蔬菜图片的类型识别系统【基于MobileNetV3模型】
蔬菜图片的类型识别系统【基于MobileNetV3模型】
文章目录
-
- MobileNet V3 的创新
-
- 1. SE模块的加入
- 2. 修改尾部结构
- 3. 修改通道数量
- 4. 改变激活函数
- 使用示例:
-
- 1. 安装PaddleX
- 2. 准备蔬菜分类数据集
- 3. 定义训练/数据增强
- 4. 定义dataset加载图像分类数据集
- 5. 使用MobileNetV3_small模型开始训练
- 6. 代码示例
- 7. 加载训练保存的模型预测
识别系统简介
本作业设计实现了一个蔬菜图片的类型识别系统,使用百度官方蔬菜数据集vegetables_cls(共960张训练数据+240张验证数据,包含菠菜、胡萝卜、西红柿等6种蔬菜图片数据)。
作业基于国产百度Paddle框架,使用MobileNetV3模型,进行开发实现,过程中对图片数据进行RandomCrop数据增强。
模型介绍
MobileNet V3 是对 MobileNet V2 的改进,同样是一个轻量级卷积神经网络。为了适用于对资源不同要求的情况,MobileNet V3 提供了两个版本,分别为 MobileNet V3 Large 以及 MobileNet V3 Small。
MobileNet V3 的创新
1. SE模块的加入
仿照 MnasNet,MobileNet V3 在 MobileNet V2 中的 BottleNeck 模块中的深度级卷积操作后面添加了 SE 模块。如下图所示:

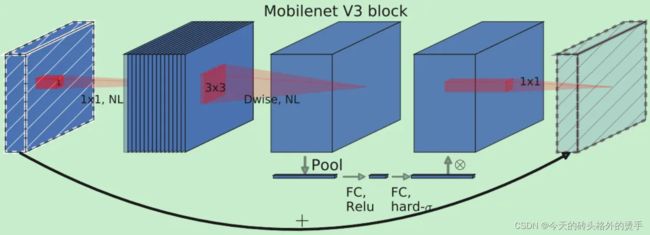
2. 修改尾部结构
MobileNet V2 中,在 GlobalAveragePooling 操作之前,为了提高特征图的维度我们使用了一个 1x1 的卷积层,但是这必定会带来了一定的计算量,所以在 MobileNet V3 中作者将其放在 GlobalAveragePooling 的后面,首先利用 GlobalAveragePooling 将特征图大小由 7x7 降到了 1x1,然后再利用 1x1 提高维度,这样就减少了很多计算量。另外,为了进一步地降低计算量,作者直接去掉了前面纺锤型卷积的 3x3 以及 1x1 卷积,进一步减少了计算量,就变成了如下图第二行所示的结构。
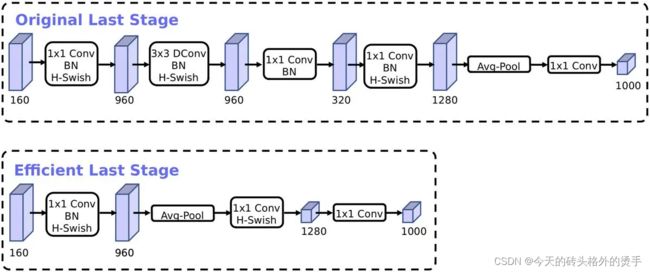
3. 修改通道数量
修改网络开始时第一个卷积核的数量,MobileNet V2 中使用了 32 个卷积核,在 MobileNet V3 中,作者仅使用了 16 个卷积核就达到了相同的精度。
4. 改变激活函数
SE 模块中
MobileNet V3 中将原来 SE 模块中的 sigmoid 激活函数换成了 h-sigmoid 激活函数,其表达式如下:

BottleNeck 模块中
MobileNet V3 中将原来 BottleNeck 模块中的 ReLU6 激活函数换成了 h-swish 激活函数,其表达式如下:

使用示例:
使用pip安装方式安装2.1.0版本:
1. 安装PaddleX
pip install paddlex==2.1.0 -i https://mirror.baidu.com/pypi/simple
pip install paddlepaddle==2.3.2 -i https://mirror.baidu.com/pypi/simple
2. 准备蔬菜分类数据集
wget https://bj.bcebos.com/paddlex/datasets/vegetables_cls.tar.gz
tar xzvf vegetables_cls.tar.gz
3. 定义训练/数据增强
因为训练时加入了数据增强操作,因此在训练和验证过程中,模型的数据处理流程需要分别进行定义。如下所示,代码在train_transforms中加入了RandomCrop和RandomHorizontalFlip两种数据增强方式。
from paddlex import transforms as T
train_transforms = T.Compose([
T.RandomCrop(crop_size=224),
T.RandomHorizontalFlip(),
T.Normalize()])
eval_transforms = T.Compose([
T.ResizeByShort(short_size=256),
T.CenterCrop(crop_size=224),
T.Normalize()
])
4. 定义dataset加载图像分类数据集
定义数据集,pdx.datasets.ImageNet表示读取ImageNet格式的分类数据集:
train_dataset = pdx.datasets.ImageNet(
data_dir='vegetables_cls',
file_list='vegetables_cls/train_list.txt',
label_list='vegetables_cls/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='vegetables_cls',
file_list='vegetables_cls/val_list.txt',
label_list='vegetables_cls/labels.txt',
transforms=eval_transforms)
5. 使用MobileNetV3_small模型开始训练
本文档中使用百度基于蒸馏方法得到的MobileNetV3预训练模型,模型结构与MobileNetV3一致,但精度更高。PaddleX内置了20多种分类模型,查阅PaddleX 图像分类模型API了解更多分类模型。
num_classes = len(train_dataset.labels)
model = pdx.cls.MobileNetV3_small(num_classes=num_classes)
model.train(num_epochs=10,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
save_dir='output/mobilenetv3_small',
use_vdl=True)
6. 代码示例
项目地址:https://github.com/PaddlePaddle/PaddleX/blob/develop/tutorials/train/image_classification/mobilenetv3_small.py
import paddlex as pdx
from paddlex import transforms as T
# 定义训练和验证时的transforms
# API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/transforms/transforms.md
train_transforms = T.Compose(
[T.RandomCrop(crop_size=224), T.RandomHorizontalFlip(), T.Normalize()])
eval_transforms = T.Compose([
T.ResizeByShort(short_size=256), T.CenterCrop(crop_size=224), T.Normalize()
])
# 定义训练和验证所用的数据集
# API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/datasets.md
train_dataset = pdx.datasets.ImageNet(
data_dir='vegetables_cls',
file_list='vegetables_cls/train_list.txt',
label_list='vegetables_cls/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='vegetables_cls',
file_list='vegetables_cls/val_list.txt',
label_list='vegetables_cls/labels.txt',
transforms=eval_transforms)
# 初始化模型,并进行训练
# 可使用VisualDL查看训练指标,参考https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/visualdl.md
num_classes = len(train_dataset.labels)
model = pdx.cls.MobileNetV3_small(num_classes=num_classes)
# API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/models/classification.md
# 各参数介绍与调整说明:https://github.com/PaddlePaddle/PaddleX/tree/develop/docs/parameters.md
model.train(
num_epochs=10,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
learning_rate=0.01,
save_dir='output/mobilenetv3_small',
use_vdl=True)
7. 加载训练保存的模型预测
模型在训练过程中,会每间隔一定轮数保存一次模型,在验证集上评估效果最好的一轮会保存在save_dir目录下的best_model文件夹。通过如下方式可加载模型,进行预测:
import paddlex as pdx
model = pdx.load_model('output/mobilenetv3_small/best_model')
result = model.predict('vegetables_cls/bocai/100.jpg')
print("Predict Result: ", result)
预测结果输出如下,
Predict Result: [{'category_id': 0, 'category': 'bocai', 'score': 0.99960476}]
