Python 机器学习实战 —— 监督学习(下)
前言
近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习、深度学习、神经网络等文章多不胜数。从智能家居、自动驾驶、无人机、智能机器人到人造卫星、安防军备,无论是国家级军事设备还是广泛的民用设施,都充斥着AI应用的身影。接下来的一系列文章将会由浅入深从不同角度分别介绍机器学习、深度学习之间的关系与区别,通过一系统的常用案例讲述它们的应用场景。
在上一篇文章中已经讲述了机械学习的相关概念与基础知识,监督学习的主要流程。对损失函数进行了基础的介绍,并对常用的均方误差与递度下降法的计算过程进行演示,并对常用的 LogisticRegression , LinearSVC、SGDClassifier、 LinearRegression、Ridge、Lasso 、SGDRegressor 等线性模型进行了介绍,讲解了非线性 PolynomialFeatures 多项式转换器以及管道 Pipe 的基本用法。
本文将介绍支持向量机、k近邻、朴素贝叶斯分类 、决策树、决策树集成等模型的应用。
五、支持向量机
支持向量机(Support Vector Machine,SVM)是一个功能强大的模型,它概支持线性分类和非线性分类(SVC),也支持回归(SVR),是机器学习中最常用的模型之一。所介绍的 LinearSVC 线性支持向量机就是属于 SVC 的一种,可把它看作是 SVC 的一个特殊类型。
5.1 SVM 的由来
回顾在上一章节介绍 LogisticRegression 线性分类模型,可以知道在同一组二分类数据当中,有不止一条的直线可以把它们完美地分割,从中很难判断哪一条分割线能更好地让新的数据点分配到正确的标签。

1 def logistic(c=1.0):
2 #生成数据集
3 X,y=datasets.make_forge()
4 X_train,X_test,y_train,y_test=train_test_split(X,y)
5 #对Logistic模型进行训练
6 logistic=LogisticRegression(C=c,random_state=1)
7 logistic.fit(X_train,y_train)
8 #输入正确率
9 print('logistic\n train data:{0}'.format(logistic.score(X_train,y_train)))
10 print(' test data:{0}'.format(logistic.score(X_test,y_test)))
11 #输出模型点
12 plt.scatter(X[:,0], X[:,1],c=y,s=100)
13 plt.legend(['model','data'])
14 #输出模型决策边界
15 line = np.linspace(7, 13, 100)
16 y=(-logistic.coef_[0][0]*line-logistic.intercept_)/logistic.coef_[0][1]
17 plt.plot(line,y,'-')
18
19 logistic(1)
20 logistic(2)
21 logistic(3)
22 plt.show()
运行结果

支持向量机就是为了改进这个问题而产生的模型,它提供的不再是一条直线来区分类型,而是画出一条到最接近点边界且有宽度的线条(决策边界线),边界最大的那条线就是模型的最优选答案。
因此,支持向量机也可以看作为边界最大化的评估器。
5.2 SVC 分类模型
5.2.1 线性 SVM 分类
第四节介绍的 LinearSVC 线性支持向量机就是属于线性分类模型,事实上它是属于一种特殊的 SVC 模型,在编写代码时把 SVC 模型的 ”kernel” 值设置 “linear ” 即:SVC (kernel='linear') ,也可得到与 LinearSVC 类似的效果。由运行结果可以观察到,LinearSVC 可以根据测试数据生成一条决策边界线,边界线的紧密程度可以通过参数C调节。
1 def linearSVC_test(c=100): 2 # 训练数据 3 X,y=dataset.make_blobs(centers=2,random_state=2,n_features=2) 4 # 使用 LinearSVC 模型,使用默认值 C=100 5 linear=LinearSVC(C=c) 6 linear.fit(X,y) 7 # 画出数据点 8 plt.scatter(X[:,0],X[:,1],c=y,marker='^',s=50) 9 # 建立网格数据 10 xx=np.linspace(-5,6,100) 11 yy=np.linspace(-13,3,100) 12 XX,YY=np.meshgrid(xx,yy) 13 ZZ=np.c_[XX.ravel(),YY.ravel()] 14 # 根据网络数据推算出预测值 15 zz=linear.decision_function(ZZ) 16 # 显示决策分界线 17 plt.contour(xx,yy,zz.reshape(XX.shape),levels=[-1,0,1], 18 linestyles=['--','-','--'],alpha=0.7,cmap='jet') 19 plt.show()
运行结果

5.2.2 非线性 SVM 分类
5.2.2.1 多项式转换器
在处理线性分类时可以使用 LinearSVC,然而它受到了线性分类的限制,当处理非线性数据集时,LinearSVC 则无法单独支撑,此时可以使用上一章介绍python教程过的多项式转换器 PolynomialFeatures 与管道 Pipe 来解决此问题。
1 def polynomialFeatures_linearSVC_test(): 2 # 获取数据集,通过求余方式把输出值变为2个 3 X,y=dataset.make_blobs(centers=4,random_state=8,n_features=2) 4 y=y%2 5 # 通过管道使用多项转换器PolynomialFeatures和线性支持向量机LinearSVC 6 pipe=make_pipeline(PolynomialFeatures(degree=2),LinearSVC(C=10)) 7 model=pipe.fit(X,y) 8 # 建立网格数组 9 xx=np.linspace(-9,11,100) 10 yy=np.linspace(-14,14,100) 11 XX,YY=np.meshgrid(xx,yy) 12 ZZ=np.c_[XX.ravel(),YY.ravel()] 13 # 计算网络中的输出值 14 zz=model.decision_function(ZZ) 15 # 显示分类决策边界线 16 plt.contourf(xx,yy,zz.reshape(XX.shape),alpha=0.7) 17 # 显示测试数据点 18 plt.scatter(X[:,0],X[:,1],c=y,s=50,marker='^') 19 plt.show()
运行结果

上面例子的运行结果可以看出,通过多项式转换器可以有效地利用 LinearSVC 解决非线性数据的问题。
5.2.2.2 核技巧的定义
通过某种非线性映射将原始数据嵌入到合适的高维特征空间,利用通用的线性学习器在这个新的空间中分析和处理的模式被称为核函数技巧。
常用的核函数有:

遗憾的是常用的 LinearSVC 模型并不支持核函数,为此 sklearn 特意开发了支持核函数的 SVC 模型。
5.2.2.3 SVC 模型
上面用到的 LinearSVC 模型是基于 liblinear 库实现的 SVM 算法,它并不支持核技巧,因此它所训练的数据基本都是线性数据,处理数据的速度较快,运行时间为O (m*n) ,适合处理量大的数据集。当遇到非线性数据时,也可使用多项式转换器来处理。
下面说到的 SVC 模型则是基于 libsvm 库实现的,它本身就支持核技巧,使用时只需要通过 kernel 参数进行设置。但不幸的是它的处理速度比较慢,运行时间O(m3*n)从指数级上升,因此只适合处理中小型的数据集。
下表就统计了 LinearSVC 与 SVC 两个模型的区别,时间O公式中的 m 和 n 分别表示未知数的行数和列数。
| 模型 | 时间 | 核技巧 | 需要缩放 |
| LinearSVC | O(m*n) | 不支持 | 是 |
| SVC | O(m2*n)到O(m3*n) | 支持 | 是 |
SVC 构造函数
1 class SVC(BaseSVC): 2 @_deprecate_positional_args 3 def __init__(self, *, C=1.0, kernel='rbf', degree=3, gamma='scale', 4 coef0=0.0, shrinking=True, probability=False, 5 tol=1e-3, cache_size=200, class_weight=None, 6 verbose=False, max_iter=-1, decision_function_shape='ovr', 7 break_ties=False, 8 random_state=None): 9 ......
参数说明:
- C: float参数 默认值为1.0,错误项的惩罚系数。C越大,即对分错样本的惩罚程度越大,因此在训练样本中准确率越高,但是泛化能力降低,也就是对测试数据的分类准确率降低。相反,减小C的话,容许训练样本中有一些误分类错误样本,泛化能力强。对于训练样本带有噪声的情况,一般采用后者,把训练样本集中错误分类的样本作为噪声。
- kernel: str参数 默认为‘rbf’,算法中采用的核函数类型,可选参数有:‘linear’:线性核函数、‘poly’:多项式核函数、‘rbf’:径像核函数/高斯核、‘sigmod’:sigmod核函数、‘precomputed’:核矩阵,precomputed表示自己提前计算好核函数矩阵,这时候算法内部就不再用核函数去计算核矩阵,而是直接用你给的核矩阵。除了上面限定的核函数外,还可以给出自己定义的核函数。
- degree: int型参数 默认为3,这个参数只对 poly 多项式核函数有用,是指多项式核函数的阶数 n,如果给的核函数参数是其他核函数,则会自动忽略该参数。
- gamma: 可选 scale、auto 或 float参数, 默认为 scale,可调节决策边界的影响范围。值越大决策边界越窄,每个实例影响范围越小。反之值越小,决策边界越大,影响范围越广。只对 kernel为:‘rbf’,‘poly’,‘sigmod’有效,当使用线性核函数 linear 时无效。如果gamma为auto,代表其值为样本特征数的倒数,即1/n_features。
- coef0: float参数 默认为0.0,核函数中的独立项,控制模型受高阶多项式的影响程度,只有对 kernel为 ‘poly’和‘sigmod’ 核函数有用
- probability:bool参数 默认为False,是否启用概率估计。这必须在调用fit()之前启用,并且会fit()方法速度变慢。
- shrinking:bool参数 默认为True,是否采用启发式收缩方式
- tol: float参数 默认为1e^-3,svm停止训练的误差精度
- cache_size:float参数 默认为200,指定训练所需要的内存,以MB为单位,默认为200MB。
- class_weight:字典类型或者‘balance’字符串。默认为None,给每个类别分别设置不同的惩罚参数C,如果没有给,则会给所有类别都给C=1,即前面参数指出的参数C.如果给定参数‘balance’,则使用y的值自动调整与输入数据中的类频率成反比的权重。
- verbose :bool参数 默认为False,是否启用详细输出。此设置利用libsvm中的每个进程运行时设置,如果启用,可能无法在多线程上下文中正常工作。一般情况都设为False,不用管它。
- max_iter :int参数 默认为-1,最大迭代次数,如果为-1,表示不限制
- decision_function_shape: 可选 'ovo' 或 'ovr',默认值为 ‘ovr'。多分类时需要进行选择的两种不同策略。ovo:one versus one,一对一,即一对一的分类器,这时对K个类别需要构建K * (K - 1) / 2个分类器; ovr:one versus rest,一对其他,这时对K个类别只需要构建K个分类器。
- break_ties:默认值为False。如果选择 True 当decision_function_shape 为’ovr' ,且测试数据类型大于2,系统将根据 decision_function 的值计算 predict 的类型输出值。
- random_state:int 型参数 默认为None,伪随机数发生器的种子,在混洗数据时用于概率估计。
常用属性:
- svc.support_vectors_:位于边界上的点,称为支持向量,SVM 支持向量机也是由此得名
- svc.n_support_:获取不同类型的支持向量的数据
- svc.support_:支持向量在训练样本中的索引
- dual_coef_ : 决策函数中支持向量的系数,分类器为 ‘ovo’ 一对一的系数
- coef_ : 返回每个特征的权重,仅在使用 linear 线性核函数时有效
(1)线性( Linear)核函数
使用 SVC 模型时,可以通过设置 kernel 参数得到不同的核函数,当使用 linear 核函数时,其结果与直接使用 LinearSVC 相仿,也是无法对非线性数据集进行精准的训练。不同的是使用 SVC 可以通过 support_vectors_ 参数获取支持向量,能够更准备地预知决策边界。
1 def svc_test(c=0.01):
2 #测试数据集
3 X, y = dataset.make_blobs(centers=2, random_state=2, n_features=2)
4 #生成SVC模型,使用Linear核函数,把C设置为0.01
5 svc = SVC(C=c,kernel='linear')
6 svc.fit(X, y)
7 #生成矩形网络数据
8 xx = np.linspace(-5, 7, 1000)
9 yy = np.linspace(-14, 4, 1000)
10 XX, YY = np.meshgrid(xx, yy)
11 ZZ = np.c_[XX.ravel(), YY.ravel()]
12 #计算分隔平面距离
13 zz = svc.decision_function(ZZ)
14 #划出分隔线
15 plt.contour(xx, yy, zz.reshape(XX.shape), levels=[-1,0,1],linestyles=['--','-','--'])
16 #划出数据点
17 plt.scatter(X[:, 0], X[:, 1], c=y,marker='^',s=80)
18 #划出支持向量
19 sv=svc.support_vectors_
20 plt.scatter(sv[:,0],sv[:,1],marker='.',color='red',s=300)
21 #坐标标识
22 plt.legend(['data point','supper vector'])
23 plt.xlabel('feature0')
24 plt.ylabel('feature1')
25 plt.show()
运行结果

通过调节 C 参数,可以调节惩罚程度。
上面代码当 C 为默认值 0.01时,support_vectors_ 就有14个。C 值越小,能容纳的训练样本中误分类错误样本越多,泛化能力强,这被称为边界软化。
C 越大对分错样本的惩罚程度越大,因此在训练样本中准确率越高,但是泛化能力降低,也就是对测试数据的分类准确率会降低,这被称之为边界硬化。
下面试着把 C 设置为100 时,support_vectors_ 则只有2个,由此可知 C 对调节惩罚程度的作用。

(2)多项式 Poly 核函数
当把 kernel 参数设置为 poly 时,可无需通过多项式转换器 PolynomialFeatures 就可得到类似的效果。
使用 poly 核函数时有两个重要参数,degree 用于控制多项式的阶数,coef0 可控制高阶多项式与低阶多项式对模型的影响。
把 degree 设置为2,coef0 设置为0.1 时,支持向量点 support_vectors_有66个之多,可见模型欠拟合。
1 def svc_test():
2 #测试数据集
3 X, y = dataset.make_blobs(centers=8, random_state=18, n_features=2)
4 y=y%2
5 #生成SVC模型,使用poly核函数,把C设置为2,degree
6 svc = SVC(C=2,kernel='poly',degree=2,coef0=0.1)
7 svc.fit(X, y)
8 #生成矩形网络数据
9 xx = np.linspace(-10, 11, 1000)
10 yy = np.linspace(-14, 14, 1000)
11 XX, YY = np.meshgrid(xx, yy)
12 ZZ = np.c_[XX.ravel(), YY.ravel()]
13 #计算分隔平面距离
14 zz = svc.decision_function(ZZ)
15 #划出分隔线
16 plt.contourf(xx, yy, zz.reshape(XX.shape),)
17 #划出数据点
18 plt.scatter(X[:, 0], X[:, 1], c=y,marker='^',s=80)
19 #划出支持向量
20 sv=svc.support_vectors_
21 plt.scatter(sv[:,0],sv[:,1],marker='.',color='red',s=150)
22 #标签
23 plt.xlabel('feature0')
24 plt.ylabel('feature1')
25 print('support_vectors_ shape:{0}'.format(sv.shape))
26 plt.show()
运行结果


把degree设置为3,coef0设置为10后,运行结果如下,此支持向量点只剩11个,且模型的边界更明确,拟合度有所提升。


(3)高斯 RBF 核函数
使用高斯RBF核函数时,可把 kerenl 设置为 rbf,此时通过调节 gamma 参数可调节决策边界。值越大决策边界越窄,每个实例影响范围越小。反之值越小,决策边界越大,影响范围越广。下面的例子使用环形数据集,把 gamma 设置为10。
1 def svc_test():
2 #测试数据集
3 X, y = dataset.make_circles(random_state=2,noise=0.1,factor=0.1)
4 #生成SVC模型,使用RBF核函数
5 svc = SVC(C=2,kernel='rbf',gamma=10)
6 svc.fit(X, y)
7 #生成矩形网络数据
8 xx = np.linspace(-1.5, 1.5, 1000)
9 yy = np.linspace(-1.5, 1.5, 1000)
10 XX, YY = np.meshgrid(xx, yy)
11 ZZ = np.c_[XX.ravel(), YY.ravel()]
12 #计算分隔平面距离
13 zz = svc.decision_function(ZZ)
14 #划出分隔线
15 plt.contourf(xx, yy, zz.reshape(XX.shape),alpha=0.8)
16 #划出数据点
17 plt.scatter(X[:, 0], X[:, 1], c=y,marker='^',s=50)
18 #划出支持向量
19 sv=svc.support_vectors_
20 plt.scatter(sv[:,0],sv[:,1],marker='.',color='red',s=150)
21 #标签
22 plt.xlabel('feature0')
23 plt.ylabel('feature1')
24 print('support_vectors_ shape:{0}'.format(sv.shape))
25 plt.show()
运行结果


