基于MindSpore的手写数字识别初体验
在开始之前,首先声明本篇文章参考官方编程指南,我基于官网的这篇文章加以自己的理解发表了这篇博客,希望大家能够更快更简单直观的体验MindSpore,如有不妥的地方欢迎大家指正。
【本文代码编译环境为MindSpore1.3.0 CPU版本】
准备环节
- 确保已安装MindSpore(可以根据自己的硬件情况安装,CPU,GPU,Ascend环境均可)
- 选择一个集成开发工具(Jupyter Notebook,Pycharm等),我选择的是Pycharm
- 查看是否安装python中的画图库 matplotlib,若未安装,在终端输入pip install matplotlib
数据集
下载数据集
手写数字识别初体验采用的是业界经典的MNIST数据集,它包含了60000张训练图片,10000张测试图片。
MindSpore中提供了很多经典数据集的下载命令,其中自然包括MNIST数据集。在Jupyter Notebook中执行如下命令下载MNIST数据集。
Copy!mkdir -p ./datasets/MNIST_Data/train ./datasets/MNIST_Data/test
!wget -NP ./datasets/MNIST_Data/train https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-labels-idx1-ubyte --no-check-certificate
!wget -NP ./datasets/MNIST_Data/train https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-images-idx3-ubyte --no-check-certificate
!wget -NP ./datasets/MNIST_Data/test https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-labels-idx1-ubyte --no-check-certificate
!wget -NP ./datasets/MNIST_Data/test https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-images-idx3-ubyte --no-check-certificate
!tree ./datasets/MNIST_Data
得到的文档目录结构如图所示:
./datasets/MNIST_Data
├── test
│ ├── t10k-images-idx3-ubyte
│ └── t10k-labels-idx1-ubyte
└── train
├── train-images-idx3-ubyte
└── train-labels-idx1-ubyte
2 directories, 4 files
./ 表示当前目录的意思,(当前项目中有一个datasets的文件夹,datasets文件夹下有一个MNIST_Data文件夹,然后依次类推)。
这里我没有采用命令下载的方法,因为我用的是pycharm。笔者可前往http://yann.lecun.com/exdb/mnist/下载MNIST数据集,并将它按照文档目录结构图的形式放置于我们的项目中。
配置运行信息
接着我们配置MindSpore的运行模式,硬件信息等。
from mindspore import context
context.set_context(mode=context.GRAPH_MODE, device_target="CPU")
导入context模块,调用context的set_context方法,参数mode表示运行模式,MindSpore支持动态图和静态图两种模式,GRAPH_MODE表示静态图模式,PYNATIVE_MODE表示动态图模式,对于手写数字识别问题来说采用静态图模式即可。参数device_target表示硬件信息,有三个选项(CPU,GPU,Ascend),读者可根据自己的真实环境选择。
查看数据集的详细信息
既然我们已经将MNIST数据集下载到本地,那我们自然得去看一下它里面到底有什么东西,是否真的是我们熟知的手写阿拉伯数字。这里我们就要采用画图库了。
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
import mindspore.dataset as ds
train_data_path = "./datasets/MNIST_Data/train"
test_data_path = "./datasets/MNIST_Data/test"
mnist_ds = ds.MnistDataset(train_data_path)
#生成的图像有两列[img, label],列图像张量是uint8类型,
#因为像素点的取值范围是(0, 255),需要注意的是这两列数据的数据类型是Tensor
print('The type of mnist_ds:', type(mnist_ds))
print("Number of pictures contained in the mnist_ds:", mnist_ds.get_dataset_size())
#int, number of batches.
