2021-09-24
这里写自定义目录标题
- 欢迎使用Markdown编辑器
-
- K8S中Pod的生命周期与init container初始化容器详解
- 开启kube-proxy的ipvs的前置条件
-
- 即将初始化
- Kubernetes初始化失败处理.
- k8s中pod状态
- 添加节点
- 证书过期
- Kubernetes常用组件部署
- 功能
- 合理的创建标题,有助于目录的生成
- 如何改变文本的样式
- 插入链接与图片
- 如何插入一段漂亮的代码片
- 生成一个适合你的列表
- 创建一个表格
-
- 设定内容居中、居左、居右
- SmartyPants
- 创建一个自定义列表
- 如何创建一个注脚
- 注释也是必不可少的
- KaTeX数学公式
- 新的甘特图功能,丰富你的文章
- UML 图表
- FLowchart流程图
- 导出与导入
-
- 导出
- 导入
欢迎使用Markdown编辑器
你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。

etcd 一个高可用的K/V键值对存储和服务发现系统
flannel 实现夸主机的容器网络的通信
kube-apiserver 提供kubernetes集群的API调用
kube-controller-manager 确保集群服务
kube-scheduler 调度容器,分配到Node
kubelet 在Node节点上按照配置文件中定义的容器规格启动容器
kube-proxy 提供网络代理服务
K8S中Pod的生命周期与init container初始化容器详解

pause容器说明
每个Pod里运行着一个特殊的被称之为Pause的容器,其他容器则为业务容器,这些业务容器共享Pause容器的网络栈和Volume挂载卷,因此他们之间通信和数据交换更为高效。在设计时可以充分利用这一特性,将一组密切相关的服务进程放入同一个Pod中;同一个Pod里的容器之间仅需通过localhost就能互相通信。
kubernetes中的pause容器主要为每个业务容器提供以下功能:
PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID。
网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围。
IPC命名空间:Pod中的多个容器能够使用System V IPC或POSIX消息队列进行通信。
UTS命名空间:Pod中的多个容器共享一个主机名;Volumes(共享存储卷)。
Pod中的各个容器可以访问在Pod级别定义的Volumes。
Init Container容器
Pod可以包含多个容器,应用运行在这些容器里面,同时 Pod 也可以有一个或多个先于应用容器启动的 Init 容器。
如果为一个 Pod 指定了多个 Init 容器,这些Init容器会按顺序逐个运行。每个 Init 容器都必须运行成功,下一个才能够运行。当所有的 Init 容器运行完成时,Kubernetes 才会为 Pod 初始化应用容器并像平常一样运行。
Init容器与普通的容器非常像,除了以下两点:
1、Init容器总是运行到成功完成且正常退出为止
2、只有前一个Init容器成功完成并正常退出,才能运行下一个Init容器。
如果Pod的Init容器失败,Kubernetes会不断地重启Pod,直到Init容器成功为止。但如果Pod对应的restartPolicy为Never,则不会重新启动。
在所有的 Init 容器没有成功之前,Pod 将不会变成 Ready 状态。 Init 容器的端口将不会在 Service 中进行聚集。 正在初始化中的 Pod 处于 Pending 状态,但会将条件 Initializing 设置为 true。
如果 Pod 重启,所有 Init 容器必须重新执行。
在 Pod 中的每个应用容器和 Init 容器的名称必须唯一;与任何其它容器共享同一个名称,会在校验时抛出错误。
Init 容器能做什么?
