【Lawin Transformer2022】Lawin Transformer: Improving Semantic Segmentation Transformer with Multi-Sc
Lawin Transformer: Improving Semantic Segmentation Transformer with Multi-Scale Representations via Large Window Attention
Lawin Transformer:通过大窗口注意改进具有多尺度表示的语义分割转换器
论文地址:https://arxiv.org/abs/2201.01615
代码地址:https://github.com/yan-hao-tian/lawin
摘要
多尺度表征对语义分割至关重要。社区已经见证了利用多尺度背景信息的语义分割卷积神经网络(CNN)的蓬勃发展。由于Vision Transformer(ViT)在图像分类中的强大作用,最近提出了一些语义分割ViTs,其中大多数取得了令人印象深刻的结果,但以计算经济为代价。在本文中,我们通过窗口关注机制成功地将多尺度表示引入语义分割ViT,并进一步提高了性能和效率。为此,我们引入了大窗口关注机制,允许本地窗口在仅有少量计算开销的情况下查询更大范围的上下文窗口。通过调节上下文区域与查询区域的比例,我们使大窗口关注能够捕捉到多种尺度的上下文信息。此外,我们还采用了空间金字塔池的框架来与大窗口注意力协作,这就为语义分割ViT提供了一个新颖的解码器,名为大窗口注意力空间金字塔池(LawinASPP)。我们得到的ViT,Lawin Transformer,是由一个高效的hierarchical vision transformer (HVT)作为编码器和LawinASPP作为解码器组成。实验结果表明,与现有的方法相比,Lawin Transformer提供了一个更好的效率。Lawin Transformer在Cityscapes(84.4% mIoU)、ADE20K(56.2% mIoU)和COCO-Stuff数据集上进一步创造了新的最先进性能。该代码将发布在*https://github.com/yan-hao-tian/lawin。*
1. 介绍
语义分割是计算机视觉中最重要的稠密预测任务之一。随着深度卷积神经网络(CNN)在这一领域的繁荣,基于CNN的语义分割管道在广泛的实际应用中获得越来越多的青睐,如自动驾驶汽车、医学成像分析和遥感图像解释[32, 34, 35]。在仔细研究了著名的语义分割CNN之后,我们注意到一系列的工作主要集中在利用多尺度表征上[9,10,24,25,49,50],这对理解多尺度的先验背景起着至关重要的作用。为了纳入丰富的上下文信息,这些工作大多将过滤器或池化操作,如无序卷积[47]和自适应池化,应用于空间金字塔池化(SPP)模块[23, 27]。
自从Vision Transformer(ViT)在图像分类上的表现令人印象深刻[19,38],有一些努力用纯Transformer模型来解决语义分割问题,仍然比以前的语义分割CNN要好得多[30,36,42,52]。然而,实现这些语义分割ViTs需要很高的计算成本,特别是当输入图像很大时。为了解决这个问题,出现了纯粹基于hierarchical vision transformer (HVT)的方法,节省了很多计算预算。Swin Transformer是最有代表性的HVT之一,在许多视觉任务上取得了最先进的成果[30],同时它采用了一个重型解码器[42]来对像素进行分类。SegFormer完善了编码器和解码器的设计,产生了一个非常高效的语义分割ViT[43]。但有一个问题是,SegFormer仅仅依靠增加编码器的模型容量来逐步提高性能,这有可能降低效率的上限。
通过以上分析,我们认为目前语义分割ViT的一个主要问题是缺乏多尺度的语境信息,从而影响了性能和效率。为了克服这一限制,我们提出了一种新的窗口关注机制,即大窗口关注。如图1所示,在大窗口关注中,均匀分割的补丁会查询覆盖更大区域的上下文补丁,而局部窗口关注中的补丁只是查询自己。另一方面,考虑到注意力会随着上下文补丁的扩大而变得难以计算,我们设计了一个简单而有效的策略来缓解大上下文的困境。具体来说,我们首先将大的上下文补丁汇集到相应的查询补丁的空间维度上,以保持原有的计算复杂性。
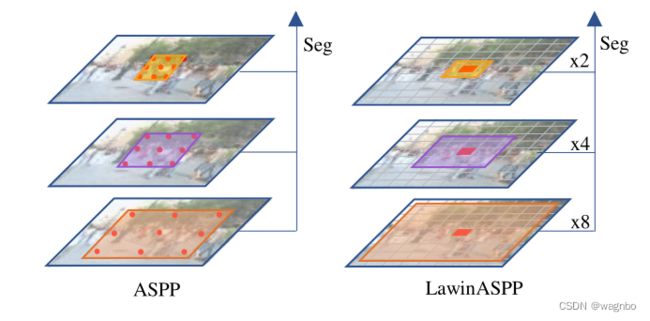
图1. LawinASPP和ASPP之间的区别。在ASPP中,以不同的扩张率进行的无序卷积可以捕获多个尺度的表征。相比之下,LawinASPP用我们提出的大窗口关注取代了无序卷积。红色窗口代表查询区域。黄色、橙色和紫色的窗口代表不同空间大小的背景区域。
然后,我们在大窗口关注中启用多头机制,在汇集上下文的同时,将头的数量严格设定为下采样率R的平方,主要用于恢复查询和上下文之间被抛弃的依赖关系。最后,受MLP-Mixer[37]中token-mixing MLP的启发,我们在头的 R 2 R^2 R2子空间上分别应用了 R 2 R^2 R2位置混合操作,加强了多头注意的空间表示能力。因此,我们提出的大窗口注意中的补丁可以捕获任何尺度的上下文信息,只是产生了一点位置混合操作引起的计算开销。与不同比率R的大窗口注意相结合,SPP模块演变成大窗口注意空间金字塔池(LawinASPP),人们可以像ASPP(Atrous Spatial Pyramid Pooling)[9]和PPM(Pyramid Pooling Module)[50]一样采用它来利用多尺度表示进行语义分割。
我们通过将LawinASPP置于HVT的顶端,将高效的HVT扩展到Lawin Transformer,从而将多尺度表示引入语义分割ViT。Lawin Transformer的性能和效率在Cityscapes[17]、ADE20K[53]和COCO-Stuff[4]数据集上得到了评估。我们进行了广泛的实验,将Lawin Transformer与现有的基于HVT的语义分割方法[11, 30, 43]进行比较。Lawin Transformer的效率提高了,这一点从Lawin Transformer花费较少的计算资源来获得更好的性能得到了证明。此外,我们的实验表明,Lawin Transformer在这些基准上一直优于其他先进的方法。
2. 相关工作
2.1. 语义分割
基于全卷积神经网络(FCN)的语义分割模型[31]是完成像素级分类的最有希望的方法。为了实现精确的场景理解,已经在许多方面对语义分割CNN进行了连续改进。[1, 3, 29, 34] 缓解了高层特征的边界信息不足。[7, 8, 33, 47]被提出来扩大模型的接受域。空间金字塔集合(SPP)模块已被证明在利用多尺度表征方面是有效的,它从局部背景到全局背景收集场景线索[10, 24, 25, 50]。另一条工作路线是利用自我注意机制的变体来建立表征之间的依赖关系[5, 21, 26, 28, 40, 45, 46, 51]。