尝试把 把 gamma 设置改 0.5,测试结果如下,很明显其决策边界加宽了,支持向量点也减小到18个。


注意:gamma 配置只有在 kernel 为:‘rbf’,‘poly’,‘sigmod’ 时有效,当使用线性核函数 linear 时则无效。
当使用支持向量机时,如果数据量不大时,建议使用高斯RBF核函数,大部分情况下其准确率较高。当数据量较大时,可使用 LinearSVC ,其效率较高。
5.3 SVR 回归模型
SVM 除了支持 SVC 分类外,还支持 SVR 回归模型。使用方法与 SVC 模型类似,可以通过 kernel 参数选择核函数,使用 poly 核函数时可通过 degree 设置阶数。使用 ‘rbf’,‘poly’,‘sigmod’ 等核函数时,可能通过 gamma 设置决策边界的影响范围。
构造函数
1 class SVR(RegressorMixin, BaseLibSVM): 2 @_deprecate_positional_args 3 def __init__(self, *, kernel='rbf', degree=3, gamma='scale', 4 coef0=0.0, tol=1e-3, C=1.0, epsilon=0.1, shrinking=True, 5 cache_size=200, verbose=False, max_iter=-1): 6 ......
- C: float参数 默认值为1.0,错误项的惩罚系数。C越大,即对分错样本的惩罚程度越大,因此在训练样本中准确率越高,但是泛化能力降低,也就是对测试数据的分类准确率降低。相反,减小C的话,容许训练样本中有一些误分类错误样本,泛化能力强。对于训练样本带有噪声的情况,一般采用后者,把训练样本集中错误分类的样本作为噪声。
- kernel: str参数 默认为‘rbf’,算法中采用的核函数类型,可选参数有:‘linear’:线性核函数、‘poly’:多项式核函数、‘rbf’:径像核函数/高斯核、‘sigmod’:sigmod核函数、‘precomputed’:核矩阵,precomputed表示自己提前计算好核函数矩阵,这时候算法内部就不再用核函数去计算核矩阵,而是直接用你给的核矩阵。除了上面限定的核函数外,还可以给出自己定义的核函数。
- degree: int型参数 默认为3,这个参数只对 poly 多项式核函数有用,是指多项式核函数的阶数 n,如果给的核函数参数是其他核函数,则会自动忽略该参数。
- gamma: 可选 scale、auto 或 float参数, 默认为 scale,可调节决策边界的影响范围。值越大决策边界越窄,每个实例影响范围越小。反之值越小,决策边界越大,影响范围越广。只对 kernel为:‘rbf’,‘poly’,‘sigmod’有效,当使用线性核函数 linear 时无效。如果gamma为auto,代表其值为样本特征数的倒数,即1/n_features。
- coef0: float参数 默认为0.0,核函数中的独立项,控制模型受高阶多项式的影响程度,只有对 kernel为 ‘poly’和‘sigmod’ 核函数有用
- shrinking:bool参数 默认为True,是否采用启发式收缩方式
- tol: float参数 默认为1e^-3,svm停止训练的误差精度
- cache_size:float参数 默认为200,指定训练所需要的内存,以MB为单位,默认为200MB。
- verbose :bool参数 默认为False,是否启用详细输出。此设置利用libsvm中的每个进程运行时设置,如果启用,可能无法在多线程上下文中正常工作。一般情况都设为False,不用管它。
- max_iter :int参数 默认为-1,最大迭代次数,如果为-1,表示不限制
下面例子尝试使用多项式核函数 poly 对测试集进行计算,因为数据量较少,为了提高准确率,把 C 惩罚程度调高到 2,把阶数 degree 设置为 2,此时测试数据的准确率已接近 99%,线条更接近于一条直线。
1 def svr_test():
2 # 测试数据
3 X, y = dataset.make_regression(n_samples=100,noise=10,n_features=1,random_state=8)
4 X_train, X_test, y_train, y_test = train_test_split(X, y)
5 # SVR 模型,使用 poly 核函数,degree为2级
6 svr = SVR(kernel='poly',C=2,degree=2,coef0=2)
7 svr.fit(X_train, y_train)
8 # 准确率
9 print('SVR:\n train data:{0}\n test data:{1}'
10 .format(svr.score(X_train, y_train), svr.score(X_test, y_test)))
11 # 生成线状图
12 line=np.linspace(-3,3,100)
13 result=svr.predict(line.reshape(-1,1))
14 plt.plot(line.reshape(-1,1),result)
15 plt.plot(X,y,'^')
16 plt.show()
运行结果


若改为使高斯核函数RBF,当惩罚系数依然为 C=2 时,准确率将会大幅下降,这是由于可训练的数据量太少,前后数据的误差所造成的。若遇到这种情况,有两种不同的解决方案,一是提高测试集的数据量,让模型得到充分的训练,二是加大惩罚系数。


这里还是使用高斯核函数RBF,但尝试把惩罚系数修改为 C=100,运行则得到以下的结果,可见准确率有明显的提升,而且相对 poly 核函数,线条扭曲程度会更高。


回到目录
六、K 近邻
K 近邻(KNN,K-NearestNeighbor)是比较简单的一种算法,它包含 KNN 分类与回归算法。所谓 K 近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来做代表进行计算。
6.1 KNeighborsClassifier 分类
KNeighborsClassifier 近邻分类算法就是将数据集中的每一个记录进行分类的方法。最简单的思路就是通过 n_neighbors 参数(默认值为5)控制近邻的个数,把 n 个近邻看到为同一类型。模型使用的近邻点(n_neightbors)越大模型复杂程度越低,相反近邻点数量越少模型的复杂程度低高。
构造函数
1 class KNeighborsClassifier(KNeighborsMixin, 2 ClassifierMixin, 3 NeighborsBase): 4 @_deprecate_positional_args 5 def __init__(self, n_neighbors=5, *, 6 weights='uniform', algorithm='auto', leaf_size=30, 7 p=2, metric='minkowski', metric_params=None, n_jobs=None, 8 **kwargs): 9 ......
- n_neighbors: int, 默认为 5 表示默认邻居的数量
- weights(权重): str 类型, 默认为 ‘uniform’,用于预测的权重函数。可选参数如下: ‘uniform’ : 统一的权重. 在每一个邻居区域里的点的权重都是一样的。 ‘distance’ : 权重点等于他们距离的倒数。使用此函数,更近的邻居对于所预测的点的影响更大。‘callable’ : 一个用户自定义的方法,此方法接收一个距离的数组,然后返回一个相同形状并且包含权重的数组。
- algorithm(算法): str 类型,默认值为 auto ,可选值 {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’},代表计算最近邻居用的算法。'ball_tree':使用BallTree维数大于20时建议使用。kd_tree':原理是数据结构的二叉树,以中值为划分,每个节点是一个超矩形,在维数小于20是效率高。'brute':暴力算法,线性扫描。'auto':自动选取最合适的算法。
- leaf_size(叶子数量): int, 默认为 30,代表使用 BallTree 或者 KDTree 算法时的叶子数量。此参数会影响构建、查询BallTree或者KDTree的速度,以及存储BallTree或者KDTree所需要的内存大小。
- p: int,默认为 2,可选值为[1,2]。p=1表示用于使用曼哈顿距离进行度量。p = 2表示使用闵可夫斯基距离。
进行度量 - metric(矩阵): string or callable, 默认为 ‘minkowski’,用于树的距离矩阵。
- metric_params(矩阵参数): dict, 可选参数(默认为 None),代表给矩阵方法使用的其他的关键词参数。
- n_jobs: int, 默认为 1,可并行运行的任务数量。如果为-1, 任务数量设置为CPU核的数量。
knn 适用于集中的同类型数据,测试可见只有临近的几个数据点可能出现错误判断的数据点。
1 def knn_classifier_test():
2 # 2类的测试数据100个
3 X,y= dataset.make_blobs(n_samples=100,n_features=2,
4 centers=2,random_state=30)
5 X_train,X_test,y_train,y_test=train_test_split(X,y)
6 # 用k近邻算法进行分类
7 knn_classifier=KNeighborsClassifier(n_neighbors=3)
8 knn_classifier.fit(X_train,y_train)
9 knn_classifier.predict(X_test)
10 # 打印测试数据正确率
11 print('KNN Claassifier\n test data:{0}'
12 .format(knn_classifier.score(X_test,y_test)))
13 # 划出分类图形
14 plt.scatter(X[:,0],X[:,1],c=y,marker='^')
15 plt.title('neighbors 3')
16 plt.xlabel('feature0')
17 plt.ylabel('feature1')
18 plt.show()
运行结果


尝试把近邻点的数量参数调高,测试数据的正确很容易就会上升到100%。
6.2 KNeighborsRegressor 回归
KNeighborsRegressor 的用法基本与 KNeighborsClassifier 类似,主要也是通过 n_neighbors 来控制近邻数量
构造函数
1 class KNeighborsRegressor(KNeighborsMixin, 2 RegressorMixin, 3 NeighborsBase): 4 @_deprecate_positional_args 5 def __init__(self, n_neighbors=5, *, weights='uniform', 6 algorithm='auto', leaf_size=30, 7 p=2, metric='minkowski', metric_params=None, n_jobs=None, 8 **kwargs): 9 ......
- n_neighbors: int, 默认为 5 表示默认邻居的数量
- weights(权重): str 类型, 默认为 ‘uniform’,用于预测的权重函数。可选参数如下: ‘uniform’ : 统一的权重. 在每一个邻居区域里的点的权重都是一样的。 ‘distance’ : 权重点等于他们距离的倒数。使用此函数,更近的邻居对于所预测的点的影响更大。‘callable’ : 一个用户自定义的方法,此方法接收一个距离的数组,然后返回一个相同形状并且包含权重的数组。
- algorithm(算法): str 类型,默认值为 auto ,可选值 {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’},代表计算最近邻居用的算法。'ball_tree':使用BallTree维数大于20时建议使用。kd_tree':原理是数据结构的二叉树,以中值为划分,每个节点是一个超矩形,在维数小于20是效率高。'brute':暴力算法,线性扫描。'auto':自动选取最合适的算法。
- leaf_size(叶子数量): int, 默认为 30,代表使用 BallTree 或者 KDTree 算法时的叶子数量。此参数会影响构建、查询BallTree或者KDTree的速度,以及存储BallTree或者KDTree所需要的内存大小。
- p: int,默认为 2,可选值为[1,2]。p=1表示用于使用曼哈顿距离进行度量。p = 2表示使用闵可夫斯基距离。
进行度量 - metric(矩阵): string or callable, 默认为 ‘minkowski’,用于树的距离矩阵。
- metric_params(矩阵参数): dict, 可选参数(默认为 None),代表给矩阵方法使用的其他的关键词参数。
- n_jobs: int, 默认为 1,可并行运行的任务数量。如果为-1, 任务数量设置为CPU核的数量。
下面以简单的单特征数据集测试,把 n_neighbors 设置为1时,训练数据的正确率为100%,而测试数据的正确率只有71%左右,可见数据的拟合度过高,线条基本上会经过所有的数据点。
1 def knn_regressor_test():
2 #测试数据集
3 X,y=dataset.make_regression(n_features=1,noise=25,random_state=2)
4 X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0)
5 #训练KNeighborsRegressor模型
6 knn_regressor=KNeighborsRegressor(n_neighbors=1)
7 knn_regressor.fit(X_train,y_train)
8 #输出训练数据集、测试数据集的正确率
9 print('KNN_Regressor:\n train data:{0}\n test data:{1}'
10 .format(knn_regressor.score(X_train,y_train),
11 knn_regressor.score(X_test,y_test)))
12 #画出数据点与数据线
13 line=np.linspace(-3,3,1000).reshape(-1,1)
14 plt.plot(line,knn_regressor.predict(line))
15 plt.plot(X,y,'v')
16 plt.legend(['model predict','train data'])
17 plt.show()
运行结果


