2020_WWW_Few-Shot Learning for New User Recommendation in Location-based Social Networks
[论文阅读笔记]2020_WWW_Few-Shot Learning for New User Recommendation in Location-based Social Networks
论文下载地址: https://doi.org/10.1145/3366423.3379994
发表期刊:WWW
Publish time: 2020
作者及单位:
- Ruirui Li UCLA [email protected]
- Xian Wu Univeristy of Notre Dame [email protected]
- Xiusi Chen UCLA [email protected]
- Wei Wang UCLA [email protected]
数据集: 正文中的介绍
- Yelp. from the Yelp challenge.
- For the Yelp dataset, we investigate the recommendation tasks in six large cities
- Foursquare The Foursquare dataset contains interactions between customers and businesses in Los Angeles and New York
代码:
- (作者文中给的)
其他:
其他人写的文章
- few-shot learning是什么
- Few-shot learning(少样本学习)和 Meta-learning(元学习)概述
简要概括创新点: 主要为了看Metric-Learning-based Few-Shot Learning,用地理信息推荐不是自己的领域。
- In this paper, we study the problem of potential new user recommendation in LBSNs. The main contributions of this work are as follows: (本文研究了LBSNs中 潜在的新用户推荐问题 。这项工作的主要贡献如下:)
- We decompose the geographical influence into geographical convenience and dependency. (我们将 地理影响 分解为 地理便利性 和 依赖性)
- The geographical convenience models the relative transportation efforts of a check-in, ( 地理上的便利性 模拟了check-in的 相关交通影响,)
- while the geographical dependency modeling makes our model neighborhood-aware. (而地理依赖 模型使我们的模型具有 邻域意识。)
- We apply meta-learning to location-based recommendation tasks and formulate the problem as metric-learning-based few-shot learning. (我们将 元学习 应用于基于位置的推荐任务,并将该问题描述为 基于度量学习 的 few-shot学习。)
ABSTRACT
- (1) The proliferation of GPS-enabled devices establishes the prosperity of location-based social networks, which results in a tremendous amount of user check-ins. (支持GPS的设备的激增建立了基于位置的社交网络的繁荣,这导致了大量的用户登录。)
- These check-ins bring in preeminent opportunities to understand users’ preferences and facilitate matching between users and businesses. (这些签到为了解用户偏好和促进用户与企业之间的匹配带来了绝佳的机会。)
- (2) However, the user check-ins are extremely sparse due to the huge user and business bases, which makes matching a daunting task. (然而,由于庞大的用户和业务基础,用户签入非常稀少,这使得匹配成为一项艰巨的任务。)
- (3) In this work, we investigate the recommendation problem in the context of identifying potential new customers for businesses in LBSNs. (在这项工作中,我们在为LBSNs中的企业 识别潜在新客户 的背景下研究推荐问题。)
- In particular, we focus on investigating the geographical influence, composed of geographical convenience and geographical dependency. (特别是,我们着重调查地理影响,包括 地理便利性 和 地理依赖性。)
- In addition, we leverage metric-learning-based few-shot learning to fully utilize the user check-ins and facilitate the matching between users and businesses. (此外,我们利用 基于度量学习的few-shot学习 来充分利用用户签入,并促进用户和企业之间的匹配。)
- To evaluate our proposed method, we conduct a series of experiments to extensively compare with 13 baselines using two real-world datasets. The results demonstrate that the proposed method outperforms all these baselines by a significant margin. (为了评估我们提出的方法,我们进行了一系列实验,使用两个真实数据集与13个基线进行了广泛比较。结果表明,该方法的性能明显优于所有这些基线。)
CCS CONCEPTS
• Information systems Location based services
KEYWORDS
Customer recommendation; self-attention; few-shot learning
1 INTRODUCTION
-
(1) As an increasingly popular application of location-based services, location-based social networks (LBSNs), such as Yelp and Instagram, attract millions of users to share their locations, resulting in a huge amount of user check-ins [25, 40]. (作为一种越来越流行的基于位置的服务应用,基于位置的社交网络(LBSN),如Yelp和Instagram,吸引了数百万用户分享他们的位置,导致大量用户登录[25,40]。)
