Real-time Rendering (3rd edition)学习笔记第3章
目录
- 第3章 图像处理单元(The Graphics Processing Unit)
-
- 3.1 GPU 管道概述
- 3.2 可编程着色器阶段(The Programmable Shader Stage)
- 3.3 可编程着色的演变(The Evolution of Programmable Shading)
-
- 3.3.1 着色器模型的比较(Comparison of Shader Models)
- 3.4 顶点着色器(The Vertex Shader)
- 3.5 几何着色器(The Geometry Shader)
-
- 3.5.1 流输出(Stream Output)
- 3.6 像素着色器(The Pixel Shader)
- 3.7 合并阶段(The Merging Stage)
- 3.8 效果(Effects)
- Further Reading and Resources
第3章 图像处理单元(The Graphics Processing Unit)
“The display is the computer.”—Jen-Hsun Huang
从历史上看,硬件图形加速始于管线的末端,首先对三角形的扫描线进行栅格化。随后,一代又一代的硬件开始备份管道(back up the pipeline),直到一些更高级别的应用程序级算法被提交给硬件加速器。 专用硬件相对于软件的唯一优势是速度,但是速度至关重要。
在过去的十年中,图形硬件经历了不可思议的转变。 1999年交付的第一款包含硬件顶点处理的消费类图形芯片(NVIDIA的GeForce256)。NVIDIA创造了图形处理单元(graphics processing unit,GPU)一词,以将GeForce 256与以前可用的仅光栅化芯片区分开来,并因此停滞[898]。在接下来的几年中,GPU从复杂的固定功能管道的可配置实现发展到高度可编程的空白状态,开发人员可以在其中实现自己的算法。各种可编程着色器(shaders)是控制GPU的主要方法。顶点着色器可对每个顶点执行各种操作(包括变换和变形)。类似地,像素着色器处理单个像素,从而允许对每个像素评估复杂的着色方程式。几何着色器允许GPU动态创建和销毁几何图元(点,线,三角形)。可以将计算的值写入多个高精度缓冲区,并重新用作顶点或纹理数据。为了提高效率,流水线的某些部分仍然是可配置的,而不是可编程的,但是趋势是朝着可编程性和灵活性的方向发展[123]。
3.1 GPU 管道概述
GPU实现了第2章中描述的几何和栅格化概念管线阶段。这些阶段分为具有不同程度的可配置性或可编程性的几个硬件阶段。 图3.1显示了根据各个阶段的可编程性或可配置性对其进行颜色编码的各个阶段。 请注意,这些物理阶段的划分与第2章中介绍的功能阶段略有不同。

图3.1 渲染管道的GPU实现。阶段根据用户对其操作的控制程度进行颜色编码。绿色阶段是完全可编程的。黄色阶段是可配置的,但不可编程,例如,裁剪阶段可以选择性地执行剔除或添加用户定义的裁剪平面。蓝色阶段的功能是完全固定的。
顶点着色器是一个完全可编程的阶段,通常用于实现“模型和视图变换”,“顶点着色”和“投影”功能阶段。几何着色器是一个可选的,完全可编程的平台,可在图元的顶点(点,线或三角形)上运行。它可用于执行每个图元的着色操作,销毁图元或创建新的图元。裁剪,屏幕映射,三角形设置和三角形遍历阶段是固定功能阶段,可实现相同名称的功能阶段。与顶点和几何着色器一样,像素着色器是完全可编程的,并执行“像素着色”功能阶段。最后,合并阶段介于着色器阶段的完全可编程性和其他阶段的固定操作之间。尽管它不是可编程的,但它是高度可配置的,可以设置为执行多种操作。当然,它实现了合并功能阶段,负责修改颜色,Z缓冲区,混合,模板和其他相关缓冲区。
随着时间的流逝,GPU管道已从硬编码操作演变为增加灵活性和控制能力。 可编程着色器阶段的引入是这一发展过程中最重要的一步。 下一节将介绍各个可编程阶段的通用功能。
3.2 可编程着色器阶段(The Programmable Shader Stage)
现代着色器阶段(即在Vista上支持Shader Model 4.0,DirectX 10及更高版本的着色器)使用公共着色器核心(common-shader core)。 这意味着顶点,像素和几何着色器共享一个编程模型。 在本书中,我们区分了通用着色器核心,应用程序程序员看到的功能描述和统一着色器(统一映射到该核心的GPU架构)。 参见18.4节。 通用着色器核心是API; 具有统一的着色器是GPU的功能。 较早的GPU在顶点着色器和像素着色器之间的通用性较低,并且没有几何着色器。 尽管如此,该模型的大多数设计元素还是由较旧的硬件共享的。 在大多数情况下,较旧版本的设计元素比较简单或缺失,没有根本不同。 因此,目前我们将重点关注Shader Model 4.0,并在后面的部分中讨论较旧的GPU shader模型。
