一文读懂分布式系统通信基本框架!
1.RPC透明调用
RPC模型
RPC 比较有影响的论文就是1984年发表的 Implementing Remote Procedure Calls. 有五个核心概念。
1.user(客户端)------>UserStub----->RPCRuntimes ---->RPCRuntimes--->ServerStub--->Server
2.user(客户端)<------UserStub<-----RPCRuntimes <----RPCRuntimes<---ServerStub<---Server
一个完整的RPC调用,核心是通信,序列化和透明化调用.
Java远程方法调用
RMI
远程方法调用(Remote Method Invocation,RMI),它与论文的流程相似,增加了RMI Registry的概念,进而实现了 客户端和服务端通过Registry来注册服务和寻找服务的调用方式,让客户端和服务端的调用变的透明。
缺点:性能低(JRMP协议采用阻塞模型,原生的序列化方方案),缺少服务治理,不支持异构语言。
异构语言框架gRPC
gRPC是google 开源的一款对语言和平台中立的高性能 RPC框架,,基于http2,支持单连接多路复用,在移动设备上可以节省流量和耗电量。
gRPC服务端的启动代码和 Netty相似,其实其java版本就是使用了Netty作为底层通信框架。
Dubbo
ubbo(读音[ˈdʌbəʊ])是阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 [1] Spring框架无缝集成。
Dubbo是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现
![]()
-
Provider
暴露服务方称之为“服务提供者”。 -
Consumer
调用远程服务方称之为“服务消费者”。 -
Registry
服务注册与发现的中心目录服务称之为“服务注册中心”。 -
Monitor
统计服务的调用次数和调用时间的日志服务称之为“服务监控中
小结:RMI已经不再适用,Dubbo性能极高,支持多种通信和序列化协议,还支持服务治理。但是有些重。另外Restful API性能较弱,java开发实际中可以采用Netty+Kryo的通信和序列化组合自行实现通信框架也是不错的。
2、IO通信
1.正确理解IO定义
IO涉及两个系统对象,一个是用户进程,一个是系统内核
阻塞IO和非阻塞IO 针对是对用户进程来讲的调用函数。
同步IO和异步IO针对的是系统内核。
select,poll,epoll是Linux系统使用最多的IO多路复用机制,采用的都是同步IO。
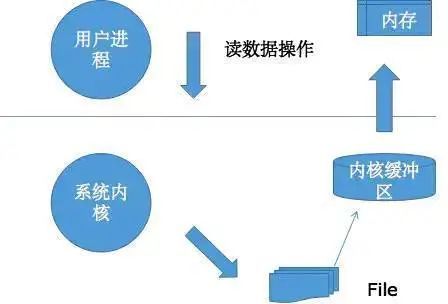
IO读取过程
2.Java IO
BIO/NIO/AIO
-
BIO
BIO 使用简单,适用于连接数少并发不高的场景(因为服务端线程数量和客户端访问数成正比,很容易膨胀,耗尽资源,可以通过线程池做一定的优化,但本质上还是受资源限制明显)。 -
NIO JDK1.4 引入,从最初的select/poll,到1.5增加了对epoll的支持。
NIO 里面几个核心概念
Buffer(数据操作的对象),Channel(可同时读写操作,代替BIO每次访问建立的线程,降低资源消耗),Selector(channel的注册,监听,轮询;一个selector可以管理成百上千个 channel,而Selector只是一个线程)。
![]()
image
NIO Reactor模式
数据读取流程
1.Selector阻塞并等待事件发生。
2.Selector被唤醒,发送读就绪事件给预先注册的事件处理器
3.应用程序读取数据
4.应用程序处理相关业务逻辑
Selecor是NIO的关键,NIO采用的是非阻塞IO模型。原生Java接口开发网络应用中使用最多的。
NIO的实现框架 Netty,Mina.Netty在内存管理和综合性能上更胜一筹。Netty内部通过封装 Java NIO实现了零拷贝的功能(不用将数据复制到用户进程,直接发送到网络)。
-
AIO 采用Proactor模式
与NIO模式类似,只是AIO 是由操作系统执行完读写后,通知回调方法,由回调方法处理业务逻辑。其采用的是异步 IO。
有两种使用方式
1.使用java.util.concurrent.future访问,通过get获取结果,本质上还是同步,不推荐
2.回调方式,通过java.nio.channels.CompletionHandler的completed和failed回调方法,应用开发者可以覆盖实现自己的业务逻辑
3.序列化
对象序列化
在程序运行时,在内存中的对象,希望能够持久化保存对象,则需要讲内存的对象转换为一定的格式,这个过程就是序列化的过程。反过来,程序重新运行,读取数据转换为对象的过程就是反序列化。这个在当我们讲数据存入数据库,再从数据库读取,其实是数据库帮我们做了序列化和反序列化这个过程。另外一个就是网络通信,也需要接收方和发送方分别支持特定格式的序列化和反序列化。
序列化/反序列化其实是要数据有一定的格式,这个格式就是序列化协议,主要关注数据存储和传输。序列化方案很多,主要有三个性能度量指标
-
对象序列化后的字节占位大小
-
序列化和反序列化的性能
-
序列化工具自身的性能
常见的序列化分为下面几类
1.文本序列化
2.二进制序列化
1.文本序列化
文本序列化有两种格式JSON和XML,XML已经很少使用,目前主要就是JSON,他是一种轻量级的数据交换格式,采用文本格式存储和表示数据。
java语言框架:
1.Jackson jackson-core+jackson-databind(流式处理)
2.Gson 谷歌开源的三方库
3.FastJson--用的最广,之前的漏洞问题暴露进行了统一的升级处理
4.Json-lib
2.二进制序列化
二进制java序列化
1.java 原生序列化 实现Serializable接口 ,RMI,EJB采用就是次方案,导致吞吐量受限。
2.高性能框架kryo (主要方法WriteObject,WriteClassAndObject,register)
二进制异构语言序列化
-
PB Protocol Buffers 高性能异构语言序列化框架 ProtoBuf
可以安装命令行 通过编译 proto文件,生成对应的类文件。在开发环境中,可以通过mvn 插件protobuf-java,mvn 命令来进行编译生成 -
msgpack
采用packb对数据进行打包,使用unpackd进行解包。除了使用packed方法,msgpack很人性化的提供了另一种打包和解包的方法,这个方法和json打包/解包的方法一样,那就是dumps和loads方法了
数据压缩结论比较:如果说把json数据的大小比作西瓜大小,那么protobuf就是苹果大小,msgpack呢,则是红豆大小,所以msgpack使用优势还是很明显的
扫描二维码获取更多精彩