#print(mnist_ds.get_batch_size()) #Return the size of batch.
dic_ds = mnist_ds.create_dict_iterator() #数据集上创建迭代器,为字典数据类型,输出的为Tensor类型
item = next(dic_ds)
img = item["image"].asnumpy() #asnumpy为Tensor中的方法,功能是将张量转化为numpy数组,因为matplotlib.pyplot中不
#能接受Tensor数据类型的参数
label = item["label"].asnumpy()
print("The item of mnist_ds:", item.keys())
print("Tensor of image in item:", img.shape)
print("The label of item:", label)
plt.imshow(np.squeeze(img)) #squeeze将shape中为1的维度去掉,plt.imshow()函数负责对图像进行处理,并显示其格式
plt.title("number:%s"% item["label"].asnumpy())
plt.show() #show显示图像
代码部分的解释,我想注释已经写的很明白了,但我们需要注意几点。
- 我们尽量将自己拿到的数据集转化为MindSpore能够处理的数据类型,因为框架里面加了一些对于数据加速的方法。当然,这里的MNIST数据集不需要我们使用复杂的加载,因为对于MNIST这一类经典的数据集MindSpore都提供了专门的加载方法,将它加载成MindSpore能处理的数据。
- MindSpore提供的内置数据集处理方法默认输出一般都是在框架中通用的Tensor,但是对于非框架优化包含的python库,包括matplotlib,它们就无法处理接受Tensor,这是我们就要采用Tensor类中定义的asnumpy方法将张量转化为numpy数组
上述代码的运行截图:

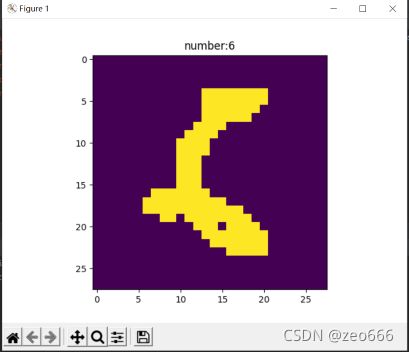
上述结果验证了我们前面的说法,训练集中有60000张图片,以image和lable两个标签分别储存,并且每一张图片的大小为28 x 28,通道数为1说明里面是黑白图片。图中显示的图片是6(我觉得有点不像),它的标签值也为6。
加载及处理数据集
定义一个create_dataset函数。在这个函数中,总体分为一下几步。
- 将原始的MNIST数据集加载进来, mnist_ds = ds.MnistDataset(data_path)
- 设置一些数据增强和处理所需要的参数(parameters)
- 使用2中设置的参数得到一些实例化的数据增强和处理方法
- 将3中的方法映射到(使用)在对应数据集的相应部分(image,label)
- 返回处理好的数据集(不同的神经网络可以接受不同的输入数据格式)
create_dataset函数代码如下:
import mindspore.dataset.vision.c_transforms as CV
import mindspore.dataset.transforms.c_transforms as C
from mindspore.dataset.vision import Inter
from mindspore import dtype as mstype
def create_dataset(data_path, batch_size=32, repeat_size=1,
num_parallel_workers=1):
mnist_ds = ds.MnistDataset(data_path)
# 定义数据增强和处理所需的一些参数
resize_height, resize_width = 32, 32
rescale = 1.0 / 255.0
shift = 0.0
rescale_nml = 1 / 0.3081
shift_nml = -1 * 0.1307 / 0.3081
# 根据上面所定义的参数生成对应的数据增强方法,即实例化对象
resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR)
rescale_nml_op = CV.Rescale(rescale_nml, shift_nml)
rescale_op = CV.Rescale(rescale, shift)
hwc2chw_op = CV.HWC2CHW()
type_cast_op = C.TypeCast(mstype.int32)
# 将数据增强处理方法映射到(使用)在对应数据集的相应部分(image,label)
mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=rescale_nml_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=num_parallel_workers)
# 处理生成的数据集
buffer_size = 10000
mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)
mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)
mnist_ds = mnist_ds.repeat(repeat_size)
return mnist_ds
导入的模块:
- mindspore.dataset.vision.c_transforms:MindSpore提供的通过数据增强操作对图像进行预处理,从而提高模型的广泛性。它是基于基于C++的OpenCV实现,具有较高的性能。接着来看一下,在增强MNIST数据集中,我们所使用到该模块中的方法(算子)。