把 n_neighbors 设置为 3 时,可见线条会更加平滑,数据的拟合度有所降低。

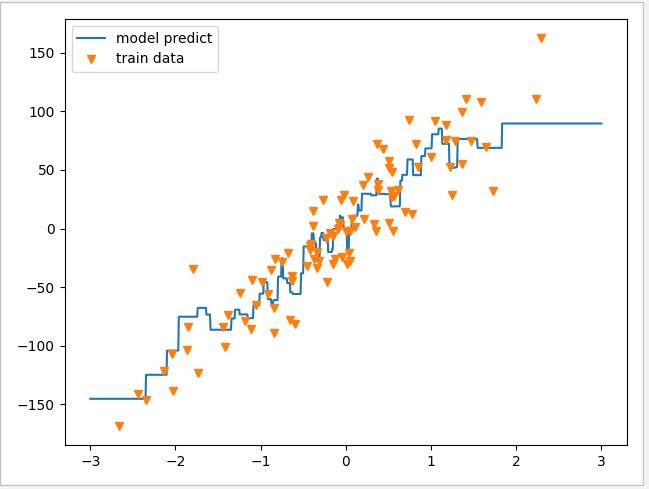
k 近邻是一种很好理解的模型,它比较适用于特征量较少的集合型数据,当特征数上到几个百个甚至更多时,k 近邻的准确率就是急剧下降。使用时主要是控制好 n_neighbors 的数量,一般为 3 到 5 个比较合理。
回到目录
七、朴素贝叶斯分类器
朴素贝叶斯模型是一个简单快速的分类算法,适用于维度较高的的数据集,因为它可调的参数少,运行速度快,所以多用于初步的数据分类。它基于 “ 贝叶斯定理 ” 而得名,是关于随机事件 A 和 B 的条件概率的数学定理。其中 P(A|B)是在 B 发生的情况下 A 发生的可能性。这个数学定理十分有趣,并且跟生活有着密切的关联,有兴趣的朋友可以百度科普一下,在此不作详述。

在 sklearn 中常用的朴素贝叶斯分类器有高斯朴素贝叶斯分类器(Gaussian naive Bayes)、多项式朴素贝叶斯分类器(Multinomial naive Bayes)和 伯努利贝叶斯分类器 (Bernoulli naive Bayes)。
7.1 GaussianNB 分类器
高斯朴素贝叶斯分类是最常用一种朴素贝叶斯分类器,它可以应用于任意连续的数据,而且会保存每个类别中每个特征的平均值与标准差值。而且可以通过快节的方法 predict_proba() 找到测试数据所属类型的概率。其构造函数简单易用,只有两个参数。
构造函数
1 class GaussianNB(_BaseNB): 2 @_deprecate_positional_args 3 def __init__(self, *, priors=None, var_smoothing=1e-9): 4 ....
- prior:表示类的先验概率。如果指定,则不根据数据调整先验,如果不指定,则自行根据数据计算先验概率P(Y)。
- var_smoothing:float 类型,默认值为: 1e-9,在估计方差时,为了追求估计的稳定性,将所有特征的方差中最⼤大的方差以某个比例添加到估计的方差中。
假设测试数据集服从高斯分布,且变量无方差关系,则只要找到每个标签样本点的均值和标准差,就可以通过高斯分布找到拟合的模型。从高斯模型的分界可以看出,它是一个二次方的曲线形成的。因为GaussianNB 模型的运算速度较快,测试的数据量较大,所以模型特意准备了一个 partial_fit() 方法,可以分批处理训练数据。
1 def gaussianNB():
2 X, y = dataset.make_blobs(centers=4, random_state=2, n_features=2)
3 X_train,X_test,y_train,y_test=train_test_split(X,y)
4 #训练数据
5 gaussina=GaussianNB()
6 model=gaussina.fit(X_train,y_train)
7 #输出准确率
8 print('GaussianNB\n train data:{0}\n test data:{1}'
9 .format((gaussina.score(X_train,y_train)),
10 gaussina.score(X_test,y_test)))
11 #画出数据点
12 plt.scatter(X[:,0],X[:,1],c=y,s=100,marker='^')
13 #画出分界
14 xx=np.linspace(-8,4,100)
15 yy=np.linspace(-12,5,100)
16 XX,YY=np.meshgrid(xx,yy)
17 ZZ=np.c_[XX.ravel(),YY.ravel()]
18 zz=gaussina.predict(ZZ)
19 plt.contourf(xx,yy,zz.reshape(XX.shape),alpha=0.4)
20 #画出坐标
21 plt.xlabel('feature0')
22 plt.ylabel('feature1')
23 #输出数据所属类型的概率
24 print('\ndata probability:\n{0}'.format(gaussina.predict_proba(X[1:3].reshape(-1,1))))
25 plt.show()
运行结果


7.2 MultinomialNB 分类器
高斯朴素贝叶斯分类器适用于连续型的数据分类,而 MultinomialNB 多项式朴素贝叶斯分类器更适用于分布型的数据分类,例如在玩筛子的时候,1,2,3,4,5,6 出现的机率均为1/6,其出现的情况互不干扰也没有相关性,它的特点在于所涉及的特征往往是次数,频率,计算等,不会有负值。因此,MultinomialNB 分类往往用于文本数据的分析。与 GaussianNB 类似,MultinomialNB 也可以通过快节的方法 predict_proba() 找到测试数据所属类型的概率。通过 partial_fit() 方法对数据量大的数据进行分批处理。
构造函数
1 class MultinomialNB(_BaseDiscreteNB): 2 @_deprecate_positional_args 3 def __init__(self, *, alpha=1.0, fit_prior=True, class_prior=None): 4 ......
- alpha: float 类型,默认为1.0,表示平滑值
- fit_prior: bool类型,默认为True。如果为True,则不去学习类别先验概率,以均匀分布替代;如果为False,则去学习
- class_prior: 数组类型,默认为空。它指定了每个分类的先验概率,如果指定了该参数,则每个分类的先验概率不再从数据集中学得
常用参数
- class_log_prior_: 一个数组对象,形状为(n_classes,)。给出了每个类别调整后的经验概率分布的对数值
- feature_log_prob_: 一个数组对象,形状为(n_classes, n_features)。给出了P(wi|c)的经验概率分布的对数值
- class_count_: 一个数组,形状为(n_classes,),是每个类别包含的训练样本数量
- feature_count_: 一个数组,形状为(n_classes, n_features)。训练过程中,每个类别每个特征遇到的样本数
- coef_ :将多项式模型解释为线性模型后的系数序列w1,w2,…,wn,每个类别的词语多项式权值向量,shpae=[类别数量,词汇表长度]
- intercept_:将多项式模型解释为线性模型后的截距值b,每个类别的先验概率,shape=[类别数量]
下面就是文本分析为案例,首先从 fetch_20newsgroups 测试集中获取6类的文件做测试,通过管道 pipe 把数据先通过 TF-IDF 做文本分析,再使用 MultinomialNB 进行分类,最后用混淆矩阵把各类数据的数据显示出来。可见,数据的准确率达到 88.8% 左右。
1 def multinomialNB_test():
2 #获取6类文章做测试
3 categories=['rec.autos','soc.religion.christian','talk.politics.guns'
4 ,'sci.electronics','sci.med','sci.crypt']
5 #获取训练数据和测试数据
6 train=fetch_20newsgroups(subset='train',categories=categories)
7 test=fetch_20newsgroups(subset='test',categories=categories)
8 #通过pipe管道用TF_IDF文本统计器和MultinomialNB进行训练
9 pipe=make_pipeline(TfidfVectorizer(),MultinomialNB())
10 pipe.fit(train.data,train.target)
11 y_model=pipe.predict(test.data)
12 #输入准确率
13 print('MultinomialNB\n test data:{0}'
14 .format(pipe.score(test.data,test.target)))
15 #混淆矩阵
16 matrix=confusion_matrix(test.target,y_model)
17 heatmap(matrix,square=True,annot=True,cbar=False,fmt='d',linewidths=2
18 ,xticklabels=test.target_names,yticklabels=test.target_names)
19 plt.show()
运行结果


至于 BernoulliNB 伯努利贝叶斯分类器的使用方法与 MultinomialNB 十分类似,只不过BernoulliNB 更多用于二元离散值或者稀疏的多元离散值分类,在此就不作详细描述。
回到目录
八、决策树与决策树集成
8.1 决策树
决策树是广泛应用于分类与回归的模型,从本质上说它类似于 if / else 的语句,从是与否中对数据进行分析。打个比方,在现实生活中我们对交通工具的划分,有轮子的是车,没轮子的船,有轮子带油箱的是机动车,有轮子不油箱的是电动车,没轮子带电机的游轮,没轮子不带电机的竹筏。这样子,我们就把交通工具分成三层关系(如下图),交通工具需要根结点,车跟船属于内结点,电动车、机动车、游轮、竹筏属于叶结点。

