解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉Transformer
机器之心报道
来源:机器之心
来自字节跳动的研究者提出了一种能在现实工业场景中有效部署的下一代视觉 Transformer,即 Next-ViT。Next-ViT 能像 CNN 一样快速推断,并有 ViT 一样强大的性能。
由于复杂的注意力机制和模型设计,大多数现有的视觉 Transformer(ViT)在现实的工业部署场景中不能像卷积神经网络(CNN)那样高效地执行。这就带来了一个问题:视觉神经网络能否像 CNN 一样快速推断并像 ViT 一样强大?
近期一些工作试图设计 CNN-Transformer 混合架构来解决这个问题,但这些工作的整体性能远不能令人满意。基于此,来自字节跳动的研究者提出了一种能在现实工业场景中有效部署的下一代视觉 Transformer——Next-ViT。从延迟 / 准确性权衡的角度看,Next-ViT 的性能可以媲美优秀的 CNN 和 ViT。

论文地址:https://arxiv.org/pdf/2207.05501.pdf
Next-ViT 的研究团队通过开发新型的卷积块(NCB)和 Transformer 块(NTB),部署了友好的机制来捕获局部和全局信息。然后,该研究提出了一种新型混合策略 NHS,旨在以高效的混合范式堆叠 NCB 和 NTB,从而提高各种下游任务的性能。
大量实验表明,Next-ViT 在各种视觉任务的延迟 / 准确性权衡方面明显优于现有的 CNN、ViT 和 CNN-Transformer 混合架构。在 TensorRT 上,Next-ViT 与 ResNet 相比,在 COCO 检测任务上高出 5.4 mAP(40.4 VS 45.8),在 ADE20K 分割上高出 8.2% mIoU(38.8% VS 47.0%)。同时,Next-ViT 达到了与 CSWin 相当的性能,并且推理速度提高了 3.6 倍。在 CoreML 上,Next-ViT 在 COCO 检测任务上比 EfficientFormer 高出 4.6 mAP(42.6 VS 47.2),在 ADE20K 分割上高出 3.5% mIoU(从 45.2% 到 48.7%)。
