AlexNet:深度卷积神经网络的ImageNet分类
https://www.toutiao.com/a6640032761132368392/
2018-12-28 21:18:21
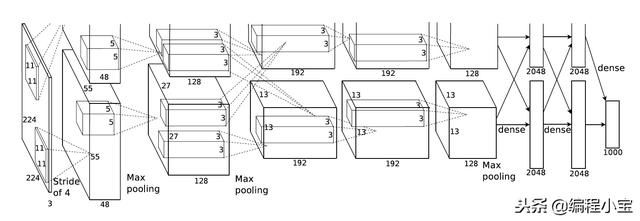
该模型赢得了ILSVRC 2012大赛
本文内容
- 在ImageNet数据上训练网络,其中包含超过22,000个类别的超过1500万张图像。
- 本文使用ReLU激活函数进行非线性。发现ReLU降低了训练的运行时间,因为它比传统的tanh函数更快。
- 实施dropout以减少过度拟合的影响。
- 采用图像平移、patch提取和图像反射等数据增强技术。
- 随机梯度下降(momentum和权重衰减)优化器。
- 模型训练。
机器学习数据集
Imagenet是一个超过1500万张图像的机器学习数据集,属于22,000个类别。从2010年开始,作为Pascal视觉对象挑战的一部分,举办了名为ImageNet大规模视觉识别挑战(ILSVRC)的年度竞赛。ILSVRC使用ImageNet的一个子集,在1000个类别中分别拥有大约1000个图像。总共有大约120万个训练图像,50,000个验证图像和150,000个测试图像。
由于计算原因,我们将在本文实现中使用CIFAR-10数据集。
ReLU非线性
在本文之前实现神经元输出的标准方法是使用tanh激活。

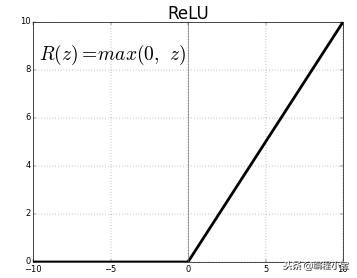
在梯度下降优化的反向传播步骤中,tanh激活函数的训练时间大于ReLU激活的训练时间。

实线 - ReLU 虚线 - tanh
ReLU in Numpy
import numpy as np
def ReLU(x):
return abs(x) * (x > 0)
x = np.array([1,-1, -0.5, 0.32])
ReLU(x)array([1. , 0. , 0. , 0.32])
ReLU in Pytorch
import torch
relu = torch.nn.ReLU()
x = torch.tensor(x) # x = numpy array of [1,-1, -0.5, 0.32]
relu(x)tensor([1.0000, 0.0000, 0.0000, 0.3200], dtype=torch.float64)
局部响应归一化
Relu具有这种理想的特性,它们不需要输入归一化来防止它们saturating。即使某些训练数据偏好正输入,也会通过ReLU进行学习。然而,局部响应归一化仍然有助于泛化。


Pytorch中的局部响应归一化
import torch.nn as nn
class LRN(nn.Module):
def __init__(self, size, alpha=1e-4, beta=0.75, k=1):
super(LRN, self).__init__()
self.avg = nn.AvgPool3d(kernel_size =(size,1,1), stride=1, padding=int((size-1)/2))
self.alpha = alpha
self.beta = beta
self.k = k
def forward(self, x):
deno = x.pow(2).unsqueeze(1)
deno = self.avg(deno).squeeze(1)
deno = deno.mul(self.alpha).add(self.k).pow(self.beta)
x = x.div(deno)
return x
x = torch.randn( 20,3, 10, 10)
lrn = nn.LocalResponseNorm(2)
lrn(x).size()
torch.Size([20, 3, 10, 10])
深度学习架构
class AlexNet(nn.Module):
def __init__(self, classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
import pylab as plt
x = torch.randn(1, 3, 224, 224).uniform_(0, 1)
im = plt.imshow(x.squeeze().permute(1, 2, 0).numpy())
plt.show()

x = torch.randn(1, 3, 224, 224).uniform_(0, 1)
alexnet = AlexNet()
alexnet(x).size()
torch.Size([1, 1000])
减少过度拟合
数据增强
避免过度拟合的最简单方法是增加机器学习数据大小,以便深度学习模型可以学习更多广义的数据特征。
但是获取更多数据始终不是一件容易的事,因此获取更多数据的方法之一是从给定数据中人为地生成更多数据。


