字节跳动多篇论文入选 CVPR 2021,精选干货都在这里了
CVPR 2021,近期刚刚落下帷幕。
作为计算机视觉领域三大顶级学术会议之一,CVPR每年都吸引了各大高校、科研机构与科技公司的论文投稿,许多重要的计算机视觉技术成果都在CVPR上中选发布。
今天,为大家精选了14篇字节跳动技术团队入选本届CVPR的论文,其中包含2篇Oral(口头演讲论文),分享其中的核心突破,学习计算机视觉领域的最前沿研究。
除此之外,在本届CVPR的各个比赛环节,字节跳动技术团队荣获4项比赛冠军。
接下来,我们就来一起读paper啦。
HR-NAS:使用轻量级Transformer的高效搜索高分辨率神经架构
HR-NAS: Searching Efficient High-Resolution Neural Architectures with Lightweight Transformers
本文由字节跳动与香港大学、中国人民大学高瓴人工智能学院合作完成,是本届CVPR的Oral论文之一。
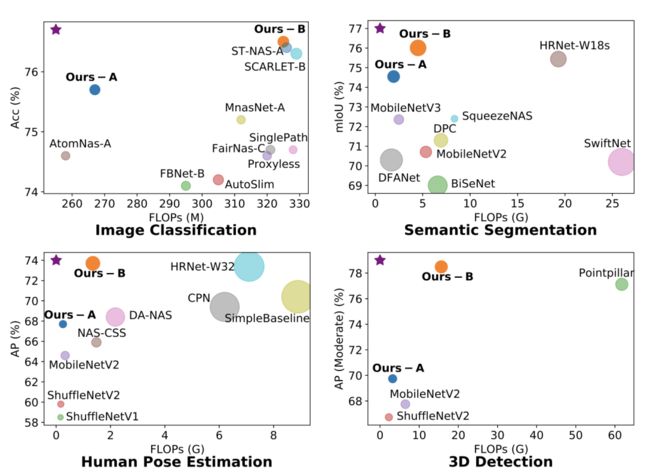
文中提出了一种适用于包括分类、分割、检测在内的各种视觉感知任务的统一的supernet和在其之上的模型结构搜索和压缩方法,提出了一个统一的框架用于解决不同视觉感知任务对不同结果的需求。
论文作者更新了NAS搜索空间及搜索策略,设计了轻量级的Transformer,其计算复杂性可以随着不同的目标函数和计算预算动态变化。为了维持学习网络的高分辨率表示,HR-NAS采用多分支架构提供多个特征分辨率的卷积编码。作者还提出了一种更有效的搜索策略来训练HR-NAS以有效探索搜索空间,在特定任务和计算资源下找到最佳架构。
论文链接:
https://openaccess.thecvf.com/content/CVPR2021/papers/Ding_HR-NAS_Searching_Efficient_High-Resolution_Neural_Architectures_With_Lightweight_Transformers_CVPR_2021_paper.pdf
代码链接:
https://github.com/dingmyu/HR-NAS
用于自监督视觉预训练的密集对比学习
Dense Contrastive Learning for Self-Supervised Visual Pre-Training
本文由字节跳动与阿德莱德大学、同济大学合作完成,是本届CVPR的一篇Oral论文。
这项研究可以实现不需要昂贵的密集人工标签,就能在下游密集预测任务上实现出色的预训练性能。
研究团队提出的新方法 DenseCL(Dense Contrastive Learning)通过考虑局部特征之间的对应关系,直接在输入图像的两个视图之间的像素(或区域)特征上优化成对的对比(不相似)损失来实现密集自监督学习。
