线性代数在数据科学中的十个强大应用(一)

来源 | AnalyticsVidhya译者 | 磐石
本篇主要介绍了机器学习与数据科学背后的数学技术十大应用之基础机器学习部分与降维部分。
概览
线性代数为各种各样的数据科学算法或应用提供支撑
我们将介绍十种强大的线性代数应用示例,他可以帮助你成为更好的数据科学家
我们将这些应用细分到各个领域--基础机器学习(ML),降维,自然语言处理(NLP)和计算机视觉(CV)
介绍
线性代数与数据科学的关系就像罗宾与蝙蝠侠。这位数据科学忠实的伙伴经常会被大家所忽视,但实际上,它是数据科学主要领域--包括计算机视觉(CV)与自然语言处理(NLP)等热门领域的强力支撑。
数据开发者往往会因为数学太难而尝试避开这个主题。因为有很多现成的数据处理库可以帮助他们避开线性代数这个烦恼。
这是极其错误的想法。线性代数是我们所熟知的所用强大机器学习算法的背后核心,同样是数据科学家技能的重要组成部分,接下来就让我们一起详细剖析下线性代数在数据科学中的强大应用。

在本文中,我会详细解释线性代数在数据科学中的十大应用。这些应用大致分为四个领域:
机器学习
降维
自然语言处理(NLP)
计算机视觉(CV)
另外每一个应用还为大家准备了相关的资源,以便感兴趣的同学更进一步了解。
目录:
为什么学习线性代数
机器学习中的线性代数
损失函数
正则化
协方差矩阵
支持向量机分类器
降维中的线性代数
主成分分析(PCA)
奇异值分解(SVD)
自然语言处理中的线性代数
词嵌入(Word Embeddings)
潜在语义分析
计算机视觉中的线性代数
图像用张量表示
卷积与图像处理
为什么学习线性代数
我也曾多次问过自己这个问题。当只需导入Python包就可以构建模型时,为什么还要花时间学习线性代数呢?我是这样认为的,线性代数是数据科学的基础之一,假如没有坚实的基础,就无法建造一栋真正的摩天大楼。比如:
当你希望使用主成分分析(PCA)来减少数据的维数时,如果你不知道算法的机制(数学原理),那么你就无法确定该怎样调整组件,以及会对数据产生什么影响。
通过对线性代数的理解,可以对机器学习和深度学习算法有更深一层的感悟,而不是将它们视为黑盒子。从而可以选择适当的超参数,建立更好的模型。
机器学习中的线性代数
最大的问题是,机器学习在什么地方需要线性代数?让我们看一下非常熟悉的四个应用。
1. 损失函数
你需要非常熟悉模型是如何拟合给定的数据(如线性回归模型):