2.2. Vision Transformer
Transformer已经彻底改变了神经语言处理,并在计算机视觉中被证明非常成功。ViT[19]是第一个用于图像分类的端到端视觉转化器,它将输入图像投射到一个标记序列中,并将其附加到一个类标记上。DeiT[38]通过一个令牌提炼管道提高了训练ViT的数据效率。除了序列到序列的结构,PVT[39]和Swin Transformer[30]的效率激发了人们对探索层次视觉变换器(HVT)[14, 22, 41, 44]的极大兴趣。ViT也被扩展到解决低层次任务和密集预测问题[2,6,20]。特别是,由ViT驱动的并发语义分割方法呈现出令人印象深刻的性能。SETR[52]将ViT部署为编码器,并对输出的补丁嵌入进行上采样,对像素进行分类。Swin Transformer通过连接UperNet[42]将自己扩展为一个语义分割的ViT。Segmenter[36]依赖于ViT/DeiT作为骨干,并提出了一个掩码变换器解码器。Segformer[43]展示了一个简单、高效而强大的语义分割编码器和解码器的设计。MaskFormer[11]将语义分割重新表述为一个掩码分类问题,与Swin-UperNet相比,其FLOPs和参数要少很多。在本文中,我们通过在HVT中引入多尺度表示,向更有效的语义分割ViT设计迈出了新的一步。
2.3. MLP-Mixer
MLP-Mixer[37]是一个比ViT更简单的新型神经网络。与ViT类似,MLP-Mixer首先采用线性投影的方式,像ViT一样得到一个标记序列。鲜明的区别是MLP-Mixer完全基于多层感知器(MLP),因为它用令牌混合MLP取代了转换层的自我注意。令牌混合MLP沿着通道维度行事,混合令牌(位置)来学习空间表征。在我们提出的大窗口注意中,令牌混合MLP被应用于集合的上下文补丁,我们称之为位置混合,以提高多头注意的空间表征。
3.方法
在这一部分,我们首先简要地介绍了多头注意力和标记混合MLP。然后,我们阐述了大窗口注意力并描述了LawinASPP的结构。最后,介绍了Lawin变换器的整体结构。
3.1. 背景
多头注意是Transformer layer的核心。在层次视觉变换器(Hierarchical Vision Transformer,HVT)中,多头注意的操作仅限于局部均匀分割的窗口,这被称为局部窗口注意。假设输入是一个二维特征图,表示为 x 2 d ∈ C × H × W {x_{2d}} \in {^{C \times H \times W}} x2d∈C×H×W,我们可以将窗口注意的操作表述为:
x ^ 2 d = R e s h a p e ( h , H W P 2 , C h , P , P ) ( x 2 d ) , (1) \hat x_{2d}=Reshape \left( h,{HW\over P^2},{C\over h},P,P \right)(x_{2d}),\tag{1} x^2d=Reshape(h,P2HW,hC,P,P)(x2d),(1)
x 2 d = R e s h a p e ( C , H , W ) ( M H A ( x ^ 2 d ) ) + x 2 d , (2) x_{2d}=Reshape(C,H,W)(MHA(\hat x_{2d}))+x_{2d},\tag{2} x2d=Reshape(C,H,W)(MHA(x^2d))+x2d,(2)
其中 h h h是头数, P P P是窗口的空间大小, M H A ( ) MHA() MHA()是多头关注(MHA)机制。MHA的基本操作可以描述为。
A = s o f t m a x ( ( W q x 2 d ( W k x 2 d ) T ) D h ) ( W v x 2 d ) , (3) A=softmax\left( {(W_qx_{2d}(W_kx_{2d})^T)\over\sqrt D_h }\right)(W_vx_{2d}),\tag{3} A=softmax(Dh(Wqx2d(Wkx2d)T))(Wvx2d),(3)
M H A = c o n c a t [ A 1 ; A 2 ; . . . ; A h ] W m h a , (4) MHA=concat[A_1;A_2;...;A_h]W_{mha},\tag{4} MHA=concat[A1;A2;...;Ah]Wmha,(4)
其中, W q W_q Wq、 W k W_k Wk和 W V ∈ C × D h {W_V} \in {^{C \times {D_h}}} WV∈C×Dh是学习到的线性变换, W m h s a ∈ R D × C {W_{mhsa}} \in {R^{D \times C}} Wmhsa∈RD×C是学习到的权重,聚集了多个注意值。 D h D_h Dh通常被设定为 D / h D/h D/h, D D D是嵌入维度。
Token-mixing MLP是MLP-Mixer的核心,它可以聚合空间信息,通过让空间位置相互沟通。给定输入的二维特征图 x 2 d ∈ C × H × W {x_{2d}} \in {^{C \times H \times W}} x2d∈C×H×W,令牌混合MLP的操作可以表述为。
x ^ 2 d = R e s h a p e ( C , H W ) ( x 2 d ) , (5) \hat x_{2d}=Reshape (C,HW)(x_{2d}),\tag{5} x^2d=Reshape(C,HW)(x2d),(5)
x 2 d = R e s h a p e ( C , H , W ) ( M L P ( x ^ 2 d ) ) + x 2 d , (6) x_{2d}=Reshape (C,H,W)(MLP(\hat x_{2d}))+x_{2d},\tag{6} x2d=Reshape(C,H,W)(MLP(x^2d))+x2d,(6)
M L P ( x 2 d ) = W 2 σ ( W 1 ( x 2 d ) ) , (7) MLP( x_{2d})=W_2σ(W_1(x_{2d})),\tag{7} MLP(x2d)=W2σ(W1(x2d)),(7)
其中 W 1 ∈ R H W × D m l p {W_1} \in {R^{HW \times {D_{mlp}}}} W1∈RHW×Dmlp和 W 2 ∈ R D m l p × H W {W_2} \in {R^{{D_{mlp}} \times HW}} W2∈RDmlp×HW都是学习的线性变换, σ σ σ是提供非线性的激活函数。
3.2. 大窗口注意力
