【CTR】《Towards Universal Sequence Representation Learning for Recommender Systems》 (KDD‘22)
《Towards Universal Sequence Representation Learning for Recommender Systems》 (KDD‘22)
序列推荐是根据用户点击过的item序列,学习出一个序列表征,然后根据表征预测下一个item,建模表征的模型有 RNN、CNN、GNN、Transformer、MLP等。
现有方法依赖于显式的商品ID建模,存在迁移性差和冷启动的问题(即使各个推荐场景的数据格式是完全相同的)。文章受预训练语言模型的启发,希望能设计一种针对序列推荐的序列表示学习的方法。
核心思想是利用:与商品相关的文本(如商品描述、标题、品牌等)来学习可跨域迁移的商品表示和序列表示。(模型可以在同一APP新的场景上快速适配、新APP上快速适配)。
核心技术主要靠MoE和动态路由。
解决的两个问题:1、需要将文本的语义空间适配到推荐任务中。2、跨domain的数据可能会冲突,导致跷跷板现象。
UnisRec模型
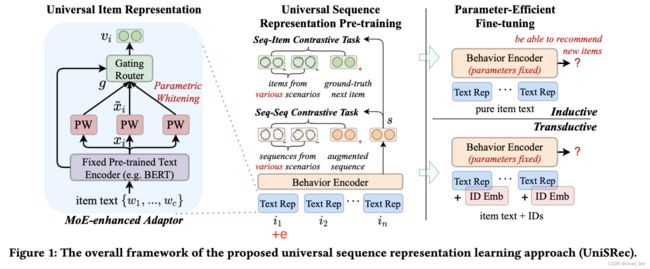
输入
用户点击过的item按照时间顺序排列 s = { i 1 , i 2 , … , i n } s=\left\{i_{1}, i_{2}, \ldots, i_{n}\right\} s={i1,i2,…,in},其中每个商品 i 都对应着一个id和一段描述性文本(如商品描述、标题或品牌)。商品i的描述文本可以形式化为 t i = { w 1 , w 2 , … , w c } t_{i}=\left\{w_{1}, w_{2}, \ldots, w_{c}\right\} ti={w1,w2,…,wc},其中 w j w_j wj 是共享的词表, c表示商品文本的最长长度(截断)。
- 这里的商品序列是用户匿名的,不记录user id
- 一个用户在多个平台、多个领域都会产生交互序列,每个domain的序列单独记录,混合在一起作为序列数据
- 商品ID不会作为UniSRec的输入,因为商品ID跨domain是没有意义的。
- 因此UniSRec的目的能够有 建模通用序列表征 的能力,这样的话就可以实现利用 微博 的序列数据在 淘宝 推荐
通用商品文本表示
基于预训练语言模型的商品文本编码
将商品文本输入BERT,用 [CLS] 作为序列表征:
x i = BERT ( [ [ C L S ] ; w 1 , … , w c ] ) \boldsymbol{x}_{i}=\operatorname{BERT}\left(\left[[\mathrm{CLS}] ; w_{1}, \ldots, w_{c}\right]\right) xi=BERT([[CLS];w1,…,wc])
x i ∈ R d W \boldsymbol{x}_{i} \in \mathbb{R}^{d_{W}} xi∈RdW 是 [CLS]的输出。尽管已经
Semantic Transformation via Parametric Whitening
在NLP领域有很多研究表明BERT生成的表示空间是非平滑且各向异性的,具体表现就是BERT输出的向量在计算无监督相似度的时候效果很差,一个改进措施就是把BERT的输出向量变成高斯分布,即让所有的向量转换为均值为0且协方差为单位矩阵的向量。
(也比较好理解,在BERT的预训练中完全没有显式的pairwise的优化Alignment和Uniformity)
这篇文章没有用预先算出来的均值和方差来做白化,为了在未知领域上更好地泛化,在将b和W置为可学习参数:
x ~ i = ( x i − b ) ⋅ W 1 \widetilde{\boldsymbol{x}}_{i}=\left(\boldsymbol{x}_{i}-\boldsymbol{b}\right) \cdot \boldsymbol{W}_{1} x i=(xi−b)⋅W1
就是投影到另一个语义空间中。
Domain Fusion and Adaptation via MoE-enhanced Adaptor