从一些预测函数开始(线性回归模型的线性函数)
使用数据的独立特征预测输出
计算预测输出与实际结果的距离
使用Gradient Descent等策略根据距离优化预测函数
如何计算预测输出与实际结果的差异?损失函数。
损失函数是向量范数在线性代数中的应用。范数可以简单地说是向量的量纲。有许多类型的向量范数。
L1范数:也称为曼哈顿距离或Taxicab 范数。如果只允许行进方向与空间轴平行,从原点到矢量的距离,在L1范数的距离就是你行进的距离。
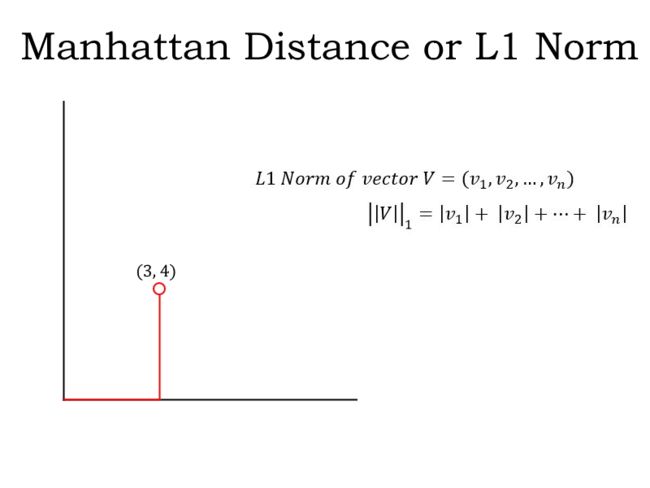
在这个2D空间中,您可以通过沿x轴行进3个单位然后沿y轴平行移动4个单位(如图所示)到达矢量(3,4)。或者您可以先沿y轴行进4个单位,然后沿x轴行进3个单位。在任何一种情况下,您将共旅行7个单位。
L2范数:也称为欧几里德距离。L2 范数是向量距原点的最短距离,如下图中的红色路径所示:
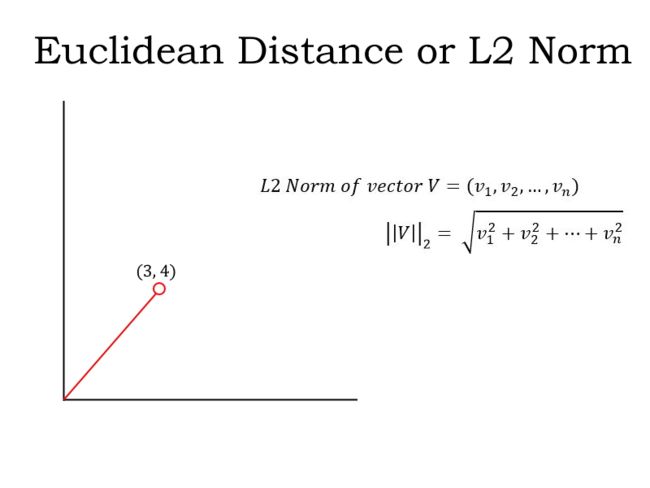
这个距离是用毕达哥拉斯定理计算的。它是![]() 的平方根,等于5。
的平方根,等于5。
但是,范数如何用于找出预测值与真实值之间的差异?假设预测值存储在向量P中,并且真实值存储在向量E中。P-E是它们之间的差异。P-E的范数就是预测的总损失。
2. 正则化
正则化是数据科学中非常重要的概念。它是用来防止模型过拟合的方法。正则化实际上是规范化的另一种应用。
如果模型在训练时发生了过拟合,模型就会对新数据的预测结果不好,因为模型甚至学习了训练数据中的噪声。它无法预测之前没有训练过的数据。下面的图片揭示了这个思想:
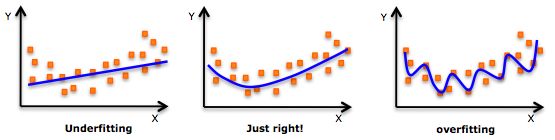
正则化通过向损失函数添加权重向量来惩罚过于复杂的模型。由于我们希望最小化成本函数,因此需要最小化此范数。正则化的结果是权重向量中无关紧要的部分变为零,防止预测函数过于复杂。
我们上面讨论的L1和L2范数用于两种类型的正则化:
L1正则化与Lasso 回归一起使用
L2正则化与Ridge 回归一起使用
3. 协方差矩阵
双变量分析是数据探索中的重要一步。我们想研究变量对之间的关系。协方差或相关性是用于研究两个连续变量之间关系的度量。
协方差表示变量之间线性关系的方向。正协方差表示一个变量的增加或减少在另一个变量中同样增加或减少。负协方差表明一个变量的增加或减少同时另一个变量与它相反。