CV.Resize(size, interpolation=Inter.LINEAR):
功能:使用给定的插值模式将输入图像调整为给定大小。
参数:size:调整后输出图像的大小;interpolation:图像的插值模式(5个常量可供选择),一般情况下使用默认的Inter.LINEAR即可。
CV.Rescale(rescale, shift):
功能:使用给定的重缩放和移位重缩放输入图像。此运算符将使用以下命令重新缩放输入图像:输出=图像*重新缩放+移位(output = image * rescale + shift),可以用来消除图片在不同位置给模型带来的影响。
参数:rescale:缩放因子;shift:偏移因子
CV.HWC2CHW():
功能:将输入图像从形状(H,W,C)转换为形状(C,H,W)。输入图像应为3通道图像。
- mindspore.dataset.transforms.c_transforms:该模块也是一个用于支持常见的图形增强功能的模块,基于C++的OpenCV实现的。
C.TypeCast(data_type):
功能:一个转化为给定MindSpore数据类型(data_type)的张量操作。
参数:data_type:MindSpore中dtype模块中所指定的数据类型。
- mindspore.dataset.MnistDataset,MindSpore中专门提供的加载处理MNIST数据集为MindSpore数据类型的类,这里主要看一下它的map方法。
ds.map(operations, input_columns=None, output_columns=None, column_order=None, num_parallel_workers=None, python_multiprocessing=False, cache=None, callbacks=None):
功能:将具体的操作和方法应用到数据集上
参数:我们主要看一下使用到的参数,因为它的很多参数实际上是默认的。operations:用于数据集的操作列表,操作将按照他们在列表中的顺序进行应用。 ;input_columns:将作为输入传递给第一个操作的列的名称列表。 ;num_parallel_workers:用于并行处理数据集的线程数,默认值为无。
参数含义
现在既然我们清楚了这些方法的功能以及他们中参数的含义,那么这里为什么要将参数定义成这样呢?
resize_height, resize_width = 32, 32
resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR)
mnist_ds = mnist_ds.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers)
我们要将MNIST数据中的28 x 28大小的图片转化为32 x 32的大小,这是因为后面我们要采用的LeNet-5的卷积神经网络训练模型,该模型要求输入图像的尺寸统一归一化为32 x 32,具体的关于该网络的细节,我会在构建网络时详细介绍。
rescale = 1.0 / 255.0, shift = 0.0
rescale_op = CV.Rescale(rescale, shift)
mnist_ds = mnist_ds.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers)
这里我们将数据集中图像进行缩放,选择除以255是因为像素点的取值范围是(0,255)。该操作可以使得每个像素的数值大小在(0,1)范围中,可以提升训练效率。进行完该操作之后,有对图像进行了依次缩放,不过那个缩放的值应该是总结出来的能够进一步提高训练效率的值,需要大量实验才能得到,这里我直接是使用了官方代码上的值。
hwc2chw_op = CV.HWC2CHW()
使用它对图片张量进行转化的原因是原图片张量形状是(28 x 28 x 1)(高 x 宽 x通道),在python中用高维数组解释是28个 28 x 1的矩阵,这不是很符合我们的计算习惯,所以我们将它转化为1 x 28 x 28(通道 x 高 x 宽),相对于是1个 28 x 28的矩阵,这不就是我们推导计算过程中常用的值吗。因此,它能够方便我们进行数据训练。
buffer_size = 10000
mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)
在该操作之前,我们已经将MNIST数据集处理成网络和框架所能接受的数据。接着就是对处理好的数据集进行一个增强操作。
shuffle用于将数据集随机打乱,我们不希望有太多的人为因素干扰我们的训练,因为可能MNIST数据集本身是有一定规律的,我们不希望按照制作这个数据集的前辈的顺序来训练神经网络。
mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)
将整个数据集按照batch_size的大小分为若干批次,每一次训练的时候都是按一个批次的数据进行训练, drop_remainder:确定是否删除数据行数小于批大小的最后一个块,这里设置为True就是只保留数据集个数整除batch_size后得到的批次,多余得则从minst_ds中舍弃。
mnist_ds = mnist_ds.repeat(repeat_size)
将数据集重复repeat_size次,需要注意得是该操作一般使用在batch操作之后。
原理讲完之后,让我们看一下处理好的数据集是什么样子的吧。
数据集的展示
ms_dataset = create_dataset(train_data_path)
print('Number of each group',ms_dataset.)