描述整个编程模型远远超出了本书的范围,并且已经有许多文档,书籍和网站[261,338,647,1084]。 但是,请按顺序进行一些评论。 使用类似于C的着色语言(shading languages)(例如HLSL,Cg和GLSL)对着色器进行编程。 它们被编译为与机器无关的汇编语言,也称为中间语言(intermediate language,IL)。 以前的着色器模型允许直接使用汇编语言进行编程,但是从DirectX 10开始,使用该语言的程序仅作为调试输出可见[123]。 通常在驱动程序中,在单独的步骤中将此汇编语言转换为实际的机器语言。 这种安排允许不同硬件实现之间的兼容性。 这种汇编语言可以看作是定义虚拟机,其是着色语言编译器的目标。
该虚拟机是具有各种类型的寄存器和数据源的处理器,并通过一组指令进行编程。由于许多图形操作是在短矢量(最大长度为4)上完成的,因此该处理器具有4路SIMD(单指令多数据(single-instruction multiple-data))功能。每个寄存器包含四个独立的值。基本数据类型是32位单精度浮点标量和向量。最近还添加了对32位整数的支持。浮点向量通常包含诸如位置(xyzw),法线,矩阵行,颜色(rgba)或纹理坐标(uvwq)之类的数据。整数最常用于表示计数器,索引或位掩码。还支持聚合数据类型,例如结构,数组和矩阵。为了方便使用向量,还支持旋转(复制)任何向量组件。即,向量的元素可以根据需要重新排序或复制。类似地,还支持仅使用指定矢量元素的遮罩。
绘制调用(draw call)调用图形API来绘制一组基元,从而使图形管道得以执行。每个可编程着色器阶段都有两种类型的输入:统一输入(uniform inputs),其值在整个绘制调用期间保持恒定(但可以在绘制调用之间更改),以及变化的输入(varying inputs),这些输入对于着色器处理的每个顶点或像素都是不同的。纹理是一种特殊的统一输入,它曾经总是应用于表面的彩色图像,但现在可以认为是任何大型数据数组。重要的是要注意,尽管着色器具有各种各样的输入,它们可以用不同的方式处理,但是输出却受到极大的限制。这是着色器与在通用处理器上执行的程序不同的最重要方式。基础虚拟机为不同类型的输入和输出提供特殊的寄存器。通过只读常量寄存器或常量缓冲区(constant registers or constant buffers)访问统一输入,之所以这样称呼,是因为它们的内容在一次绘制调用中是恒定的。可用的常量寄存器的数量远远大于可用于变化的输入或输出的寄存器的数量。这是因为变化的输入和输出需要针对每个顶点或像素分别存储,并且统一输入仅存储一次并在绘制调用中的所有顶点或像素之间重复使用。虚拟机还具有用于暂存空间的通用临时寄存器(temporary registers)。可以使用临时寄存器中的整数值对所有类型的寄存器进行数组索引。着色器虚拟机的输入和输出如图3.2所示。
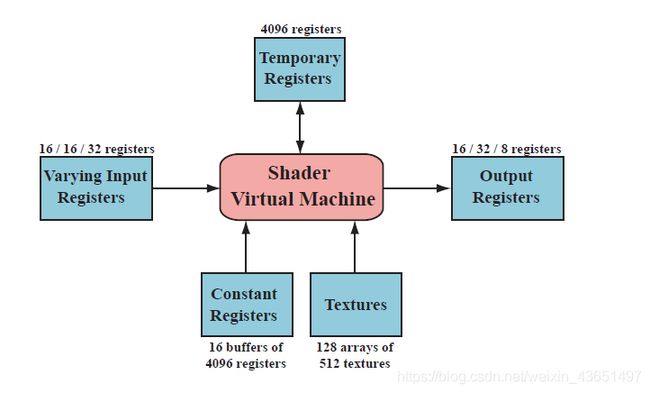
图3.2 DirectX 10下的通用着色器核心虚拟机体系结构和寄存器布局。每个资源旁边都会显示最大可用数量。 用斜杠分隔的三个数字表示顶点,几何和像素着色器的限制(从左到右)。
图形计算中常见的操作可在现代GPU上高效执行。 通常,最快的运算是标量和向量乘法,加法及其组合,例如乘加和点积。 其他运算,例如倒数,平方根,正弦,余弦,求幂和对数,往往会稍微花一些钱,但仍然相当快。 纹理化操作(请参见第6章)是有效的,但是其性能可能受到诸如等待检索访问结果所花费的时间等因素的限制。 着色语言通过*和+等运算符公开了这些运算中最常见的运算(例如加法和乘法)。 其余的则通过内在函数(intrinsic functions)公开,例如**atan(),dot(),log()*等。 对于更复杂的操作,也存在内在函数,例如矢量归一化和反射,叉积,矩阵转置和行列式等。
术语流控制(flow control)是指使用分支指令来更改代码执行流。这些指令用于实现高级语言构造,例如if和case语句,以及各种类型的循环。着色器支持两种类型的流控制。静态流量控制(static
flow control)*分支基于统一输入的值。这意味着代码流在绘图调用中是恒定的。静态流控制的主要好处是允许将相同的着色器用于各种不同的情况(例如,不同数量的灯光)。动态流量控制(Dynamic flow control)基于变化的输入值。这比静态流控制功能强大得多,但成本更高,尤其是如果在着色器调用之间代码流不规则地更改时。如第18.4.2节所述,一次在一个顶点或多个像素上评估着色器。如果流为某些元素选择了if分支,为其他元素选择了else分支,则必须对所有元素都评估两个分支(并且丢弃每个元素的未使用分支)。可以在加载程序之前或在运行时离线编译着色器程序。 与任何编译器一样,有用于生成不同输出文件和使用不同优化级别的选项。 编译后的着色器以文本字符串形式存储,并通过驱动程序传递给GPU。
3.3 可编程着色的演变(The Evolution of Programmable Shading)