因为 Init 容器是与应用容器分离的单独镜像,其启动相关代码具有如下优势:
1、Init 容器可以包含一些安装过程中应用容器不存在的实用工具或个性化代码。例如,在安装过程中要使用类似 sed、 awk、 python 或 dig 这样的工具,那么放到Init容器去安装这些工具;再例如,应用容器需要一些必要的目录或者配置文件甚至涉及敏感信息,那么放到Init容器去执行。而不是在主容器执行。
2、Init 容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低。
3、应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像。
4、Init 容器能以不同于Pod内应用容器的文件系统视图运行。因此,Init容器可具有访问 Secrets 的权限,而应用容器不能够访问。
5、由于 Init 容器必须在应用容器启动之前运行完成,因此 Init 容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。一旦前置条件满足,Pod内的所有的应用容器会并行启动。
=========================================================================================
Init 容器示例
下面的例子定义了一个具有 2 个 Init 容器的简单 Pod。 第一个等待 myservice 启动,第二个等待 mydb 启动。 一旦这两个 Init容器都启动完成,Pod 将启动spec区域中的应用容器。
[root@k8s-master lifecycle]# pwd
/root/k8s_practice/lifecycle
[root@k8s-master lifecycle]# cat init_C_pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp-busybox-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: registry.cn-beijing.aliyuncs.com/google_registry/busybox:1.24
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: registry.cn-beijing.aliyuncs.com/google_registry/busybox:1.24
command: ['sh', '-c', "until nslookup myservice; do echo waiting for myservice; sleep 60; done"]
- name: init-mydb
image: registry.cn-beijing.aliyuncs.com/google_registry/busybox:1.24
command: ['sh', '-c', "until nslookup mydb; do echo waiting for mydb; sleep 60; done"]
启动这个 Pod,并检查其状态,可以执行如下命令:
[root@k8s-master lifecycle]# kubectl apply -f init_C_pod.yaml
pod/myapp-busybox-pod created
[root@k8s-master lifecycle]# kubectl get -f init_C_pod.yaml -o wide # 或者kubectl get pod myapp-busybox-pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-busybox-pod 0/1 Init:0/2 0 55s 10.244.4.16 k8s-node01 <none> <none>
查看更详细的信息
kubectl describe pod myapp-busybox-pod
[root@k8s-master lifecycle]# kubectl describe pod myapp-busybox-pod
Name: myapp-busybox-pod
Namespace: default
Priority: 0
…………
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m18s default-scheduler Successfully assigned default/myapp-busybox-pod to k8s-node01
Normal Pulled 2m17s kubelet, k8s-node01 Container image "registry.cn-beijing.aliyuncs.com/google_registry/busybox:1.24" already present on machine
Normal Created 2m17s kubelet, k8s-node01 Created container init-myservice
Normal Started 2m17s kubelet, k8s-node01 Started container init-myservice
如需查看Pod内 Init 容器的日志,请执行:
kubectl logs -f --tail 500 myapp-busybox-pod -c init-myservice # 第一个 init container 详情
[root@k8s-master lifecycle]# kubectl logs -f --tail 500 myapp-busybox-pod -c init-myservice # 第一个 init container 详情
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
waiting for myservice
nslookup: can't resolve 'myservice'
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
………………
[root@k8s-master lifecycle]# kubectl logs myapp-busybox-pod -c init-mydb # 第二个 init container 详情
Error from server (BadRequest): container "init-mydb" in pod "myapp-busybox-pod" is waiting to start: PodInitializing
此时Init 容器将会等待直至发现名称为mydb和myservice的 Service。
Service yaml文件
[root@k8s-master lifecycle]# pwd
/root/k8s_practice/lifecycle
[root@k8s-master lifecycle]# cat init_C_service.yaml
---
kind: Service
apiVersion: v1
metadata:
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
---
kind: Service
apiVersion: v1
metadata:
name: mydb
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9377
创建mydb和myservice的 service 命令:
[root@k8s-master lifecycle]# kubectl create -f init_C_service.yaml
service/myservice created
service/mydb created
之后查看pod状态和service状态,能看到这些 Init容器执行完毕后,随后myapp-busybox-pod的Pod转移进入 Running 状态:
[root@k8s-master lifecycle]# kubectl get svc -o wide mydb myservice
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
mydb ClusterIP 10.108.24.84 <none> 80/TCP 72s <none>
myservice ClusterIP 10.105.252.196 <none> 80/TCP 72s <none>
[root@k8s-master lifecycle]#
[root@k8s-master lifecycle]# kubectl get pod myapp-busybox-pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-busybox-pod 1/1 Running 0 7m33s 10.244.4.17 k8s-node01 <none> <none>
由上可知:一旦我们启动了 mydb 和 myservice 这两个 Service,我们就能够看到 Init 容器完成,并且 myapp-busybox-pod 被创建。
进入myapp-busybox-pod容器,并通过nslookup查看这两个Service的DNS记录。
[root@k8s-master lifecycle]# kubectl exec -it myapp-busybox-pod sh
/ # nslookup mydb
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: mydb
Address 1: 10.108.24.84 mydb.default.svc.cluster.local
/ #
/ #
/ #
/ # nslookup myservice
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: myservice
Address 1: 10.105.252.196 myservice.default.svc.cluster.local
=========================================================================================
开启kube-proxy的ipvs的前置条件
模式改为lvs调度的方式,kube-proxy主要解决的是svc(service)与pod之间的调度关系,ipvs的调度方式可以极大的增加它的访问效率,所以这种方式现在是我们必备的一种。
1、 加载netfilter模块
modprobe br_netfilter
2、 编写一个引导文件,这个文件将会引导我们lvs的一些相关依赖的加载,注意这里的依赖并不是rpm包含,也是模块依赖。
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
3、赋予该文件755权限并执行该文件,然后使用lsmod命令查看这些文件是否被引导。
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
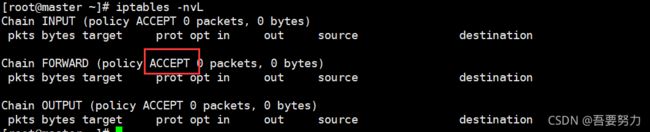
4、确认一下iptables filter表中FOWARD链的默认策略(pllicy)为ACCEPT
iptables -nvL
后面再补充
#如果不是ACCEPT,则修改
iptables -P FORWARD ACCEPT
kubectl edit configmap kube-proxy -n kube-system
mode修改为mode: "ipvs"
1.修改完毕mode: "ipvs"
2.执行重启操作
kubectl get pod -n kube-system | grep kube-proxy | awk '{system("kubectl delete pod "$1" -n kube-system")}'
3.查看日志中打印出了Using ipvs Proxier,说明ipvs模式已经开启。
kubectl get pod -n kube-system -o wide | grep kube-proxy
kubectl logs kube-proxy-8cwj4 -n kube-system
I0729 07:05:35.580934 1 server_others.go:170] Using ipvs Proxier.