print('Number of groups in the dataset:', ms_dataset.get_dataset_size())

可以看到,我们将32张图片作为一个批次,将训练集总共分为了60000/32 = 1875个批次。接着我们拿出一个批次的数据将其形状等属性显示出来并将它进行可视化。
data = next(ms_dataset.create_dict_iterator(output_numpy=True))
images = data["image"]
labels = data["label"]
print('Tensor of image:', images.shape)
print('Labels:', labels)
count = 1
for i in images:
plt.subplot(4, 8, count)
plt.imshow(np.squeeze(i))
plt.title('num:%s'%labels[count-1])
plt.xticks([])
count += 1
plt.axis("off")
plt.show()

从Tensor of image:可以看出我们在处理数据的操作中执行Resize和HWC2CHW成功将图片转化为1 x 32 x 32的,同时可以知道所谓的分批次就是将batch_size张图片放在一起,用矩阵表示就是将batch_size个矩阵合成一个大型的矩阵,每一次使用一个这样的大型矩阵去训练,一个一个来。这样可以避免过高维度数组造成的内存过大,训练时间过长的问题,接着看一下图片显示。

接下来,我将给大家介绍卷积神经网络LeNet-5的一些基础知识,以及如何使用MindSpore来构建出一个LeNet-5网络。
LeNet-5
对于手写数字识别初体验的网络,我们选择的是相对简单的一个卷积神经网络——LeNet-5。它的输入是一个黑白二维图片,先经过两层卷积层提取特征,然后到池化层,再经过全连接层连接,最后使用softmax分类作为输出层(因为它的输出有10个标签),网络结构如下图所示:
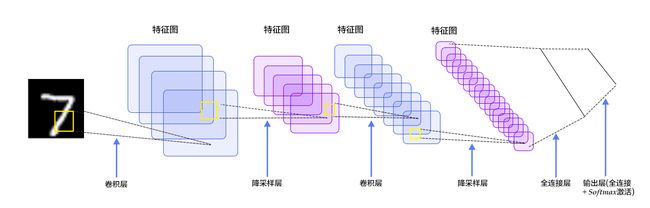
LeNet-5是一个非常经典的网络,它虽然规模较小,但已经包含了一个卷积神经网络的基本模块——卷积层,池化层,全连接层。让我们来详细看一下它的各层参数以及作用。

输入层
我们的输入数据(手写数字图片)就是首先传入输入层,LeNet-5网络要求输入层的图片尺寸必须为32 x 32。我们已经通过create_dataset()函数将图片处理为 32 x 32了。
卷积层1(C1层)
输入:32 x 32 x 1
卷积核大小: 5 x 5(过滤器)
卷积核数量:6
输出形状:28 x 28 x 6
可训练参数:(5 x 5 +1)x 6 =156(5 x 5过滤器参数加一个偏差b)
说明:对输入图像做卷积运算,一个过滤器与图片进行卷积运算得到28 x 28(32 - 5 +1)的矩阵,使用6个过滤器自然得到28 x 28 x 6的高阶数组。可以理解为提取了6个不同的图片特征。对于32 x 32中的每一个像素点,它都和6个过滤器以及他们的偏差有连接,我们通过156个参数就完成了全部的连接,这主要是通过权值共享实现的。(这是卷积层的主要优势之一,可以使要训练的参数减少)。
池化层1(S2层)
输入:28 x 28 x 6
采样区域:2 x 2
采用方式:论文里面使用的是平均池化的方式,但由于现在更加喜欢使用最大池化,所以我们这里采用最大池化。4个输入比较大小,取最大值。
采样种类:6
输出形状:14 x 14 x 6(这里的步长 s = 2)
说明:第一次卷积运算提取特征之后,进行池化运算,将图片的大小进行缩减。2 x 2的采样器通常高和宽缩小一半。
卷积层2(C3层)
输入:14 x 14 x 6
卷积核大小 :5 x 5
卷积核数量 : 16
输出形状:10 x 10 x 16
池化层2(S4层)
输入:10 x 10 x 16
采样区域:2 x 2
采样方式:最大池化
输出 形状:5 x 5 x 16
C5层
输入:5 x 5 x 16
功能:展平张量
输出形状:1 x 1 x 120
F6层(全连接层)
输入:C5
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过Relu函数输出。
Output层-全连接层
该层也是全连接层,不过它对应的是10个标签(0到9的数字)。需采用softmax分类得到。
定义网络
首先说明MindSpore支持多种参数初始化方法,常用的有Normal等。具体可查看https://www.mindspore.cn/docs/api/zh-CN/r1.3/api_python/mindspore.common.initializer.html的接口说明。
另外,MindSpore中所有网络的定义都需要继承自mindspore.nn.cell,并重写父类的init和construct方法,其中init方法中完成一些我们所需算子,网络的定义,construct方法则是写网络的执行逻辑。而且在nn模块中有很多定义好的各网路层可以使用,包括卷积层(nn.Conv2d()),全连接层(nn.Flatten())等。
接下来看一下我们依照LeNet-5网络各层的参数以及功能要求使用MindSpore定义的网络结构:
class LeNet5(nn.Cell):
def __init__(self, num_class=10, num_channel=1):