可编程阴影框架的构想可以追溯到1984年,库克的阴影树(shade trees)[194]。一个简单的着色器及其相应的着色树如图3.3所示。 RenderMan着色语言[30,1283]是在80年代后期从这个想法发展而来的,如今仍广泛用于电影制作渲染。在GPU原生支持可编程着色器之前,曾有几次尝试通过多次渲染实时实现可编程着色操作的尝试。 Quake III:Arena脚本语言是该地区在1999年的第一个广泛的商业成功[558,604]。在2000年,Peercy等人。 [993]描述了一种系统,该系统转换了RenderMan着色器以在图形硬件上多次运行。他们发现GPU缺乏使该方法变得非常通用的两个功能:将计算结果用作纹理坐标(依赖于纹理读取(dependent texture reads))的能力以及对纹理和颜色缓冲区具有扩展范围和精度的数据类型的支持。提出的一种数据类型是一种新颖的(当时)16位浮点表示形式。目前,没有商用的GPU支持可编程着色,尽管大多数都具有高度可配置的管线[898]。

图3.3 一个简单的铜着色器的着色树及其相应的着色器语言程序。 (在库克[194]之后)
在2001年初,NVIDIA的GeForce 3是第一个支持可编程顶点着色器[778]的GPU,该着色器通过DirectX 8.0和OpenGL扩展公开。 这些着色器以一种类似于汇编的语言进行编程,该语言被驱动程序即时转换为微代码。 像素着色器也包含在DirectX 8.0中,但是像素着色器SM 1.1缺少实际的可编程性,驱动程序将受支持的非常有限的程序转换为纹理混合状态,然后将其连接到硬件寄存器组合器中。 这些程序不仅限于长度(12条指令或更少),而且缺少Peercy等人的两个要素(依赖纹理读取1和浮动数据)。 已经确定对于真正的可编程性至关重要。
着色器此时不允许进行流控制(分支),因此必须通过计算两个项以及在结果之间进行选择或内插来模拟条件。 DirectX定义了着色器模型(Shader Model)的概念,以区分具有不同着色器功能的硬件。 GeForce 3支持顶点着色器模型1.1和像素着色器模型1.1(着色器模型1.0用于从未发售的硬件)。 在2001年,GPU的发展更接近于通用的像素着色器编程模型。 DirectX 8.1添加了像素着色器模型1.2至1.4(每个都适用于不同的硬件),从而进一步扩展了像素着色器的功能,增加了其他指令,并为从属纹理读取提供了更多常规支持。
2002年见证了DirectX 9.0的发布,其中包括Shader Model 2.0(及其扩展版本2.X),该版本具有真正的可编程顶点和像素着色器。在OpenGL下使用各种扩展名也公开了类似的功能。添加了对任意相关纹理读取的支持以及16位浮点值的存储,最终完成了Peercy等人确定的一组要求。在2000年[993]。诸如指令,纹理和寄存器之类的着色器资源的限制增加了,因此着色器可以具有更复杂的效果。还增加了对流量控制的支持。着色器的长度和复杂性不断增长,使得汇编编程模型变得越来越麻烦。幸运的是,DirectX 9.0还包含了一种新的着色器编程语言,称为HLSL(高级着色语言)。 HLSL是由Microsoft与NVIDIA合作开发的,后者发布了名为Cg [818]的跨平台变体。大约在同一时间,OpenGL ARB(架构审查委员会)为OpenGL发布了某种类似的语言,称为GLSL [647,1084](也称为GLslang)。这些语言在很大程度上受到C编程语言的语法和设计理念的影响,并且还包含来自RenderMan着色语言的元素。
Shader Model 3.0于2004年推出,是一项增量改进,将可选功能转变为需求,进一步增加了资源限制,并增加了对顶点着色器中纹理读取的有限支持。 当在2005年末(Microsoft的Xbox 360)和2006年(Sony Computer Entertainment的PLAYSTATION 3系统)推出新一代游戏机时,它们都配备了Shader Model 3.0级GPU。 固定功能的流水线并没有完全失效:任天堂的Wii控制台于2006年底交付,带有固定功能的GPU [207]。 但是,几乎可以肯定这是该类型的最后一个控制台,因为即使是移动设备(例如手机)也可以使用可编程着色器(请参见第18.4.3节)。
提供了用于着色器开发的其他语言和环境。 例如,Sh语言[837,838]允许通过C ++库生成和组合GPU着色器[839]。 这个开源项目在许多平台上运行。 另一方面,已经引入了几种视觉编程工具,以允许艺术家(其中大多数人不太喜欢使用C语言编写程序)来设计着色器。 此类工具包括用于链接预定义着色器构建块的可视图形编辑器,以及将结果图形转换为着色语言(例如HLSL)的编译器。 图3.4中显示了一个这样的工具(mental mill,包含在NVIDIA的FX Composer 2中)的屏幕快照。 McGuire等。 [847]考察了视觉着色器编程系统,并提出了该概念的高层抽象扩展。
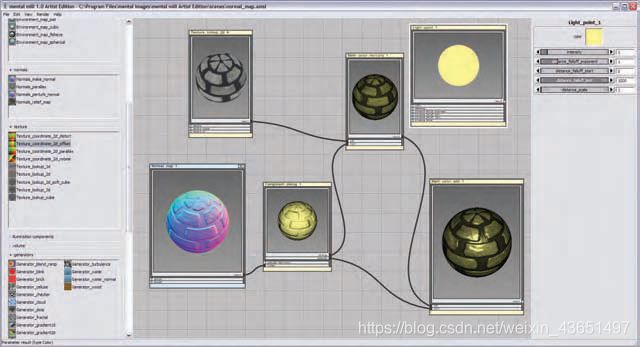
图3.4 用于着色器设计的可视着色器图形系统。 各种操作封装在功能框中,可在左侧选择。 选中后,每个功能框都有可调参数,如右图所示。 每个功能框的输入和输出相互链接以形成最终结果,如中间框架的右下方所示。 (Screenshot from mental mill, mental images, inc.)