W0729 07:05:35.585891 1 proxier.go:401] IPVS scheduler not specified, use rr by default
I0729 07:05:35.588572 1 server.go:534] Version: v1.15.1
I0729 07:05:35.642475 1 conntrack.go:52] Setting nf_conntrack_max to 131072
I0729 07:05:35.653344 1 config.go:96] Starting endpoints config controller
I0729 07:05:35.654584 1 controller_utils.go:1029] Waiting for caches to sync for endpoints config controller
I0729 07:05:35.654629 1 config.go:187] Starting service config controller
I0729 07:05:35.654649 1 controller_utils.go:1029] Waiting for caches to sync for service config controller
I0729 07:05:35.755738 1 controller_utils.go:1036] Caches are synced for endpoints config controller
I0729 07:05:35.755806 1 controller_utils.go:1036] Caches are synced for service config controller
看到pod如下信息表明成功
[root@k8s ~]# kubectl logs kube-proxy-72lg9 -n kube-system
I0530 03:38:11.455609 1 feature_gate.go:226] feature gates: &{{} map[]}
I0530 03:38:11.490470 1 server_others.go:183] Using ipvs Proxier.
W0530 03:38:11.503868 1 proxier.go:304] IPVS scheduler not specified, use rr by default
I0530 03:38:11.504109 1 server_others.go:209] Tearing down inactive rules.
I0530 03:38:11.552587 1 server.go:444] Version: v1.10.3

前提
~~前提需要内核版本大于2.10的,使用uname -r 查看版本号~~
1. 设置系统主机名以及 Host 文件的相互解析
hostnamectl set-hostname k8s-master01
vim /etc/hosts
eg:
172.21.0.10 master
172.21.0.14 node01
2. 安装依赖包
yum -y install wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake\
libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel\
wget vim ncurses-devel autoconf automake zlib-devel python-devel\
epel-release lrzsz openssh-server socat ipvsadm conntrack bind-utils\
libffi-devel zip ntpdate ipset jq sysstat libseccomp git yum-utils
3. 关闭 SELINUX;关闭swap;关闭防火墙与关闭自启动
setenforce 0 && \
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config && \
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/sysconfig/selinux
swapoff -a && sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
或
vi /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS=--fail-swap-on=false
systemctl stop firewalld && systemctl disable firewalld
4. 文件描述符的最大值限制,默认是1024
#echo "root soft nofile 65536" >> /etc/security/limits.conf
#echo "root hard nofile 65536" >> /etc/security/limits.conf
#echo "* soft nofile 65536" >> /etc/security/limits.conf
#echo "* hard nofile 65536" >> /etc/security/limits.conf
或者
[root@mobanji ~]# cat >> /etc/security/limits.d/kubectl.conf <
# End of file
* soft nofile
* hard nofile
* soft nproc
* hard nproc
EOF
echo "fs.file-max=655360" >> /etc/sysctl.conf
sysctl -p
echo "ulimit -n 65536" >> /etc/profile
source /etc/profile
5. 调整内核参数
cat > kubernetes.conf <<EOF
net.bridge.bridge-nf-call-iptables=1 #开启ipv4网桥模式
net.bridge.bridge-nf-call-ip6tables=1 #开启ipv6网桥模式
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0 # 禁止使用 swap 空间,只有当系统 OOM 时才允许使用它
vm.overcommit_memory=1 # 不检查物理内存是否够用
vm.panic_on_oom=0 # 开启 OOM
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
cp -fr kubernetes.conf /etc/sysctl.d/kubernetes.conf
sysctl -p /etc/sysctl.d/kubernetes.conf
6. 调整系统时区
# 设置系统时区为 中国/上海
timedatectl set-timezone Asia/Shanghai
# 将当前的 UTC 时间写入硬件时钟
timedatectl set-local-rtc 0
# 重启依赖于系统时间的服务
systemctl restart rsyslog && systemctl restart crond
7. 设置 rsyslogd 和 systemd journald
mkdir /var/log/journal # 持久化保存日志的目录
mkdir /etc/systemd/journald.conf.d
cat > /etc/systemd/journald.conf.d/99-prophet.conf <<EOF
[Journal]
# 持久化保存到磁盘
Storage=persistent
# 压缩历史日志
Compress=yes
SyncIntervalSec=5m
RateLimitInterval=30s
RateLimitBurst=1000
# 最大占用空间 10G
SystemMaxUse=10G
# 单日志文件最大 200M
SystemMaxFileSize=200M