另一方面,相关性是协方差的标准化值。 相关性值告诉我们线性关系的强度和方向,范围从-1到1。
您可能会认为这是统计学而非线性代数的概念。好吧,记得我告诉过你线性代数是无处不在的吗?使用线性代数中的转置和矩阵乘法的概念,协方差矩阵有一个非常简洁的表达式:

其中X是包含所有数字特征的标准化数据矩阵。
4. 支持向量机分类器
支持向量机(SVM)是最常见的分类算法之一,经常产生令人印象深刻的结果。它是向量空间概念在线性代数中的应用。
支持向量机是一种判别分类器,通过查找决策面来工作。它是一种有监督的机器学习算法。
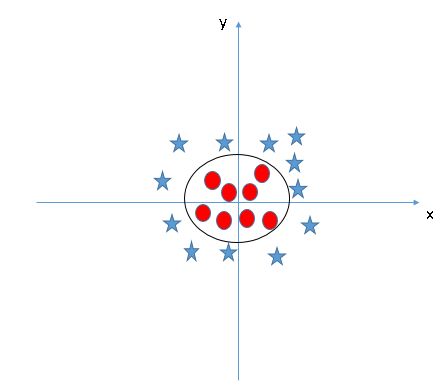
在此算法中,我们将每个数据项绘制为n维空间中的点(其中n是特征数),每个特征的值是特定坐标的值。然后,通过找到最好的区分两个类的超平面来进行分类,即最大余量,下面的例子中是C.

超平面是一个子空间,其维数比其对应的向量空间小1,因此它是2D向量空间的直线,3D向量空间的2D平面等等。使用向量范数来计算边界。
但是,如果数据像下面的情况那样该怎样线性分离呢?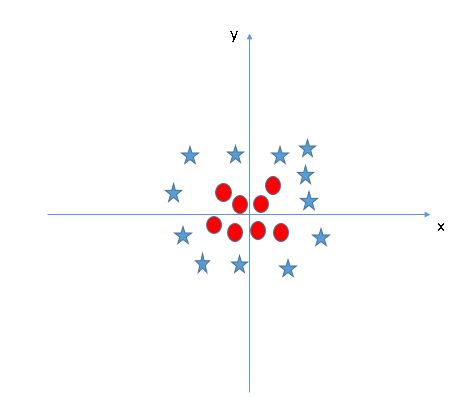
我们一般认为决策面必须是圆形或椭圆形,但怎么找到它?这里,使用了内核转换的概念。在线性代数中,从一个空间转换到另一个空间的想法非常普遍。
让我们介绍一个变量![]() 。如果我们沿z轴和x轴绘制数据,就是下面的样子:
。如果我们沿z轴和x轴绘制数据,就是下面的样子:
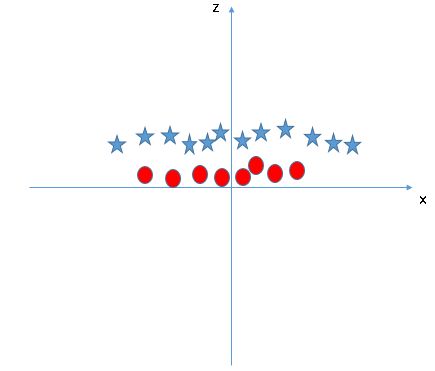
这显然可以通过 z=a 线性分离,其中a是一些正常数。在转换回原始空间时,我们得到![]() 作为决策曲面,这是一个圆圈!
作为决策曲面,这是一个圆圈!
最后的部分?我们不需要手动添加其他函数。SVM有一种称为内核技巧的技术。阅读有关支持向量机的这篇文章(https://www.analyticsvidhya.com/blog/2017/09/understaing-support-vector-machine-example-code/?utm_source=blog&utm_medium=10-applications-linear-algebra-data-science),了解SVM,内核技巧以及如何在Python中实现它。
降维
您将经常使用具有数百甚至数千个变量的数据集。这是行业运作的方式。查看每个变量并确定哪个变量更重要是否切合实际?