由于不同域之间往往存在较大的语义差距,因此学习通用商品表示时要考虑如何迁移和融合不同域的信息。举例来说,Food 域的高频词有 natural, sweet, fresh 等,而 Movies 域则是 war, love, story 等。如果直接将多个BERT的原始输出投影到同一个语义空间,可能会存在bias,不能适配新的推荐场景。
因此利用混合专家架构(mixture-of-expert, MoE)对每个商品学习多个参数白化表示,并自适应的融合成通用的商品表示。引入G个参数白化网络作为expert,以及参数化的路由模块:(有专家就有路由)
v i = ∑ k = 1 G g k ⋅ x ~ i ( k ) \boldsymbol{v}_{i}=\sum_{k=1}^{G} g_{k} \cdot \widetilde{\boldsymbol{x}}_{i}^{(k)} vi=k=1∑Ggk⋅x i(k)
其中 x ~ i ( k ) \widetilde{\boldsymbol{x}}_{i}^{(k)} x i(k)是第k个参数白化网络的输出, g k g_k gk是门口路由模块生成的对应的融合权重,具体计算方式:
g = Softmax ( x i ⋅ W 2 + δ ) δ = Norm ( ) ⋅ Softplus ( x i ⋅ W 3 ) \begin{aligned} &\boldsymbol{g}=\operatorname{Softmax}\left(\boldsymbol{x}_{i} \cdot \boldsymbol{W}_{2}+\boldsymbol{\delta}\right) \\ &\boldsymbol{\delta}=\operatorname{Norm}() \cdot \operatorname{Softplus}\left(\boldsymbol{x}_{i} \cdot \boldsymbol{W}_{3}\right) \end{aligned} g=Softmax(xi⋅W2+δ)δ=Norm()⋅Softplus(xi⋅W3)
使用BERT原始输出 x i x_i xi 作为路由模块的输入,W都是可学习参数。Norm()是生成随机高斯噪声,为了experts之间负载均衡。
- 多个参数白化网络类似于MHA、多核卷积
- 这种MoE架构有利于领域适配与融合
- 在这里插入参数有利于后续的微调
通用序列表示
现在已经得到了一条embedding组成的序列了,设计模型架构需要考虑可以使用同一个序列模型建模不同推荐场景的商品。考虑到不同domain通常对应不同的用户行为模式,简单的直接pooling方法可能会导致跷跷板现象、冲突。
基于这个motivation提出两种基于对比学习的预训练任务。
首先过多层Transformer:
f j 0 = v i + p j F l + 1 = FFN ( MHAttn ( F l ) ) \begin{gathered} \boldsymbol{f}_{j}^{0}=\boldsymbol{v}_{i}+\boldsymbol{p}_{j} \\ \boldsymbol{F}^{l+1}=\operatorname{FFN}\left(\operatorname{MHAttn}\left(\boldsymbol{F}^{l}\right)\right) \end{gathered} fj0=vi+pjFl+1=FFN(MHAttn(Fl))
最后一层的最后一个位置的输出作为整条序列的表征 f n L f_{n}^{L} fnL,也是下文的 s s s
序列-商品对比任务
给定序列,预测下一时刻商品(正例),负例是用in-batch的多个域的商品作为负例,增强不同域的通用表示的融合与适配:
ℓ S − I = − ∑ j = 1 B log exp ( s j ⋅ v j / τ ) ∑ j ′ = 1 B exp ( s j ⋅ v j ′ / τ ) \ell_{S-I}=-\sum_{j=1}^{B} \log \frac{\exp \left(\boldsymbol{s}_{j} \cdot \boldsymbol{v}_{j} / \tau\right)}{\sum_{j^{\prime}=1}^{B} \exp \left(\boldsymbol{s}_{j} \cdot \boldsymbol{v}_{j^{\prime}} / \tau\right)} ℓS−I=−j=1∑Blog∑j′=1Bexp(sj⋅vj′/τ)exp(sj⋅vj/τ)