# 日志保存时间 2 周
MaxRetentionSec=2week
# 不将日志转发到 syslog
ForwardToSyslog=no
EOF
systemctl restart systemd-journald
8.修改docker cgroup driver为systemd
根据文档CRI installation中的内容,对于使用systemd作为init system的Linux的发行版,使用systemd作为docker的cgroup driver可以确保服务器节点在资源紧张的情况更加稳定,因此这里修改各个节点上docker的cgroup driver为systemd。
创建或修改/etc/docker/daemon.json:
{
"registry-mirrors": ["http://f1361db2.m.daocloud.io"],#使用国内镜像
"exec-opts": ["native.cgroupdriver=systemd"], #cgroup driver为systemd
}
重启docker
systemctl restart docker
docker info|grep Cgroup
#9.提前下载镜像
#cat k8s-image-download.sh
##!/bin/bash
#if [ $# -ne 1 ];then
# echo "please user in: ./`basename $0` KUBERNETES-VERSION"
# exit 1
#fi
#version=$1
#images=`kubeadm config images list --kubernetes-version=${version} |awk -F'/' '{print $2}'`
#for imageName in ${images[@]};do
# docker pull gcr.azk8s.cn/google-containers/$imageName
# docker tag gcr.azk8s.cn/google-containers/$imageName k8s.gcr.io/$imageName
# docker rmi gcr.azk8s.cn/google-containers/$imageName
#done
#./k8s-image-download.sh 1.15.3
即将初始化
初步操作
1、通过如下指令创建默认的kubeadm-config.yaml文件
kubeadm config print init-defaults > kubeadm-config.yaml
kubeadm-config.yaml组成部署说明:
InitConfiguration: 用于定义一些初始化配置,如初始化使用的token以及apiserver地址等
ClusterConfiguration:用于定义apiserver、etcd、network、scheduler、controller-manager等master组件相关配置项
KubeletConfiguration:用于定义kubelet组件相关的配置项
KubeProxyConfiguration:用于定义kube-proxy组件相关的配置项
2、在默认的kubeadm-config.yaml文件中只有InitConfiguration、ClusterConfiguration 两部分。我们可以通过如下操作生成另外两部分的示例文件:
# 生成KubeletConfiguration示例文件
kubeadm config print init-defaults --component-configs KubeletConfiguration
# 生成KubeProxyConfiguration示例文件
kubeadm config print init-defaults --component-configs KubeProxyConfiguration
打发士大夫阿萨的沙发上东方大厦发 发大师傅士大夫 --------------------------可能需要修改鞥
备注:
下载镜像
[root@master1 ~]# vim images.txt
kube-apiserver:v1.18.8 # node节点不需要
kube-controller-manager:v1.18.8 # node节点不需要
kube-scheduler:v1.18.8 # node节点不需要
kube-proxy:v1.18.8
pause:3.2
etcd:3.4.3-0 # node节点不需要
coredns:1.6.7 # node节点不需要
[root@master1 ~]# vim images.sh
for image in `cat images.txt`
do
docker pull gotok8s/$image
docker tag gotok8s/$image k8s.gcr.io/$image
docker rmi gotok8s/$image
done
[root@master1 ~]# sh images.sh
关于kubeadm-config.yaml更多配置语法参考: https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta2
使用kubeadm-config.yaml配置主节点:https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/control-plane-flags/
kube-proxy开启ipvs参考: https://github.com/kubernetes/kubernetes/blob/master/pkg/proxy/ipvs/README.md
kubelet的配置示例参考: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/kubelet-integration/#configure-kubelets-using-kubeadm
初始化过程说明(不要忘记需要修改地方):
==========================================
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.28.131 #需要修改
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
imagePullPolicy: IfNotPresent
name: master1
taints: null #使用kubeadm默认配置初始化的集群,会在master节点打上node-role.kubernetes.io/master:NoSchedule的污点,阻止master节点接受调度运行工作负载。这里测试环境只有两个节点,所以将这个taint修改为node-role.kubernetes.io/master:PreferNoSchedule。
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers #需要修改
kind: ClusterConfiguration
kubernetesVersion: v1.22.1 #需要修改
networking:
dnsDomain: cluster.local
podSubnet: "10.244.0.0/16" #需要修改
serviceSubnet: 10.96.0.0/12
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
==========================================
kubeadm init --config /home/kubeadm.yaml --ignore-preflight-errors=Swap --ignore-preflight-errors=NumCPU
注释:避免swap和cpu报错,可以指定参数避免
[init]:指定版本进行初始化操作
[preflight] :初始化前的检查和下载所需要的Docker镜像文件。