这并没有多大意义。我们需要降低变量的数量来执行任何类型的连贯性分析。这就是为什么减少维数的原因。现在,我们来看看常用的两种降维方法。
5. 主成分分析(PCA)
主成分分析(PCA)是一种无监督降维技术。PCA会找到最大方差的方向并沿着它们的投影以减小维度。
在不深入数学的情况下,这些方向就是数据的协方差矩阵的特征向量。
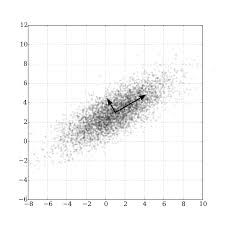
方阵的特征向量是特殊的非零向量,即使在对矩阵应用线性变换(乘法)之后,其方向也不会改变。它们显示为下图中的红色矢量:
您可以使用scikit-learn包中的PCA类轻松地在Python中实现PCA:
from sklearn.decomposition import PCA
// say you want to reduce to 2 features
pca = PCA(n_components = 2)
// obtain transformed data
data_transformed = pca.fit_transform(data)
我在sklearn 的Digits(https://scikit-learn.org/stable/auto_examples/datasets/plot_digits_last_image.html)数据集上应用了PCA - 一组8×8的手写数字图像。我获得的结果相当令人印象深刻。数字看起来很好地聚集在一起:
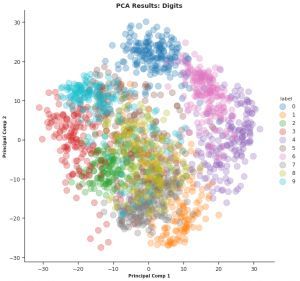
参阅我们的12维降维技术综合指南(https://www.analyticsvidhya.com/blog/2018/08/dimensionality-reduction-techniques-python/?utm_source=blog&utm_medium=10-applications-linear-algebra-data-science),并用Python代码深入了解PCA和其他11种降维技术。老实说,这是你可以找到关于这个主题的最好的文章之一。
6.奇异值分解
在我看来,奇异值分解(SVD)被低估了,没有进行足够的讨论。这是一种令人惊叹的矩阵分解技术,具有多种应用。我将在以后的文章中尝试介绍其中的一些内容。
现在,让我们谈谈维度降低中的SVD。具体而言,这称为截断SVD。
我们从大的mxn数值数据矩阵A开始,其中m是行数,n是特征的数量
将其分解为3个矩阵,如下所示:

根据对角矩阵选择k个奇异值,并相应地截断(修剪)3个矩阵:
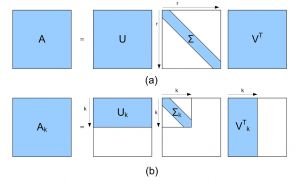
最后,将截断的矩阵相乘以获得变换后的矩阵A_k。它的尺寸为mx k。因此,它具有k < n的k个特征
以下是在Python中实现截断的SVD的代码(它与PCA非常相似):
from sklearn.decomposition import TruncatedSVD
//减少到2个特征
svd = TruncatedSVD(n_features = 2)
//获取转换后的数据
data_transformed = svd.fit_transform(data)
在将截断的SVD应用于Digits数据时,我得到了下面的图。您会注意到它不像我们在PCA之后获得的那样集群:
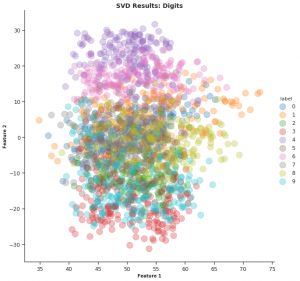
作为机器学习与数据科学背后的线性代数知识系列开篇,本篇主要介绍了机器学习与数据科学背后的数学技术十大应用之基础机器学习部分与降维部分。涵盖损失函数、正则化、协方差矩阵、支持向量机(SVM)、主成分分析(PCA)与奇异值分解(SVD)背后的线性代数知识。相信这也是各位数据科学爱好者常用的各项技术,希望可以帮大家理清思路和对这些算法有更进一步的认识。