序列-序列对比任务
对于一个商品序列,随机drop商品或者商品文本中的单词,得到序列的正例,然后负例是in-batch的其它域的其它序列:
ℓ S − S = − ∑ j = 1 B log exp ( s j ⋅ s ~ j / τ ) ∑ j ′ = 1 B exp ( s j ⋅ s j ′ / τ ) \ell_{S-S}=-\sum_{j=1}^{B} \log \frac{\exp \left(\boldsymbol{s}_{j} \cdot \tilde{\boldsymbol{s}}_{j} / \tau\right)}{\sum_{j^{\prime}=1}^{B} \exp \left(\boldsymbol{s}_{j} \cdot \boldsymbol{s}_{j^{\prime}} / \tau\right)} ℓS−S=−j=1∑Blog∑j′=1Bexp(sj⋅sj′/τ)exp(sj⋅s~j/τ)
两个loss一起预训练:
L P T = ℓ S − I + λ ⋅ ℓ S − S \mathcal{L}_{\mathrm{PT}}=\ell_{S-I}+\lambda \cdot \ell_{S-S} LPT=ℓS−I+λ⋅ℓS−S
微调
微调时把所有Transformer encoder fix(PLM的本来就是fixed的),只微调MoE那一块的参数,即利用MoE让预训练模型快速和新领域适配、融合。
根据新的推荐场景中的商品id是否可用,设置两种微调设置:
Inductive:
对于新商品频繁涌现的推荐场景,商品ID没啥用,还是用商品文本作为新商品的通用表示,按照以下概率预测:
P I ( i t + 1 ∣ s ) = Softmax ( s ⋅ v i t + 1 ) P_{I}\left(i_{t+1} \mid s\right)=\operatorname{Softmax}\left(\boldsymbol{s} \cdot \boldsymbol{v}_{i_{t+1}}\right) PI(it+1∣s)=Softmax(s⋅vit+1)
Transductive:
对于几乎所有商品都在训练集出现的场景(没有OOV),我们也可以同时学习商品 ID 表示。可以简单将通用文本表示和 ID 表示加和并进行预测:
P T ( i t + 1 ∣ s ) = Softmax ( s ~ ⋅ ( v i t + 1 + e i t + 1 ) ) P_{T}\left(i_{t+1} \mid s\right)=\operatorname{Softmax}\left(\tilde{\boldsymbol{s}} \cdot\left(\boldsymbol{v}_{i_{t+1}}+\boldsymbol{e}_{i_{t+1}}\right)\right) PT(it+1∣s)=Softmax(s~⋅(vit+1+eit+1))
就是在第二个Encoder之前加e。
两类微调都用交叉熵loss。
实验
数据集

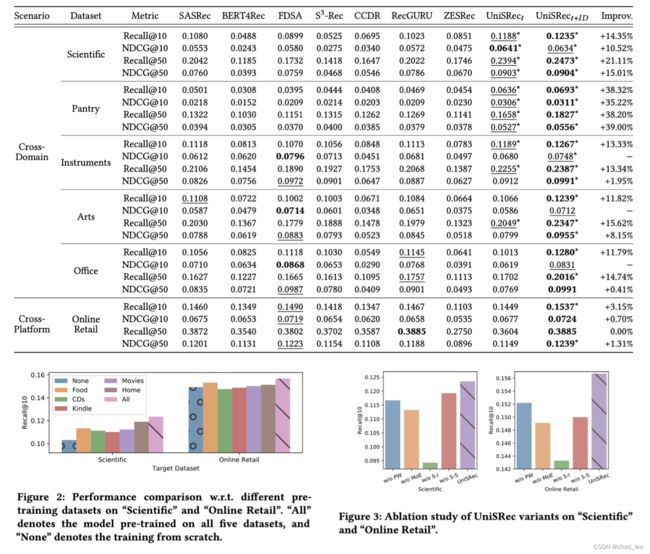
在Amazon数据集的5个domain(Food, Home, CDs, Kindle, Movies)上预训练,然后将预训练好的UniSRec在下游数据集上微调。
下游数据集可以分为两类:
- 跨domain:将 Amazon 数据集中另 5 个规模较小的 domain(Pantry, Scientific, Instruments, Arts, Office)视作新 domain 并测试 UniSRec 的效果。
- 跨平台:某英国电商数据集 Online Retail 作为新平台进行测试。
预训练数据集和下游的六个数据集均没有用户和商品重叠
实验效果
UnisRec的模型结构和SASRec基本是一样的