[kubelet-start] :生成kubelet的配置文件”/var/lib/kubelet/config.yaml”,没有这个文件kubelet无法启动,所以初始化之前的kubelet实际上启动失败。
[certificates]:生成Kubernetes使用的证书,存放在/etc/kubernetes/pki目录中。
[kubeconfig] :生成 KubeConfig 文件,存放在/etc/kubernetes目录中,组件之间通信需要使用对应文件。
[control-plane]:使用/etc/kubernetes/manifest目录下的YAML文件,安装 Master 组件。
[etcd]:使用/etc/kubernetes/manifest/etcd.yaml安装Etcd服务。
[wait-control-plane]:等待control-plan部署的Master组件启动。
[apiclient]:检查Master组件服务状态。
[uploadconfig]:更新配置
[kubelet]:使用configMap配置kubelet。
[patchnode]:更新CNI信息到Node上,通过注释的方式记录。
[mark-control-plane]:为当前节点打标签,打了角色Master,和不可调度标签,这样默认就不会使用Master节点来运行Pod。
[bootstrap-token]:生成token记录下来,后边使用kubeadm join往集群中添加节点时会用到
[addons]:安装附加组件CoreDNS和kube-proxy
Kubernetes Master 初始化成功,提示如何配置常规用户使用kubectl访问集群。
提示如何安装 Pod 网络。
提示如何注册其他节点到 Cluster。
===============
初始化集群需使用kubeadm init命令,可以指定具体参数初始化,也可以指定配置文件初始化。
可选参数:
--apiserver-advertise-address apiserver的监听地址,有多块网卡时需要指定
--apiserver-bind-port apiserver的监听端口,默认是6443
--cert-dir 通讯的ssl证书文件,默认/etc/kubernetes/pki
--control-plane-endpoint 控制台平面的共享终端,可以是负载均衡的ip地址或者dns域名,高可用集群时需要添加
--image-repository 拉取镜像的镜像仓库,默认是k8s.gcr.io
--kubernetes-version 指定kubernetes版本
--pod-network-cidr pod资源的网段,需与pod网络插件的值设置一致
--service-cidr service资源的网段
--service-dns-domain service全域名的后缀,默认是cluster.local
初始化失败
集群初始化如果遇到问题,可以使用下面的命令进行清理:
kubeadm reset
ifconfig cni0 down
ip link delete cni0
ifconfig flannel.1 down
ip link delete flannel.1
rm -rf /var/lib/cni/
Kubernetes初始化失败处理.
Kubernetes网络之Calico(:官网https://www.projectcalico.org/)

故障:
Warning Unhealthy 4m36s kubelet Readiness probe failed: 2021-05-06 06:23:16.868 [INFO][135] confd/health.go 180: Number of node(s) with BGP peering established = 0
calico/node is not ready: BIRD is not ready: BGP not established with 172.21.130.168,172.28.17.85
Warning Unhealthy 4m26s kubelet Readiness probe failed: 2021-05-06 06:23:26.885 [INFO][174] confd/health.go 180: Number of node(s) with BGP peering established = 0
解决如下:
查看节点calico状态
calicoctl node status
修改calico的yaml文件,添加配置项
- name: IP_AUTODETECTION_METHOD
value: ""
IP_AUTODETECTION_METHOD 配置项默认为first-found,这种模式中calico会使用第一获取到的有效网卡,虽然会排除docker网络,localhost,但是在复杂网络环境下还是有出错的可能。在这次异常中master上的calico选择了一个非主网卡。
为了解决这种情况,IP_AUTODETECTION_METHOD还提供了两种配置can-reach=DESTINATION,interface=INTERFACE-REGEX。
can-reach=DESTINATION 配置可以理解为calico会从部署节点路由中获取到达目的ip或者域名的源ip地址。
interface=INTERFACE-REGEX 配置可以指定calico使用匹配的网卡上的第一个IP地址。列出网卡和IP地址的顺序取决于系统。匹配支持goalong的正则语法。
k8s中pod状态
CrashLoopBackOff: 容器退出,kubelet正在将它重启
InvalidImageName: 无法解析镜像名称
ImageInspectError: 无法校验镜像
ErrImageNeverPull: 策略禁止拉取镜像
ImagePullBackOff: 正在重试拉取
RegistryUnavailable: 连接不到镜像中心
ErrImagePull: 通用的拉取镜像出错
CreateContainerConfigError: 不能创建kubelet使用的容器配置
CreateContainerError: 创建容器失败
m.internalLifecycle.PreStartContainer 执行hook报错
RunContainerError: 启动容器失败
PostStartHookError: 执行hook报错
ContainersNotInitialized: 容器没有初始化完毕
ContainersNotReady: 容器没有准备完毕
ContainerCreating:容器创建中
PodInitializing:pod 初始化中
DockerDaemonNotReady:docker还没有完全启动
NetworkPluginNotReady: 网络插件还没有完全启动
Evicted:即驱赶的意思,意思是当节点出现异常时,kubernetes将有相应的机制驱赶该节点上的Pod。 多见于资源不足时导致的驱赶。
添加节点
Kubernetes集群中添加Node节点
[root@master ~]# kubeadm token create
tkxyys.8ilumwddiexjd8g2
[root@master ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
tkxyys.8ilumwddiexjd8g2 23h 2019-07-10T21:19:17+08:00 authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
获取ca证书sha256编码hash值
[root@master ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt|openssl rsa -pubin -outform der 2>/dev/null|openssl dgst -sha256 -hex|awk '{print $NF}'
2e4ec2c6267389ccc2aa293a61ab474b0304778d56dfb07f5105a709d3b798e6
添加node节点
kubeadm join 10.0.0.10:6443 --token 4qcl2f.gtl3h8e5kjltuo0r \