8.1.1 DecisionTreeClassifier 分类决策树
分类决策树 DecisionTreeClassifier 就是通过二分类的方式对数据进行逐步分割,这表示决策树的每个节点都是根据一个特征的阈值将数据分成两组进行分割的。如果结点进行无限的分枝,必然会引起性能的虚耗,导致数据过分拟合。为避免此类问题,决策树提供了预剪枝的功能,可以通过 max_depth 参数控制树的最大深度。通过 min_samples_split 控制结点的最小样本数量,当样本数量可能小于此值时,节点将不会在划分。通过 min_samples_leaf 限制了叶子节点最少的样本数,如果叶子节点数目小于最小样本数,就会和兄弟节点一起被剪枝。特别是在数据量比较大的时候,通过设置几个参数,将有效提高系统的性能。
构造函数
1 class DecisionTreeClassifier(ClassifierMixin, BaseDecisionTree): 2 @_deprecate_positional_args 3 def __init__(self, *, 4 criterion="gini", 5 splitter="best", 6 max_depth=None, 7 min_samples_split=2, 8 min_samples_leaf=1, 9 min_weight_fraction_leaf=0., 10 max_features=None, 11 random_state=None, 12 max_leaf_nodes=None, 13 min_impurity_decrease=0., 14 min_impurity_split=None, 15 class_weight=None, 16 ccp_alpha=0.0): 17 ......
- criterion:str类型,默认值为 ‘gini'。表示特征选择标准,可选 gini 或者 entropy ,前者是基尼系数,后者是信息熵。
- splitter:str 类型,默认值为 ’best' 。表示特征划分标准,可选择 best 或 random,”best”是在所有特征中找最好的切分点,适合样本量不大的时候。而random 在部分特征中选择分割点,适用于样本数据量较大时使用。
- max_depth: int 类型,默认值 为 None。 设置决策随机森林中的决策树的最大深度,深度越大,越容易过拟合,推荐树的深度为:5-20之间。
- min_samples_split:int 类型,默认值为2。设置结点的最小样本数量,当样本数量可能小于此值时,节点将不会在划分。
- min_samples_leaf:int 类型,默认值为1。 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
- min_weight_fraction_leaf: int 类型,默认值为 0。这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。
- max_features:类型 int, float or {"auto", "sqrt", "log2"}, 默认值为 None,表示限制的最大特征数。{"auto", "sqrt", "log2"} 一般在特征小于50的时候使用
- random_state:随机数种子,推荐设置一个任意整数,同一个随机值,模型可以复现。
- max_leaf_nodes: int 类型,默认是"None”。表示限制最大叶子的节点数,可以防止过拟合。当设置为None时,即不限制最大的叶子节点数。
- min_impurity_decrease:float 类型,默认值为0.0。表示节点划分最小不纯度, 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。
- min_impurity_split: float 类型,默认值为0.0。功能可用 min_impurity_decrease 参数代替,新版不推荐使用,这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
- class_weight:dict 或 list 类型,默认值为 None , 可选 "balanced" 。指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
- ccp_alpha:float 类型,默认值为 0.0 。表示使用 CCP 算法的误差率增益率α阈值,小于该值的误差率增益率对应的节点都会被剪枝。
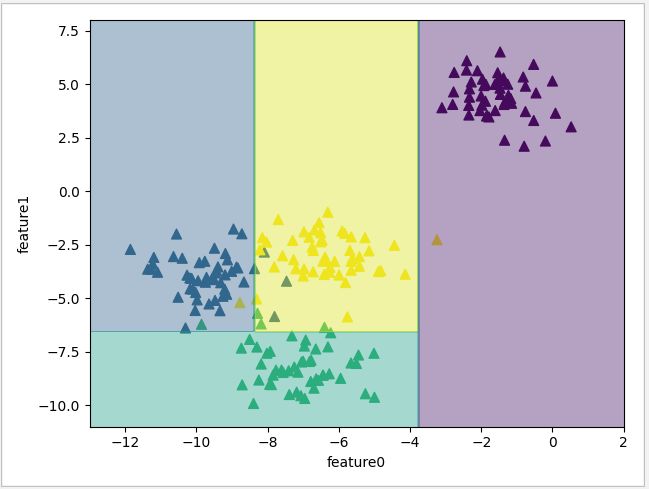
下面以一个4类的数据集作为例子,看一下决策树是如果通过二分类的方式对数据进行逐步分割的。从运行结果可以看到每一层分类时数据的划分情况,深度越大,数据的分类就越仔细,这里把最大深度设置为5,然后进行剪枝。
1 def decisionTreeClassifier_test():
2 #测试集,用四类数据
3 X,y=make_blobs(n_samples=200,centers=4,random_state=0,n_features=2)
4 X_train,X_test,y_train,y_test=train_test_split(X,y)
5 #生成决策树模型进行训练
6 decisiontree=DecisionTreeClassifier(max_depth=5)
7 decisiontree.fit(X_train,y_train)
8 #显示准确率
9 print('DecisionTreeClassifier:\n train data:{0}\n test data:{1}'
10 .format(decisiontree.score(X_train,y_train),
11 decisiontree.score(X_test,y_test)))
12 #打印数据分布图
13 xx=np.linspace(-5,5,200)
14 yy=np.linspace(-2,11,200)
15 XX,YY=np.meshgrid(xx,yy)
16 ZZ=np.c_[XX.ravel(),YY.ravel()]
17 zz=decisiontree.predict(ZZ).reshape(XX.shape)
18 plt.contourf(xx,yy,zz,alpha=0.4,zorder=2)
19 #画出数据点
20 plt.scatter(X[:,0],X[:,1],c=y,marker='^',s=50)
21 plt.show()
运行结果

|
|
|
|
|
|



除此以外,还可以使用 tree.export_graphviz() 保存决策树和重要信息。使用 DecisionTreeClassifier.feature_importances_ 属性查看决策树每个特征的重要性占比,每个特征的重要性比率加起来必然是等于1 。注意,即使特征的重要性为0,并不说明此特征没有提供任何信息,只是表示此次运行中该特征并末被此决策树选中,每次运行同样的数据集,特征的占比均不相同。
1 def decisionTreeClassifier_test():
2 #测试集,用四类数据
3 X,y=make_blobs(n_samples=500,centers=10,random_state=1,n_features=10)
4 X_train,X_test,y_train,y_test=train_test_split(X,y)
5 #生成决策树模型进行训练
6 decisiontree=DecisionTreeClassifier(max_depth=8)
7 decisiontree.fit(X_train,y_train)
8 #显示准确率
9 print('DecisionTreeClassifier:\n train data:{0}\n test data:{1}'
10 .format(decisiontree.score(X_train,y_train),
11 decisiontree.score(X_test,y_test)))
12 #输出 feature 特性重要性比率
13 print(' feature_importance:\n{0}'.format(decisiontree.feature_importances_))
14 #保存决策树重要信息
15 export_graphviz(decisiontree,out_file='data2.dot')
运行结果

8.1.2 DecisionTreeRegressor 回归决策树
回归决策树的原理与分类决策树的原理基本一致,但是有一点必须注意的是,他的测试数据不能在训练范围以外进行预测,一但超出训练范围,测试值就是一定被认定为最后的一个值。
构造函数
1 class DecisionTreeRegressor(RegressorMixin, BaseDecisionTree): 2 @_deprecate_positional_args 3 def __init__(self, *, 4 criterion="mse", 5 splitter="best", 6 max_depth=None, 7 min_samples_split=2, 8 min_samples_leaf=1, 9 min_weight_fraction_leaf=0., 10 max_features=None, 11 random_state=None, 12 max_leaf_nodes=None, 13 min_impurity_decrease=0., 14 min_impurity_split=None, 15 ccp_alpha=0.0): 16 ......
- criterion:str类型,默认值为 ‘mse'。表示特征选择标准,可选 gini 或者 entropy ,前者是基尼系数,后者是信息熵。
- splitter:str 类型,默认值为 ’best' 。表示特征划分标准,可选择 best 或 random,”best”是在所有特征中找最好的切分点,适合样本量不大的时候。而random 在部分特征中选择分割点,适用于样本数据量较大时使用。
- max_depth: int 类型,默认值 为 None。 设置决策随机森林中的决策树的最大深度,深度越大,越容易过拟合,推荐树的深度为:5-20之间。
- min_samples_split:int 类型,默认值为2。设置结点的最小样本数量,当样本数量可能小于此值时,节点将不会在划分。
- min_samples_leaf:int 类型,默认值为1。 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
- min_weight_fraction_leaf: int 类型,默认值为0。这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。
- max_features:类型 int, float or {"auto", "sqrt", "log2"}, 默认值为 None,表示限制的最大特征数。{"auto", "sqrt", "log2"} 一般在特征小于50的时候使用
- random_state:随机数种子,推荐设置一个任意整数,同一个随机值,模型可以复现。
- max_leaf_nodes: int 类型,默认是"None”。表示限制最大叶子的节点数,可以防止过拟合。当设置为None时,即不限制最大的叶子节点数。
- min_impurity_decrease:float 类型,默认值为0.0。表示节点划分最小不纯度, 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。
- min_impurity_split: float 类型,默认值为0.0。功能可用 min_impurity_decrease 参数代替,新版不推荐使用,这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
- class_weight:dict 或 list 类型,默认值为 None , 可选 "balanced" 。指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
- ccp_alpha:float 类型,默认值为 0.0 。表示使用 CCP 算法的误差率增益率α阈值,小于该值的误差率增益率对应的节点都会被剪枝。
下面的例子使用一个自定义的数据集进行训练,输出测试集的准确率,同时把训练集以外的数据进行测试。从运行结果可以看出,超出训练集以外的数据都会以最后一个值作为输出。
1 def decisionRegression_test():
2 # 生成数据集
3 X = np.linspace(-3, 3, 100)
4 y = 2*X+1+np.random.ranf(100)
5 X_train,X_test,y_train,y_test=train_test_split(X.reshape(-1,1),y)
6 # 使用决策树模型进行训练
7 decisiontree=DecisionTreeRegressor(max_depth=4)
8 decisiontree.fit(X_train,y_train)
9 # 测试数据
10 model_y=decisiontree.predict(X.reshape(-1,1))
11 print('DecisionTreeRegression:\n train data:{0}\n test data{1}'
12 .format(decisiontree.score(X_train,y_train),
13 decisiontree.score(X_test,y_test)))
14 # 画出数据点
15 plt.plot(X_train,y_train,'.')
16 plt.plot(X,model_y,'-')
17
18 #超越训练范围会取最后一个点值
19 XX=np.linspace(3, 5, 20)
20 YY=decisiontree.predict(XX.reshape(-1,1))
21 plt.plot(XX,YY,'-')
22 plt.legend(['train data','predict data','out tree data'])
23 plt.show()
运行结果