super(LeNet5, self).__init__() #继承父类nn.cell的__init__方法
#nn.Conv2d的第一个参数是输入图片的通道数,即单个过滤器应有的通道数,第二个参数是输出图片的通道数
#即过滤器的个数,第三个参数是过滤器的二维属性,它可以是一个int元组,但由于一般过滤器都是a x a形
#式的,而且为奇数。所以这里填入单个数即可,参数pad_mode为卷积方式,valid卷积即padding为0的卷积
#现在也比较流行same卷积,即卷积后输出的图片不会缩小。需要注意的是卷积层我们是不需要设置参数的随机
#方式的,因为它默认会给我们选择为Noremal。
self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid')
#nn.Dense为致密连接层,它的第一个参数为输入层的维度,第二个参数为输出的维度,第三个参数为神经网
#络可训练参数W权重矩阵的初始化方式,默认为normal
self.fc1 = nn.Dense(16 * 5 * 5, 120, weight_init=Normal(0.02))
self.fc2 = nn.Dense(120, 84, weight_init=Normal(0.02))
self.fc3 = nn.Dense(84, num_class, weight_init=Normal(0.02))
#nn.ReLU()非线性激活函数,它往往比论文中的sigmoid激活函数具有更好的效益
self.relu = nn.ReLU()
#nn.MaxPool2d为最大池化层的定义,kernel_size为采样器的大小,stride为采样步长,本例中将其
#都设置为2相当于将图片的宽度和高度都缩小一半
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
#nn.Flatten为输入展成平图层,即去掉那些空的维度
self.flatten = nn.Flatten()
def construct(self, x):
#输入x,下面即是将x通过LeNet5网络执行前向传播的过程
x = self.max_pool2d(self.relu(self.conv1(x)))
x = self.max_pool2d(self.relu(self.conv2(x)))
x = self.flatten(x)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
你可能一下子看不懂上面的一些代码,但没有关系,只要你懂了LeNet-5网络的特征和运算规则,前往api中的nn模块参看相应说明之后你马上就会懂了。
print(LeNet5())
我们通过该代码来看一下LeNet-5的各层网络参数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xT9GQeCe-1630322405510)(D:\photo\捕获29.PNG)]
读者可以根据打印的参数选项与我在前面提到过的的参数形式和自己掌握的一些数学矩阵计算规则验证一下,来加强自己对这些参数的理解。
反向传播
前面我们已经定义好了网络的前向传播过程,为了改变我们的可训练参数,即让我们所使用的参数能够预测出更加精确的值。我们需要定义损失函数即优化器,在MindSpore框架中是封装好了损失函数和优化器的,这使得我们的编程可以更快更加高效。
损失函数:又叫目标函数,用于衡量预测值与实际值差异的程度。深度学习通过不停地迭代来缩小损失函数的值。定义一个好的损失函数,可以有效提高模型的性能。常见的有二分类的损失函数L,以及softmax损失函数等。
优化器:用于最小化损失函数,从而在训练过程中改进模型。
from mindspore.nn import SoftmaxCrossEntropyWithLogits
lr = 0.01 #learingrate,学习率,可以使梯度下降的幅度变小,从而可以更好的训练参数
momentum = 0.9
network = LeNet5()
#使用了流行的Momentum优化器进行优化
#vt+1=vt∗u+gradients
#pt+1=pt−(grad∗lr+vt+1∗u∗lr)
#pt+1=pt−lr∗vt+1
#其中grad、lr、p、v和u分别表示梯度、学习率、参数、力矩和动量。
net_opt = nn.Momentum(network.trainable_params(), lr, momentum)
#相当于softmax分类器
#sparse指定标签(label)是否使用稀疏模式,默认为false,reduction为损失的减少类型:mean表示平均值,一般
#情况下都是选择平均地减少
net_loss = SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
自定义一个回调类
自定义一个数据收集的回调类StepLossAccInfo该类继承自Callback类。主要用于收集两类信息,step与loss值之间地关系。step与对应模型精度之间联系。
我们将该类作为回调函数,会在后面的高级api——model.train模型训练函数中调用。
from mindspore.train.callback import Callback
# custom callback function
class StepLossAccInfo(Callback):
def __init__(self, model, eval_dataset, steps_loss, steps_eval):