--discovery-token-ca-cert-hash sha256:7ed5404175cc0bf18dbfe53f19d4a35b1e3d40c19b10924275868ebf2a3bbe6e \
--ignore-preflight-errors=all
node01加入集群很是顺利,下面在master节点上执行命令查看集群中的节点:
[root@master ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master Ready master 18m v1.15.0
node01 <none> master 11m v1.15.0
节点没有ready 一般是由于flannel 插件没有装好,可以通过查看kube-system 的pod 验证
==移除Node节点==
如果需要从集群中移除node01这个Node执行下面的命令:
在master节点上执行,将节点变成不可调度状态SchedulingDisabled,再执行kubectl delete node node01 :
kubectl drain node01 --delete-local-data --force --ignore-daemonsets
在node01上执行:
kubeadm reset
ifconfig cni0 down
ip link delete cni0
ifconfig flannel.1 down
ip link delete flannel.1
rm -rf /var/lib/cni/
在master上执行:
kubectl delete node node01
证书过期
kubeadm alpha
注意:
kubeadm alpha 提供了一组可用于收集社区反馈的预览性质功能。 请试用这些功能并给我们提供反馈!
(类似于test命令一样)
1. 检查证书有效期
<1.4版本执行如下命令
openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -text |grep 'Not'
>1.4版本执行如下命令
kubeadm certs check-expiration
2. 备份过期证书
cp -rp /etc/kubernetes /etc/kubernetes.bak
cp -rp /root/.kube /root/.kube.bak
3.生成配置文件
kubectl config view --raw -o yaml >old.yaml
4. 在一台 master 上执行更新证书的操作
kubeadm alpha certs renew all --config=/tmp/cluster.yaml
5.重启服务
docker ps |grep -E 'k8s_kube-apiserver|k8s_kube-controller-manager|k8s_kube-scheduler|k8s_etcd_etcd' | awk -F ' ' '{print $1}' |xargs docker restart
省略号内暂时无需执行
··········································
重启etcd kube-apiserver kube-controller kube-scheduler 这4个容器(这几个都在主节点,重启不会影响业务的正常运行)
for i in etcd kube-apiserver kube-controller kube-scheduler;do
echo ….restart container $i….
docker ps |grep $i | grep -v pause | cut -d " " -f1 | xargs docker restart
done
重启 kubelet 服务(注:所有服务会重启,慎用!)
生产新的配置文件
kubeadm init phase kubeconfig all
··········································
6. 再次查看证书有效期
将证书同步到其他master主机上
查看状态
kubectl get no
rsync -Pav -e "ssh -p 22" /etc/kubernetes/pki/ root@<master-ip>:/etc/kubernetes/pki/
Kubernetes常用组件部署
3.1 Helm的安装
Helm由客户端命helm令行工具和服务端tiller组成,Helm的安装十分简单。 下载helm命令行工具到master节点node1的/usr/local/bin下,这里下载的2.14.1版本:
curl -O https://get.helm.sh/helm-v2.14.1-linux-amd64.tar.gz
tar -zxvf helm-v2.14.1-linux-amd64.tar.gz
cd linux-amd64/
cp helm /usr/local/bin/
为了安装服务端tiller,还需要在这台机器上配置好kubectl工具和kubeconfig文件,确保kubectl工具可以在这台机器上访问apiserver且正常使用。 这里的node1节点已经配置好了kubectl。
因为Kubernetes APIServer开启了RBAC访问控制,所以需要创建tiller使用的service account: tiller并分配合适的角色给它。 详细内容可以查看helm文档中的Role-based Access Control。 这里简单起见直接分配cluster-admin这个集群内置的ClusterRole给它。创建helm-rbac.yaml文件:
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system
kubectl create -f helm-rbac.yaml
接下来使用helm部署tiller:
helm init --service-account tiller --skip-refresh
tiller默认被部署在k8s集群中的kube-system这个namespace下:
kubectl get pod -n kube-system -l app=helm
helm version
注意由于某些原因需要网络可以访问gcr.io和kubernetes-charts.storage.googleapis.com,如果无法访问可以通过helm init –service-account tiller –tiller-image <your-docker-registry>/tiller:v2.13.1 –skip-refresh使用私有镜像仓库中的tiller镜像
最后在k8s-master上修改helm chart仓库的地址为azure提供的镜像地址:
helm repo add stable http://mirror.azure.cn/kubernetes/charts
helm repo list
===============
注:如果tiller的状态一直是ErrImagePull的时候,需要更换国内helm源。
NAME READY STATUS RESTARTS AGE
tiller-deploy-7bf78cdbf7-fkx2z 0/1 ImagePullBackOff 0 79s
解决方法1:
1、删除默认源
# helm repo remove stable
2、 增加新的国内镜像源
# helm repo add stable https://burdenbear.github.io/kube-charts-mirror/
或
# helm repo add stable https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
3、查看helm源情况
# helm repo list
4、搜索测试
# helm search mysql
解决方法2:
1、手动下载images
# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.14.1
2、查看tiller需要的镜像名
# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-bccdc95cf-tb6pf 1/1 Running 3 5h21m
coredns-bccdc95cf-xpgm8 1/1 Running 3 5h21m
etcd-master 1/1 Running 3 5h20m
kube-apiserver-master 1/1 Running 3 5h21m
kube-controller-manager-master 1/1 Running 3 5h21m
kube-flannel-ds-amd64-b4ksb 1/1 Running 3 5h18m
kube-flannel-ds-amd64-vmv29 1/1 Running 0 127m
kube-proxy-67zn6 1/1 Running 2 37m
kube-proxy-992ns 1/1 Running 0 37m
kube-scheduler-master 1/1 Running 3 5h21m
tiller-deploy-7bf78cdbf7-fkx2z 0/1 ImagePullBackOff 0 33m
3、使用describe查看镜像名
# kubectl describe pods tiller-deploy-7bf78cdbf7-fkx2z -n kube-system
Normal Scheduled 32m default-scheduler Successfully assigned kube-system/tiller-deploy-7bf78cdbf7-fkx2z to node1
Normal Pulling 30m (x4 over 32m) kubelet, node1 Pulling image “gcr.io/kubernetes-helm/tiller:v2.14.1”
Warning Failed 30m (x4 over 31m) kubelet, node1 Failed to pull image “gcr.io/kubernetes-helm/tiller:v2.14.1”: rpc error: code = Unknown desc = Error response from daemon: Get https://gcr.io/v2/: Service Unavailable
Warning Failed 30m (x4 over 31m) kubelet, node1 Error: ErrImagePull
Warning Failed 30m (x6 over 31m) kubelet, node1 Error: ImagePullBackOff
Normal BackOff 111s (x129 over 31m) kubelet, node1 Back-off pulling image “gcr.io/kubernetes-helm/tiller:v2.14.1”
4、使用docker tag 重命令镜像
# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.14.1 gcr.io/kubernetes-helm/tiller:v2.14.1
5、删除多余的镜像
# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.14.1
6、删除失败的pod
# kubectl delete deployment tiller-deploy -n kube-system
稍等一会儿就可以使用kubectl get pods -n kube-system查看状态已经正常了
注释
在node修改hel chart仓库的地址
# helm repo add stable http://mirror.azure.cn/kubernetes/charts
"stable" has been added to your repositories
# helm repo list
NAME URL
stable http://mirror.azure.cn/kubernetes/charts
local http://127.0.0.1:8879/charts
===============
3.2 使用Helm部署Nginx Ingress
为了便于将集群中的服务暴露到集群外部,需要使用Ingress。接下来使用Helm将Nginx Ingress部署到Kubernetes上。 Nginx Ingress Controller被部署在Kubernetes的边缘节点上,关于Kubernetes边缘节点的高可用相关的内容可以查看之前整理的Bare metal环境下Kubernetes Ingress边缘节点的高可用,Ingress Controller使用hostNetwork。
我们将k8s-node(192.168.100.11)做为边缘节点,打上Label:
kubectl label node k8s-master node-role.kubernetes.io/edge=
#kubectl label node k8s-master node-role.kubernetes.io/edge- #减号表示删除
kubectl get node
stable/nginx-ingress chart的值文件ingress-nginx.yaml如下:
controller:
replicaCount: 1
hostNetwork: true
nodeSelector:
node-role.kubernetes.io/edge: ''
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx-ingress
- key: component
operator: In
values:
- controller
topologyKey: kubernetes.io/hostname
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: PreferNoSchedule
defaultBackend:
nodeSelector:
node-role.kubernetes.io/edge: ''
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: PreferNoSchedule
nginx ingress controller的副本数replicaCount为1,将被调度到node1这个边缘节点上。这里并没有指定nginx ingress controller service的externalIPs,而是通过hostNetwork: true设置nginx ingress controller使用宿主机网络。
helm repo update
helm install stable/nginx-ingress -n nginx-ingress --namespace ingress-nginx -f ingress-nginx.yaml
kubectl get pod -n ingress-nginx -o wide
如果访问http://192.168.100.11返回default backend,则部署完成。
3.3 使用Helm部署dashboard
image:
repository: k8s.gcr.io/kubernetes-dashboard-amd64
tag: v1.10.1
ingress:
enabled: true
hosts:
- k8s.frognew.com
annotations:
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
tls:
- secretName: frognew-com-tls-secret
hosts:
- k8s.frognew.com
nodeSelector:
node-role.kubernetes.io/edge: ''
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: PreferNoSchedule
rbac:
clusterAdminRole: true