决策树的原理比较容易理解,在计算前不需要对特征进行预处理,当特征独立性较强或多元特征与连续特征同时存在时,决策树的效果会比较好。而且处理时只需要通过调节上述的几个参数: max_depth 、 min_samples_split 、 min_samples_leaf 就可以适应多样性的特征。然而,它的泛化性能较差,有时候即使做了剪枝,也会出现过拟合的情况。
有见及此,sklearn 还提供了决策树集成模型,下面就为大家介绍 2 种常用的决策树集成模型:随机森林与梯度提升决策树。
8.2 随机森林
随机森林顾名思义就是把多棵决策树集成一起同时运行,最后把个运算结果进行合并运算求平均值。类似这种通过多个拟合评估器来降低拟合程度的算法被称作装袋算法,它使用并行评估器对数据进行有效的数据抽取并集成 ,对本来的过拟合的数量通过求和取平均值,最后通过更好的分类效果。因此,相比起决策树,随机森林的准确率会更高,也是应该最广的模型之一。
随机森林可以通过 n_estimators 参数来设置随机森林中决策树的数量,通过 estimator_ 属性可以获取随机森林中的每一棵决策树。一般情况下,n_estimators 越大越好。还能然后通过 max_features 来控制每个节点的特征数,回归时一般 max_features 可以设置为数据集中所有的特征数,在分类时,max_features=sqrt(n_features)。
8.2.1 RandomForestClassifier 随机森林分类
使用 RandomForestClassifier 进行分类时,通过增加决策树的数量(在默认设置中随机森林往往使用100棵决策树),可以减小数据拟合度,使数据边界更加平滑。在设置特征数时,max_features 直接使用默认值 auto ,则最大特征数 max_features = sqrt(n_features)。
构造函数
1 class RandomForestClassifier(ForestClassifier): 2 @_deprecate_positional_args 3 def __init__(self, 4 n_estimators=100, *, 5 criterion="gini", 6 max_depth=None, 7 min_samples_split=2, 8 min_samples_leaf=1, 9 min_weight_fraction_leaf=0., 10 max_features="auto", 11 max_leaf_nodes=None, 12 min_impurity_decrease=0., 13 min_impurity_split=None, 14 bootstrap=True, 15 oob_score=False, 16 n_jobs=None, 17 random_state=None, 18 verbose=0, 19 warm_start=False, 20 class_weight=None, 21 ccp_alpha=0.0, 22 max_samples=None): 23 ......
- n_estimators:类型 int,默认值100,森林中决策树的数量。
- criterion:str类型,默认值为 ‘mse'。表示特征选择标准,可选 gini 或者 entropy ,前者是基尼系数,后者是信息熵。
- max_depth: int 类型,默认值 为 None。 设置决策随机森林中的决策树的最大深度,深度越大,越容易过拟合,推荐树的深度为:5-20之间。
- min_samples_split:int 类型,默认值为2。设置结点的最小样本数量,当样本数量可能小于此值时,节点将不会在划分。
- min_samples_leaf:int 类型,默认值为1。 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
- min_weight_fraction_leaf: int 类型,默认值为0。这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。
- max_features:类型 int, float or {"auto", "sqrt", "log2"} 默认值为 auto ,此时 max_features =sqrt( n_features)。表示最佳分割时要考虑的特征数量,如果为int,则在每个拆分中考虑max_features个特征。如果为float,则max_features是一个分数,并在每次拆分时考虑int(max_features * n_features)个特征。如果为“auto”,则 max_features = sqrt(n_features)。如果为“ sqrt”,则 max_features = sqrt(n_features)。如果为“ log2”,则max_features = log2(n_features)。注意:在找到至少一个有效的节点样本分区之前,分割的搜索不会停止。
- max_leaf_nodes:int 类型,默认为None,最大叶子节点数。
- min_impurity_decrease:float 类型,默认值为0.0。表示节点划分最小不纯度, 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。
- min_impurity_split:float 类型,默认值为0.0。功能可用 min_impurity_decrease 参数代替,新版不推荐使用,这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
- bootstrap:bool类型,默认值为 True,表示是否进行bootstrap操作。当为 True 时,将每次有放回地随机选取样本,只有在extra-trees中,才可设置为 False
- oob_score:bool类型,默认值为 False。表示是否使用袋外样本来估计泛化精度。
- n_jobs:int, 默认为 None,可并行运行的任务数量。如果为-1, 任务数量设置为CPU核的数量。
- random_state:int 默认为 None。随机数种子,推荐设置一个任意整数,同一个随机值,模型可以复现。
- verbose:int 默认是0。表示在拟合和预测时控制详细程度。
- warm_start:bool 类型,默认值 False,当设置为True时,重用之前调用的解决方案作为初始化,否则,需要删除前面的解决方案。
- class_weight:dict 或 list 类型,默认值为 None , 可选 "balanced" 。指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
- ccp_alpha:float 类型,默认值为 0.0 。表示使用 CCP 算法的误差率增益率α阈值,小于该值的误差率增益率对应的节点都会被剪枝。
- max_samples:bool 类型,默认值为None。如果bootstrap为True,则从X抽取以训练每个基本分类器的样本数。如果为None(默认),则抽取X.shape [0]样本。如果为int,则抽取max_samples样本。如果为float,则抽取max_samples * X.shape [0]个样本。
下面例子尝试使用 6 棵决策树的随机森林,分别把每棵决策树的数据分布与特征权重打印出来作比较。可见每棵决策树的边界并不相同,而且特征权重也有区别。随机森林会根据特征权重求和并取平均值,最后算出的权重更客观平均。
1 def randomforestclassifier_test():
2 #测试集,用四类数据
3 X,y=make_blobs(n_samples=100,centers=4,random_state=1,n_features=2)
4 X_train,X_test,y_train,y_test=train_test_split(X,y)
5 #生成随机森林模型进行训练
6 randomforest=RandomForestClassifier(n_estimators=6,max_features=2)
7 #训练模型
8 randomforest.fit(X_train,y_train)
9 #显示准确率
10 print('RandomForestClassifier:\n train data:{0}\n test data:{1}\n'
11 .format(randomforest.score(X_train,y_train),
12 randomforest.score(X_test,y_test)))
13 #打印数据分布图
14 fig,axes=plt.subplots(2,3)
15 axes1=axes.reshape(1,-1)[0]
16 # 打印每棵决策树的数据分布图
17 for ax,estimator in zip(axes1,randomforest.estimators_):
18 xx=np.linspace(-13,2,200)
19 yy=np.linspace(-11,8,200)
20 XX,YY=np.meshgrid(xx,yy)
21 ZZ=np.c_[XX.ravel(),YY.ravel()]
22 zz=estimator.predict(ZZ).reshape(XX.shape)
23 ax.contourf(xx,yy,zz,alpha=0.4,zorder=2)
24 #画出数据点
25 ax.scatter(X[:,0],X[:,1],c=y,marker='^',s=50)
26 # 显示特征占比
27 print(estimator.feature_importances_)
28 plt.show()
运行结果