self.model = model #计算图模型Model
self.eval_dataset = eval_dataset #测试数据集
self.steps_loss = steps_loss
#收集step和loss值之间的关系,数据格式{"step": [], "loss_value": []},会在后面定义
self.steps_eval = steps_eval
#收集step对应模型精度值accuracy的信息,数据格式为{"step": [], "acc": []},会在后面定义
def step_end(self, run_context):
cb_params = run_context.original_args()
#cur_epoch_num是CallbackParam中的定义,获得当前处于第几个epoch,一个epoch意味着训练集
#中每一个样本都训练了一次
cur_epoch = cb_params.cur_epoch_num
#同理,cur_step_num是CallbackParam中的定义,获得当前执行到多少step
cur_step = (cur_epoch-1)*1875 + cb_params.cur_step_num
self.steps_loss["loss_value"].append(str(cb_params.net_outputs))
self.steps_loss["step"].append(str(cur_step))
if cur_step % 125 == 0:
#调用model.eval返回测试数据集下模型的损失值和度量值,dic对象
acc = self.model.eval(self.eval_dataset, dataset_sink_mode=False)
self.steps_eval["step"].append(cur_step)
self.steps_eval["acc"].append(acc["Accuracy"])
编写训练网络
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor
from mindspore.nn import Accuracy
from mindspore import Model
epoch_size = 1 #每个epoch需要遍历完成图片的batch数,这里是只要遍历一次
model_path = "./models/ckpt/mindspore_quick_start/"
eval_dataset = create_dataset(test_data_path)
#调用Model高级API,将LeNet-5网络与损失函数和优化器连接到一起,具有训练和推理功能的对象。
#metrics 参数是指训练和测试期,模型要评估的一组度量,这里设置的是"Accuracy"准确度
model = Model(network, net_loss, net_opt, metrics={"Accuracy": Accuracy()} )
#保存训练好的模型参数的路径
config_ck = CheckpointConfig(save_checkpoint_steps=375, keep_checkpoint_max=16)
ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet", directory=model_path, config=config_ck)
#回调类中提到的我们要声明的数据格式
steps_loss = {"step": [], "loss_value": []}
steps_eval = {"step": [], "acc": []}
#使用model等对象实例化StepLossAccInfo,得到具体的对象
step_loss_acc_info = StepLossAccInfo(model , eval_dataset, steps_loss, steps_eval)
#调用Model类的train方法进行训练,LossMonitor(125)每隔125个step打印训练过程中的loss值,dataset_sink_mode为设置数据下沉模式,但该模式不支持CPU,所以这里我们只能设置为False
model.train(epoch_size, ms_dataset, callbacks=[ckpoint_cb, LossMonitor(125), step_loss_acc_info], dataset_sink_mode=False)
接下来我们直接开始训练:

从上面的训练截图可以看一看出效果还是很好的,因为我第一次跑手写数字识别项目是别人给我的pytorch版本,一般跑第一个epoch的准确率是94%左右。用MindSpore来跑这个loss值这么小,我觉得可能是处理数据集上有优势一些。这只是一个较小的项目,我在一篇文章上看到,MindSpore结合Ascend处理器跑大一点的项目一般比其它的主流框架平台都要快一些。
同时我们可以看到,我们的项目下有一个models的文件夹,里面储存的ckpt文件就是我们训练过程中的参数,不过LeNet-5的参数量并不是很大。我们可以将该文件的参数加载到LeNet-5网络中,然后用该网络去跑测试集可以得到在测试集上的准确率。
def test_net(network, model, mnist_path):
"""Define the evaluation method."""
