【机器学习】线性回归实战案例三:股票数据价格区间预测模型(国外+国内数据)
股票数据价格区间预测模型(国外+国内数据)
-
- 案例三:股票数据价格区间预测模型(国外+国内数据)
-
- 2.3.1 模块加载与忽略警告设置
- 2.3.2 加载数据和数据筛选
- 2.3.3 探索式数据分析(EDA)
- 2.3.4 探究字段之间的关联性
- 2.3.5 特征工程
- 2.3.6 模型创建与应用
- 2.3.7 模型对比
- 2.3.8 预测结果可视化
- 2.3.9 国内茅台股票数据集应用
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/121452962(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
案例三:股票数据价格区间预测模型(国外+国内数据)
2.3.1 模块加载与忽略警告设置
打开Jupyter notebook,然后新建一个python3文件,命名为股票时序数据回归预测模型1.ipynb。文件首个cell中导入数据分析常用模块和模型相关的模块,设置提示警告的过滤,代码如下。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import math
import seaborn as sns
import datetime
import matplotlib.pyplot as plt
from matplotlib import style
import time
import warnings
warnings.filterwarnings('ignore')
2.3.2 加载数据和数据筛选
准备的数据集为谷歌2004年的股票数据,读取过程中将Date字段进行时间字段转化,并设置为索引,然后查看数据的维度。
df=pd.read_csv('./data/google-stockdata.csv',index_col='Date',
parse_dates=True)
df
输出结果如下。(直接输出读取后文件数据对应的变量,最后面一行会有提示数据的维度,一共有3424行,12列,相当于最后输出了df.shape)

了解一下股票数据的基本信息,一般就是包含了前六个字段(包含索引),即股票的开盘时间、开盘价、最高点、最低点、收盘价和成交量。最后面的五个字段是经过复权后的衍生字段,而中间的两个字段是在案例中没有使用到。
2.3.3 探索式数据分析(EDA)
之前的两个案例中均展示了探索式数据分析的几个步骤,这里就不再进行赘述。但是对于字段中的缺失值的查看一定是要做的,如果存在着缺失值就要进行缺失值处理,确保传入模型的数据是一个完整的数据,输出结果如下。

在提供的数据中并没有缺失的数据,但是经过仔细研究发现股票数据中并没有一个标签字段,因此要进行线性回归模型创建前需要先解决标签数据的问题。本案例的目标:预测未来股票的价格区间,需要根据历史的股票价钱(收盘价)来预测未来股票价钱的情况。
考虑数据量进行时间范围的确定。数据量一共3424行,假定按照数据量除以100取上限进行预测天数的确定,然后就可以构造对应标签数值。为了便于理解这个构建标签数值的过程,可以进行一个简单的示例,先以5天为基准构建数据。为了不破坏数据和方便查看,对原数据进行备份后取出10条数据进行演示。

接着就是利用pandas应用基础中第10小结的内容,shift时间平移操作。首先提取经过复权后的收盘价字段并转化为DataFrame数据类型,进一步应用shift(-5)变换并赋值给新字段,最后就是新字段与原字段相减获得相差5天的数据。
df3=df2['Adj. Close'].to_frame()
df3['col2']= df3['Adj. Close'].shift(-5)
df3['delta']=df3['col2']-df3['Adj. Close']
df3.head(7)
输出结果如下。(采用 shift 加上负值的方法 可以把同一组数据错位的放在一起,这个错位是把5天后的数据与当前天的数据放在同一行中,然后两个字段数值相减就可以获得对应天数股票价格的差值)

利用上面的原理,应用到整个股票数据集中,
forecast_col = 'Adj. Close'
forecast_out = int(math.ceil(0.01 * len(df)))
df['label'] = df[forecast_col].shift(-forecast_out)
df[-40:-30]
输出结果如下。(为了核实是否处理正确,切片获取倒数第40到第30行的数据,输出结果中label字段数据有一半缺失一般完整,说明操作过程正确)