- The availability of such unprecedented user check-ins brings in great opportunities to understand users’ preferences and help businesses identify new users as potential customers. (这种前所未有的用户签到服务为了解用户偏好、帮助企业将新用户识别为潜在客户带来了巨大的机会。)
- However, new user predictions in LBSNs suffer severely from data sparsity. (然而,LBSNs中的新用户预测受到数据稀疏性的严重影响。)
- Therefore, understanding customer preferences and making accurate predictions from the severely sparse data remain a daunting task. (因此,了解客户偏好并从极其稀疏的数据中做出准确预测仍然是一项艰巨的任务。)
-
(2) To compensate for the sparse data, various ancillary information, such as geographical influence, social correlations, and temporal patterns, has been leveraged to improve recommendation performances in different manners [4, 10, 19, 21, 29, 35, 38]. (为了补偿稀疏数据,各种辅助信息(如 地理影响 、 社会关联 和 时间模式 )被用来以不同的方式提高推荐性能[4、10、19、21、29、35、38]。)
- For LBSNs, the geographical coordinates, i.e., the latitude and longitude, of businesses are the most accessible ancillary information and they are also the ones that make location-based recommendations unique compared to other recommendation tasks. (对于LBSN来说,企业的 地理坐标(即经纬度) 是最容易访问的辅助信息,它们也是使基于位置的推荐比其他推荐任务更独特的信息。)
- However, most existing works only investigate the relationship between users and businesses by measuring the distance of a visit between them. (然而,大多数现有的研究只是通过测量用户和企业之间的访问距离来研究它们之间的关系。)
- This leads to two inherent limitations. (这导致了两个固有的局限性)
- First, distance may not be an accurate indicator to distinguish the transportation convenience for different users for a check-in. (首先,距离可能不是区分不同用户的 交通便利程度 的准确指标。)
- Second, the inter-dependencies among nearby businesses are not well modeled when making recommendations. (其次,在提出建议时, 附近企业之间的相互依赖关系 没有得到很好的建模)


-
(3) In this work, we highlight that both geographical convenience and dependency should be incorporated in order to comprehensively express the geographical influence. (在这项工作中,我们强调,为了全面表达 地理影响,应该将 地理便利性 和 依赖性 结合起来。)
- Figure 1 and Figure 2 show two motivating examples for geographical convenience and dependency, respectively. (图1和图2分别显示了地理便利性和依赖性的两个激励示例。)
- In Figure 1, the two users are both 5 miles away from business A. But the distance indicator does not offer too much disciminative power to tell who is more likely to visit from the geographical perspective. If we know that user 1 tends to drive while user 2 relies on walking, we could gauge the actual transportation efforts more accurately based on the convenience rather than the raw distance. (在图1中,这两个用户都离business A有5英里远。但是距离指示器并没有提供太多的辨别能力,从地理角度来判断谁更有可能访问。如果我们知道用户1倾向于开车,而用户2依赖于步行,那么我们可以根据便利性而不是原始距离更准确地衡量实际的交通努力。)
- In Figure 2, two businesses A and B provide the same service and they are reachable for user u with equal transportation efforts. Without considering the neighborhood information of the two businesses, the recommendation system can barely distinguish one from the other regarding u’s preference. In real-world scenarios, the neighborhood services of two businesses are never the same [9]. If the neighborhood information is modeled when making recommendations, it can provide extra guidance to understand users’ decision-making processes more comprehensively and thus make more accurate recommendations. (在图2中,两个企业A和B提供相同的服务,用户u可以通过同样的运输努力到达它们。如果不考虑两家公司的邻居信息,推荐系统就很难区分u的偏好。在现实世界中,两家公司的社区服务从来都不一样[9]。如果在提出建议时对 社区信息 进行建模,它可以提供额外的指导,以便更全面地了解用户的决策过程,从而做出更准确的建议。)