编程性的下一步是2007年。ShaderModel 4.0(包含在DirectX 10.0 [123]中,也可以通过扩展在OpenGL中使用)引入了几个主要功能,例如几何体着色器和流输出。
Shader Model 4.0包括了用于所有着色器(顶点,像素和几何)的统一编程模型,这是前面介绍的通用着色器核心。 资源限制进一步增加,并增加了对整数数据类型(包括按位运算)的支持。 Shader Model 4.0的另一个显着特点是它仅支持高级语言着色器(DirectX的HLSL和OpenGL的GLSL),没有用户可写的汇编语言界面,如以前的模型中那样。
GPU供应商,Microsoft和OpenGL ARB继续完善和扩展可编程着色的功能。 除了现有API的新版本之外,诸如NVIDIA的CUDA [211]和AMD的CTM [994]之类的新编程模型还针对非图形应用程序。 第18.3.1节简要讨论了GPU(GPGPU)上的通用计算领域。
3.3.1 着色器模型的比较(Comparison of Shader Models)
尽管本章重点介绍Shader Model 4.0(撰写本文时是最新的),但开发人员经常需要支持使用较旧的着色模型的硬件。 因此,我们将简要比较几种最新的着色模型的功能:2.0(及其2.X的扩展版本),3.0和4.0.2。所有差异的列表不在本书讨论范围之内。 可从Microsoft开发人员网络(MSDN)及其DirectX SDK [261]获得详细信息。
由于它的发行版本不同,因此我们将重点放在DirectX上,而不是OpenGL不断发展的扩展级别,其中有些已由OpenGL体系结构审查委员会(ARB)批准,有些则针对特定供应商。 该扩展系统的优势在于,可以立即使用特定独立硬件供应商(independent hardware vendor,IHV)的尖端功能。 DirectX 9和更早的版本通过公开功能位来支持IHV变化,这些功能位可以检查以查看GPU是否支持功能。 借助DirectX 10,Microsoft大大地偏离了这种做法,转向了所有IHV必须支持的标准化模型。 尽管此处重点关注DirectX,但以下讨论也与OpenGL有关,因为相同时间段的关联基础GPU具有相同的功能。
表3.1比较了各种着色器模型的功能。在表中,VS代表顶点着色器,PS代表像素着色器(Shader Model 4.0引入了几何着色器,其功能类似于顶点着色器)。如果VS和PS均未出现,则该行适用于顶点着色器和像素着色器。由于虚拟机是4路SIMD,因此每个寄存器可以存储一到四个独立的值。指令插槽是指着色器可以包含的最大指令数。最高已执行的步骤表示考虑分支和循环的情况下可以执行的最大指令数。温度寄存器显示可用于存储中间结果的通用寄存器的数量。常量寄存器指示可以输入到着色器的常量值的数量。流控制,谓词是指通过分支指令和谓词计算条件表达式并执行循环的能力(即,有条件地执行或跳过指令的能力)。纹理显示了着色器可以访问的不同纹理的数量(请参见第6章)(每个纹理可以多次访问)。整数支持是指能够使用按位运算符和整数算术对整数数据类型进行运算的能力。 VS输入寄存器显示了顶点着色器可以访问的各种输入寄存器的数量。内插器寄存器是顶点着色器的输出寄存器和像素着色器的输入寄存器。之所以称它们为“顶点着色器”,是因为从顶点着色器输出的值在被发送到像素着色器之前在三角形上进行了插值。最后,PS输出寄存器显示可以从像素着色器输出的寄存器数,每个寄存器绑定到一个不同的缓冲区或渲染目标(render target)。
表3.1 (以图片代替)着色器功能,由DirectX着色器模型版本[123、261、946、1055]列出

3.4 顶点着色器(The Vertex Shader)
顶点着色器是图3.1所示功能管线中的第一阶段。尽管这是进行任何图形处理的第一阶段,但值得注意的是,在此阶段之前发生了一些数据操作。在DirectX所谓的输入汇编器(input assembler)[123,261]中,可以将许多数据流编织在一起,以形成沿管道发送的一组顶点和图元。例如,一个对象可以由一个位置阵列和一个颜色阵列表示。输入汇编器将通过本质上创建具有位置和颜色的顶点来创建此对象的三角形(或线或点)。第二个对象可以使用相同的位置数组(以及不同的模型转换矩阵)和不同的颜色数组表示。数据表示在12.4.5节中详细讨论。输入汇编器中也支持执行实例化(instancing)。这允许一个对象被绘制多次,每个实例具有一些变化的数据,所有这些都可以通过一个绘制调用进行。第15.4.2节介绍了实例化的使用。 DirectX 10中的输入汇编器还用标识符编号标记每个实例,图元和顶点,随后的任何着色器阶段均可访问该标识符编号。对于早期的着色器模型,必须将此类数据显式添加到模型中。