也可以直接查看各字段的缺失值进行核实,输出结果如下,最终就是创建的字段label中存在着35条缺失值,满足要求。

2.3.4 探究字段之间的关联性
完成了标签字段数据的构建,接下来就可以查看特征字段与标签字段的关联性,直接利用热力图进行展示输出。

确定标签字段后,在热力图中只需要查看标签字段label对应的行或者列即可,比如上图红框标注的列。根据图中的结果,首先看两个不相关的字段,也就是中间的那两个字段在整个案例中没有进行介绍也和标签字段无关,后续直接进行剔除;然后就是股票除时间外的剩下的5个信息与调整后的5个信息,由于标签字段就是利用调整后的收盘价字段构造的,所以会和调整后的收盘价相相关性为0.99,然而调整后的4个信息之间的相关性都为1,自然标签字段和剩下的3个信息直接的相关性也是0.99,至于未调整前的数据,是经过一定的计算转化而来,相关性数值相对较小一些,但是也是存在很强的相关性。
2.3.5 特征工程
根据关联性分析的结果重新提取字段数据,构建数据集,创建两个新字段为高低价变化差和涨跌幅,并进行缺失值的处理。
df = df[['Adj. Open', 'Adj. High', 'Adj. Low', 'Adj. Close', 'Adj. Volume','label']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low']) / df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj. Open']) / df['Adj. Open'] * 100.0
df.dropna(inplace=True)
df.isnull().sum()
输出结果如下。(在进行创建模型之前,数据中的缺失值需要清洗干净,此外添加的两个字段也在数据集中)

2.3.6 模型创建与应用
(1)划分特征数据X和标签数据Y

(2)划分训练集和测试集。这里的数据集需要特别注意,在删除最后的缺失值后,中最后35条数据label值其实就是已经要预测的数据值,因此在数据集也需要进行删除。比如最后一行数据是2018年2月5号,对应的label就是2018年3月27号的数据(去掉了周末),最后的35天就作为真实值要进行预测35天后的价格进行差值对比,所以需要再将最后35行数据删除。

X_lately = X[-forecast_out:] # 把最后35行单独拿出来,作为最后的预测
X = X[:-forecast_out] # x中存放除最后35行以外的其他信息
y = y[:-forecast_out] # y中存放除最后35行以外的其他信息
然后才是进行训练集和测试集的划分,按照9:1的比例进行。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1)
(3)模型创建与拟合。
clf=LinearRegression()
clf.fit(X_train,y_train)
(4)模型预测与评估。
forecast_set = clf.predict(X_lately)
forecast_set
输出结果如下。(最终的股票价钱是在1082-1262之间)
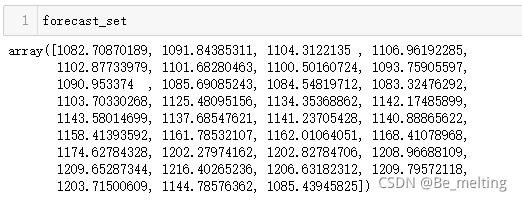
然后查看一下当前模型预测股票区间的正确率得分有多少,代码及输出结果如下。(未来35天的股票价格区间预测,有97.4%的正确率使得最终的股票价格落在1082-1262之间)

2.3.7 模型对比
在进行数据集构建时,细心点可以发现特征字段的量纲不一致,比如价钱字段和成交量字段数值。接下来就是确定特征数据标准化会不会对模型有一定的优化,需要添加一个标量处理器,之后的模型步骤保持一致,建模部分全部代码和最终测试得分如下。
#划分特征数据和标签数据
X = np.array(df.drop(['label'], 1))
y = np.array(df['label'])
#特征数据标量化
from sklearn import preprocessing
X = preprocessing.scale(X)
#进行最后35行数据剔除
X_lately = X[-forecast_out:]
X = X[:-forecast_out]
y = y[:-forecast_out]
#划分训练数据与测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1)
#创建线性回归模型
clf=LinearRegression()
#模型拟合
clf.fit(X_train,y_train)
#模型预测结果及输出股票价格区间
forecast_set = clf.predict(X_lately)
min(forecast_set),max(forecast_set)
#模型得分
confidence = clf.score(X_test, y_test)
confidence
最终输出的模型预测的股票价格区间(1080-1217之间)与模型得分结果(正确率为97.7%)如下。由于没有指定随机种子,每次程序跑出的结果基本上都不会完全一致。