与第3.1节中提到的窗口关注相似,大窗口关注将整个特征图均匀地分割成几个斑块。反之,当大窗口注意力在图像上滑动时,允许当前的补丁查询更大的区域。为了简单起见,我们把查询补丁表示为 Q ∈ P 2 × C Q \in {^{{P^2} \times C}} Q∈P2×C,把被查询的大背景补丁表示为 Q ∈ R 2 × P 2 × C Q \in {^{{R^2} \times {P^2} \times C}} Q∈R2×P2×C,其中R是背景补丁大小与查询补丁大小的比率, P 2 P^2 P2是补丁的面积。由于注意力的计算复杂度为 O ( P 2 ) O( P^2) O(P2),当C的空间大小增加R倍时,计算复杂度增加到 O ( R 2 P 2 ) O({R^2}{P^2}) O(R2P2)。在这种情况下,注意力的计算不限于 P × P P×P P×P的局部斑块,如果比率 R R R或输入分辨率非常大,甚至无法承受。为了保持原有的计算复杂性,我们将 C C C汇集成一个抽象的张量,其下采样率为 R R R,将上下文斑块的空间大小减少到 ( P , P ) (P,P) (P,P)。然而,这样一个简单的过程也有一定的缺点。情境补丁的下采样不可避免地抛弃了Q和C之间丰富的依赖关系,特别是当R很大的时候。为了缓解注意力不集中的问题,我们自然而然地采用多头机制,让头的数量严格等于 R 2 R^2 R2,从而将注意力矩阵从 ( P 2 , P 2 ) (P^2, P^2) (P2,P2)制定为 ( P 2 , P 2 , P 2 ) (P^2, P^2, P^2) (P2,P2,P2)值得注意的是,头的数量对计算复杂性没有影响。
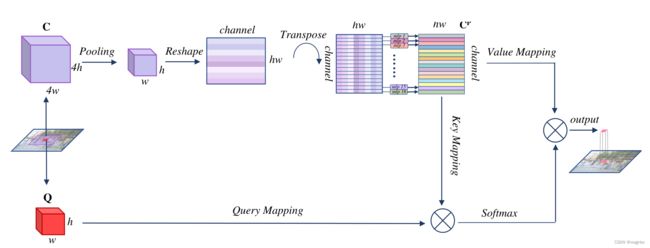
图2. 一个大窗口的关注。红色斑块Q是查询斑块,紫色斑块C是背景斑块。上下文被重塑并被送入标记混合MLPs。输出的上下文CP被命名为位置混合的上下文。最好以彩色观看
已经有研究表明,通过一定的技术规范化头部子空间,多头注意力可以学习到所需的不同表征[12,16,18]。考虑到下采样后空间信息变得抽象,我们打算加强多头注意力的空间表征能力。在MLP-Mixer中,令牌混合MLP与通道混合MLP在收集空间知识方面是互补的,因此我们定义了一组针对头部的位置混合 M L P = M L P 1 , M L P 2 , . . . , M L P h MLP={MLP_1, MLP_2, ..., MLP_h} MLP=MLP1,MLP2,...,MLPh。如图2所示,汇集的上下文补丁的每个头都被推入其相应的token(position)-mixing MLP,同一头内的空间位置以相同的行为相互交流。我们将产生的语境称为位置混合语境补丁,并将其表示为 C P C^P CP,其计算方法为。
C ^ = R e s h a p e ( h , C / h , P 2 ) ( φ ( C ) ) , (8) \hat C=Reshape(h,C/h,P^2)(\varphi (C)),\tag{8} C^=Reshape(h,C/h,P2)(φ(C)),(8)
C h = M L P h ( C ^ h ) + C ^ h , (9) C_h=MLP_h(\hat C_h)+\hat C_h,\tag{9} Ch=MLPh(C^h)+C^h,(9)
C P = R e s h a p e ( C , P 2 ) ( c o n c a t [ C 1 ; C 2 ; . . . ; C h ] ) , (10) C^P=Reshape(C,P^2)(concat[C_1;C_2;...;C_h]),\tag{10} CP=Reshape(C,P2)(concat[C1;C2;...;Ch]),(10)
其中, C ^ h {{{\rm{\hat C}}}_{\rm{h}}} C^h表示 C ^ {{\rm{\hat C}}} C^的第 h h h个头, M L P h ∈ P 2 × P 2 ML{P_h} \in {^{{P^2} \times {P^2}}} MLPh∈P2×P2是加强第h个头的空间表示的第h个变换, φ \varphi φ表示平均汇集操作。有了位置混合语境 C P C^P CP,我们可以将公式(3)和公式(4)重新表述如下。
A = s o f t m a x ( ( W q Q h ) ( W k C h P ) T D h ) ( W v C h P ) , (11) A=softmax \left({(W_qQ_h)(W_kC_h^P)^T\over \sqrt {D_h} }\right)(W_vC_h^P),\tag{11} A=softmax(Dh(WqQh)(WkChP)T)(WvChP),(11)
M H A = c o n c a t [ A 1 ; A 2 ; . . . ; A h ] W m h a . (12) MHA=concat[A_1;A_2;...;A_h]W_{mha}.\tag{12} MHA=concat[A1;A2;...;Ah]Wmha.(12)
一个主要的问题是关于MLP的开销,所以我们列出了局部窗口注意和大窗口注意的计算复杂性。
Ω ( L o w i n ) = 4 ( H W ) C 2 + 2 ( H W ) P 2 C , (13) \Omega(Lowin)=4(HW)C^2+2(HW)P^2C,\tag{13} Ω(Lowin)=4(HW)C2+2(HW)P2C,(13)
Ω ( L o w i n ) = 4 ( H W ) C 2 + 3 ( H W ) P 2 C , (143) \Omega(Lowin)=4(HW)C^2+3(HW)P^2C,\tag{143} Ω(Lowin)=4(HW)C2+3(HW)P2C,(143)
其中H和W分别是整个图像的高度和宽度, P P P是局部窗口的大小。由于 P 2 P^2 P2,通常设置为7或8,比高层特征中的 C C C小得多,所以MLP引起的额外支出是可以合理忽略的。令人钦佩的是,大窗口注意力的计算复杂性与比率 R R R无关。
3.3. LawinASPP
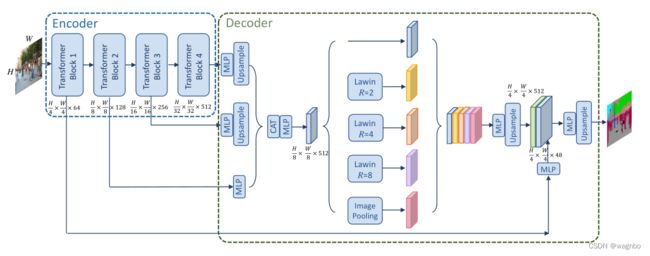
图3. Lawin变换器的整体结构。图像被送入编码器部分,它是一个MiT。然后,来自后三个阶段的特征被汇总,并被送入解码器部分,这是一个LawinASPP。最后,所得到的特征被编码器的第一级特征增强了低层次信息。"MLP "表示多层感知器。"CAT "表示对特征进行串联。
"Lawin "表示大窗口关注。"R "表示上下文补丁与查询补丁的大小比例。