8.2.2 RandomForestRegressor 随机森林回归
随机森林也支持回归算法,且 RandomForestRegressor 的构造函数与 RandomForestClassifier 基本一至。由于它是由多棵决策树构成,所以回归曲线会更加平滑。也可进行剪枝等操作,但必须注意超出训练集以外的数据与决策树一样,都会以最后一个值作为输出。而在 max_features 设置方面与 RandomForestClassifier 也有不同,默认情况下 RandomForestClassifier 分类模型 max_features = sqrt(n_features),而在 RandomForestRegressor 回归模型 max_features = n_features。
构造函数
1 class RandomForestRegressor(ForestRegressor): 2 @_deprecate_positional_args 3 def __init__(self, 4 n_estimators=100, *, 5 criterion="mse", 6 max_depth=None, 7 min_samples_split=2, 8 min_samples_leaf=1, 9 min_weight_fraction_leaf=0., 10 max_features="auto", 11 max_leaf_nodes=None, 12 min_impurity_decrease=0., 13 min_impurity_split=None, 14 bootstrap=True, 15 oob_score=False, 16 n_jobs=None, 17 random_state=None, 18 verbose=0, 19 warm_start=False, 20 ccp_alpha=0.0, 21 max_samples=None): 22 ......
- n_estimators:类型 int,默认值100,森林中决策树的数量。
- criterion:str类型,默认值为 ‘mse'。表示特征选择标准,“mse” 表示均方误差,可选 gini 或者 entropy ,前者是基尼系数,后者是信息熵。
- max_depth: int 类型,默认值 为 None。 设置决策随机森林中的决策树的最大深度,深度越大,越容易过拟合,推荐树的深度为:5-20之间。
- min_samples_split:int 类型,默认值为2。设置结点的最小样本数量,当样本数量可能小于此值时,节点将不会在划分。
- min_samples_leaf:int 类型,默认值为1。 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
- min_weight_fraction_leaf: int 类型,默认值为0。这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。
- max_features:类型 int, float or {"auto", "sqrt", "log2"} 默认值为 auto ,此时 max_features = n_features。表示最佳分割时要考虑的特征数量,如果为int,则在每个拆分中考虑 max_features个特征。如果为float,则max_features是一个分数,并在每次拆分时考虑int(max_features * n_features)个特征。如果为“auto”,则 max_features = n_features。如果为“ sqrt”,则max_features = sqrt(n_features)。如果为“ log2”,则max_features = log2(n_features)。注意:在找到至少一个有效的节点样本分区之前,分割的搜索不会停止。
- max_leaf_nodes:int 类型,默认为None,最大叶子节点数。
- min_impurity_decrease:float 类型,默认值为0.0。表示节点划分最小不纯度, 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。
- min_impurity_split:float 类型,默认值为0.0。功能可用 min_impurity_decrease 参数代替,新版不推荐使用,这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
- bootstrap:bool类型,默认值为 True,表示是否进行bootstrap操作。当为 True 时,将每次有放回地随机选取样本,只有在extra-trees中,才可设置为 False
- oob_score:bool类型,默认值为 False。表示是否使用袋外样本来估计泛化精度。
- n_jobs:int, 默认为 None,可并行运行的任务数量。如果为-1, 任务数量设置为CPU核的数量。
- random_state:int 默认为 None。随机数种子,推荐设置一个任意整数,同一个随机值,模型可以复现。
- verbose:int 默认是0。表示在拟合和预测时控制详细程度。
- warm_start:bool 类型,默认值 False,当设置为True时,重用之前调用的解决方案作为初始化,否则,需要删除前面的解决方案。
- ccp_alpha:float 类型,默认值为 0.0 。表示使用 CCP 算法的误差率增益率α阈值,小于该值的误差率增益率对应的节点都会被剪枝。
- max_samples:bool 类型,默认值为None。如果bootstrap为True,则从X抽取以训练每个基本分类器的样本数。如果为None(默认),则抽取X.shape [0]样本。如果为int,则抽取max_samples样本。如果为float,则抽取max_samples * X.shape [0]个样本。
用与决策树回归相同的例子对自定义的数据集进行训练,输出测试集的准确率。从输出图片对比可以看到,经过随机森林计算的结果会明显比决策树更平滑,而超出训练集以外的数据高样会以最后一个值作为输出。在多特征数据集中,你会发现随机森林的准确率会更高。
1 def randomforestregressor_test():
2 # 生成数据集
3 X = np.linspace(-3, 3, 100)
4 y = 2*X+1+np.random.ranf(100)
5 X_train,X_test,y_train,y_test=train_test_split(X.reshape(-1,1),y)
6 # 使用随机森林模型进行训练
7 randomforest=RandomForestRegressor()
8 randomforest.fit(X_train,y_train)
9 # 测试数据
10 model_y=randomforest.predict(X.reshape(-1,1))
11 print('randomforestRegression:\n train data:{0}\n test data{1}'
12 .format(randomforest.score(X_train,y_train),
13 randomforest.score(X_test,y_test)))
14 # 画出数据点
15 plt.plot(X_train,y_train,'.')
16 plt.plot(X,model_y,'-')
17
18 #超越训练范围会取最后一个点值
19 XX=np.linspace(3, 5, 20)
20 YY=randomforest.predict(XX.reshape(-1,1))
21 plt.plot(XX,YY,'-')
22 plt.legend(['train data','predict data','out tree data'])
23 plt.show()
运行结果


8.3 梯度提升回归树
虽然名称中包含回归字样,但其实这模型既支持分类也支持回归。与随机森林不同的地方在于,随机森林是以多棵决策树求平均值的方式得到最终结果,而梯度提升回归树是以连续方式构建决策树,每棵决策树都会试图纠正前一棵树的错误。在默认情况下,每棵决策树都会使用预剪枝,其深度都在1~5之间,以减少内存消耗。
8.3.1 GradientBoostingClassifier 梯度提升分类器
使用梯度提升分类器时,值得注意的是除了常用的 n_estimators 、min_samples_split 、 min_samples_leaf 参数外,会把 max_depth 调节到 3 ~5 之间,以减少内存消耗 。一般情况下会使用默认值把max_features 调节为 sqrt(n_features) 或以下,而学习率 learn_rate 会视乎训练数据的多少而设定。如果训练集数量不能确定时,可使用 validation_fraction 和 n_iter_no_change 参数,使训练数据达到某一比例时停止训练,并根据 n_iter_no_change 设置值把部分训练层的数据作为参数值。
构造函数
1 class GradientBoostingClassifier(ClassifierMixin, BaseGradientBoosting): 2 @_deprecate_positional_args 3 def __init__(self, *, loss='deviance', learning_rate=0.1, n_estimators=100, 4 subsample=1.0, criterion='friedman_mse', min_samples_split=2, 5 min_samples_leaf=1, min_weight_fraction_leaf=0., 6 max_depth=3, min_impurity_decrease=0., 7 min_impurity_split=None, init=None, 8 random_state=None, max_features=None, verbose=0, 9 max_leaf_nodes=None, warm_start=False, 10 validation_fraction=0.1, n_iter_no_change=None, tol=1e-4, 11 ccp_alpha=0.0): 12 ......
- loss:str 类型,表示每一次节点分裂所要最小化的损失函数 (loss function),默认值为 deviance 。可选值 "deviance"和"exponential" ,deviance 代表使用 “logistic” 作为损失函数进行分类与概率输出。exponential 代表使用 “Adaboost” 作为损失函数进行回归。
- learning_rate:float 类型,默认值为0.1 ,表示学习率。每一次树分类都会更新这个值,而 learning_ rate控制着每次更新的幅度。只要训练数据足够多,这个值不应该设得太大,因为较小的learning rate使得模型对不同的树更加稳健,就能更好地综合它们的结果。
- n_estimators:int 类型,默认值100,森林中决策树的数量。通常会把 n_estimators 与参数 learning_rate 一起考虑,控制学习的质量。
- subsample: float 类型,默认值 1.0。代表训练每个决定树所用到的子样本占总样本的比例,因为是对于子样本的,选择是随机的0.5 ~0.8就有更好的调参结果。如果使用默认值1.0,即代表不使用子样本采样。
- criterion:str类型,默认值为 ‘friedman_mse',可选值 {'friedman_mse', 'mse', 'mae'}。friedman_mse” 表示对均方误差改进的“弗里德曼得分”,“mse” 表示均方误差,“mae” 表示平均绝对误差。
- min_samples_split:int 类型,默认值为2。设置结点的最小样本数量,当样本数量可能小于此值时,节点将不会在划分。
- min_samples_leaf:int 类型,默认值为1。 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
- min_weight_fraction_leaf: int 类型,默认值为0。这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。
- max_depth: int 类型,默认值 为 3。 决策树的最大深度,深度越大,越容易过拟合。每棵决策树都会使用预剪枝,其深度都在1~5之间,以减少内存消耗。
- min_impurity_decrease:float 类型,默认值为 0.0。表示节点划分最小不纯度, 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。
- min_impurity_split:float 类型,默认值为 None 。功能可用 min_impurity_decrease 参数代替,新版不推荐使用,这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
- init:可选 estimator 或 'zero',默认值为 None,代表初始化的时候的弱学习器。默认情况下会用训练集样本来做样本集的初始化分类回归预测。否则用init参数提供的学习器做初始化分类回归预测。一般用在对数据已有先检查的经验,或者之前做过一些拟合的时候。
- random_state:int 默认为 None。随机数种子,推荐设置一个任意整数,同一个随机值,模型可以复现。
- max_features:类型 int, float or {"auto", "sqrt", "log2"} 默认值为 none,此时 max_features = n_features。表示最佳分割时要考虑的特征数量,如果为int,则在每个拆分中考虑 max_features个特征。如果为float,则max_features是一个分数,并在每次拆分时考虑int(max_features * n_features)个特征。如果为“auto”,则 max_features = sqrt(n_features)。如果为“ sqrt”,则max_features = sqrt(n_features)。如果为“ log2”,则max_features = log2(n_features)。注意:在找到至少一个有效的节点样本分区之前,分割的搜索不会停止。
- verbose:int 默认是0。表示在拟合和预测时控制详细程度。
- max_leaf_nodes:int 类型,默认为None,最大叶子节点数。
- warm_start:bool 类型,默认值 False,当设置为True时,重用之前调用的解决方案作为初始化,否则,需要删除前面的解决方案。
- validation_fraction:float 类型,默认值0.1 。测试数据占验证集的比例时提前停止工作,必须介于0和1之间 float 类型。只有当 n_iter_no_chang 有效时才起作用。
- n_iter_no_change:int 类型,默认值为 None。表示是否在验证集比例达到 validation_fraction 设定值时提前终止训练。由默认情况下,它被设置为 “None” 以禁用提前停止训练。如果设置为 n 时,它将根据 validation_fraction 的设置去训练数据多次,将前 n 次的训练数据作为参考值去修改模型。
- tol:float类型,默认值1e-4 ,表示停止训练的误差精度。
- ccp_alpha:float 类型,默认值为 0.0 。表示使用 CCP 算法的误差率增益率α阈值,小于该值的误差率增益率对应的节点都会被剪枝。
下面以 breast_cancer 数据集为例,使用 GradientBoostingClassifier 模型进行分类测试。
1 def gradientboostingclassifier_test():
2 #测试数据
3 cancer=dt.load_breast_cancer()
4 X_train,X_test,y_train,y_test=train_test_split(cancer.data,cancer.target,random_state=1)
5 #使用GradientBoostingClassifier模型进行学习
6 gradientBoosting=GradientBoostingClassifier(max_depth=5,learning_rate=0.1)
7 gradientBoosting.fit(X_train,y_train)
8 #显示准确率
9 print('GradientBoostingClassifier:\n train data:{0}\n test data:{1}'
10 .format(gradientBoosting.score(X_train,y_train),
11 gradientBoosting.score(X_test,y_test)))
12 #输出 feature 特性重要性比率
13 print('\n feature_importance:\n{0}'.format(gradientBoosting.feature_importances_))
运行结果

