【时间序列预测】Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting (第一篇)
论文链接:Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting.
摘要
许多真实世界的应用需要对长序列时间序列进行预测,如用电规划。长序列时间序列预测( Long sequence time-series forecasting LSTF)对模型的预测能力提出了很高的要求,即能够有效地捕捉输出和输入之间精确的长期依赖耦合( long-range dependency coupling)。最近的研究表明,Transformer 具有提高预测能力的潜力。然而,Transformer 存在一些严重的问题,使它不能直接应用于 LSTF,包括平方时间复杂度( quadratic time complexity)、高内存使用以及编码器-解码器架构固有的局限性。为了解决这些问题,我们设计了一个有效的基于Transformer 的 LSTF 模型,称为 Informer,它具有三个明显的特征: (i) ProbSparse self-attention 机制,在时间复杂度和内存使用上达到 O(L log L),并且在序列的依赖对齐上具有可比的性能。(ii) self-attention 蒸馏机制通过减半 (halving)的级联层输入突出了注意力,有效地处理极长输入序列。(iii)生成式风格的解码器虽然概念上简单,但只需一次forward 运算就可以预测出长时间序列,而不需要一步步地进行,大大提高了长时间序列预测的推理速度。在四个大规模数据集上的大量实验表明, Informer 的性能明显优于现有算法,为 LSTF 问题提供了一种新的解决方案。
论文十问
1. 论文试图解决什么问题?
长期时间序列预测问题。即 Long sequence time-series forecasting:LSTF。也就是预测更长的序列,并且不局限在单变量。
2. 这是否是一个新的问题?
不是。常用于传感器网络监控,能源和智能电网管理,经济与金融, 疾病传播分析等场景。
3. 这篇文章要验证一个什么科学假设?
LSTF 问题要求两点:
a. 非凡的长期对齐能力;
b.对长序列输入和输出进行有效操作;
Transformer 优点:比RNN模型能抓住长期依赖; self-attention 机制 能够在理论上将网络信号游走路径的最大长度减少到最短的 O(1) ,并且避免循环结构,对于LSTF 问题具有很大潜力。
Transformer 缺点: self-attention 机制 不满足要求b,在 L 长度的输入/输出上,L平方计算和内存消耗。
因此,本文想做的是:优化 Transformer 在LSTF 问题上的缺点。
Vanilla Transformer应用于LSTF的缺点:
- self-attention 的平方计算复杂度。self-attention 机制的 规范化点积(canonical dot-product)导致每层的 时间复杂度和内存使用量为
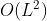 。
。 - 对于长输入,在堆叠层中的内存瓶颈。 J个编码器/解码器层的堆叠使全部内存使用到
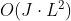 ,这限制了模型在接收长序列输入的可扩展性。
,这限制了模型在接收长序列输入的可扩展性。 - 预测长序列时候的速度暴跌。Vanilla Transformer的动态解码使得一步步推理和基于RNN的模型一样慢。
4. 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
以往大部分是短期预测(48个点或更少),LSTM 性能瓶颈在 48个点,性能和推理速度不能满足要求。
时间序列预测可以分为两类:
- 经典方法: (Box et al. 2015; Ray 1990; Seeger et al. 2017; Seeger, Salinas, and Flunkert 2016)
- 编码器-解码器范式的深度学习方法:主要使用RNN和它们的变体。
研究员:暂定。
5. 论文中提到的解决方案之关键是什么?
已有许多对 Vanilla Transformer 的优化。 如 Sparse Transformer (Child et al. 2019), LogSparse Transformer (Li et al. 2019), and Longformer (Beltagy, Peters, and Cohan 2020) , Reformer (Kitaev, Kaiser, and Levskaya 2019), Linformer (Wang et al. 2020),Transformer-XL (Dai et al. 2019) and Compressive Transformer (Rae et al. 2019)。但是这些工作主要在解决限制1。
本文对上面三个限制进行了研究。研究了 self-attention 的稀疏性,改进了网络组件,进行了大量实验。
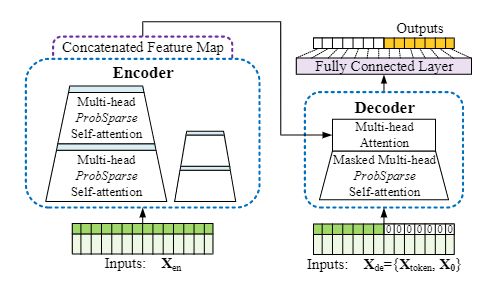
图 2:Informer 模型概述。 左:编码器接收大量长序列输入(绿色序列)。 我们用提出的 ProbSparseself-attention 替换了 canonical self-attention。 蓝色梯形 是提取主导注意力的 self-attention distilling 操作,大大减小了网络大小。 层堆叠复制增加了鲁棒性。 右图:解码器接收长序列输入,将目标元素填充为零,测量特征图的加权注意力部分,并立即以生成方式预测输出元素(橙色序列)。
1. 提出 ProbSparse self-attention 解决Self-Attention 计算复杂度问题

2. 提出 self-attention 蒸馏操作 解决堆叠层的内存 ![]() 问题
问题
3. 生成风格的解码器一次预测多个时间步的值,解决自回归生成的问题(生成速度慢)。
本文解决方案的关键在于 优化Transformer 应用到长时间预测的三个问题。
6. 论文中的实验是如何设计的?
1. 单变量预测以及不同粒度的考虑
2. 多变量预测以及不同粒度的考虑
3. 参数敏感性:输入长度、采样因子大小和层堆叠的组合
4. 消融研究: ProbSparse self-attention 机制的性能、 self-attention distilling的性能、生成式解码器的性能
5. 与其他模型比较计算效率。
7. 用于定量评估的数据集是什么?代码有没有开源?
ETT (Electricity Transformer Temperature):电力变压器温度
ECL (Electricity Consuming Load):用电量
Weather:气象
已开源:GitHub - zhouhaoyi/Informer2020: The GitHub repository for the paper "Informer" accepted by AAAI 2021.
8. 论文中的实验及结果有没有很好地支持需要验证的科学假设?
真实世界中的数据的实验表面,该算法是有效的。
9. 这篇论文到底有什么贡献?
- 提出 Informer 来解决长序列时间序列的预测问题。验证了 类 Transformer 模型在捕获长序列时间序列的输入和输出之间长期依赖关系的潜能。
- 提出 ProbSparse self-attention 机制替换了 canonical self-attention。ProbSparse self-attention 机制在依赖对齐上达到了 O(L log L) 时间复杂度和 O(L log L) 的空间使用。
- 提出了self-attention distilling操作,来优先考虑J-stacking层中的主导 attention scores,并将总空间复杂度大幅降低到
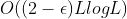 ,这有助于接收长序列输入。
,这有助于接收长序列输入。 - 提出生成式风格的解码器。一次前向传播就可以获得长序列输出,避免了推理阶段的累加误差。
10. 下一步呢?有什么工作可以继续深入?
结合Autoformer 的序列分解进来?时间序列预测更像是生成模型,可以借鉴各种生成模型对长时间序列预测进行优化。包括 更有效的和有效率的编解码器,自回归生成的解决方案等。
参考文献
【AI Drive】第55期 - AAAI 2021最佳论文 | Informer:比Transformer更有效的长时间序列预测方法_哔哩哔哩_bilibili
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting.
Informer代码详解_尘世猫的博客-CSDN博客_informer模型
AAAI最佳论文Informer 解读_fluentn的博客-CSDN博客_informer算法