现有的自监督框架将同一张图像的不同数据增强作为一对正样本,利用剩余图像的数据增强作为其负样本,构建正负样本对实现全局对比学习,这往往会忽略局部特征的联系性与差异性。
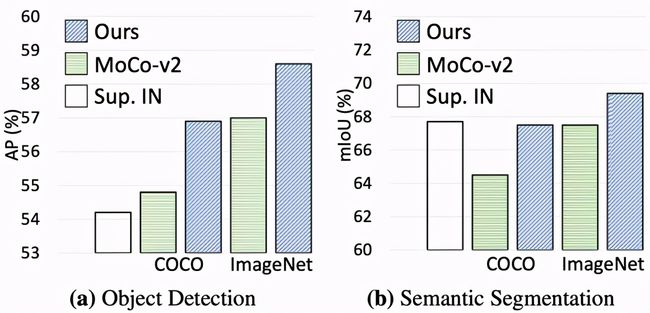
该研究提出的方法在此基础上,将同一张图像中最为相似的两个像素(区域)特征作为一对正样本,而将余下所有的像素(区域)特征作为其负样本实现密集对比学习。去掉了已有的自监督学习框架中的全局池化层,并将其全局映射层替换为密集映射层实现。在匹配策略的选择上,研究者比较了最大相似匹配和随机相似匹配对最后的精度的影响。与基准方法 MoCo-v2相比,DenseCL 引入了可忽略的计算开销(仅慢了不到 1%),但在迁移至下游密集任务(如目标检测、语义分割)时,表现出了十分优异的性能。
该方法迁移至下游密集任务的性能增益:
论文链接:
https://arxiv.org/abs/2011.09157
代码链接:
https://github.com/WXinlong/DenseCL
用于视频修复的渐进式时间特征对齐网络
Progressive Temporal Feature Alignment Network for Video Inpainting
本文由字节跳动与加利福尼亚大学戴维斯分校合作完成。
论文作者提出了一种新的视频补全算法,综合了之前的基于光流和基于3D卷积神经网络的方法,提出了特征对齐的3D卷积方法,名为「渐进式时间特征对齐网络」,使用光流从相邻帧的特征来逐步丰富当前帧的特征,该方法在时间特征传播阶段纠正了空间错位,大幅提升了生成视频的精度和视觉效果。
目前,这种新的方法在DAVIS和FVI两大数据集上达到了学界最佳的效果。
这项技术可以应用在视频编辑类App中,当用户在视频中P掉某些部分时,可以自动生成更好的补全效果。

论文链接:
https://arxiv.org/abs/2104.03507
代码链接:
https://github.com/MaureenZOU/TSAM
人物去遮挡:人物遮挡感知与恢复
Human De-occlusion: Invisible Perception and Recovery for Humans
本文由字节跳动与华中科技大学电子信息与通信学院合作完成。
针对图像中人物部分被其他物体遮挡的问题,论文作者提出了一个两阶段框架来估计人像不可见的部分,并恢复其中的内容。
首先是蒙版补全阶段,借助示例分割模型,作者设计了一个堆叠网络结构,来完善整个蒙版;之后在蒙版内进行内容恢复,用到了一种新的解析引导注意力模型,来区分身体的不同部分,补充更多信息。
这项技术可以应用在人物图像编辑过程中,实现人像合照顺序替换、修补等功能。

此外,在人物去遮挡这项任务上,作者贡献了Amodal人类感知(AHP)数据集,数据集标注了每张图片的场景,并且有丰富的人物数量。本文提出的方法也在AHP数据集上获得了当前学术界最佳的效果。
论文链接:
https://arxiv.org/abs/2103.11597
数据集:
https://sydney0zq.github.io/ahp/
先定位再分割:一种用于指代性图像分割的高性能基准方法
Locate then Segment: A Strong Pipeline for Referring Image Segmentation
本文由字节跳动与中科院自动化所合作完成。
指代性物体分割(Referring Image Segmentation),通过自然语言定位并分割出场景中的目标物体,比如语言指示「分割出穿白色衬衫的人」,系统就自动完整这项任务。
这项研究采用先定位再分割的方案(LTS,Locate then Segment),将指代性图像分割任务分解为两个子序列任务:
定位模块:被指代对象的位置预测,通过位置建模可以显式获取语言所指代的对象;
分割模块:对象分割结果的生成,后续的分割网络可以根据视觉环境信息来得到准确的轮廓。
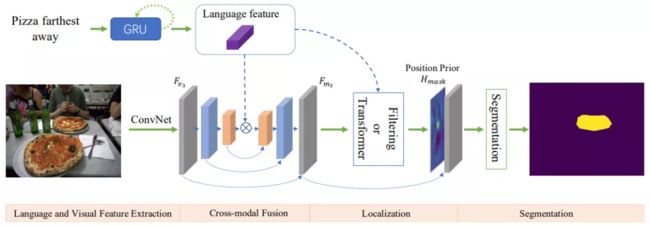
其中定位模块旨在找到语言表达所指代的视觉区域。首先基于语言描述生成卷积核,然后使用该卷积核对提取到的多模态特征进行过滤来得到位置信息,其中被指代对象所在区域的响应得分应该高于无关的视觉区域,这也是一个粗略的分割结果。
为了得到精细的分割结果,分割模块将原始的多模态特征和位置先验进行拼接,然后利用一个分割网络去细化粗分割结果,它的主要结构是 ASPP,通过使用多个采样率在多个尺度上捕获对象周围的信息。为了获得更精确的分割结果,本文采用反卷积的方式对特征图进行上采样。
该研究提出的方法比之前性能最好的方法 CGAN 性能更高,尤其在 RefCOCO + 和 RefCOCOg 上可以提高大约 3%IoU。
论文链接:
https://arxiv.org/abs/2103.16284
针对目标检测的多尺度自动数据增强方法
Scale-aware Automatic Augmentation for Object Detection
本文由字节跳动与香港中文大学合作完成。
这篇论文提出了一种针对目标检测尺度变化问题的自动化数据增强方法,研究团队设计了一种新的搜索空间和一种搜索过程中的估计指标(Pareto Scale Balance)。
这种新方法仅花费了8块GPUs,2.5天的时间即可完成,搜索效率相对提升40倍。搜索得到的数据增强策略在各类检测器和不同数据集上都能带来较大的性能提升,并超越了传统方法。
此外,搜索得到的策略存在着一定的规律,这些规律或许能为以后人工数据增强设计提供一些帮助。

论文链接:
https://arxiv.org/abs/2103.17220
代码链接:
https://github.com/Jia-Research-Lab/SA-AutoAug
即插即用,更高效:一种基于混合注意力机制的动作识别的ACTION模块