为了捕捉多尺度表征,我们采用了空间金字塔集合(SPP)的架构,与大窗口关注协作,得到了新颖的SPP模块,称为LawinASPP。LawinASPP由5个平行的分支组成,包括一个快捷连接,三个R=(2,4,8)的大窗口注意力和一个图像池分支。如图3所示,大窗口注意的分支为局部窗口提供了三个层次的感受野。按照以前关于窗口注意机制的文献[30],我们将局部窗口的补丁大小设定为8,因此提供的感受野为(16,32,64)。图像池化分支使用全局池化层获得全局上下文信息,并将其推入线性转换,然后进行双线性上采样运算,以匹配特征维度。短路径复制输入特征,并在所有上下文信息输出后将其粘贴。所有产生的特征首先被连接起来,一个学习的线性变换执行降维以生成最终的分割图。
3.4. Lawin Transformer
在研究了先进的HVT之后,我们选择MiT和Swin-Transformer作为Lawin Transformer的编码器。MiT被设计为SegFormer[43]的编码器,SegFormer是一个简单、高效而强大的语义分割ViT。Swin-Transformer[30]是一个非常成功的建立在局部窗口注意力上的HVT。在应用LawinASPP之前,我们将输出跨度=(8,16,32)的多级特征串联起来,将其调整为输出跨度=8的特征的大小,并使用线性层对串联的特征进行转换。由此产生的输出跨度=8的转换特征被送入LawinASPP,然后我们得到具有多尺度上下文信息的特征。在最先进的语义分割的ViT中,用于最终预测分割对数的特征总是来自编码器的4级特征。因此,我们采用输出跨度=4的第一级特征来补偿低级别的信息。awinASPP的输出被放大到输入图像的四分之一大小,然后通过一个线性层与第一级特征融合。最后,在低层次增强的特征上预测分割对数。更多细节见图3。
4.实验
数据集。我们在三个公共数据集上进行实验,包括Cityscapes [17], ADE20K [53] 和COCOStuff [4]。Cityscapes是一个城市场景解析数据集,包含从50个城市拍摄的5000张精细注释的图像,有19个语义类别。有2,975张图片被分为训练集,500张图片被分为验证集,1,525张图片被分为测试集。ADE20K是语义分割中最具挑战性的数据集之一。它包括一个包含150个类别的20,210张图片的训练集,一个包含3,352张图片的测试集和一个包含2,000张图片的验证集。COCO-Stuff也是一个非常具有挑战性的基准,由16400张图像和172个语义类别组成。训练集包含118k图像,测试-开发数据集包含20k图像,验证集包含5k图像。
实施细节。我们的实验方案与[43]的方案完全相同。特别是,我们使用公开的ImageNet1K-pretrained MiT[43]作为Lawin变换器的编码器。本节中的所有实验都是基于MMSegmentation[15]代码库在8台Tesla V100的服务器上实现的。在做消融研究时,我们选择MiT-B3作为编码器,对所有模型进行80k次迭代训练。除非特别说明,所有的结果都是通过单尺度推理实现的。请注意,其他方法的所有结果是由我们训练官方代码获得的。
4.1. 与SegFormer的比较
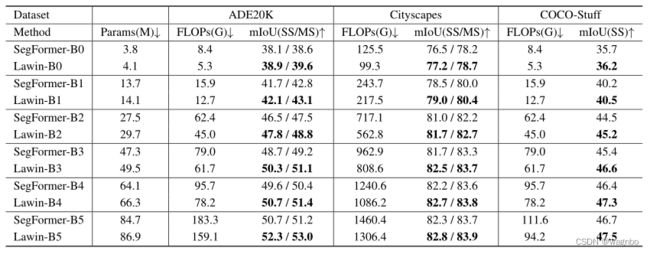
为了证明Lawin Transformer的效率提高,我们将其与SegFormer[43]进行比较。两者都是建立在窗口关注的基础上,以MiT作为编码器。为了实现公平性,我们在我们的环境中重新实现了SegFormer。表1显示了关于参数、FLOPs和mIoU的比较。显然,在MiT的所有变体中(B0→B5),Lawin Transformer在mIoU和FLOPs上胜过SegFormer,只需增加一点参数。
当轻量级的MiT-B0和MiT-B1作为编码器时,Lawin Transformer可以在节省计算成本的情况下提高性能。例如,Lawin-B0使用更少的FLOPs(3.1),在COCO-Stuff数据集上获得了0.5%的mIoU增益,在ADE20K数据集上获得了0.8%的增益。此外,我们观察到,在某些情况下,Lawin Transformer可以弥补由编码器的模型容量造成的性能差距。例如,SegFormer-B3在所有三个数据集上的表现都比SegFormerB4差。但是,如果用LawinASPP代替原始解码器,结果Lawin-B3比SegFormer-B4好0.6% mIoU,在ADE20K上产生了34G FLOPs的计算节省,甚至使用更少的参数。另外,在Cityscapes上,Lawin-B4比SegFormer-B5提高了0.4%,计算成本降低了近三分之一;Lawin-B3比SegFormer-B5提高了0.2%,计算成本和参数降低了近一半。这些经验结果表明,随着编码器容量的不断增加,语义分割ViT可能遇到性能瓶颈。与简单地扩大编码器相比,LawinASPP提出了一种有希望的、有效的方法,通过捕捉丰富的上下文信息来克服这一瓶颈。
4.2. 比较UperNet和MaskFormer
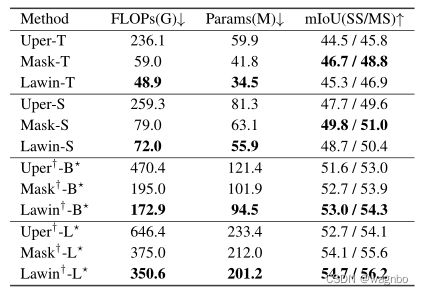
为了进一步显示效率,我们用Swin-Transformer[30]代替MiT,并将Swin-Lawin Transformer与Swin-UperNet和MaskFormer在ADE20K上进行比较,如表2所示。从表2中,我们有以下观察。首先,与Swin-UperNet相比,Swin-Lawin在很大程度上提高了性能并节省了大量的计算成本。特别是,带有Swin-B的Lawin Transformer能够以近四分之一的计算成本超越带有Swin-L的UperNet。其次,与Swin-MaskFormer相比,Swin-Lawin在Swin-Transformer的所有变体中始终使用较少的FLOPs和参数。最后,通过对性能的仔细观察,我们发现,当编码器的容量较小时(Swin-T→S),Swin-Lawin的性能比MaskFormer差。然而,随着编码器容量的增加(Swin-B→L),Swin-Lawin的表现优于MaskFormer。可以看出,随着容量的增加,Swin-Lawin与SwinUper相比所创造的性能增益也变得更大。我们推断,短路径分支和Lawin Transformer中的低层次信息在最终预测中具有非常重要的作用(4.3.3节讨论了Lawin Transformer中不同层次的贡献),它们都直接来自骨干网的多层次特征。因此,编码器部分越强大,Lawin Transformer的性能增益就越大。
4.3. 消融实验
4.3.1 空间金字塔池
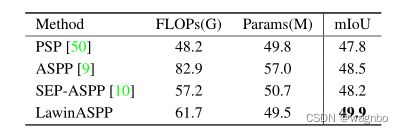