2.3.8 预测结果可视化
由于标签的结果带有时序性且是数值型,就可以对预测的结果进行可视化展示。由于删除了倒数35行的数据,因此要得到绘制35天后的数据,就需要先获得最后35行对应的时间,代码如下。
df['Forecast'] = np.nan
last_date = df.iloc[-1].name
last_unix = last_date.timestamp()
last_unix = time.mktime(last_date.timetuple())
one_day = 864006
next_unix = last_unix + one_day
输出结果如下。(之前进行数据集处理的时候将最后35条数据删除,现在输出结果汇总把添加了Forecast字段)
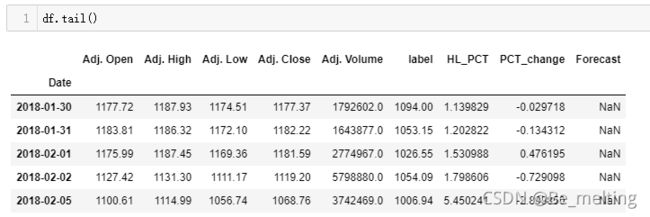
然后将预测的结果进行填充到对应的时间中去,就可以获得预测结果,代码如下。
for i in forecast_set:
next_date = datetime.datetime.fromtimestamp(next_unix)
next_unix += 86400
df.loc[next_date] = [np.nan for _ in range(len(df.columns)-1)]+[i]
输出结果如下。(需要留意,模型数据中最后日期是2018年2月5号,预测的结果对应label值,这个数据就是35天后的股票价格,映射到对应的时间段就如下)

有了数据后,进行可视化,代码及输出结果如下。

绘制预测数据的图像代码与结果输出如下。

添加两图合并后,代码及可视化图形输出如下。

2.3.9 国内茅台股票数据集应用
在使用国外谷歌的数据进行线性回归回归模型的预测中,模型得分正确率达到了97%,而对于国内股票的预测效果如何,接下来进行探究。创建一个新的python3文件,命名为股票时序数据回归预测模型2.ipynb,数据集为茅台酒的股票数据(对应的编号为600519)。首先导入模块和加载数据,代码如下。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import math
import seaborn as sns
import matplotlib.pyplot as plt
df2 = pd.read_csv('./data/600519d4.csv',index_col='trade_date',
parse_dates=True)
输出结果如下:(股票数据的时间跨度为2020年1月2日到2021年10月21日,可以通过tushare接口下载)

按照习惯,时间索引一般是按照从前到后(即从以前到现在)的方式设置,也方便绘制图形,进行反序操作后绘制折线图查看茅台股票走势图,代码及输出结果如下。

剩下的步骤就是按照前面国外数据的处理方式一致,首先进行预测时间长短的设置,需要根据数据量来确定,这里的时间设定为22天。

进一步构建数据集和缺失值处理,并进行特征数据以及标签数据的划分,并剔除最后22天的数据,代码如下。
##构建数据集
df2 = df2[['open', 'high', 'low', 'close','vol','label']]
df2.head()
#缺失值处理
df2.dropna(inplace=True)
#核实缺失值处理完毕
df2.isnull().sum()
#划分特征数据和标签数据
X = np.array(df2.drop(['label'], 1))
y = np.array(df2['label'])
#剔除最后的22条数据
X_lately = X[-forecast_out:] # 把最后22行单独拿出来
X = X[:-forecast_out] # x中存放除最后22行以外的其他信息
y = y[:-forecast_out]
最后就是进行模型的创建,训练,预测和评估,代码及输出结果如下。

模型最后的准确率只有0.796,远远低于使用国外数据进行建模时候的得分,更进一步采用以往进行模型评估的方法查看一下平均绝对误差和R方值(就是模型的score得分),输出结果如下。

利用预测结果的平均值结合平均绝对误差,可以推测该模型预测单次预测股票数据的涨跌幅范围,即正负7.13%,而股票一天的最大涨跌幅就是正负10%,这个预测结果太过粗糙了,基本上没有意义。根本原因在于国内的股票数据的波动幅度太大,就会导致预测数值与真实数值之间的误差就会扩大,模型最终的得分也就下降,对于未来数据的预测效果就很差,因此在对此类数据进行建模之前需要对数据进行平滑处理。
对于金融类数据,可以尝试ta模块,各种指标已经封装在pandas中了,只需要进行pip install pandas_ta即可进行安装。