print("============== Starting Testing ==============")
# load the saved model for evaluation
param_dict = load_checkpoint("./models/ckpt/mindspore_quick_start/checkpoint_lenet-1_1875.ckpt")
# load parameter to the network
load_param_into_net(network, param_dict)
# load testing dataset
acc = model.eval(eval_dataset, dataset_sink_mode=False)
print("============== Accuracy:{} ==============".format(acc))
test_net(network, model, mnist_path)

可以看到一次训练就有将近96%的准确率,这已经非常不错了。如果想要继续提高它的准确率可以去自定义训练网络来控制训练整个集合的次数,或者修改参数等都可以尝试。
最后一步,我们使用官网的一段代码,提取出一个批次的图片,使用已训练好的上面的模型来预测一下每一张图片的标签,并将其可视化。
ds_test = eval_dataset.create_dict_iterator()
data = next(ds_test)
images = data["image"].asnumpy()
labels = data["label"].asnumpy()
output = model.predict(Tensor(data['image']))
#利用加载好的模型的predict进行预测,注意返回的是对应的(0到9)的概率
pred = np.argmax(output.asnumpy(), axis=1)
err_num = []
index = 1
for i in range(len(labels)):
plt.subplot(4, 8, i+1)
color = 'blue' if pred[i] == labels[i] else 'red'
plt.title("pre:{}".format(pred[i]), color=color)
plt.imshow(np.squeeze(images[i]))
plt.axis("off")
if color == 'red':
index = 0
print("Row {}, column {} is incorrectly identified as {}, the correct value should be {}".format(int(i/8)+1, i%8+1, pred[i], labels[i]), '\n')
if index:
print("All the figures in this group are predicted correctly!")
print(pred, "<--Predicted figures")
print(labels, "<--The right number")
plt.show()
结果如下所示:

可以看到我抽到的这一组32张图片是属于手气较好的,全部预测正确。上面有些数字确实挺有干扰性的,但机器还是识别出来了(比如第2行最后一张2,写的挺奇葩的)。总之到了这里,基于MindSpore的手写数字识别初体验就已经结束了,写这篇文章不是说要深入手写数字识别,而是说经过这个小型项目的实践,我们可以对MindSpore的各个模块有个大体的理解。比如说dataset模块用于各种数据集的处理和加载,有热门数据集的加载处理方法,有MindSpore专属的数据格式,有一些不同数据集的增强方法。nn模块提供了与网络构建,网络参数相关的各种封装好的高级API。类似的还有很多,我们可以通过这些模块的功能进一步细化深入到该模块中子模块,方法。从功能入手,由表及里,分析源码。
训练好的参数已经上传,不想训练的小伙伴可以直接将它加载进LeNet-5网络中去实践,需要自己训练的也可以使用我上传的代码。不过该代码是文章所以测试代码的综合,其中有些测试的点已经被注释,读者可自行查看编辑。
码字实在不易,希望读者可以前往比赛地址1或者是比赛地址2浏览一下,点个赞就更好,支持一下笔者的创作。。。