由于LawinASPP中的空间金字塔池化(SPP)[23, 27]架构,Lawin Transformer以一种有效的方式捕获了具有大窗口注意力的多尺度表示。为了研究大窗口注意力和SPP架构对性能的影响,我们选择了一些依靠SPP的代表性方法,包括PPM(金字塔池化模块)[50],ASPP(Atrous空间金字塔池化)[9]和SEP-ASPP(深度可分离的Atrous空间金字塔池化)[10]。LawinASPP与这些替代方案之间的明显区别是基本的池化操作。PPM使用金字塔自适应池化来捕捉不同尺度的背景信息。ASPP使用腹式卷积来提取多尺度特征。为了提高效率,SEPASPP使用深度可分离的阿特拉斯卷积[13]来代替阿特拉斯卷积。表3显示了MiT-B3与不同的基于SPP的模块相结合时的参数、FLOPs和mIoU,这些都在ADE20K上进行了测试。PPM和SEP-ASPP是令人印象深刻的计算经济,甚至比LawinASPP使用更少的FLOPs。然而,它们与LawinASPP之间存在着相当大的性能差距(PPM为2.1%,SEP-ASPP为1.7%)。ASPP取得的性能略高于SEP-ASPP,但花费的计算资源最多。通过这些竞争,LawinASPP被证明是将多尺度表征引入语义分割ViT的首选模块,这主要归功于大窗口注意力。
4.3.2 大窗口注意力的关键组成部分
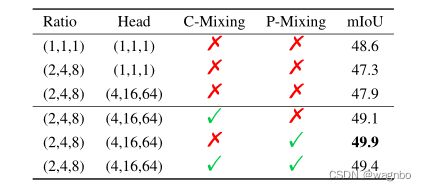

池化和多头化:用下采样率R汇集大的上下文补丁,并将MHA的头数增加到R2,目的是分别降低计算复杂性和恢复被丢弃的依赖关系。为了验证该策略,我们进行了表4所示的第一组实验。我们首先测试了大上下文补丁保持空间大小而不进行任何降采样时的性能。然而,这种设置所需的内存是无法承受的,所以我们做了一点调整,如图4所示,将查询补丁的大小设置为等于上下文补丁。这个简单实现的性能比标准实现低1.3%。如果将上下文补丁汇集到与查询补丁相同的大小,性能就会严重下降,只能达到47.3%的mIoU,这是由于注意力稀少的原因。启用多头机制可以带来0.6%的改进,但落后于标准甚至是简单的实现。这组比较表明,大窗口注意力与集合上下文补丁实际上存在不充分的依赖性,而多头机制可以略微缓解这一问题。
位置混合和通道混合。在大窗口注意中,我们创新性地采用了位置混合操作来加强多头注意的空间表征能力。在MLP-Mixer[37]中,应用通道混合MLP来学习特征通道的知识。MLP-Mixer同时使用了两种MLP,这促使我们对通道混合的研究。我们通过用通道混合MLP代替标记混合MLP来加强每个头内的特征通道的交流。上下文补丁被降低采样,多头机制被启用。表4中列出的第二组结果表明,通道混合MLP提高了多头注意力的表现,并提供了1.2%的明显的性能改进,但不像令牌混合MLP那样强大(2%)。此外,我们将令牌混合MLP和通道混合MLP结合起来,就像MLP-Mixer中的一个区块,沿着两个维度转换每个头的子空间,获得了49.4%的mIoU的竞争结果,但比孤立的位置混合(49.9%)要差。通过这些观察,我们认为位置混合操作比通道混合更有助于恢复空间降采样操作的依赖性。
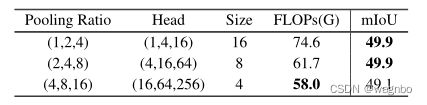
语境的空间大小。大的窗口注意将上下文补丁汇集到查询补丁的相同空间大小,以保持效率和性能之间的平衡。我们对破坏这种平衡的后果感兴趣。具体来说,我们评估了以下情况下的性能:上下文补丁被汇集到两倍于查询补丁的空间大小,以及上下文补丁被汇集到查询补丁的一半大小。前者牺牲了计算的经济性,可能对性能有利;后者节省了更多的计算成本,可能对性能有害。从表5中可以发现,在前一种情况下没有获得明显的性能。当上下文补丁被汇集到一个较小的尺寸时,mIoU下降了0.8%,只节省了3.7G的少量计算成本。将上下文补丁汇集到查询补丁的大小是一个明智的选择,可以保持良好的平衡。
4.3.3 Branch in LawinASPP
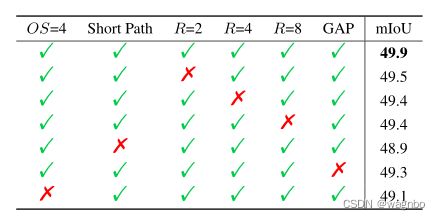
如图3所示,LawinASPP聚合了来自五个分支的特征,以收集多尺度的丰富的背景信息。在聚合之后,第一级特征通过一个辅助分支来用低层次的信息来增强它。我们在此研究LawinASPP中六个分支的功效。在表6中,我们报告了没有不同分支时的结果。对于大窗口关注的分支,去除R=2、R=4和R=8的分支,性能分别下降了0.4%、0.5%和0.5%。图像集合分支产生了0.6%的改善,所以全局背景信息是LawinASPP的一个重要层次。短路径对于LawinASPP来说也是不可或缺的,因为最大的性能提升(1.0%)是来自这个分支。我们出乎意料地观察到,增加辅助分支会导致0.8%的改进,这体现了低层次信息的重要性。
4.4.Comprasion with State-of-the-Art
最后,我们在ADE20K、Cityscapes和COCO-Stuff数据集上将我们的结果与现有方法进行了比较。
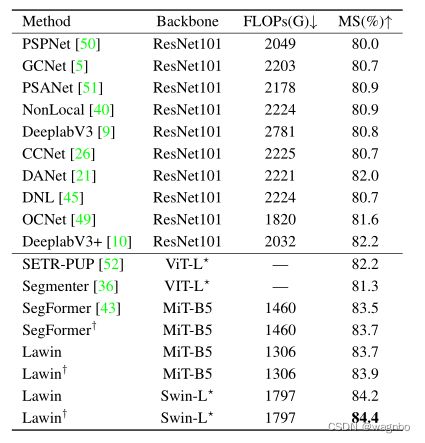
表7显示了最先进的方法在Cityscapes数据集上的结果。第一组包含基于CNN的语义分割方法,第二组包含基于ViT的语义分割方法。如果不指定8,输入图像的裁剪尺寸为768/769 × 768/769。为了提高Lawin Transformer的性能,我们使用MiT-B5和Swin-L作为编码器。使用Swin-L的Lawin Transformer在城市景观上取得了最佳性能。
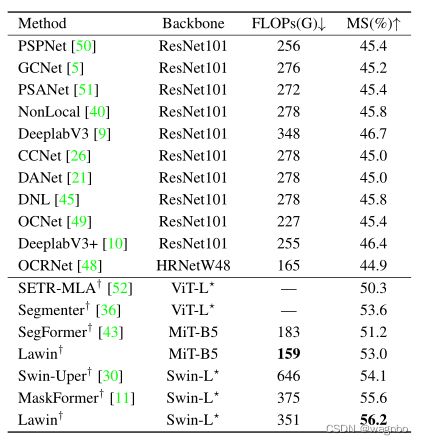
表8报告了最先进的方法在ADE20K数据集上的表现。这些结果仍然分为两部分,包括基于CNN的方法和基于ViT的方法。如果没有指定,输入图像的裁剪尺寸为512×512。采用Swin-L的Lawin变换器优于其他所有方法。采用MiT-B5的Lawin Transformer使用的FLOPs最少(159 GFLOPs),并取得了出色的性能(53.0% mIoU)。
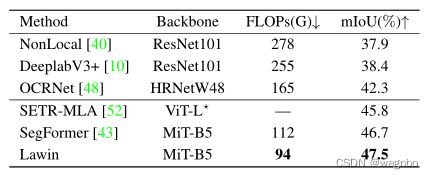
表9列出了最先进的方法在COCO-stuff上的一些结果。由于报告COCO-tuff性能的论文很少,我们只列出了基于CNN的代表性方法的结果。Lawin-B5获得了47.5%的最佳mIoU,同时也使用了94G的最少FLOPs。
5.结论
在这项工作中,我们开发了一个高效的语义分割转化器,称为Lawin Transformer。Lawin Transformer的解码器部分能够在多个尺度上捕获丰富的上下文信息,这建立在我们提出的大窗口注意上。与现有的高效语义分割变换器相比,Lawin Transformer能够以较少的计算费用实现更高的性能。最后,我们在Cityscapes、ADE20K和COCO-Stuff数据集上进行了实验,在这些基准上产生了最先进的结果。我们希望Lawin Transformer能在未来激发语义分割ViT的创造力。
References