-
(4) Beyond embracing geographical convenience and dependency to address the data sparsity issue, we also strive to seek more suitable techniques to fully utilize the user check-ins with the goal of improving recommendations in LBSNs. (除了利用地理便利性和依赖性来解决数据稀疏问题外,我们还努力寻求更合适的技术来充分利用用户签入,以改进LBSNs中的建议。)
- Few-shot learning aims to learn effectively from limited instances and has demonstrated notable performances in different domains [12, 36, 37]. (few-shot learning 旨在从有限的实例中有效学习,并在不同领域表现出显著的表现[12,36,37]。)
- In this work, we apply a metric-learning-based few-shot learning framework by optimizing two types of instances. (在这项工作中,我们通过优化两种类型的实例来应用 基于度量学习的 few-shot学习 框架。)
- More specifically, we construct support instances and query instances, with each instance composed of one user and one business. (更具体地说,我们构造 支持实例 和 查询实例 ,每个实例由 一个用户 和 一个业务 组成。)
- Support instances are labeled instances and serve as references. (支持实例 被 标记为实例 并用作 引用。)
- Query instances rely on the references to conduct reasoning. (查询实例 依赖 引用 进行 推理。)
- The model evolves by iterative reasoning between support and query instances. (该模型通过支持实例和查询实例之间的 迭代推理 进行演化。)
- In this way, the matching between a user and a business is optimized with explicit attention to multiple other related support instances. (通过这种方式,用户和企业之间的匹配得到了优化,并 明确关注 多个其他相关的支持实例。)
- Therefore, the limited check-ins are comprehensively utilized to make recommendations. (因此,综合利用有限的签入来提出建议。)
-
(5) In this paper, we study the problem of potential new user recommendation in LBSNs. The main contributions of this work are as follows: (本文研究了LBSNs中 潜在的新用户推荐问题 。这项工作的主要贡献如下:)
- We decompose the geographical influence into geographical convenience and dependency. (我们将 地理影响 分解为 地理便利性 和 依赖性)
- The geographical convenience models the relative transportation efforts of a check-in, ( 地理上的便利性 模拟了check-in的 相关交通影响,)
- while the geographical dependency modeling makes our model neighborhood-aware. (而地理依赖 模型使我们的模型具有 邻域意识。)
- We apply meta-learning to location-based recommendation tasks and formulate the problem as metric-learning-based few-shot learning. (我们将 元学习 应用于基于位置的推荐任务,并将该问题描述为 基于度量学习 的 few-shot学习。)
- We present an empirical evaluation of our approach against 13 recommendation methods on two real-world datasets. The results show that our approach outperforms all baseline methods in suggesting potential new users in different cities. (在两个真实数据集上,我们针对13种推荐方法对我们的方法进行了实证评估。结果表明,我们的方法在建议不同城市的潜在新用户方面优于所有基线方法。)
- We decompose the geographical influence into geographical convenience and dependency. (我们将 地理影响 分解为 地理便利性 和 依赖性)
2 PROBLEM FORMULATION & SETTING
-
(1) In this work, user check-ins are represented as a collection of tuples { ( b , u ) } ⊆ B × U \{(b,u)\} \subseteq B \times U {(b,u)}⊆B×U, (在这项工作中,用户check-ins被表示为元组的集合)
- where B B B and U U U are the business set and user set, respectively. (分别是业务集和用户集。)
- The task of new user recommendation is to rank users given a business. (新用户推荐的任务是对 给定业务 的 用户进行排名。)
- The goal is to rank the true new users higher than other candidates. (目标是让真正的新用户排名高于其他候选人。)
- The candidates here are all users who have not checked in this business. (这里的候选者都是尚未登记此业务的用户。)
-
(2) As we mentioned in the introduction, few-shot learning can fully utilize the training instances, which could potentially improve the recommendation performance. (正如我们在引言中提到的,few-shot学习能够充分利用训练实例,这可能会提高推荐性能。)