从运行结果看到训练数据的准确率达到 100%,有可能存在可过拟合的情况。此时可以试着把最大深度调节为 2,把学习率降低到 0.05,可得到下面的结果。可见减小最大深度,调节学习率有利于预防过拟合情况,提高泛化性。

8.3.1 GradientBoostingRegressor 梯度提升回归器
GradientBoostingRegressor 的使用方法与 RandomForestRegressor 类似,要注意的一点是 GradientBoostingRegressor 模型中 n_estimators 并非越大越好,因为值越大,模型的复杂程度就会越大,消耗的硬件资源也会越高。结合数据集的大小、内存情况以及 learning_rate 来设置 n_estimators 是比较好的选择。
构造函数
1 class GradientBoostingRegressor(RegressorMixin, BaseGradientBoosting): 2 @_deprecate_positional_args 3 def __init__(self, *, loss='ls', learning_rate=0.1, n_estimators=100, 4 subsample=1.0, criterion='friedman_mse', min_samples_split=2, 5 min_samples_leaf=1, min_weight_fraction_leaf=0., 6 max_depth=3, min_impurity_decrease=0., 7 min_impurity_split=None, init=None, random_state=None, 8 max_features=None, alpha=0.9, verbose=0, max_leaf_nodes=None, 9 warm_start=False, validation_fraction=0.1, 10 n_iter_no_change=None, tol=1e-4, ccp_alpha=0.0): 11 ......
- loss:str 类型,表示每一次节点分裂所要最小化的损失函数 (loss function),默认值为 ' ls '。可选值 {'ls', 'lad', 'huber', 'quantile'} ,“ls”是使用最小二乘法,‘lad' 是使用最小绝对偏差,‘huber' 则是两者的结合,'quantitle' 则是使用 alpha 的设置值作为分位数进行使用。
- learning_rate:float 类型,默认值为0.1 ,表示学习率。每一次树分类都会更新这个值,而 learning_ rate控制着每次更新的幅度。只要训练数据足够多,这个值不应该设得太大,因为较小的learning rate使得模型对不同的树更加稳健,就能更好地综合它们的结果。
- n_estimators:int 类型,默认值100,森林中决策树的数量。通常会把 n_estimators 与参数 learning_rate 一起考虑,控制学习的质量。
- subsample: float 类型,默认值 1.0。代表训练每个决定树所用到的子样本占总样本的比例,因为是对于子样本的,选择是随机的0.5 ~0.8就有更好的调参结果。如果使用默认值1.0,即代表不使用子样本采样。
- criterion:str类型,默认值为 ‘friedman_mse',可选值 {'friedman_mse', 'mse', 'mae'}。friedman_mse” 表示对均方误差改进的“弗里德曼得分”,“mse” 表示均方误差,“mae” 表示平均绝对误差。
- min_samples_split:int 类型,默认值为2。设置结点的最小样本数量,当样本数量可能小于此值时,节点将不会在划分。
- min_samples_leaf:int 类型,默认值为1。 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
- min_weight_fraction_leaf: int 类型,默认值为0。这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。
- max_depth: int 类型,默认值 为 3。 决策树的最大深度,深度越大,越容易过拟合。每棵决策树都会使用预剪枝,其深度都在1~5之间,以减少内存消耗。
- min_impurity_decrease:float 类型,默认值为 0.0。表示节点划分最小不纯度, 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。
- min_impurity_split:float 类型,默认值为 None 。功能可用 min_impurity_decrease 参数代替,新版不推荐使用,这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
- init:可选 estimator 或 'zero',默认值为 None,代表初始化的时候的弱学习器。默认情况下会用训练集样本来做样本集的初始化分类回归预测。否则用init参数提供的学习器做初始化分类回归预测。一般用在对数据已有先检查的经验,或者之前做过一些拟合的时候。
- random_state:int 默认为 None。随机数种子,推荐设置一个任意整数,同一个随机值,模型可以复现。
- max_features:类型 int, float or {"auto", "sqrt", "log2"} 默认值为 None,此时 max_features = n_features。表示最佳分割时要考虑的特征数量,如果为int,则在每个拆分中考虑 max_features个特征。如果为float,则max_features是一个分数,并在每次拆分时考虑int(max_features * n_features)个特征。如果为“auto”,则 max_features = n_features。如果为“ sqrt”,则max_features = sqrt(n_features)。如果为“ log2”,则max_features = log2(n_features)。注意:在找到至少一个有效的节点样本分区之前,分割的搜索不会停止。
- alpha: float类型,默认值是0.9 。当使用 “quantile” 作为 loss 时,所指定分位数的值。默认是0.9,如果噪音点较多,可以适当降低这个分位数的值。
- verbose:int 默认是0。表示在拟合和预测时控制详细程度。
- max_leaf_nodes:int 类型,默认为None,最大叶子节点数。
- warm_start:bool 类型,默认值 False,当设置为True时,重用之前调用的解决方案作为初始化,否则,需要删除前面的解决方案。
- validation_fraction:float 类型,默认值0.1 。测试数据占验证集的比例时提前停止工作,必须介于0和1之间 float 类型。只有当 n_iter_no_chang 有效时才起作用。
- n_iter_no_change:int 类型,默认值为 None。表示是否在验证集比例达到 validation_fraction 设定值时提前终止训练。由默认情况下,它被设置为 “None” 以禁用提前停止训练。如果设置为 n 时,它将根据 validation_fraction 的设置去训练数据多次,将前 n 次的训练数据作为参考值去修改模型。
- tol:float类型,默认值1e-4 ,表示停止训练的误差精度。
- ccp_alpha:float 类型,默认值为 0.0 。表示使用 CCP 算法的误差率增益率α阈值,小于该值的误差率增益率对应的节点都会被剪枝。
使用与 RandomForestRegressor 相同的测试数据,尝试把 n_estimators 降低到 20,把 max_depth 设置为 1,学习率 learning_rate 设置为 0.08 。把参数调低后,也可达到随机森林类似的结果,而且线条的顺滑程度同样比决策树要高。
1 def gradientbootingregressor_test():
2 # 生成数据集
3 X = np.linspace(-3, 3, 100)
4 y = 2*X+1+np.random.ranf(100)
5 X_train,X_test,y_train,y_test=train_test_split(X.reshape(-1,1),y)
6 # 使用梯度提升回归树模型进行训练
7 gradientbooting=GradientBoostingRegressor(n_estimators=40,max_depth=3,learning_rate=0.08)
8 gradientbooting.fit(X_train,y_train)
9 # 测试数据
10 model_y=gradientbooting.predict(X.reshape(-1,1))
11 print('gradientbootingRegression:\n train data:{0}\n test data{1}'
12 .format(gradientbooting.score(X_train,y_train),
13 gradientbooting.score(X_test,y_test)))
14 # 画出数据点
15 plt.plot(X_train,y_train,'.')
16 plt.plot(X,model_y,'-')
17
18 #超越训练范围会取最后一个点值
19 XX=np.linspace(3, 5, 20)
20 YY=gradientbooting.predict(XX.reshape(-1,1))
21 plt.plot(XX,YY,'-')
22 plt.legend(['train data','predict data','out tree data'])
23 plt.show()
运行结果


本章总结
本文主要介绍支持向量机、k近邻、朴素贝叶斯分类 、决策树、决策树集成等模型的应用。讲解了支持向量机 SVM 线性与非线性模型的适用环境,并对核函数技巧作出深入的分析,对线性 Linear 核函数、多项式 Poly 核函数,高斯 RBF 核函数进行了对比。讲述了 K 近邻的使用方法。对高斯朴素贝叶斯分类器(Gaussian naive Bayes)、多项式朴素贝叶斯分类器(Multinomial naive Bayes)和 伯努利贝叶斯分类器 (Bernoulli naive Bayes)进行了不同的介绍。最后对决策树(DecisionTree)、随机森林(RandomForest)、梯度提升回归器(GradientBoosting)进行分析。