helm install stable/kubernetes-dashboard -n kubernetes-dashboard --namespace kube-system -f kubernetes-dashboard.yaml
kubectl -n kube-system get secret | grep kubernetes-dashboard-token
kubectl describe -n kube-system secret/kubernetes-dashboard-token-xxx
[root@master ~]# kubectl create serviceaccount dashboard-admin -n kube-system
#创建一个dashboard的管理用户
[root@master ~]# kubectl create clusterrolebinding dashboard-cluster-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
#将创建的dashboard用户绑定为管理用户
[root@master ~]# kubectl get secrets -n kube-system | grep dashboard
#获取刚刚创建的用户对应的token名称
dashboard-admin-token-88gxw kubernetes.io/service-account-token 3 22s
[root@master ~]# kubectl describe secrets -n kube-system dashboard-admin-token-88gxw
#查看token的详细信息
[root@master ~]# kubectl get secrets -n kube-system | grep dashboard
#查看刚才创建的token
dashboard-admin-token-88gxw kubernetes.io/service-account-token 3 22m
[root@master ~]# kubectl describe secrets -n kube-system dashboard-admin-token-88gxw
#查看token的详细信息,会获取token
[root@master ~]# DASH_TOKEN=$(kubectl get secrets -n kube-system dashboard-admin-token-88gxw -o jsonpath={.data.token} | base64 -d)
#将token的信息生成一个变量
[root@master ~]# kubectl config set-cluster kubernets --server=192.168.100.11:6443 --kubeconfig=/root/dashboard.conf
#将k8s集群的配置信息写入到一个文件中,文件可自定义
[root@master ~]# kubectl config set-credentials dashboard-admin --token=${DASH_TOKEN} --kubeconfig=/root/dashboard.conf
#将token的信息也写入到文件中(同一个文件)
[root@master ~]# kubectl config set-context dashboard-admin@kubernetes --cluster=kubernetes --user=dashboard-admin --kubeconfig=/root/dashboard.conf
#将用户信息也写入文件中(同一个文件)
[root@master ~]# kubectl config use-context dashboard-admin@kubernetes --kubeconfig=/root/dashboard.conf
#将上下文的配置信息也写入文件中(同一个文件)
[root@master ~]# sz /root/dashboard.conf
#最后将配置信息导入到客户端本地
3.4 使用Helm部署metrics-server
从Heapster的github https://github.com/kubernetes/heapster中可以看到已经,heapster已经DEPRECATED。 这里是heapster的deprecation timeline。 可以看出heapster从Kubernetes 1.12开始从Kubernetes各种安装脚本中移除。
Kubernetes推荐使用metrics-server。我们这里也使用helm来部署metrics-server。
metrics-server.yaml:
args:
- --logtostderr
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
nodeSelector:
node-role.kubernetes.io/edge: ''
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: PreferNoSchedule
helm install stable/metrics-server -n metrics-server --namespace kube-system -f metrics-server.yaml
使用下面的命令可以获取到关于集群节点基本的指标信息:
kubectl top node
kubectl top pod -n kube-system
遗憾的是,当前Kubernetes Dashboard还不支持metrics-server。因此如果使用metrics-server替代了heapster,将无法在dashboard中以图形展示Pod的内存和CPU情况(实际上这也不是很重要,当前我们是在Prometheus和Grafana中定制的Kubernetes集群中各个Pod的监控,因此在dashboard中查看Pod内存和CPU也不是很重要)。 Dashboard的github上有很多这方面的讨论,如https://github.com/kubernetes/dashboard/issues/2986,Dashboard已经准备在将来的某个时间点支持metrics-server。但由于metrics-server和metrics pipeline肯定是Kubernetes在monitor方面未来的方向,所以推荐使用metrics-server。
安装Kuboard
如果您已经有了 Kubernetes 集群,只需要一行命令即可安装 Kuboard: kubectl apply -f https://kuboard.cn/install-script/kuboard.yaml
功能
快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
查找:Ctrl/Command + F
替换:Ctrl/Command + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
~~删除
- List item
文本~~
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片: 
带尺寸的图片:
居中的图片: 
居中并且带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block
var foo = 'bar';
生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
创建一个自定义列表
-
Markdown
- Text-to- HTML conversion tool Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。1
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图:
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
注脚的解释 ↩︎