- Therefore, we formulate the user recommendation task as a metric-learning-baesd few-shot learning problem in this work. (因此,在这项工作中,我们将用户推荐任务描述为一个基于度量学习 的 few-shot learning 问题。)
- Following the few-shot learning settings in [26, 28, 34], we assume access to a set of training tasks, where each training task T T T corresponds to the new user predictions regarding a business b b b. (按照[26,28,34]中的few-shot学习设置,我们假设可以访问一组训练任务,其中 每个训练任务 T T T对应于关于业务 b b b的新用户预测 。)
- During training, we aim to learn a generalized similarity metric to compare a set of user-business tuples against some references for each task, with each task designed to simulate the few-shot setting. (在训练期间,我们的目标是学习 一个广义的相似性度量 ,将 一组用户业务元组 与每个任务的一些 引用进行比较,每个任务都设计为模拟few-shot设置。)
- Tasks are optimized one after another multiple times. (任务被一个接一个地优化多次。)
- For each task, each time k k k observed check-in tuples are randomly sampled as references, denoted as R R R. (对于每个任务,每次k个观察到的check-in元组被 随机抽样 作为 参考,表示为 R R R。)
- An observed check-in tuple refers to a business-user pair ( b , u ) (b,u) (b,u) (观察到的check-in元组指的是业务用户对)
- where the user u u u did check in business b b b in the dataset. (用户 u u u在数据集中签入业务 b b b。)
- In addition, two query sets, i.e., a positive query set Q + Q^+ Q+ and a negative query set Q − Q^− Q−, are constructed, with each set made up of c c c tuples. (此外,还有两个查询集,即正查询集 Q + Q^+ Q+和负查询集 Q − Q^- Q−, 构造,每个集合由 c c c元组组成。)
- Each query in Q + Q^+ Q+ is also an observed check-in tuple regarding b b b, but distinct from the ones in R R R. ( Q + Q^+ Q+中的每个查询也是一个关于 b b b的观察到的check-in元组,但不同于 R R R中的查询 。)
- Each query in Q − Q^− Q− is a fake check-in tuple, where the user in the tuple did not check in b b b. ( Q − Q^− Q−中的每个查询是一个假check-in元组,元组中的用户没有签入 b b b。)
- The model thus can be optimized by comparing two types of similarities, (因此,可以通过比较 两种相似性 来优化模型)
- one between a positive query and references, (一个介于 肯定询问 和 参考 之间,)
- and the other one between a negative query and reference for each business. (另一个是对每项业务的 否定查询 和 引用。)
- Ranking loss is applied to conduct the model optimizations, (应用 排名损失 进行模型优化)
- where the ranking loss measures how well the model distinguishes a positive query from a negative query regarding a set of references. (其中,排名损失 衡量模型在多大程度上区分 了一组引用的 肯定查询 和 否定查询。)
- The optimizations run for multiple iterations and each business is optimized more than one times. (优化运行了多次迭代,每个业务都优化了不止一次。)
- Note that for each optimization of a business, we may select different observed check-ins as references and positive queries. (请注意,对于业务的每次优化,我们可能 会选择不同的观察到的签入 作为 参考 和 肯定查询 。)
- Similarly, we may construct different fake check-ins as negative queries. (类似地,我们可以将 不同的假check-in 构造为 否定查询。)
- Once trained, the embeddings of all observed check-ins regarding the same business are expected close to each other in the hidden space, (一旦经过培训,所有观察到的关于同一业务的签到 都会 在隐藏空间中彼此靠近,)
- while the embedding of a fake check-in is expected far away from the embeddings of observed check-ins. (而 伪签入的嵌入 与 观察到的签入的嵌入相去甚远。)
3 METHODOLOGY
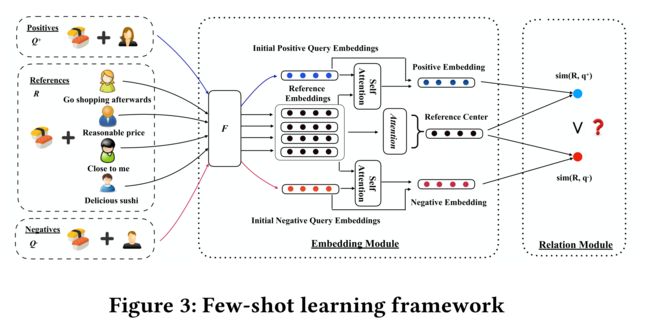
-
(1) In this section, we explain how to model the recommendation task as few-shot learning and how to incorporate geographical convenience and dependency in detail. (在本节中,我们将详细解释如何将推荐任务建模为 few-shot学习,以及如何结合 地理便利性 和 依赖性 。)
-
(2) The proposed approach decomposes the recommendation problem into a set of tasks and each task involves the user recommendations with respect to only one business. (该方法将推荐问题分解为一组任务, 每个任务 只涉及一个业务 的用户推荐。)