ACTION-Net: Multipath Excitation for Action Recognition
本文由字节跳动与都柏林圣三一大学合作完成。
这项研究主要关注3D卷积的深度神经网络完成视频动作识别任务,主要侧重于时序动作识别比如人机交互与VR/AR中的手势识别。
和传统的动作识别相比如Kinetics(注重视频分类),此类应用场景主要有两种区别:
1. 一般部署在边缘设备上如手机,VR/AR设备上。所以对模型计算量和推理速度有一定的要求;
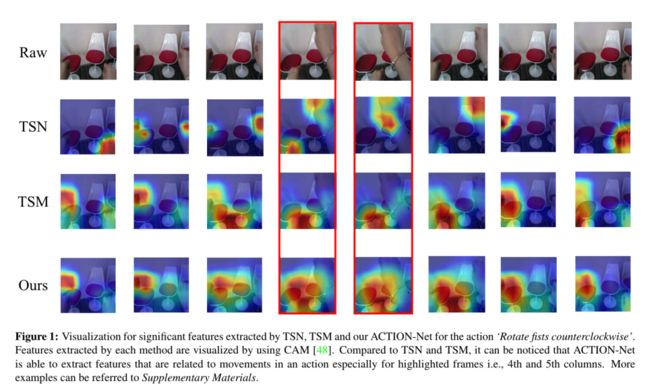
2. 此类动作("Rotate fists counterclockwise" vs "Rotate fists clockwise")和传统动作识别动作("Walking" vs "Running")相比有着较强时序性。针对以上的两点,我们基于2D CNN(轻便)提出了一个混合注意力机制的ACTION模块(对于时序动作建模)。
主要贡献点:
1.对于时序动作识别(比如手势)提出了一个混合注意力机制的ACTION模块,该模块兼顾时序动作里面三个重要的信息: (a) 时空信息即动作在时间和空间上的关系; (b) 动作的时序信息在不同信道间的一个权重;(c) 每相邻两帧之间动作的变化轨迹。
2.该模块和经典TSM模块一样,即插即用。基于2D CNN,非常轻便。我们在文章中展示了ACTION模块在三个不同backbone: ResNet-50,MobileNet V2和BNInception相比于TSM带来的效果提升和额外增加计算量。在三个时序动作数据集即Something-to-Something V2,Jester和EgoGesture上都测试了ACTION模块的实用性。
论文链接:
https://arxiv.org/pdf/2103.07372.pdf
代码链接:
https://github.com/V-Sense/ACTION-Net
以非迭代和增量学习的方法进行超像素分割
Learning the Superpixel in a Non-iterative and Lifelong Manner
本文由字节跳动与北京大学、北京邮电大学合作完成。
超像素分割旨在将图像高效的分割为远超于目标个数的超像素块,达到尽可能保留图像中所有目标的边缘信息的目的。然而,当前基于CNN的超像素分割方法,在训练过程中依赖于语义分割标注,从而导致生成的超像素通常包含很多冗余的高层语义信息,因此不仅限制了超像素分割方法的泛化性、灵活性、也制约了其在缺乏分割标注的视觉任务中的应用前景,如目标跟踪、弱监督图像分割等。
为解决这一问题,本文从持续学习的视角看待超像素分割问题,并提出了一种新型的超像素分割模型可以更好的支持无监督的在线训练模式。
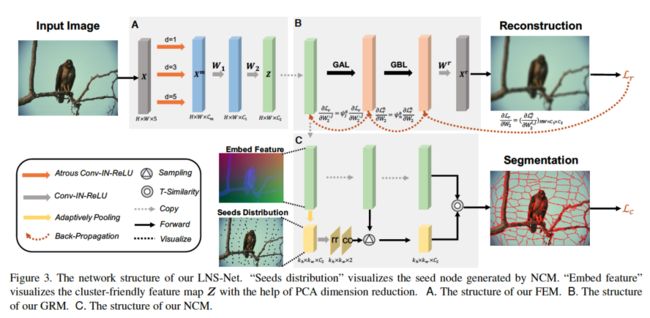