查看具体有哪些指标可以按照如下代码进行输出,当前一共有205个指标。
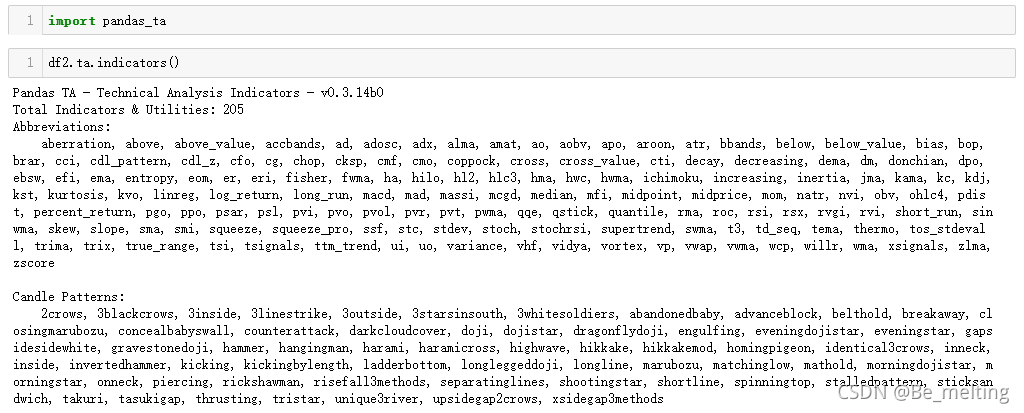
假定选取里面的EMA指标进行数据平滑处理,以收盘价字段和10天为依据,将处理后的内容添加到新的字段中。
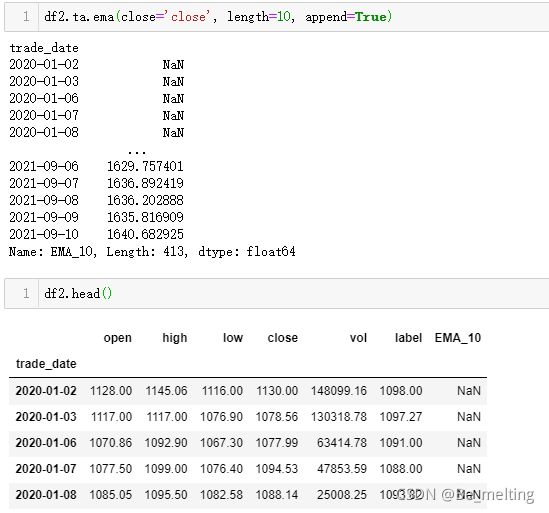
也是和手动设定天数的步骤一样,需要进行缺失值的查看,除去和核实,代码如下。

也可以借助图形查看经过平滑处理过后的股票数据折线图和原数据折线图之间的对比,代码及输出结果如下。

数据处理完毕后,进一步构建数据集和缺失值处理,并进行特征数据以及标签数据的划分,代码如下。(对于采用EMA指标处理数据后,这里的标签数据和特征数据就不需要再次进行最后10条数据的剔除,因为使用的并不是原来真实的数据,而是一个计算的数据,并非直接线性相关)
#设定标签数据
df2['label'] = df2['EMA_10']
df2 = df2[['open', 'high', 'low', 'close','vol','label']]
#核实没有缺失值
df2.isnull().sum()
#构建特征数据与标签数据
X = np.array(df2.drop(['label'], 1))
y = np.array(df2['label'])
#训练数据与测试数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
#创建模型
clf=LinearRegression()
#训练模型
clf.fit(X_train,y_train)
#模型预测
y_pred = clf.predict(X_test)
min(y_pred),max(y_pred)
#模型得分
confidence = clf.score(X_test, y_test)
confidence
最终的输出股票价格区间和对应的模型得分,以及预测股票价格的涨跌幅结果如下。数据经过平滑处理过后,模型预测的准确度要大大提升,最后的涨跌幅度的范围拿捏着也很准确。