三角形网格由一组顶点和附加信息表示,这些信息描述了形成每个三角形的顶点。 顶点着色器是处理三角形网格的第一阶段。 顶点着色器无法获取描述形成了哪些三角形的数据。 顾名思义,它专门处理传入的顶点。 一般而言,顶点着色器提供了一种修改,创建或忽略与每个多边形的顶点关联的值的方法,例如其颜色,法线,纹理坐标和位置。 通常,顶点着色器程序会将顶点从模型空间转换为同构的剪辑空间。 顶点着色器至少必须始终输出此位置。
此功能于2001年随DirectX 8首次引入。由于它是流水线的第一阶段,很少调用,因此可以在GPU或CPU上实现,然后将结果发送到GPU进行光栅化。 这样做使得从较旧的硬件到较新的硬件的转换是速度问题,而不是功能问题。 当前生产的所有GPU都支持顶点着色。
顶点着色器本身与前面3.2节中描述的通用核心虚拟机几乎相同。 传入的每个顶点都由顶点着色器程序处理,然后输出在三角形或直线上插值的多个值。3顶点着色器既不能创建也不能破坏顶点,并且一个顶点生成的结果不能传递给 另一个顶点。 由于每个顶点都是独立处理的,因此可以将GPU上任意数量的着色器处理器并行应用于传入的顶点流。
随后的章节介绍了许多顶点着色器效果,例如阴影体积创建,用于动画关节的顶点混合以及轮廓渲染。 顶点着色器的其他用途包括:
- 镜头效果(Lens effects),使屏幕出现鱼眼,在水下或以其他方式变形。
- 定义对象(Object definition),通过仅创建一次网格并使其由顶点着色器变形来进行对象定义。
- 对象扭转、弯曲和锥化操作。
- 程序变形(Procedural deformations),例如旗帜,布料或水的移动[592]。
- 原始创作(Primitive creation),通过将退化的网格发送到管道中,并根据需要为其分配面积。 较新的GPU中的几何着色器已取代了此功能。
- 通过将整个帧缓冲区的内容用作经过程序变形的屏幕对齐网格上的纹理,可以实现页面卷曲,热雾,水波纹和其他效果。
- 顶点纹理获取(在SM 3.0及更高版本中可用)可用于将纹理应用于顶点网格,从而可以廉价地应用海洋表面和地形高度场[23,703,887]。
使用顶点着色器完成的一些变形如图3.5所示。

3.5 几何着色器(The Geometry Shader)
几何着色器是在2006年末发布的DirectX 10中添加到硬件加速的图形管道中的。它位于管道中顶点着色器之后,并且可以选择使用。虽然是Shader Model 4.0的必需部分,但在较早的着色器模型中未使用它。
几何着色器的输入是单个对象及其关联的顶点。该对象通常是网格,线段或仅是点中的三角形。另外,扩展的图元可以由几何着色器定义和处理。特别是,可以传入三角形外部的三个附加顶点,并且可以使用折线上的两个相邻顶点。见图3.6。
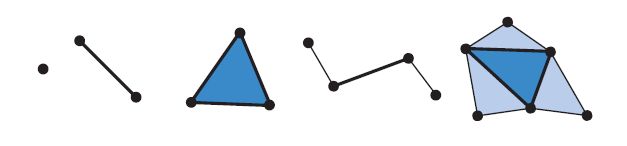
几何着色器处理此图元并输出零个或多个图元。输出为点,折线和三角形条的形式。例如,通过一次调用几何着色器程序,可以输出多个三角带。重要的是,几何着色器根本不会生成任何输出。通过这种方式,可以通过编辑顶点,添加新图元以及删除其他图元来选择性地修改网格。
几何着色器程序设置为输入一种类型的对象并输出一种类型的对象,并且这些类型不必匹配。例如,可以输入三角形,并将其质心输出为点,每个三角形输入一个。即使输入和输出对象类型匹配,也可以省略或扩展每个顶点处携带的数据。例如,可以计算三角形的平面法线并将其添加到每个输出顶点的数据中。与顶点着色器相似,几何着色器必须为生成的每个顶点输出均匀的剪切空间位置。
保证几何着色器以与输入相同的顺序从图元输出结果。这会影响性能,因为如果许多着色器单元并行运行,则必须保存和排序结果。作为功能和效率之间的折衷,在Shader Model 4.0中,每次执行最多可以生成1024个32位值。因此,以单个叶子作为输入生成一千个灌木叶子是不可行的,也不是几何着色器的推荐用法。不建议将简单表面细分为更复杂的三角形网格[123]。这个阶段更多地是关于以编程方式修改输入的数据或制作有限数量的副本,而不是大量复制或放大它。例如,一种用途是生成六个转换后的数据副本,以便同时渲染立方体贴图的六个面;见8.4.3节。可以利用几何着色器的其他算法包括从点数据创建各种大小的粒子,沿着轮廓拉伸鳍以进行毛发渲染以及为阴影算法找到对象边缘。有关更多信息,请参见图3.7。这些和其他用途将在本书的其余部分中讨论。

3.5.1 流输出(Stream Output)
GPU管线的标准用法是通过顶点着色器发送数据,然后栅格化生成的三角形并在像素着色器中处理它们。 始终通过管道传递的数据,无法访问中间结果。 流输出的想法是在Shader Model 4.0中引入的。 在顶点着色器(以及可选的几何形状着色器)处理了顶点之后,除了可以发送到栅格化阶段之外,还可以将它们输出到流(即有序数组)中。 实际上,光栅化可以完全关闭,然后将管道纯粹用作非图形流处理器。 可以将通过这种方式处理的数据通过管道发送回去,从而允许进行迭代处理。 如第10.7节所述,这种类型的操作对于模拟流水或其他粒子效果特别有用。