考虑到超像素分割作为广义分割问题需要更关注图像的细节信息,本模型摒弃了其他超像素分割网络中采用的较深而复杂的卷积神经网络结构,而选用了较为轻量级的特征提取模块(FEM),并提出了非迭代聚类模块(NCM)通过自动选取种子节点,避免了超像素分割方法中的聚类中心的迭代更新,极大地降低了超像素分割的空间复杂度与时间复杂度。
最后,为解决在线学习所带来的灾难性遗忘问题,本模型采用了梯度调节模块(GRM),通过训练权重在特征重建时的作用效果及像素的空间位置先验,调节反向传播时各权重的梯度,以增强模型的记忆性及泛化性。
论文链接:
https://arxiv.org/abs/2103.10681
代码链接:
https://github.com/zh460045050/LNSNet
Involution:反转卷积的固有性质以进行视觉识别
Involution: Inverting the Inherence of Convolution for Visual Recognition
本文由字节跳动与香港科技大学、北京大学合作完成。
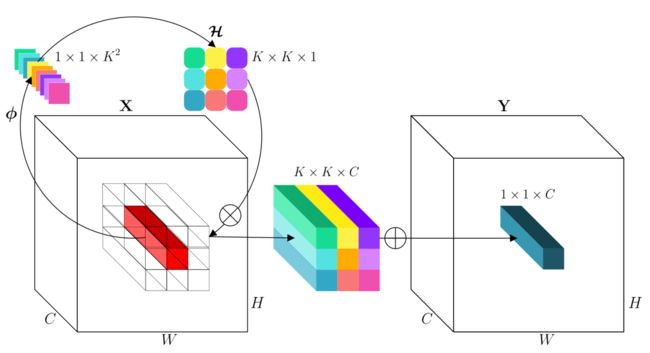
本文重新思考了卷积核在空间和通道维度的固有特性,即空间不变性和通道特异性。
论文作者通过反转以上的两个设计准则,提出了一种新颖的神经网络算子,称为Involution,并将最近应用广泛的自注意力操作作为一种复杂的特例归入了involution的范畴。Involution算子可以替代普通卷积来搭建新一代的视觉神经网络,在不同的视觉任务中支持多种多样的深度学习模型,包括ImageNet图像分类,COCO目标检测和实例分割,Cityscapes语义分割。
基于Involution的深度神经网络相较于卷积神经网络模型,在上述任务中显著减少计算代价的同时能够提高识别性能。
论文链接:
https://arxiv.org/abs/2103.06255
代码链接:
https://github.com/d-li14/involution
一种针对视觉-语义嵌入的自动学习最佳池化策略
Learning the Best Pooling Strategy for Visual Semantic Embedding
本文由字节跳动与南加州大学合作完成。

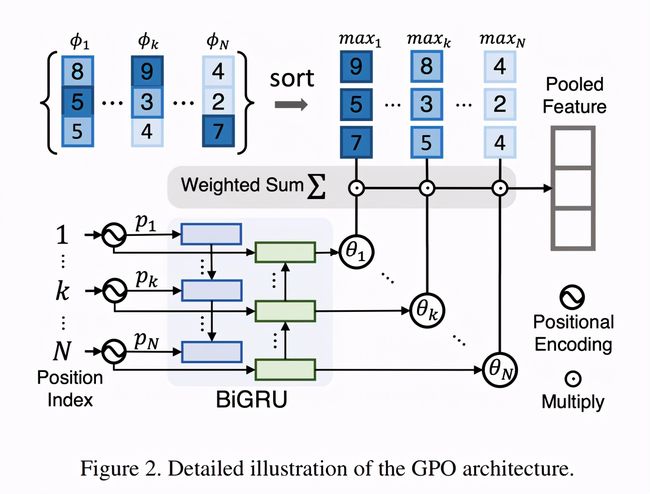
本文针对视觉-语义跨模态匹配问题,提出了一种通用的池化策略。
视觉-语义嵌入(Visual Semantic Embedding)学习是视觉-文本检索的一个常用方法,通过将视觉与文本模态对应的嵌入映射到同一个空间,使得匹配的视觉与文本的嵌入是相近的。
论文作者发现对单个模态的集合嵌入(如图片的grid-level特征、文本的token-level特征、视频的frame-level特征)聚合成全局嵌入的池化方式对模型效果有着很大的影响,提出了一种简单且通用的池化模块Generalized Pooling Operator(GPO),用于对任意模态的集合嵌入聚合为一个全局嵌入。GPO模块可以自适应地学习出每个模态最优的池化策略,从而免除复杂的组合尝试。
