(),
Conv2D(512, 256, (1, 1)),
BatchNorm(256),
ReLU(),
Conv2D(256, 128, (1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, 128, (1, 1)),
BatchNorm(128),
ReLU(),
Conv2D(128, num_classes, (1, 1)),
Softmax(axis=1)
)
def forward(self, inputs): #(64,1,1024,3)
batchsize = inputs.shape[0]
t_net = self.input_transform_net(inputs) #(64,1024,1,1)
t_net = paddle.squeeze(t_net) #(64,1024)
t_net = self.input_fc(t_net) #(64,9)
t_net = paddle.reshape(t_net, [batchsize, 3, 3])#(64,3,3)
x = paddle.squeeze(inputs)#(64,1024,3)
x = paddle.matmul(x, t_net)#(64,1024,3)
x = paddle.unsqueeze(x, axis=1)#(64,1,1024,3)
x = self.mlp_1(x) #(64,64,1024,1)
t_net = self.feature_transform_net(x)#(64,1024,1,1)
t_net = paddle.squeeze(t_net)#(64,1024)
t_net = self.feature_fc(t_net) #(64,64*64)
t_net = paddle.reshape(t_net, [batchsize, 64, 64])#(64,64,64)
x = paddle.squeeze(x)#(64,64,1024)
x = paddle.transpose(x, (0, 2, 1))#(64,1024,64)
x = paddle.matmul(x, t_net)#(64,1024,64)
x = paddle.transpose(x, (0, 2, 1))#(64,64,1024)
x = paddle.unsqueeze(x, axis=-1)#(64,64,1024,1)
point_feat = x #点的局部特征
x = self.mlp_2(x) #(64,1024,1024,1)
x = paddle.max(x, axis=2) #(64,1024,1)#全局特征
global_feat_expand = paddle.tile(paddle.unsqueeze(x, axis=1),
[1, self.num_point, 1, 1]) #(64,1024,1024,1)
x = paddle.concat([point_feat, global_feat_expand], axis=1)#(64,1088,1024,1)
x = self.seg_net(x)#(64,50,1024,1)
x = paddle.squeeze(x, axis=-1) #(64,50,1024)
x = paddle.transpose(x, (0, 2, 1)) #(64,1024,50)
return x补充注释:
1.paddle.tile(x, repeat_times, name=None)
根据参数 repeat_times 对输入 x 的各维度进行复制。 平铺后,输出的第 i 个维度的值等于 x.shape[i]*repeat_times[i] 。
2、模型结构可视化
pointnet = PointNet()
paddle.summary(pointnet, (64, 1, 1024, 3))⑤训练
def train():
train_loader = pointDataLoader(mode='train')
model = PointNet()
model.train()
optim = paddle.optimizer.Adam(parameters=model.parameters(), weight_decay=0.001)
loss_fn = paddle.nn.CrossEntropyLoss()
epoch_num = 200
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
inputs = paddle.to_tensor(data[0])
#print(data[0].shape) #(64,1,1024,3)
labels = paddle.to_tensor(data[1])
#print(data[1].shape) #(64,1024)
predicts = model(inputs)
loss = loss_fn(predicts, labels)
#print("ggggggggggggggggggggggg")
#print((paddle.argmax(predicts, axis=-1)).shape) #(64,1024)
#mean_iou第一项维度为(64,1024,1),第二项也为(64,1024,1)
miou, _, _ = paddle.fluid.layers.mean_iou(paddle.unsqueeze(paddle.argmax(predicts, axis=-1), axis=-1), paddle.unsqueeze(labels, axis=-1), 50)
loss.backward()
if batch_id % 100 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, miou is: {}".format(epoch, batch_id, loss.numpy(), miou.numpy()))
optim.step()
optim.clear_grad()
if epoch % 20 == 0:
paddle.save(model.state_dict(), './model/PointNet.pdparams')
paddle.save(optim.state_dict(), './model/PointNet.pdopt')
if __name__ == '__main__':
train()⑥评估
def evaluation():
test_loader = pointDataLoader(mode='test')
model = PointNet()
model_state_dict = paddle.load('./model/PointNet.pdparams')
model.load_dict(model_state_dict)
for batch_id, data in enumerate(test_loader()):
inputs = paddle.to_tensor(data[0])
labels = paddle.to_tensor(data[1])
predicts = model(inputs)
loss = F.cross_entropy(predicts, labels)
miou, _, _ = paddle.fluid.layers.mean_iou(paddle.unsqueeze(paddle.argmax(predicts, axis=-1), axis=-1), paddle.unsqueeze(labels, axis=-1), 50)
# 打印信息
if batch_id % 100 == 0:
print("batch_id: {}, loss is: {}, miou is: {}".format(batch_id, loss.numpy(), miou.numpy()))
if __name__ == '__main__':
evaluation()⑦预测
1、可视化预测样本
zdata = []
xdata = []
ydata = []
label = []
f = h5py.File('./dataset/ply_data_val0.h5','r')
for i in f['data'][0]:#(1024,3)
xdata.append(i[0])
ydata.append(i[1])
zdata.append(i[2])
for i in f['pid'][0]:#(1024)
label.append(i)
f.close()
map_color = {0:'r', 1:'g', 2:'b', 3:'y'}
Color = list(map(lambda x: map_color[x], label))#让不同类别的点绘制为不同颜色。
xdata = np.array(xdata)
ydata = np.array(ydata)
zdata = np.array(zdata)
from mpl_toolkits import mplot3d
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
ax = plt.axes(projection='3d')#创建三维坐标轴
ax.scatter3D(xdata, ydata, zdata, c=Color)#3D散点图,c为颜色
plt.show()补充注释:
1. lambda x(传入的参数):要执行的语句(这条语句执行完之后,就会返回一个值,也就是函数的返回值)
2、开始预测
def test():
test_loader = pointDataLoader(mode='val')
model = PointNet()
model_state_dict = paddle.load('./model/PointNet.pdparams')
model.load_dict(model_state_dict)
for batch_id, data in enumerate(test_loader()):
predictdata = paddle.to_tensor(data[0]) #(64,1,1024,3)
label = paddle.to_tensor(data[1]) #(64,1024)
predict = model(predictdata)#(64,1024,50)
# print(np.argmax(predict[0].numpy(), 1).shape) #(1024)
break
zdata = []
xdata = []
ydata = []
label = []
for i in data[0][0][0]:#(1024,3)
xdata.append(i[0])
ydata.append(i[1])
zdata.append(i[2])
for i in np.argmax(predict[0].numpy(), 1):#(1024)
label.append(i)
f.close()
map_color = {0:'r', 1:'g', 2:'b', 3:'y'}
Color = list(map(lambda x: map_color[x], label))
xdata = np.array(xdata)
ydata = np.array(ydata)
zdata = np.array(zdata)
from mpl_toolkits import mplot3d
%matplotlib inline
import matplotlib.pyplot as plt
ax = plt.axes(projection='3d')
ax.scatter3D(xdata, ydata, zdata, c=Color)
plt.show()
if __name__ == '__main__':
test()