- Figure 3 shows the few-shot learning framework for each task. (图3显示了每个任务的few-shot学习框架。)
- On the left side, a reference set R R R and two query sets, a positive query set Q + Q^+ Q+ and a negative query set Q − Q^− Q−, are constructed for a business b b b. (左侧是一个参考集 R R R和两个查询集,一个正查询集 Q + Q^+ Q+和一个负查询集 Q − Q^− Q−, 是为商业 b b b设计的。)
- The reference set is composed of k k k random observed check-ins, where k = 4 k = 4 k=4 in this example. (参考集由k个 随机观察的 签入组成,在本例中,k=4。)
- The positive query set is made up of another random selection of c c c observed check-ins. (肯定查询集由另一个 随机选择 的 c c c 观察到的 签入组成。)
- But the check-ins in Q + Q^+ Q+ are mutually exclusive alternatives from the ones in R. (但是, Q + Q^+ Q+中的签入与 R R R中的签入是 互斥的 。)
- For illustration simplicity, c c c is set to 1 in the example. (为便于说明,本例中 c c c设置为1。)
- The negative query set is constructed by building c c c user-business tuples, such that each user in the tuple does not check in business b b b. (否定查询集是通过构建 c c c用户业务元组来构建的,这样元组中的每个用户都没有check-in业务 b b b。)
- The reference set functions as the supports in the setting of few-shot learning. The two query sets, based on the reference set, jointly conduct reasoning and inference. (参考集在few-shot学习设置中起到 支持 作用。这两个查询集基于参考集,共同进行推理和推理。)
- Figure 3 shows the few-shot learning framework for each task. (图3显示了每个任务的few-shot学习框架。)
-
(3) The framework has two modules, an embedding module and a relation module. (该框架包括两个模块,一个 嵌入模块 和一个 关系模块 )
- The embedding module learns the representations of references and queries, (嵌入模块学习引用和查询的表示,)
- while the relation module compares the learnt representations and optimize them in such a manner that (而关系模块则比较学习到的表达,并以如下方式对其进行优化:)
- representations of positive queries are similar to the ones of references, ( 肯定查询 的表示与引用的表示 类似 ,)
- while representations of negative queries are dissimilar to the ones of references. (而 否定查询 的表示与引用的表示 不同。)
- In the embedding module, F ( ⋅ ) F(·) F(⋅) is a layer which learns the initial embeddings of reference, positive query, and negative query tuples. (在嵌入模块中, F ( ⋅ ) F(⋅) F(⋅) 是一个学习引用、肯定查询和否定查询元组的 初始嵌入 的层。)
- By going through F F F, each reference/positive/negative tuple is represented by a fixed-length vector. (通过 F F F,每个引用/正/负元组由 一个固定长度的向量 表示。)
- Attention is a layer which utilizes the attention mechanism to learn the representative of the references. (注意是利用注意机制学习 参考表示 的一个层。)
- Self Attention is another attention layer, which takes both initial query and reference embeddings as inputs to generate the relative embeddings for queries. (自我注意是另一个注意层,它以初始查询和引用嵌入为输入,生成查询的 相对嵌入。)
- The relative embedding of a query learns to use references to explain the user check-in behavior encoded in the query. (查询的相对嵌入学习使用 参考 来解释查询中编码的用户签入行为。)
- In the relation module, based on the learnt embeddings, we match each query in the query set to the reference representative by calculating the similarity between them, denoted as s i m ( R , q ) sim(R,q) sim(R,q). (在关系模块中,基于学习到的嵌入,我们通过 计算它们之间的相似性 ,将查询集中的每个查询 匹配 到参考表示,表示为 s i m ( R , q ) sim(R,q) sim(R,q)。)
- Then, we compare the score s i m ( R , q + ) sim(R, q^+) sim(R,q+) of a positive query q + q^+ q+ with the score s i m ( R , q − ) sim(R, q^−) sim(R,q−) of a negative query q − q^− q−. (然后,我们将正面查询 q + q^+ q+的分数 s i m ( R , q + ) sim(R, q^+) sim(R,q+)与 一个否定的查询 q − q^− q−分数 s i m ( R , q − ) sim(R, q^−) sim(R,q−)进行比较)
