【时序】时间序列数据预处理
目录
1. 时间戳转换
2. 缺失值处理
3. 去噪
1)滚动平均值
2)傅里叶变换
4. 异常点检测
1)基于滚动统计的方法
2)孤立森林
3)K-means 聚类
为了分析预处理结果,我们后续使用 Kaggle 的 Air Passenger 数据集。
1. 时间戳转换
时间序列数据通常以非结构化格式存在,即时间戳可能混合在一起并且没有正确排序。另外在大多数情况下,日期时间列具有默认的字符串数据类型,在对其应用任何操作之前,必须先将数据时间列转换为日期时间数据类型。
Python代码:
import pandas as pd
passenger = pd.read_csv('AirPassengers.csv')
passenger['Date'] = pd.to_datetime(passenger['Date'])
passenger.sort_values(by=['Date'], inplace=True, ascending=True)结果:
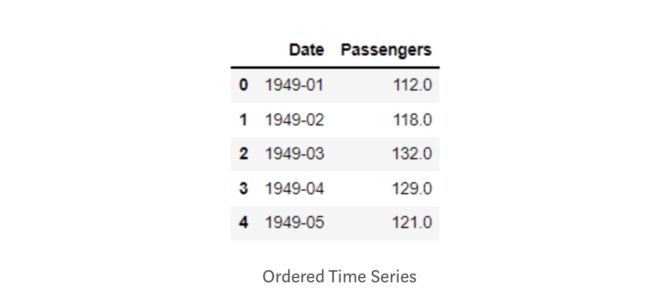
2. 缺失值处理
插值是一种常用的时间序列缺失值插补技术。它有助于使用周围的两个已知数据点估计丢失的数据点。这种方法简单且最直观。传统的插补技术不适用于时间序列数据,因为接收值的顺序很重要。 处理时序数据时可以使用以下的方法:
-
基于时间的插值
-
样条插值
-
线性插值
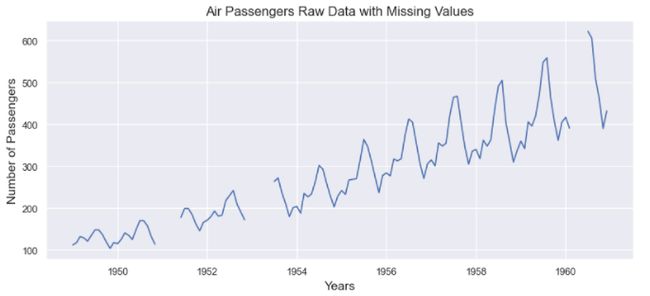
数据在插补之前:
以上三个方法的Python代码:
passenger[‘Linear’] = passenger[‘Passengers’].interpolate(method=’linear’)
passenger[‘Spline order 3’] = passenger[‘Passengers’].interpolate(method=’spline’, order=3)
passenger[‘Time’] = passenger[‘Passengers’].interpolate(method=’time’)
methods = ['Linear', 'Spline order 3', 'Time']
from matplotlib.pyplot import figure
import matplotlib.pyplot as plt
for method in methods:
figure(figsize=(12, 4), dpi=80, linewidth=10)
plt.plot(passenger["Date"], passenger[method])
plt.title('Air Passengers Imputation using: ' + types)
plt.xlabel("Years", fontsize=14)
plt.ylabel("Number of Passengers", fontsize=14)
plt.show()插值后结果:

当缺失值窗口(缺失数据的宽度)很小时,这些方法更有意义。但是如果丢失了几个连续的值,这些方法就更难估计它们。
3. 去噪
通常用于从时间序列中去除噪声的方法:
1)滚动平均值
滚动平均值是先前观察窗口的平均值,其中窗口是来自时间序列数据的一系列值。为每个有序窗口计算平均值。这可以极大地帮助最小化时间序列数据中的噪声。
在谷歌股票价格上应用滚动平均值:
python代码:.rolling(20).mean()
rolling_google = google_stock_price['Open'].rolling(20).mean()
plt.plot(google_stock_price['Date'], google_stock_price['Open'])
plt.plot(google_stock_price['Date'], rolling_google)
plt.xlabel('Date')
plt.ylabel('Stock Price')
plt.legend(['Open','Rolling Mean'])
plt.show()2)傅里叶变换
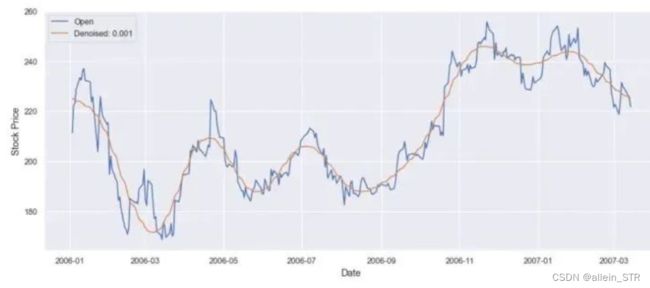
傅里叶变换可以通过将时间序列数据转换到频域来帮助去除噪声,我们可以过滤掉噪声频率。然后应用傅里叶反变换得到滤波后的时间序列。
我们用傅里叶变换来计算谷歌股票价格。
python代码:
denoised_google_stock_price = fft_denoiser(value, 0.001, True)
结果:
4. 异常点检测
1)基于滚动统计的方法
这种方法最直观,适用于几乎所有类型的时间序列。在这种方法中,上限和下限是根据特定的统计量度创建的,例如均值和标准差、Z 和 T 分数以及分布的百分位数。
例如,我们可以将上限和下限定义为:

取整个序列的均值和标准差是不可取的,因为在这种情况下,边界将是静态的。边界应该在滚动窗口的基础上创建,就像考虑一组连续的观察来创建边界,然后转移到另一个窗口。该方法是一种高效、简单的离群点检测方法。
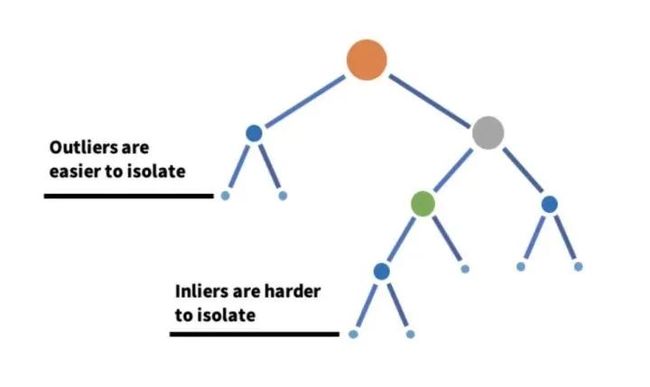
2)孤立森林
孤立森林是一种基于决策树的异常检测机器学习算法。
它通过使用决策树的分区隔离给定特征集上的数据点来工作。换句话说,它从数据集中取出一个样本,并在该样本上构建树,直到每个点都被隔离。为了隔离数据点,通过选择该特征的最大值和最小值之间的分割来随机进行分区,直到每个点都被隔离。特征的随机分区将为异常数据点在树中创建更短的路径,从而将它们与其余数据区分开来。
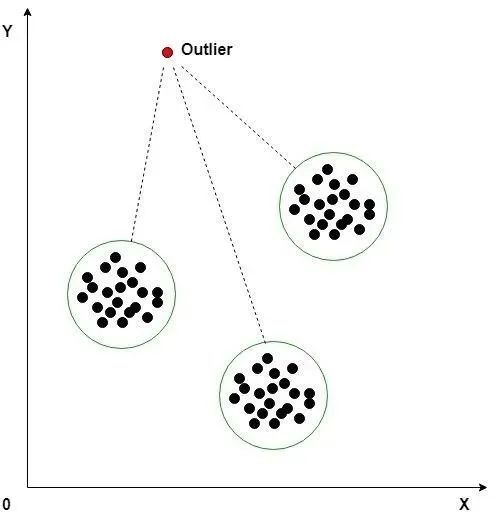
3)K-means 聚类
K-means 聚类是一种无监督机器学习算法,经常用于检测时间序列数据中的异常值。该算法查看数据集中的数据点,并将相似的数据点分组为 K 个聚类。通过测量数据点到其最近质心的距离来区分异常。如果距离大于某个阈值,则将该数据点标记为异常。K-Means 算法使用欧几里得距离进行比较。
作者:Shashank Gupta
来源:deephub