论文链接:
https://arxiv.org/abs/2011.04305
代码链接:
https://vse-infty.github.io
DeepI2P:基于深度学习的点云-图像配准
DeepI2P: Image-to-Point cloud registration via deep classification
本文由字节跳动与新加坡国立大学合作完成。
本文提出了全新的方法来实现跨模态点云-图像配准。给定在同一个地点附近拍摄的RGB图片,以及激光雷达扫描的三维点云,可以通过DeepI2P估算相机与激光雷达的相对位置,即旋转矩阵和平移向量。
以往的跨模态匹配工作中常见的方法是学习点云、图像的描述子。但是学习和匹配这两个模态的描述子是非常困难的,因为点云、图像的几何、纹理特征差异非常大。
DeepI2P巧妙地绕过了困难的跨模态描述子学习,而将跨模态配准问题转化为一个分类问题加一个“逆投影”问题。通过一个分类网络,能够将三维点云中的每一个点分类为落在相机平面之内或之外。这些经过标记的点可以通过文中提出的“逆投影”优化器求解出相机和激光雷达的相对位置。
DeepI2P算法已经在KITTI和Oxford RobotCar数据集上验证了有效性。

论文链接:
https://arxiv.org/abs/2104.03501
代码链接:
https://github.com/lijx10/DeepI2P
Sparse R-CNN:基于可学习候选框的端到端稀疏目标检测器
Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
本文由字节跳动与香港大学、同济大学、加利福尼亚大学伯克利分校合作完成。
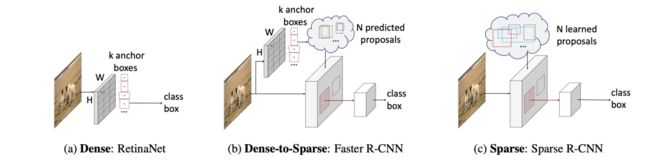
传统的目标检测器主要可以分为两类:
第一大类是从非深度学习时代以来就被广泛应用的密集检测器(dense detector),例如DPM,YOLO,RetinaNet。在密集检测器上,大量的候选物体例如锚点框以及参考点等被提前预设在图像网格或者特征图网格上,然后直接预测这些候选框到真实值的偏离量和物体类别。
第二大类是密集到稀疏的检测器(dense-to-sparse detector),例如,Faster R-CNN系列。这类方法的特点是对一组稀疏的候选框预测回归和分类,而这组稀疏的候选框来自于密集检测器。
沿着目标检测领域中Dense和Dense-to-Sparse的框架,Sparse R-CNN建立了一种彻底的稀疏目标检测框架, 脱离了锚点框、参考点等概念,无需非极大值抑制(NMS)后处理, 在标准的COCO benchmark上达到了当前最好的的性能。
论文链接:
https://arxiv.org/pdf/2011.12450.pdf
代码链接:
https://github.com/PeizeSun/SparseR-CNN
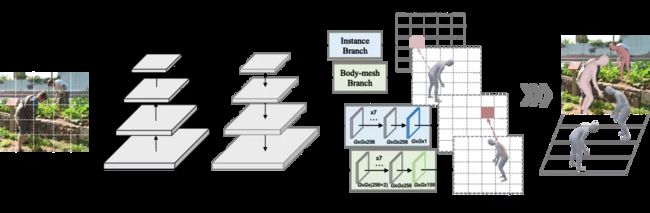
单阶段的人体网格估计模型
Body Meshes as Points
本文由字节跳动与新加坡国立大学合作完成。
现有的人体网格估计算法大多是基于两阶段的,第一阶段用于人物定位,第二阶段用于身体网格估计,这种冗余的计算框架导致了较高计算成本以及在复杂场景下性能不佳。
在这项工作中,研究团队首次提出了单阶段的人体网格估计模型 (BMP),用来简化计算框架并提升效率和性能。具体而言,本文将多个人物实例表示为2D平面和1D深度空间中的点,其中每个点与一个身体网格相关联。BMP 可以同时定位人物实例点和估计相应的身体网格,从而达到在单个阶段直接预测多个人物的身体网格。为了更好地推理同一场景中所有人物的深度排序,BMP 设计了一个简单而有效的实例间序数深度损失以获得深度连贯的多人身体网格估计。BMP 还引入了一种新颖的基于关键点的数据增强技术来增强模型对被遮挡和部分可见人物实例的鲁棒性。
这项成果在Panoptic、MuPoTS-3D 和 3DPW 等数据集上取得了最先进性能。
论文链接:
https://arxiv.org/pdf/2105.02467.pdf
代码链接:
https://github.com/jfzhang95/BMP
学习视频去雾:一个真实世界数据集与一种新方法
Learning to Restore Hazy Video: A New Real-World Dataset and A New Method
本文由字节跳动与腾讯优图实验室、西安交通大学、南京理工大学合作完成。
这篇论文基于可重复定位机械臂设计出一种全新的视频数据集采集系统,在有雾和无雾的情况下分别拍摄同一场景的图片,来获取完全真实的数据集(REal-world VIdeoDEhazing, REVIDE),可以用来使用监督学习方法训练去雾模型。
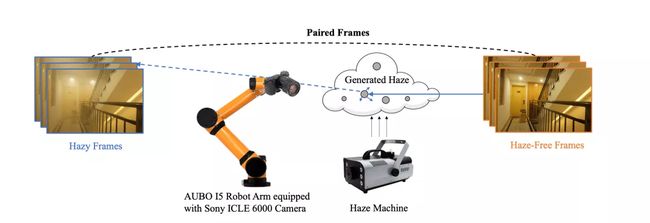

该数据集比合成数据更逼真,能够训练出更优秀的去雾算法。
论文链接:
https://openaccess.thecvf.com/content/CVPR2021/papers/Zhang_Learning_To_Restore_Hazy_Video_A_New_Real-World_Dataset_and_CVPR_2021_paper.pdf
数据集:
http://xinyizhang.tech/revide/

4项CVPR竞赛冠军
除了发表论文之外,在本届CVPR的各项比赛环节,字节跳动技术团队同样拿下了优异成绩。
在CVPR Mobile AI Workshop实时移动端检测场景竞赛中,字节跳动ByteScene团队以163.08分的绝对优势夺得冠军。
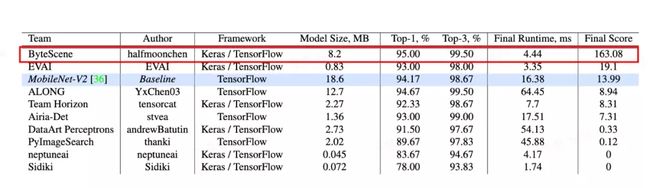