- Ranking loss is generated if a negative query is more similar to the reference representative than a positive query is. ( 如果否定查询比肯定查询更类似于参考代表,则会产生 排名损失。)
- The model gets optimized by minimizing such ranking loss. ( 该模型通过最小化这种排名损失得到优化 。)
-
(4) Given a tuple ( b , u ) (b,u) (b,u), F ( ⋅ ) F(·) F(⋅) encodes four types of features: (给定一个元组 ( b , u ) (b,u) (b,u), F ( ⋅ ) F(⋅) F(⋅) 对四种类型的功能进行编码:)
- (1) business features, which represent its service, quality, and other business self-related factors; (代表其服务、质量和其他业务自身相关因素的 商务特征;)
- (2) user features, which represent his/her preference; (代表用户偏好的 用户特征;)
- (3) features indicating the geographical convenience of b b b for user u u u; and (显示 b b b对用户 u u u的 地理便利性 的功能)
- (4) features indicating the geographical dependencies of b b b, i.e., the neighborhood information of b b b. (表示 b b b的 地理依赖性 的特征,即 b b b的 邻域 信息。)
-
These four types of features collectively express how likely the user u u u will check in the business b b b. (这四种类型的特性共同表示用户 u u u签入业务 b b b的可能性。)

-
(5) Figure 4 illustrates the initial embedding construction for a user-business tuple. (图4展示了用户业务元组的 初始嵌入 构造。)
- Given a tuple, two vectors, a user embedding vector and a business embedding vector, are utilized to encode user preferences and business self-related features, respectively. (给定一个元组,两个向量,一个 用户嵌入向量 和一个 业务嵌入向量 ,分别用于编码 用户偏好 和 业务自相关特征。)
- A geographical convenience vector is constructed by considering the geographical location of the business and the historical check-in locations of the user. (通过考虑 商业的地理位置 和 用户的历史入住位置 ,构建 地理便利向量。)
- A geographical dependency vector is constructed to encode the neighborhood information of the business. (构造了一个 地理依赖向量 来编码 商业的邻域信息 。)
- These four types of information are concatenated together and then fed into a fully-connected neural network to derive the initial embedding of a user-business tuple. (这四种类型的信息 连接在一起,然后输入一个全连接的神经网络,以获得用户业务元组的初始嵌入。)
3.1 Geographical Convenience Modeling (Ruirui Li2019的论文,有这方面的工作)
-
(1) We follow [11] and discuss how to model the geographical convenience of a business b b b for a user u u u based on u u u’s historical check-ins. (我们遵循[11]并讨论如何基于 u u u的历史签入为用户 u u u建模业务 b b b的地理便利性。) ([11]Ruirui Li, Jyunyu Jiang, Chelsea Ju, and Wei Wang. 2019. CORALS: Who are My Potential New Customers? Tapping into the Wisdom of Customers’ Decisions. In WSDM ’19, Melbourne, Australia, February 11-15, 2019.)
-
(2) Gaussian mixture model [23] is applied to model the convenience. A Gaussian mixture model is a weighted aggregation of M M M component Gaussian densities: (采用 高斯混合模型 [23]进行建模。高斯混合模型是 M M M分量高斯密度的加权聚合:)

- where l l l is the location vector, (是位置向量)
- α m \alpha_m αm is the mixture weight, (是混合权重)
- and g ( l ∣ μ m , ∑ m ) g(l|\mu_m,\sum_m) g(l∣μm,∑m) are the component Gaussian densities. (是高斯密度的分量)
-
(3) Each component density is a 2-variate Gaussian function. Formally, (每个分量密度是一个 二元高斯函数 。正式地)

- where Φ \Phi Φ is the mean location vector (是平均位置向量)
- and ∑ m \sum_m ∑m gives the covariance. (给出协方差)
-
(4) The complete Gaussian mixture model is parameterized by the mean location vectors, covariance matrices and mixture weights from all mixture components. Φ \Phi Φ is used to denote these parameters. ( 完全高斯混合模型 由所有混合分量的 平均位置向量 、 协方差矩阵 和 混合权重 参数化。)
- Φ \Phi Φ is used to denote these parameters. ( Φ \Phi Φ用于表示这些参数)
-