方法
Next-ViT 的整体架构如下图 2 所示。Next-ViT 遵循分层金字塔架构,在每个阶段配备一个 patch 嵌入层和一系列卷积或 Transformer 块。空间分辨率将逐步降低为原来的 1/32,而通道维度将按阶段扩展。
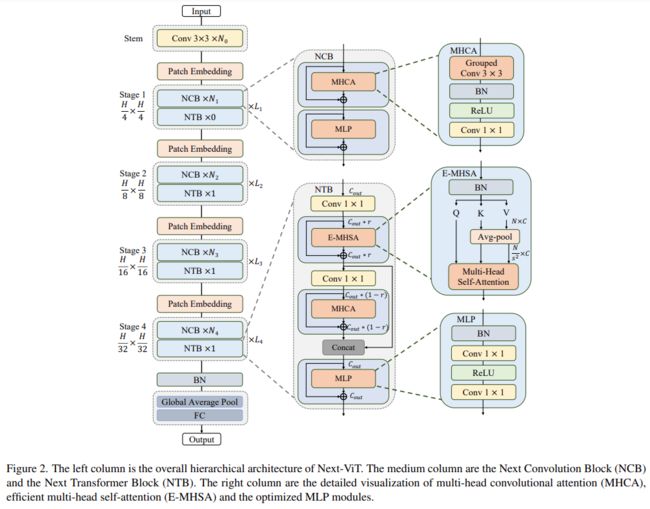
研究者首先深入设计了信息交互的核心模块,并分别开发强大的 NCB 和 NTB 来模拟视觉数据中的短期和长期依赖关系。NTB 中还进行了局部和全局信息的融合,进一步提高了建模能力。最后,为了克服现有方法的固有缺陷,该研究系统地研究了卷积和 Transformer 块的集成方式,提出了 NHS 策略,来堆叠 NCB 和 NTB 构建新型 CNN-Transformer 混合架构。
NCB
研究者分析了几种经典结构设计,如下图 3 所示。ResNet [9] 提出的 BottleNeck 块由于其在大多数硬件平台上固有的归纳偏置和易于部署的特性,长期以来一直在视觉神经网络中占据主导地位。不幸的是,与 Transformer 块相比,BottleNeck 块的有效性欠佳。ConvNeXt 块 [20] 通过模仿 Transformer 块的设计,对 BottleNeck 块进行了现代化改造。虽然 ConvNeXt 块提高了网络性能,但它在 TensorRT/CoreML 上的推理速度受到低效组件的严重限制。Transformer 块在各种视觉任务中取得了优异的成绩,然而 Transformer 块的推理速度比 TensorRT 和 CoreML 上的 BottleNeck 块要慢得多,因为其注意力机制比较复杂,这在大多数现实工业场景中是难以承受的。
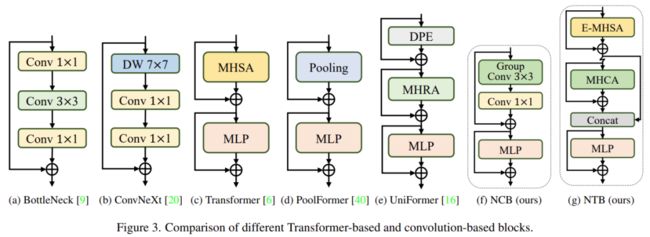
为了克服上述几种块的问题,该研究提出了 Next Convolution Block (NCB),它在保持 BottleNeck 块的部署优势的同时获得了 Transformer 块的突出性能。如图 3(f) 所示,NCB 遵循 MetaFormer (已被证实对 Transformer 块至关重要) 的一般架构。