该比赛要求在移动端硬件上对摄像头输入的图像实时地做出判断,预测当前的场景是包含画像、海滩、天空、猫、狗等30个类别中的哪一类,此类算法能够帮助视频创作者更方便的剪辑,更智能的帮创作者匹配模版素材。
CVPR细粒度视觉分类挑战赛中,字节跳动两支团队包揽了冠亚军。
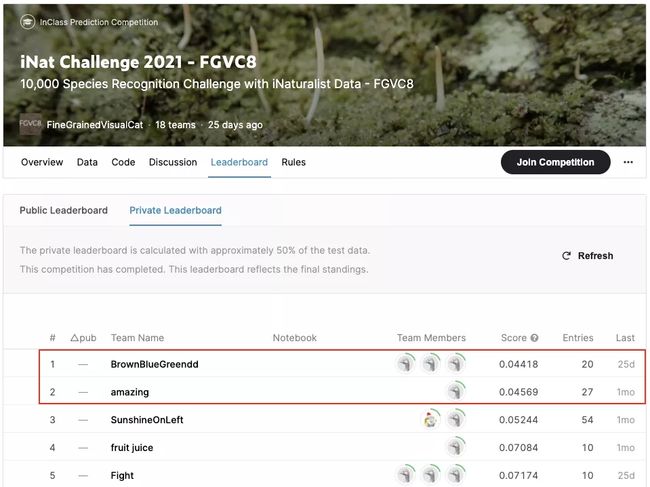
该比赛要求识别高达10000种不同的动植物,相似的物种之间差别非常小,并且不能受到背景图案的干扰。这类算法可以用于各种物品识别场景。
而在半监督细粒度视觉分类挑战赛中,字节跳动团队同样拿下了第一名。
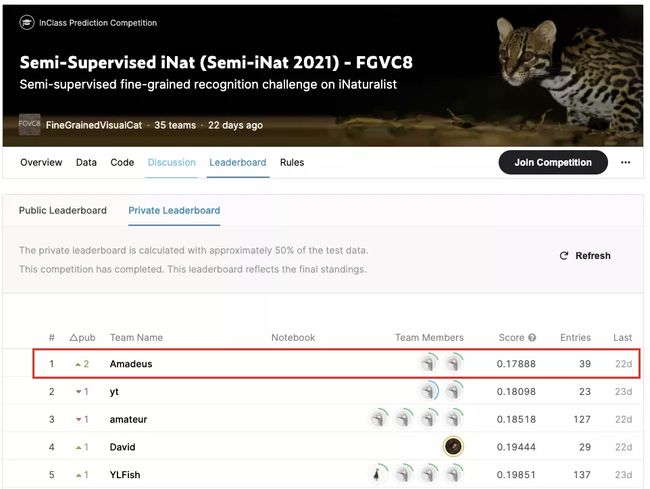
和上面的比赛不同的是,该比赛的重点是半监督学习,也就是无需提前给训练集做大量标注,即可实现视觉分类模型的训练。
Kinetics-700视频分类比赛监督学习赛道中,字节跳动与CMU(卡耐基梅隆大学)合作的团队拿下了第一名。
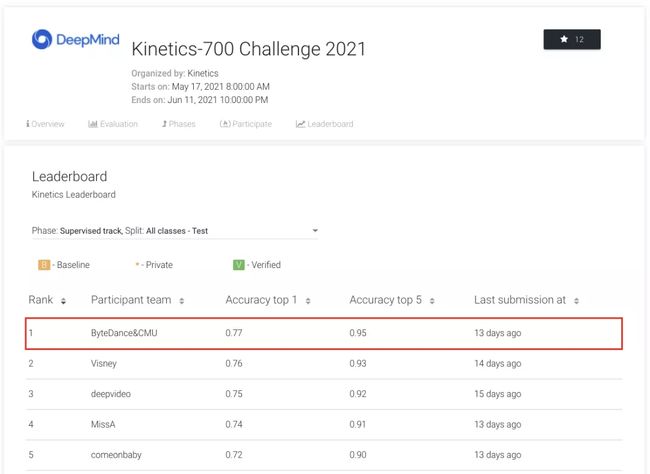
Kinetics-700是一个视频数据集,包含大约65万个视频片段,展示了700种不同的人体动作,参赛者需要训练模型来为不同的视频进行动作分类。

论文课题从哪儿来?业务出发&前瞻判断
看到这么多成果,那么在字节跳动真实的业务中,这些成果究竟是如何落地的?字节跳动的研究员们,又是如何在真实的业务需求中,创造出这些领先成果的呢?
一位研发Leader介绍,在公司内,研发同学有足够自由的决策权力,能够自下而上的推动研究自己感兴趣的技术,在支持业务的同时可以提炼自己的创新想法,自驱推动研究,成为学术成果。另外,公司提供了丰富的训练资源来,不仅支持业务,也支持科研。
这些学术研究的成果,也被用在了真实的业务上。
比如说,计算机视觉技术被广泛应用在解决内容安全、视频理解、视频版权等各种问题上。“而实际业务中线上数据分布在持续变化,我们需要确保机器学习模型在适配线上数据分布变化的同时,也能充分利用已经学到的海量的知识,这在学术界是一个持续学习(continual learning)的问题,它既是一个业务问题,也是学术界重要的课题。我们会在这些问题上做深入探索,不仅能解决学术问题和业务难题,也要考虑在具体业务落地中如何节省计算资源、降低模型运维成本。”
“再比如,在机器人视觉感知中,机器人物体检测是一个非常重要的内容,如何提升精度、如何在保证精度的情况下提升计算效率,两者都是重要的目标,这会迫使我们做很多尝试和探索。”
此外,相关的计算机视觉研究成果也被用在了剪映、西瓜视频等各类产品中,帮助创作者更便捷的完成视频创作和编辑。
在解决这些业务问题的过程中,当研发团队会做出新的突破,深入研究,甚至会做到世界领先水平,就可以做为科研成果来分享给学术界。
除了业务驱动的研发课题之外,字节跳动研发团队也会做技术前瞻的判断,在业务尚未发展到有相关技术需求的时候,就做充足的技术研发和储备,以应对未来的技术需求和挑战。