For a particular customer, given a set of his historical T T T check-ins, represented by T T T location vectors L = { l 1 , . . , l T } L = \{l_1, ..,l_\mathcal{T}\} L={l1,..,lT}, the GMM likelihood is given by: (对于特定的客户,给定一组历史 T T T个签入,由 T T T个位置向量 L = { l 1 , . . , l T } L = \{l_1, ..,l_\mathcal{T}\} L={l1,..,lT}, GMM可能性由下式给出:)

-
(5) We use the Expectation-Maximization algorithm [2] to estimate the parameters. (我们使用期望最大化算法[2]来估计参数。)
- After the GMM construction for a customer u u u, given the geographical location l b l_b lb of a business b, as shown in Equation 1, p ( l b ∣ Φ ) p(l_b | \Phi) p(lb∣Φ) gives the geographical convenience of the business b b b for user u u u. (在为客户 u u u构建GMM后,考虑到地理位置 l b l_b lb,如等式1所示, p ( l b ∣ Φ ) p(l_b | \Phi) p(lb∣Φ)为用户 u u u提供了商业 b b b的地理便利 。)
- We highlight that the geographical convenience, modeled by GMM, is superior to conventional distance-based metrics, since it captures the relative efforts of a visit, which is capable of distinguishing customers with different traveling flexibility more accurately. (我们强调,GMM建模的 地理便利性 优于 传统的基于距离的指标,因为它捕获了访问的相对影响,能够更准确地区分 具有不同出行灵活性 的客户。)
3.2 Geographical Dependency Modeling
-
(1) In this section, we show how to encode geographical neighborhood information using graphs and how to model the dependence relationship among businesses using graph convolutional networks [8]. (在本节中,我们将展示如何使用图对 地理邻域信息 进行编码,以及如何使用 图卷积网络 建模企业之间的 依赖关系 [8])
-
(2) The geographical correlations among businesses are modeled with a graph G = ( V , E ) G = (V, E) G=(V,E), which encodes the geographical proximity. (企业之间的 地理相关性 用一个图 G = ( V , E ) G = (V, E) G=(V,E)建模,该图对 地理邻近性 进行编码。)
- Each vertex v ∈ V v \in V v∈V represents a business (代表商业)
- and an edge e ∈ E e \in E e∈E with weight e − λ ( v i , v j ) e^{−λ(vi_, v_j)} e−λ(vi,vj) connects every two vertices v i v_i vi and v j v_j vj, (连接每两个顶点连接 v i v_i vi和 v j v_j vj)
- where λ ( v i , v j ) λ(v_i, v_j) λ(vi,vj) gives the geographical distance between v i v_i vi and v j v_j vj. (给出了 v i v_i vi和 v j v_j vj之间的地理距离)
- Formally, an adjacency matrix A A A is used to represent G G G with A i , j = e − λ ( v i , v j ) A_{i,j} = e^{−λ(v_i, v_j)} Ai,j=e−λ(vi,vj).
-
(3) Graph convolutional network (GCN) is defined over the proximity graph, which allows us to extract and aggregate neighborhood information for each vertex. A graph convolution is defined as: ( 图卷积网络(GCN) 是在 邻近图 上定义的,它允许我们提取和聚合每个顶点的 邻域信息 。图卷积 定义为:)

- with A ^ = A + I \hat{A} = A + I A^=A+I,
- where I I I is the Identify matrix, which is added to capture business’ own features during feature propagations. (其中 I I I是 鉴别矩阵 ,用于在特征传播期间 捕获企业自身的特征 。)
- D D D is the diagonal node degree matrix of A ^ \hat{A} A^. ( D D D是 A ^ \hat{A} A^的 对角节点度矩阵。)
- W ( β ) W^{(β)} W(β) is the weight matrix for the β β β-th layer in GCN, (是GCN中 β β β-th层的权重矩阵,)
- and H β H^β Hβ is the output for the β β β-th layer. (是 ′ b e t a 'beta ′beta-th层的输出)
- with A ^ = A + I \hat{A} = A + I A^=A+I,
-
(4) In particular, H ( 0 ) = X H^{(0)} = X H(0)=X and H ( β ~ ) = Z H^{(\tilde{β})}= Z H(β~)=Z,
- where X X X is the initial vertex feature matrix, (是初始顶点特征矩阵)
- Z Z Z is the final outputs of GCN, (是GCN的最终输出,)
- with β ~ \tilde{β} β~ indicating the number of layers in GCN. (指示GCN中的层数。)
-
(5) For example, H i 0 H^0_i Hi0 represents the initial features of business i i i. (代表商业 i i i的初始特征。)
- By going through GCN, the information of i i i’s neighbors gets propagated to H i β H^β_i Hiβ. (通过GCN, i i i的 邻居的信息 被传播到 H i β H^β_i Hiβ.)