此外,一个高效的基于注意力的 token 混合器同样重要。该研究设计了一种多头卷积注意力(MHCA)作为部署卷积操作的高效 token 混合器,并在 MetaFormer [40] 的范式中使用 MHCA 和 MLP 层构建 NCB。
NTB
NCB 已经有效地学习了局部表征,下一步需要捕获全局信息。Transformer 架构具有很强的捕获低频信号的能力,这些信号能够提供全局信息(例如全局形状和结构)。
然而,相关研究已经发现,Transformer 块可能会在一定程度上恶化高频信息,例如局部纹理信息。不同频段的信号在人类视觉系统中是必不可少的,它们以某种特定的方式融合,以提取更多本质和独特的特征。
受这些已知结果的影响,该研究开发了 Next Transformer Block (NTB),以在轻量级机制中捕获多频信号。此外,NTB 可用作有效的多频信号混频器,进一步增强整体建模能力。
NHS
近期一些工作努力将 CNN 和 Transformer 结合起来进行高效部署。如下图 4(b)(c) 所示,它们几乎都在浅层阶段采用卷积块,在最后一两个阶段仅堆叠 Transformer 块,这种结合方式在分类任务上是有效的。但该研究发现这些混合策略很容易在下游任务(例如分割和检测)上达到性能饱和。原因是,分类任务仅使用最后阶段的输出进行预测,而下游任务(例如分割和检测)通常依赖每个阶段的特征来获得更好的结果。这是因为传统的混合策略只是在最后几个阶段堆叠 Transformer 块,浅层无法捕获全局信息。
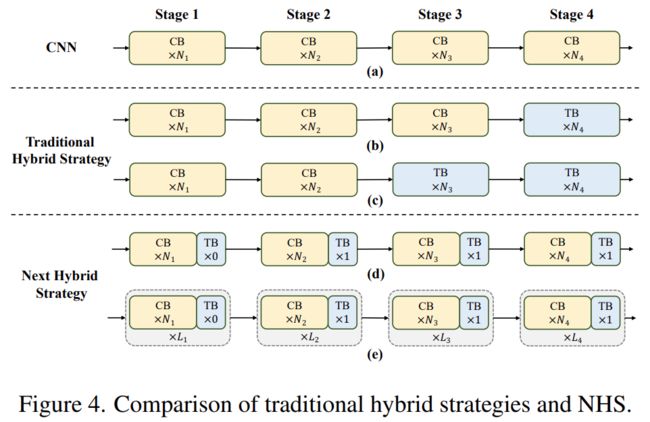
该研究提出了一种新的混合策略 (NHS),创造性地将卷积块 (NCB) 和 Transformer 块 (NTB) 与 (N + 1) * L 混合范式结合在一起。NHS 在控制 Transformer 块比例的情况下,显著提升了模型在下游任务上的性能,并实现了高效部署。
首先,为了赋予浅层捕获全局信息的能力,该研究提出了一种(NCB×N+NTB×1)模式混合策略,在每个阶段依次堆叠 N 个 NCB 和一个 NTB,如图 4(d) 所示。具体来说,Transformer 块 (NTB) 放置在每个阶段的末尾,使得模型能够学习浅层中的全局表征。该研究进行了一系列实验来验证所提出的混合策略的优越性,不同混合策略的性能如下表 1 所示。