[1] Md Amirul Islam, Mrigank Rochan, Neil DB Bruce, and Yang Wang. Gated feedback refinement network for dense image labeling. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3751–3759,2017. 2
[2] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Luˇci´c, and Cordelia Schmid. Vivit: A video vision transformer. arXiv preprint arXiv:2103.15691, 2021. 2
[3] Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla.Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE transactions on pattern analysis and machine intelligence, 39(12):2481–2495, 2017. 2
[4] Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. Cocostuff: Thing and stuff classes in context. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1209–1218, 2018. 2, 5
[5] Y ue Cao, Jiarui Xu, Stephen Lin, Fangyun Wei, and Han Hu. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF Inter national Conference on Computer Vision Workshops, pages 0–0, 2019. 2, 8
[6] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-toend object detection with transformers. In European Conference on Computer Vision, pages 213–229. Springer, 2020.2
[7] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos,Kevin Murphy, and Alan L Y uille. Semantic image segmentation with deep convolutional nets and fully connected crfs.arXiv preprint arXiv:1412.7062, 2014. 2
[8] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos,Kevin Murphy, and Alan L Y uille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE transactions on pattern analysis and machine intelligence, 40(4):834–848, 2017. 2
[9] Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587,2017. 1, 2, 6, 8
[10] Liang-Chieh Chen, Y ukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), pages 801–818, 2018. 1, 2, 6, 8
[11] Bowen Cheng, Alexander G. Schwing, and Alexander Kirillov. Per-pixel classification is not all you need for semantic segmentation. arXiv, 2021. 2, 8
[12] Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever.Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019. 4
[13] Franc ¸ois Chollet. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages1251–1258, 2017. 7
[14] Xiangxiang Chu, Zhi Tian, Y uqing Wang, Bo Zhang, Haibing Ren, Xiaolin Wei, Huaxia Xia, and Chunhua Shen.Twins: Revisiting spatial attention design in vision transformers. arXiv preprint arXiv:2104.13840, 2021. 2
[15] MMSegmentation Contributors. MMSegmentation:Openmmlab semantic segmentation toolbox and benchmark. https : / / github . com / open mmlab/mmsegmentation, 2020. 5
[16] Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the relationship between self-attention and convolutional layers. arXiv preprint arXiv:1911.03584, 2019.4
[17] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016. 2, 5
[18] Stéphane d’Ascoli, Hugo Touvron, Matthew Leavitt, Ari Morcos, Giulio Biroli, and Levent Sagun. Convit: Improving vision transformers with soft convolutional inductive biases.arXiv preprint arXiv:2103.10697, 2021. 4