有许多类型的数据增强技术可用
- 翻转(水平和垂直)
- 旋转
- 缩放
- Crop
- 平移
- 高斯噪声
from skimage import io
import matplotlib.pyplot as plt
image = io.imread('https://cdn3.bigcommerce.com/s-nadnq/product_images/uploaded_images/20.jpg')
plt.imshow(image)
plt.grid(False)
plt.axis('off')
plt.show()

import random
from scipy import ndarray
import skimage as sk
from skimage import transform
from skimage import util
def random_rotation(image_array: ndarray):
random_degree = random.uniform(-25, 25)
return sk.transform.rotate(image_array, random_degree)
def random_noise(image_array: ndarray):
return sk.util.random_noise(image_array)
def horizontal_flip(image_array: ndarray):
return image_array[:, ::-1]
def vertical_flip(image_array: ndarray):
return image_array[::-1, :]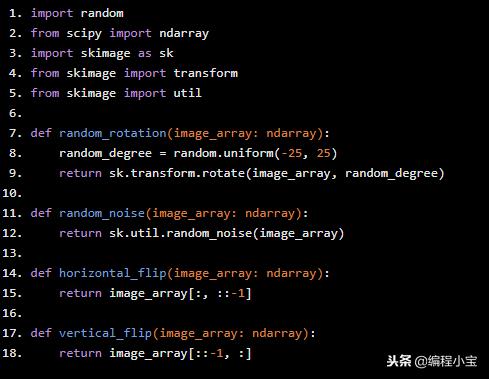
Dropout
该技术减少了神经元的复杂共同适应,因为神经元不能依赖于特定其他神经元的存在。因此,它被迫学习更有力的特征,这些特征与其他神经元的许多不同随机子集一起使用是有用的。在测试时,我们使用所有神经元但是将它们的输出乘以0.5,这是采用由exponentially-many dropout网络产生的预测分布的几何平均值的合理近似值。
Dropout in Numpy
def dropout(X, drop_probability):
keep_probability = 1 - drop_probability
mask = np.random.uniform(0, 1.0, X.shape) < keep_probability
if keep_probability > 0.0:
scale = (1/keep_probability)
else:
scale = 0.0
return mask * X * scale
x = np.random.randn(3,3)
dropout(x, 0.3)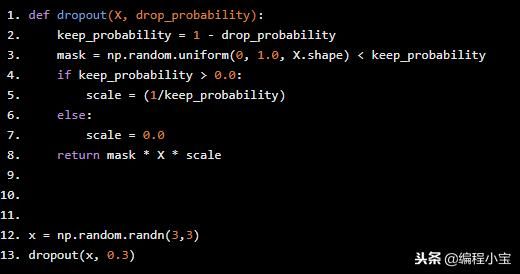
array([[ 0. , 2.12769017, -1.95883643],
[ 0.05583112, -0.51280684, 0. ],
[-1.64030713, 3.15857694, 1.13236446]])
Dropout in Pytorch
import torch
x = np.random.randn(3,3)
x_tensor = torch.from_numpy(x)
dropout = torch.nn.Dropout(0.5)
dropout(x_tensor)

tensor([[ 0.9667, 0.0000, 2.1510],
[ 1.4301, 0.0000, 1.4544],
[-0.0000, 1.3651, -0.0000]], dtype=torch.float64)
学习
使用具有0.9的momentim和0.0005的权重衰减的梯度下降优化器。批量大小128。
权重/偏差初始化器
每层的权重由一个标准差为0.01的零均值高斯分布初始化。偏差初始化为1。
lr调度程序
当损失停止增加时,手工调整学习率和lr降低。
Numpy的权重/偏差初始化器
weights = np.random.normal(loc=0.0, scale=0.01, size=(3,3))array([[-0.00723783, -0.00436599, 0.00199946], [-0.00618118, -0.00122866, 0.00844244], [ 0.01453114, 0.00025038, -0.00534145]])
X = np.random.rand(3,3)
print('Input X =
',X)
w = np.random.normal(loc=0.0, scale=0.01, size=(3,1))
print('
Initialized weight w =
',w)
bias = np.ones((3,1))
print('
Initialized bias b =
',bias)
z = np.dot(X, w) + bias z
print(z)
Input X =
[[0.9769654 0.91344693 0.26452228]
[0.24474425 0.75985733 0.0462379 ]
[0.80824044 0.9641414 0.89342702]]
Initialized bias b = [[1.] [1.] [1.]]
array([[0.98718374], [0.99301363], [0.99457285]])