pandas 数据处理-数据结构(Series,DataFrame)
pandas 数据处理-数据结构(Series,DataFrame)
- 1 数据结构
-
- 1.1 Series
-
- 1.1.1 Series与 ndarray 相似地方
- 1.1.2 Series与 dict 相似地方
- 1.1.3 矢量化操作
- 1.1.4 Name 属性
- 1.2 DataFrame
-
- 1.2.1 根据不同类型数据创建DataFrame
- 1.2.2 列选择、列增加、列删除
- 1.2.3 assign方法增加列
- 1.2.4 索引与选择
- 1.2.5 数据对齐
- 1.2.6 转置
- 1.2.7 DataFrame 与 NumPy 函数互操作
- 1.2.8 DataFrame 显示
- 参考
1 数据结构
数据对齐是数据的内在结构,即数据标签和数据本身是原生关联的,除非显式解除这一限制。pandas 中有两种类型的数据 Series 和 DataFrame
对DataFrame 的操作:
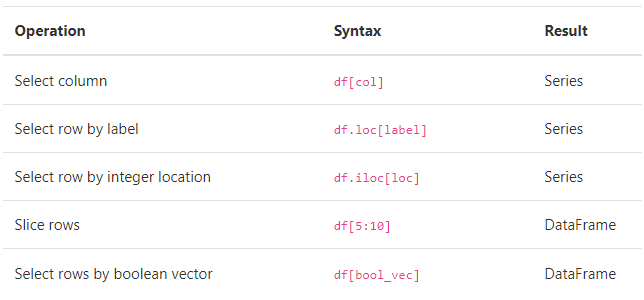
另外 DataFrame 可以使用 assign 函数直接进行操作 iris.assign(sepal_ratio=iris["SepalWidth"] / iris["SepalLength"])
1.1 Series
Series 是一维的标签数组,轴标签统称为索引
创建Series:
"""
data可以为字典、ndarray、标量
index 为轴标签
"""
s = pd.Series(data, index=index)
(1) 当 data 为 ndarray 时,index 长度需与data 长度相同,当无 index 参数时,会默认创建 [0, …, len(data) - 1] 的轴标签
s = pd.Series(np.random.randn(5), index=["a", "b", "c", "d", "e"])
s
Out[4]:
a 0.469112
b -0.282863
c -1.509059
d -1.135632
e 1.212112
dtype: float64
(2) 当 data 为 dicts 时
d = {"b": 1, "a": 0, "c": 2}
pd.Series(d)
Out[8]:
b 1
a 0
c 2
d = {"a": 0.0, "b": 1.0, "c": 2.0}
# NaN (not a number)
pd.Series(d, index=["b", "c", "d", "a"])
Out[11]:
b 1.0
c 2.0
d NaN
a 0.0
dtype: float64
(3) 当 data 为标量时
当data 为标量时,必须设置 index 参数,标量值会复制到 index 的长度
pd.Series(5.0, index=["a", "b", "c", "d", "e"])
Out[12]:
a 5.0
b 5.0
c 5.0
d 5.0
e 5.0
dtype: float64
1.1.1 Series与 ndarray 相似地方
可以进行 slicing 操作
s = pd.Series(np.random.randn(5), index=["a", "b", "c", "d", "e"])
Out[12]:
a 1.822980
b -1.426471
c 0.687526
dtype: float64
dtype属性
s.dtype
Out[18]: dtype('float64')
s.to_numpy() 转为 ndarray
s.to_numpy()
Out[20]: array([ 0.4691, -0.2829, -1.5091, -1.1356, 1.2121])
1.1.2 Series与 dict 相似地方
可以通过标签轴获取和设置值
s["a"]
Out[21]: 0.4691122999071863
s["e"] = 12.0
"e" in s
Out[24]: True
s.get("f", np.nan)
1.1.3 矢量化操作
Series 可以传入大多数的 NumPy 方法中
s + s
np.exp(s)
有一点不同之处在于,Series 会基于标签进行关联计算,如
s1 = pd.Series(np.random.randn(5), index=["a", "b", "c", "d", "e"])
s2 = pd.Series(np.random.randn(5), index=["a", "b", "c", "d", "e"])
s3 = pd.Series(np.random.randn(5), index=["f", "g", "h", "i", "j"])
s1[1:] + s2[:-1]
Out[31]:
a NaN
b -0.565727
c -3.018117
d -2.271265
e NaN
dtype: float64
s1[1:] + s3[:-1]
b NaN
c NaN
d NaN
e NaN
f NaN
g NaN
h NaN
i NaN
dtype: float64
1.1.4 Name 属性
s = pd.Series(np.random.randn(5), name="something")
Out[33]:
0 -0.494929
1 1.071804
2 0.721555
3 -0.706771
4 -1.039575
Name: something, dtype: float64
# s and s2 是两个不同的对象
s2 = s.rename("different")
1.2 DataFrame
DataFrame 是一种二维标签数据,不同列可能有不同类型数据的值
DataFrame 可接受不同类型的数据作为输入:
- lists, dicts, or Series
- 2-D numpy.ndarray
- Structured or record ndarray
- A Series
- Another DataFrame
1.2.1 根据不同类型数据创建DataFrame
(1) Series字典 或 字典的字典
d = {
"one": pd.Series([1.0, 2.0, 3.0], index=["a", "b", "c"]),
"two": pd.Series([1.0, 2.0, 3.0, 4.0], index=["a", "b", "c", "d"]),
}
df = pd.DataFrame(d)
Out[39]:
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
获取属性值
df.index
Out[42]: Index(['a', 'b', 'c', 'd'], dtype='object')
df.columns
Out[43]: Index(['one', 'two'], dtype='object')
(2) 数组字典
d = {"one": [1.0, 2.0, 3.0, 4.0], "two": [4.0, 3.0, 2.0, 1.0]}
pd.DataFrame(d)
Out[45]:
one two
0 1.0 4.0
1 2.0 3.0
2 3.0 2.0
3 4.0 1.0
(3) 结构数组
data = np.zeros((2,), dtype=[("A", "i4"), ("B", "f4"), ("C", "a10")])
data[:] = [(1, 2.0, "Hello"), (2, 3.0, "World")]
pd.DataFrame(data)
Out[49]:
A B C
0 1 2.0 b'Hello'
1 2 3.0 b'World'
(4) 字典列表
data2 = [{"a": 1, "b": 2}, {"a": 5, "b": 10, "c": 20}]
pd.DataFrame(data2)
Out[53]:
a b c
0 1 2 NaN
1 5 10 20.0
(5) namedtuples
from collections import namedtuple
Point3D = namedtuple("Point3D", "x y z")
pd.DataFrame([Point3D(0, 0, 0), Point3D(0, 3, 5), Point(2, 3)])
Out[61]:
x y z
0 0 0 0.0
1 0 3 5.0
2 2 3 NaN
1.2.2 列选择、列增加、列删除
可以将 DataFrame 当作值是 Series 的字典
d = {
"one": pd.Series([1.0, 2.0, 3.0], index=["a", "b", "c"]),
"two": pd.Series([1.0, 2.0, 3.0, 4.0], index=["a", "b", "c", "d"]),
}
df = pd.DataFrame(d)
# 列选择
df["one"]
# 增加列
df["three"] = df["one"] * df["two"]
# 删除列
del df["two"]
three = df.pop("three")
当列赋值为标量时,它会自动扩展长度
df["foo"] = "bar"
选择特定位置插入
df.insert(1, "bar", df["one"])
Out[81]:
one bar flag foo one_trunc
a 1.0 1.0 False bar 1.0
b 2.0 2.0 False bar 2.0
c 3.0 3.0 True bar NaN
d NaN NaN False bar NaN
1.2.3 assign方法增加列
assign 返回的是原数据的副本,原DataFrame没有改变
iris = pd.read_csv("data/iris.data")
Out[83]:
SepalLength SepalWidth PetalLength PetalWidth Name
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2
iris.assign(sepal_ratio=iris["SepalWidth"] / iris["SepalLength"]).head()
Out[84]:
SepalLength SepalWidth PetalLength PetalWidth Name sepal_ratio
0 5.1 3.5 1.4 0.2 Iris-setosa 0.686275
1 4.9 3.0 1.4 0.2 Iris-setosa 0.612245
2 4.7 3.2 1.3 0.2 Iris-setosa 0.680851
3 4.6 3.1 1.5 0.2 Iris-setosa 0.673913
4 5.0 3.6 1.4 0.2 Iris-setosa 0.720000
# 可以使用 lambda 函数
iris.assign(sepal_ratio=lambda x: (x["SepalWidth"] / x["SepalLength"])).head()
dfa = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6]})
dfa.assign(C=lambda x: x["A"] + x["B"], D=lambda x: x["A"] + x["C"])
Out[88]:
A B C D
0 1 4 5 6
1 2 5 7 9
2 3 6 9 12
1.2.4 索引与选择
当选择某行时候,返回 Series 类型数据,索引名为列名
dfa = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6]})
dfa.loc[2]
Out[88]:
A 3
B 6
Name: 2, dtype: int64
1.2.5 数据对齐
DataFrame 的列和行索引都是自动对齐的
df1 = pd.DataFrame({"a": [1, 0, 1], "b": [0, 1, 1]}, dtype=bool)
df2 = pd.DataFrame({"a": [0, 1, 1], "b": [1, 1, 0]}, dtype=bool)
df1 & df2
Out[100]:
a b
0 False False
1 False True
2 True False
1.2.6 转置
dfa.T
Out[100]:
0 1 2
A 1 2 3
B 4 5 6
1.2.7 DataFrame 与 NumPy 函数互操作
逐值操作的 NumPy 函数 (log, exp, sqrt, …)同样适用于 DataFrame
# 转为二维 ndarray
np.asarray(df)
1.2.8 DataFrame 显示
print(baseball.iloc[-20:, :12].to_string())
# 设置行宽
pd.set_option("display.width", 40) # default is 80
pd.set_option("display.max_colwidth", 100)
参考
Intro to data structures