[19] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov,Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner,Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR. OpenReview.net, 2021. 1, 2
[20] Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12873–12883, 2021. 2
[21] Jun Fu, Jing Liu, Haijie Tian, Y ong Li, Y ongjun Bao, Zhiwei Fang, and Hanqing Lu. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3146–3154, 2019. 2, 8
[22] Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, and Matthijs Douze.Levit: a vision transformer in convnet’s clothing for faster inference. arXiv preprint arXiv:2104.01136, 2021. 2
[23] Kristen Grauman and Trevor Darrell. The pyramid match kernel: Discriminative classification with sets of image features. In Tenth IEEE International Conference on Computer Vision (ICCV’05) V olume 1, volume 2, pages 1458–1465.IEEE, 2005. 1, 6
[24] Junjun He, Zhongying Deng, and Y u Qiao. Dynamic multiscale filters for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3562–3572, 2019. 1, 2
[25] Junjun He, Zhongying Deng, Lei Zhou, Yali Wang, and Y u Qiao. Adaptive pyramid context network for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7519–7528, 2019. 1, 2
[26] Zilong Huang, Xinggang Wang, Lichao Huang, Chang Huang, Y unchao Wei, and Wenyu Liu. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision,pages 603–612, 2019. 2, 8
[27] Svetlana Lazebnik, Cordelia Schmid, and Jean Ponce. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), volume 2, pages 2169–2178. IEEE, 2006.1, 6
[28] Hanchao Li, Pengfei Xiong, Jie An, and Lingxue Wang.Pyramid attention network for semantic segmentation. arXiv preprint arXiv:1805.10180, 2018. 2
[29] Guosheng Lin, Anton Milan, Chunhua Shen, and Ian Reid. Refinenet: Multi-path refinement networks for highresolution semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1925–1934, 2017. 2
[30] Ze Liu, Y utong Lin, Y ue Cao, Han Hu, Yixuan Wei,Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030, 2021. 1, 2, 5, 6, 8
[31] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3431–3440, 2015. 2
[32] V olodymyr Mnih and Geoffrey E Hinton. Learning to detect roads in high-resolution aerial images. In European Conference on Computer Vision, pages 210–223. Springer, 2010.1
[33] Chao Peng, Xiangyu Zhang, Gang Y u, Guiming Luo, and Jian Sun. Large kernel matters–improve semantic segmentation by global convolutional network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4353–4361, 2017. 2
[34] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. Unet: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241.Springer, 2015. 1, 2
[35] Mennatullah Siam, Sara Elkerdawy, Martin Jagersand, and Senthil Y ogamani. Deep semantic segmentation for automated driving: Taxonomy, roadmap and challenges. In 2017 IEEE 20th international conference on intelligent transportation systems (ITSC), pages 1–8. IEEE, 2017. 1