3.6 像素着色器(The Pixel Shader)
顶点和几何着色器执行完操作后,便会裁剪并设置图元以进行栅格化,如上一章所述。
流水线的这一部分在其处理步骤中是相对固定的,而不是可编程的。遍历每个三角形,并在整个三角形的区域内插值顶点的值。 像素着色器是下一个可编程阶段。 在OpenGL中,此阶段称为片段着色器(fragment shader),在某些方面它是一个更好的名称。 这个想法是,三角形完全或部分覆盖每个像素的单元,并且所描绘的材质是不透明或透明的。 光栅化器不会直接影响像素存储的颜色,而是会生成或多或少地描述三角形如何覆盖像素单元的数据。 然后是在合并期间,使用此片段的数据来修改存储在像素处的内容。
顶点着色器程序的输出有效地成为像素着色器程序的输入。 在Shader Model 4.0.5中,总共16个矢量(每个4个值)可以从顶点着色器传递到像素着色器。使用几何着色器时,可以将32个矢量输出到像素着色器[261]。
Shader Model 3.0的引入专门为像素着色器添加了其他输入。 例如,添加了三角形的哪一侧可见作为输入标志。 该知识对于一次通过每个三角形的正面和背面渲染不同的材质非常重要。 片段的屏幕位置也可用于像素着色器。
像素着色器可以访问相邻像素的信息(尽管是间接的)的一种情况是梯度或导数信息的计算。像素着色器可以获取任何值并计算其沿x和y屏幕轴的每个像素的变化量。这对于各种计算和纹理寻址很有用。这些梯度对于诸如过滤之类的操作尤其重要(请参见第6.2.2节)。大多数GPU通过处理2x2或更多的像素来实现此功能。当像素着色器请求渐变值时,将返回相邻像素之间的差异。此实现的一个结果是,无法在受动态流控制影响的着色器的某些部分中访问渐变信息,组中的所有像素都必须处理相同的指令。这是一个基本限制,即使在脱机渲染系统中也存在[31]。访问渐变信息的能力是像素着色器的独特功能,其他任何可编程着色器阶段均不共享。
像素着色器程序通常会设置片段颜色以在最终合并阶段进行合并。光栅化阶段生成的深度值也可以由像素着色器修改。模板缓冲区值不可修改,而是传递到合并阶段。在SM 2.0及更高版本中,像素着色器也可以丢弃传入的片段数据,即不生成任何输出。此类操作可能会降低性能,因为通常无法再使用GPU通常执行的优化。有关详细信息,请参见第18.3.7节。雾计算和alpha测试等操作已从SM 4.0中的合并操作变为像素着色器计算[123]。
当前的像素着色器能够执行大量处理。在单个渲染过程中计算任意数量的值的能力引发了多个渲染目标(multiple render targets,MRT)的想法。代替将像素着色器程序的结果保存到单个颜色缓冲区中,可以为每个片段生成多个矢量并将其保存到不同的缓冲区中。这些缓冲区必须具有相同的尺寸,并且某些体系结构要求它们各自具有相同的位深度(尽管根据需要使用不同的格式)。表3.1中的PS输出寄存器的数目是指可访问的独立缓冲器的数目,即4或8。与可显示的彩色缓冲器不同,在任何其他目标上还有其他限制。例如,通常不能执行抗锯齿。即使有这些限制,MRT功能还是更有效地执行渲染算法的有力辅助。如果要从同一组数据中计算多个中间结果图像,则仅需要一次渲染通道,而不是每个输出缓冲区一次。与MRT相关的另一个关键功能是从这些结果图像中读取纹理的能力。
3.7 合并阶段(The Merging Stage)
如第2.4.4节所述,合并阶段是将各个片段(在像素着色器中生成)的深度和颜色与帧缓冲区组合在一起的阶段。 此阶段是模板缓冲区和Z缓冲区操作发生的地方。 此阶段中发生的另一种操作是颜色混合,它最常用于透明度和合成操作(请参见5.7节)。
合并阶段在固定功能阶段(例如剪切)和完全可编程的着色器阶段之间占据了一个有趣的中间点。 尽管它不是可编程的,但其操作是高度可配置的。 可以将颜色混合设置为执行大量不同的操作。 最常见的是涉及颜色和Alpha值的乘法,加法和减法的组合,但是其他操作(例如最小和最大值)以及按位逻辑操作也是可能的。 DirectX 10添加了将像素着色器中的两种颜色与帧缓冲区颜色进行混合的功能,此功能称为双色混合(dual-color blending)。
如果采用了MRT功能,则可以在多个缓冲区上执行混合。 DirectX 10.1引入了对每个MRT缓冲区执行不同混合操作的功能。 在以前的版本中,始终对所有缓冲区执行相同的混合操作(请注意,双色混合与MRT不兼容)。
3.8 效果(Effects)
到目前为止,流水线之旅已集中在各个可编程阶段。 虽然顶点,几何和像素着色器程序是控制这些阶段所必需的,但它们并不是真空存在的。 首先,单独的着色器程序在隔离方面不是特别有用:顶点着色器程序将其结果提供给像素着色器。 必须加载这两个程序才能完成任何工作。 程序员必须对顶点着色器的输出与像素着色器的输入进行一些匹配。 可以通过几次遍历执行的任何数量的着色器程序来产生特定的渲染效果。 除了着色器程序本身之外,有时还必须在特定配置中设置状态变量,以使这些程序正常工作。 例如,渲染器的状态包括是否以及如何使用Z缓冲区和模板缓冲区,以及片段如何影响现有像素值(例如,替换,添加或混合)。