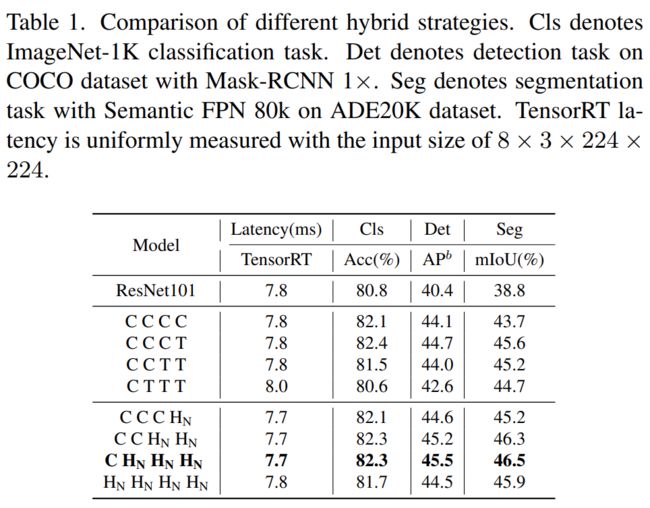
此外,如下表 2 所示,大模型的性能会逐渐达到饱和。这种现象表明,通过扩大 (NCB × N + NTB × 1) 模式的 N 来扩大模型大小,即简单地添加更多的卷积块并不是最佳选择,(NCB × N + NTB × 1)模式中的 N 值可能会严重影响模型性能。
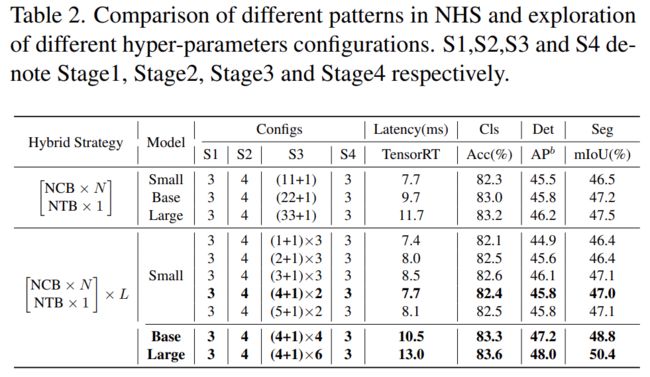
因此,研究者开始通过广泛的实验探索 N 的值对模型性能的影响。如表 2(中)所示,该研究在第三阶段构建了具有不同 N 值的模型。为了构建具有相似延迟的模型以进行公平比较,该研究在 N 值较小时堆叠 L 组 (NCB × N + NTB × 1) 模式。
如表 2 所示,第三阶段 N = 4 的模型实现了性能和延迟之间的最佳权衡。该研究通过在第三阶段扩大 (NCB × 4 + NTB × 1) × L 模式的 L 来进一步构建更大的模型。如表 2(下)所示,Base(L = 4)和 Large(L = 6)模型的性能相对于小模型有显著提升,验证了所提出的(NCB × N + NTB × 1)× L 模式的一般有效性。
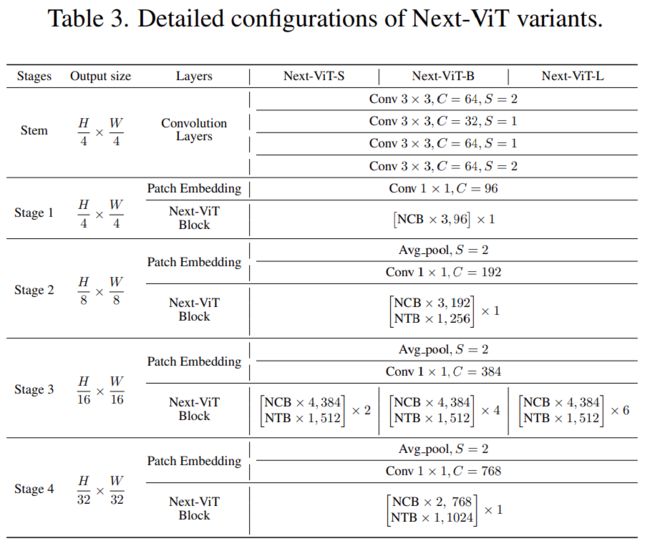
最后,为了提供与现有 SOTA 网络的公平比较,研究者提出了三个典型的变体,即 Next-ViTS/B/L。
实验结果
ImageNet-1K 上的分类任务
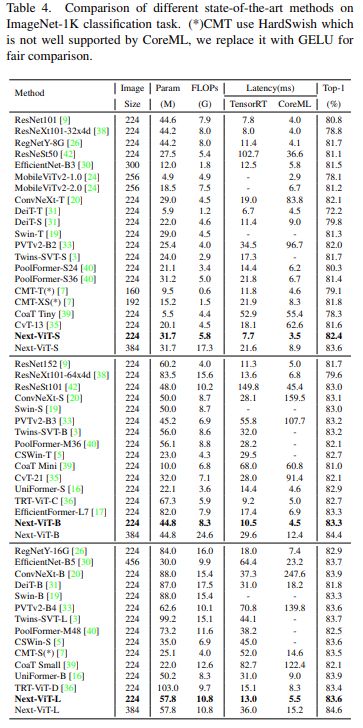
与最新的 SOTA 方法(例如 CNN、ViT 和混合网络)相比,Next-ViT 在准确性和延迟之间实现了最佳权衡,结果如下表 4 所示。
ADE20K 上的语义分割任务
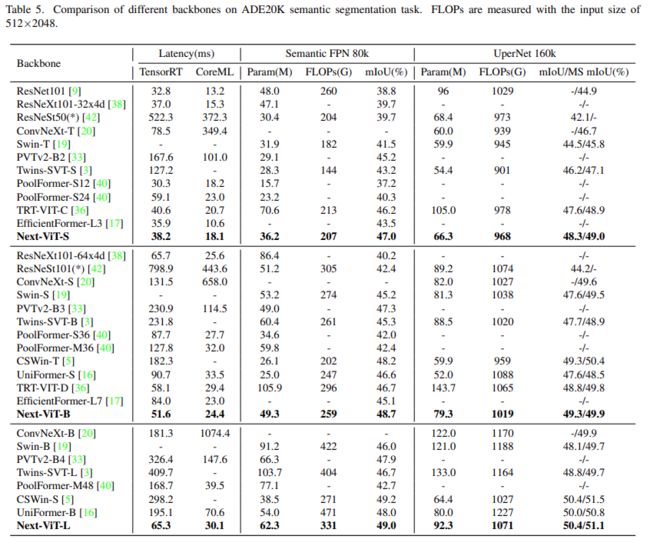
该研究将 Next-ViT 与 CNN、ViT 和最近一些混合架构针对语义分割任务进行了比较。如下表 5 所示,大量实验表明,Next-ViT 在分割任务上具有出色的潜力。
目标检测和实例分割
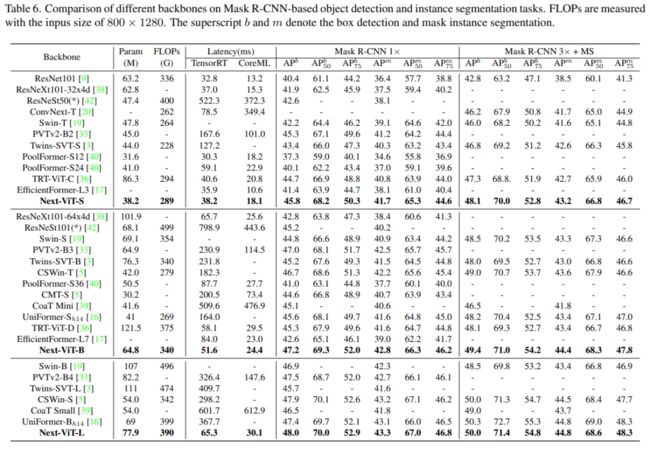
在目标检测和实例分割任务上,该研究将 Next-ViT 与 SOTA 模型进行了比较,结果如下表 6 所示。