[36] Robin Strudel, Ricardo Garcia, Ivan Laptev, and Cordelia Schmid. Segmenter: Transformer for semantic segmentation. arXiv preprint arXiv:2105.05633, 2021. 1, 2, 8
[37] Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Y ung,Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al.Mlp-mixer: An all-mlp architecture for vision. arXiv preprint arXiv:2105.01601, 2021. 2, 7
[38] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning,pages 10347–10357. PMLR, 2021. 1, 2
[39] Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao.Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. arXiv preprint arXiv:2102.12122, 2021. 2
[40] Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7794–7803, 2018. 2, 8
[41] Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu,Xiyang Dai, Lu Y uan, and Lei Zhang. Cvt: Introducing convolutions to vision transformers. arXiv preprint arXiv:2103.15808, 2021. 2
[42] Tete Xiao, Yingcheng Liu, Bolei Zhou, Y uning Jiang, and Jian Sun. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), pages 418–434, 2018. 1, 2
[43] Enze Xie, Wenhai Wang, Zhiding Y u, Anima Anandkumar,Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers.arXiv preprint arXiv:2105.15203, 2021. 2, 5, 8
[44] Haotian Yan, Zhe Li, Weijian Li, Changhu Wang, Ming Wu, and Chuang Zhang. Contnet: Why not use convolution and transformer at the same time? arXiv preprint arXiv:2104.13497, 2021. 2
[45] Minghao Yin, Zhuliang Yao, Y ue Cao, Xiu Li, Zheng Zhang,Stephen Lin, and Han Hu. Disentangled non-local neural networks. In European Conference on Computer Vision, pages 191–207. Springer, 2020. 2, 8
[46] Changqian Y u, Jingbo Wang, Changxin Gao, Gang Y u,Chunhua Shen, and Nong Sang. Context prior for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12416–12425, 2020. 2
[47] Fisher Y u and Vladlen Koltun. Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122, 2015. 1, 2
[48] Y uhui Y uan, Xilin Chen, and Jingdong Wang. Objectcontextual representations for semantic segmentation. In Computer Vision–ECCV 2020: 16th European Conference,Glasgow, UK, August 23–28, 2020, Proceedings, Part VI 16,pages 173–190. Springer, 2020. 8
[49] Y uhui Y uan, Lang Huang, Jianyuan Guo, Chao Zhang, Xilin Chen, and Jingdong Wang. Ocnet: Object context network for scene parsing. arXiv preprint arXiv:1809.00916, 2018.1, 8
[50] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2881–2890, 2017. 1, 2, 6, 8
[51] Hengshuang Zhao, Yi Zhang, Shu Liu, Jianping Shi,Chen Change Loy, Dahua Lin, and Jiaya Jia. Psanet: Pointwise spatial attention network for scene parsing. In Proceedings of the European Conference on Computer Vision (ECCV), pages 267–283, 2018. 2, 8
[52] Sixiao Zheng, Jiachen Lu, Hengshuang Zhao, Xiatian Zhu,Zekun Luo, Yabiao Wang, Yanwei Fu, Jianfeng Feng, Tao Xiang, Philip HS Torr, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6881–6890, 2021. 1, 2, 8
[53] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 633–641,2017. 2, 5