由于这些原因,各个小组已经开发了效果语言,例如HLSL FX,CgFX和COLLADA FX。 效果文件尝试封装执行特定渲染算法所需的所有相关信息[261,974]。 它通常定义一些可由应用程序分配的全局参数。 例如,单个效果文件可能会定义渲染令人信服的塑料材料所需的顶点和像素着色器。 它将显示诸如塑料颜色和粗糙度之类的参数,以便可以针对每个渲染的模型更改这些参数,但使用相同的效果文件。
为了展示效果文件的风格,我们将逐步介绍一个取自NVIDIA FX Composer 2效果系统的精简示例。 DirectX 9 HLSL效果文件实现了Gooch阴影的非常简化的形式[423]。 Gooch阴影的一部分是使用表面法线并将其与灯光的位置进行比较。 如果法线指向灯光,则使用温暖的色调为表面着色; 如果指向不对,则使用冷色调。介于两者之间的角度在这两种用户定义的颜色之间进行插值。 这种阴影技术是非真实感渲染的一种形式,这是第11章的主题。图3.8显示了这种效果的示例。

效果变量在效果文件的开头定义。 前几个变量是不可调整的,与摄像机位置相关的参数会自动跟踪效果:
float4x4 WorldXf : World;
float4x4 WorldITXf : WorldInverseTranspose;
float4x4 WvpXf : WorldViewProjection;
语法为id类型:语义(type id:semantic)。 float4x4类型用于矩阵,名称是用户定义的,语义是内置名称。 顾名思义,WorldXf是模型到世界的转换矩阵,WorldITXf是该矩阵的逆转置,而WvpXf是从模型空间转换到摄影机剪辑空间的矩阵。 这些具有公认语义的值应由应用程序提供,而不在用户界面中显示。 接下来,指定用户定义的变量:
float3 Lamp0Pos : Position <
string Object = "PointLight0";
string UIName = "Lamp 0 Position";
string Space = "World";
> = {-0.5f, 2.0f, 1.25f};
float3 WarmColor <
string UIName = "Gooch Warm Tone";
string UIWidget = "Color";
> = {1.3f, 0.9f, 0.15f};
> float3 CoolColor <
string UIName = "Gooch Cool Tone";
string UIWidget = "Color";
> = {0.05f, 0.05f, 0.6f};
此处在尖括号**<>**中提供了一些其他注释,然后指定了默认值。 注释是特定于应用程序的,对效果或着色器编译器没有任何意义。 此类注释可以由应用程序查询。 在这种情况下,注释描述了如何在用户界面中公开这些变量。 接下来定义着色器输入和输出的数据结构:
struct appdata {
float3 Position : POSITION;
float3 Normal : NORMAL;
};
struct vertexOutput {
float4 HPosition : POSITION;
float3 LightVec : TEXCOORD1;
float3 WorldNormal : TEXCOORD2;
};
appdata定义模型中每个顶点的数据,因此定义了顶点着色器程序的输入数据。 vertexOutput是顶点着色器生成和消耗的像素着色器。 使用**TEXCOORD ***作为输出名称是流水线演变的产物。 首先,可以将多个纹理附着到一个表面,因此这些附加数据字段称为纹理坐标。 实际上,这些字段保存从顶点传递到像素着色器的所有数据。 接下来,定义各种着色器程序代码元素。 我们只有一个顶点着色器程序:
vertexOutput std_VS(appdata IN) {
vertexOutput OUT;
float4 No = float4(IN.Normal,0);
OUT.WorldNormal = mul(No,WorldITXf).xyz;
float4 Po = float4(IN.Position,1);
float4 Pw = mul(Po,WorldXf);
OUT.LightVec = (Lamp0Pos - Pw.xyz);
OUT.HPosition = mul(Po,WvpXf);
return OUT;
}
该程序首先使用矩阵乘法计算世界空间中的表面法线。 变换是下一章的主题,因此在此我们将不解释为什么使用逆转置。 还可以通过应用屏幕外变换来计算世界空间中的位置。 从光的位置减去该位置以获得从表面到光的方向向量。 最后,将对象的位置转换为剪辑空间,以供光栅化器使用。 这是任何顶点着色器程序的必需输出。 给定光的方向和世界空间中的表面法线,像素着色器程序将计算表面颜色:
float4 gooch_PS(vertexOutput IN) : COLOR
{
float3 Ln = normalize(IN.LightVec);
float3 Nn = normalize(IN.WorldNormal);
float ldn = dot(Ln,Nn);
float mixer = 0.5 * (ldn + 1.0);
float4 result = lerp(CoolColor, WarmColor, mixer);
return result;
}
向量Ln是归一化的光方向,Nn是归一化的表面法线。通过归一化,这两个向量的点积ldn表示它们之间角度的余弦。我们想使用此值在冷色调和暖色调之间线性插值。函数lerp()期望一个介于0和1之间的混合器值,其中0表示使用CoolColor,1表示使用WarmColor,以及介于两者之间的值来混合两者。由于角度的余弦值的取值为[1,1],因此mixer值将此范围转换为[0,1]。然后,该值用于混合色调并生成具有适当颜色的片段。这些着色器是功能。效果文件可以包含许多功能,并且可以包括其他效果文件中的常用功能。一个pass通常包括顶点和像素(和几何)着色器,以及通过所需的任何状态设置。一个technique是一组一个或多个通过以产生所需效果的过程。这个简单的文件只有一项技术,只有一项:
technique Gooch < string Script = "Pass=p0;"; > {
pass p0 < string Script = "Draw=geometry;"; > {
VertexShader = compile vs_2_0 std_VS();
PixelShader = compile ps_2_a gooch_PS();
ZEnable = true;
ZWriteEnable = true;
ZFunc = LessEqual;
AlphaBlendEnable = false;
}
}
这些状态设置强制Z缓冲区以正常方式使用,以进行读写操作,如果片段的深度小于或等于所存储的z深度,则通过传递。 Alpha混合功能已关闭,因为使用此技术的模型被认为是不透明的。 这些规则意味着,如果片段的z深度等于或小于存储的片段深度,则使用计算出的片段颜色替换相应像素的颜色。 换句话说,使用标准的Z缓冲区用法。
多种技术可以存储在同一效果文件中。 这些技术通常是具有相同效果的变体,每种变体针对的是不同的着色器模型(例如,SM 2.0与SM 3.0)。 多种效果都是可能的。 图3.9仅展示了现代可编程着色器管线的功能。 效果通常会封装相关技术。 已经开发出各种方法来管理着色器集[845、847、887、974、1271]。

我们已经结束了GPU本身的浏览。 GPU还有很多其他功能,以及可以使用和组合其功能的多种方式。 调整以利用这些功能的相关理论和算法是本书的重点。 有了这些基础知识之后,重点将转移到提供对转换和视觉外观(管道中的关键元素)的深入了解。
Further Reading and Resources
David Blythe在DirectX 10 [123]上的论文很好地概述了现代GPU管道及其设计背后的原理,并提供了相关文章的参考。
仅关于编程顶点和像素着色器的信息就可以轻松地完成一本书。我们的最佳建议:访问ATI [50]和NVIDIA [944]开发人员网站,以获取有关最新技术的信息。他们免费的FX Composer 2和RenderMonkey交互式着色器设计工具套件提供了一种绝佳的方式来试用着色器,对其进行修改并查看使它们打勾的原因。 Sander [1105]为支持SM 2.0的硬件在HLSL中提供了固定功能管道的实现。
要学习着色器编程的形式方面,需要花费一些工作。 OpenGL着色语言书(OpenGL Shading Language)[1084]从《红皮书》(969)遗漏的地方开始,描述了GLSL(OpenGL可编程着色语言)。为了学习HLSL,DirectX API随每个新版本而不断发展。有关其SDK以外的相关链接和书籍,请参见本书的网站(http://www.realtimerendering.com)。 O Rorke的文章[974]提供了有关效果和管理着色器的有效方法的可读介绍。 Cg语言提供了一层抽象,可以导出到许多主要的API和平台,同时还为主要的建模和动画程序包提供了插件工具。 Sh元编程语言仍然更加抽象,本质上是充当C ++库的工作,该库将相关的图形代码映射到GPU。
有关高级着色器技术的信息,请首先阅读GPU Gems和ShaderX系列书籍。游戏编程宝石(Game Programming Gems)一书也有一些相关文章。 DirectX SDK [261]有许多重要的着色器和算法示例。