消融实验和可视化
为了更好地理解 Next-ViT,研究者通过评估其在 ImageNet-1K 分类和下游任务上的性能来分析每个关键设计的作用,并将输出特征的傅里叶谱和热图可视化,以显示 Next-ViT 的内在优势。
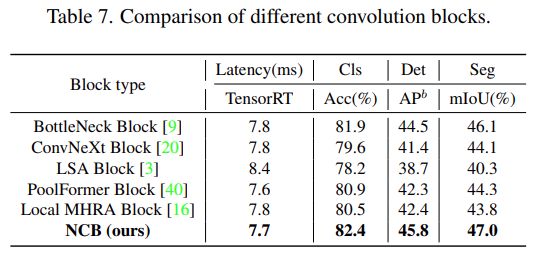
如下表 7 所示,NCB 在所有三个任务上实现了最佳延迟 / 准确性权衡。
对于 NTB 块,该研究探讨了 NTB 的收缩率 r 对 Next-ViT 整体性能的影响,结果如下表 8 所示,减小收缩率 r 将减少模型延迟。
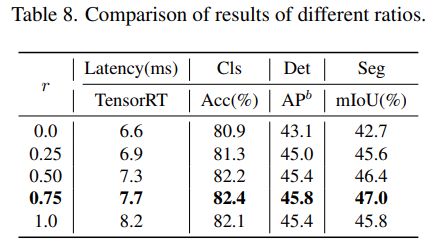
此外,r = 0.75 和 r = 0.5 的模型比纯 Transformer (r = 1) 的模型具有更好的性能。这表明以适当的方式融合多频信号将增强模型的表征学习能力。特别是,r = 0.75 的模型实现了最佳的延迟 / 准确性权衡。这些结果说明了 NTB 块的有效性。
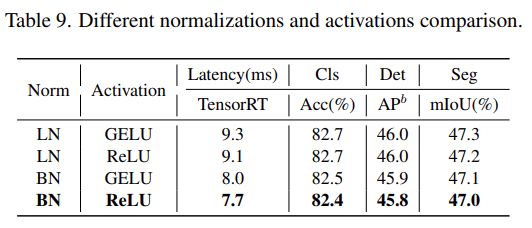
该研究进一步分析了 Next-ViT 中不同归一化层和激活函数的影响。如下表 9 所示,LN 和 GELU 虽然带来一些性能提升,但在 TensorRT 上的推理延迟明显更高。另一方面,BN 和 ReLU 在整体任务上实现了最佳的延迟 / 准确性权衡。因此,Next-ViT 统一使用 BN 和 ReLU,以便在现实工业场景中进行高效部署。
最后,该研究可视化了 ResNet、Swin Transformer 和 Next-ViT 的输出特征的傅里叶谱和热图,如下图 5(a) 所示。ResNet 的频谱分布表明卷积块倾向于捕获高频信号、难以关注低频信号;ViT 擅长捕捉低频信号而忽略高频信号;而Next-ViT 能够同时捕获高质量的多频信号,这显示了 NTB 的有效性。
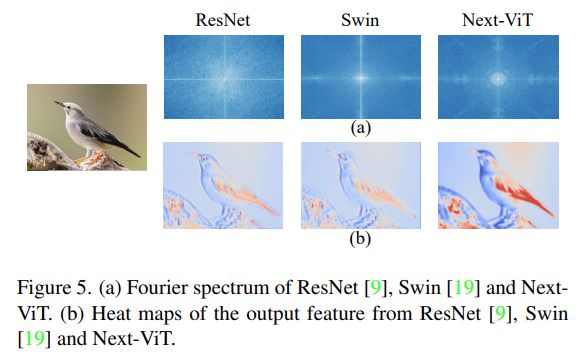
此外,如图 5(b)所示,Next-ViT 能比 ResNet 和 Swin 捕获更丰富的纹理信息和更准确的全局信息,这说明 Next-ViT 的建模能力更强。
——The End——

分享
收藏
点赞
在看