- Therefore, H i β H^β_i Hiβ not only represents the information of business i i i, but also that of its nearby neighbors. (不仅代表商业i的 信息 ,还代表其 附近邻居的信息 )

-
(6) Algorithm 1 summarizes the training process. (算法1总结了训练过程)
- For each training epoch, we go through the tasks one by one. (对于每个训练阶段,我们都会逐一完成任务。)
- For each task, we aim to distinguish positive queries from negative queries regarding references. (对于每个任务,我们的目标是区分关于参考的肯定查询和否定查询。)
- For a business b b b, we (对于商业 b b b,我们)
- first sample a set of k k k observed check-ins as the reference set, R = { ( b , u 1 r ) , . . . , ( b , u k r ) } R = \{(b,u^r_1), ..., (b, u^r_k)\} R={(b,u1r),...,(b,ukr)}. (首先,将一组 k k k个观察到的签入作为参考集)
- Then, we sample another set of c c c exclusive observed check-ins as the positive query set, Q + = { ( b , u 1 + ) , . . . , ( b , u c + ) } Q^+= \{(b,u^+_1), ...,(b, u^+_c)\} Q+={(b,u1+),...,(b,uc+)}. (然后,我们将另一组 c c c个 额外观察到的 签入作为正向查询集进行采样)
- We also construct a third set of c c c fake check-ins as the negative query set, Q − = { ( b , u 1 − ) , . . . , ( b , u c − ) } Q^−= \{(b,u^−_1), ..., (b,u^−_c)\} Q−={(b,u1−),...,(b,uc−)}.
- After the constructions of references, positive and negative queries, we calculate the similarity between each query in Q + ∪ Q − Q^+\cup Q^− Q+∪Q− and the references. (在构造引用、正查询和负查询之后,我们计算每个查询 Q + ∪ Q − Q^+\cup Q^− Q+∪Q−和参考之间的相似度)
- We expect that positive queries are closer to references, (我们希望 肯定的查询 更 接近 参考)
- while negative queries are faraway from references in the hidden space. (而 否定查询 则 远离 隐藏空间中的引用。)
- The representations of queries and references are learnt through two attention mechanisms. (查询和引用的表示通过 两种注意机制学习。)
- The closeness/similarity between a query and a set of references is calculated by comparing the query embedding with the embedding of the reference representative. (通过比较查询嵌入与参考代表的嵌入,计算查询与一组参考之间的接近度/相似性。)
- For each optimization of a business, we randomly pair up positive queries with negative queries. (对于业务的每一次优化,我们都会 随机将正面查询与负面查询配对 。)
- Ranking loss is adopted if a negative query is closer to the references than a positive query is. (如果否定查询比肯定查询更接近引用,则采用排名损失。)
- In the following paragraphs, we discuss the representation learning of both queries and references, the query-reference similarity calculation, and the ranking loss function in detail sequentially. (在下面的段落中,我们将依次详细讨论查询和参考的表示学习、查询参考相似度计算和排名损失函数。)
3.2.1 Query embedding:
-
(1) the query embedding is constructed by incorporating two types of information. (查询嵌入是通过合并两种类型的信息来构建的)
- One encodes the user business interaction behavior itself (一种是对用户业务交互行为本身进行编码)
- and the other one encodes the representation with attention to the references. (而另一个则通过对参考的引用对表示进行编码。)
- In other words, we attempt to use references to explain the user business interaction behavior in the query. (换句话说,我们试图使用参考来解释查询中的用户业务交互行为。)
- F(·) in Figure 3 yields the first part, while the second part is achieved by introducing a self-attention mechanism. (图3中的 F(·)产生第一部分,而第二部分是通过引入自我注意机制实现的。)
- The scaled dot-product attention [27] is defined as: (按 比例调整的点积注意力 [27]定义为:)

- where Q ~ \tilde{Q} Q~, K ~ \tilde{K} K~, and V ~ \tilde{V} V~ represent the queries, keys, and values in the attention mechanism, respectively. (分别表示注意机制中的查询、键和值)
- The attention operation calculates a weighted sum of all values, where the weight between query i i i and value j j j relates to the interaction between query i i i and key j j j. (注意操作计算所有值的加权和,其中查询 i i i和值 j j j之间的权重与查询 i i i和键 j j j之间的交互有关。)
- d Q d_Q dQ is the feature dimension of Q ~ \tilde{Q} Q~ (是 Q ~ \tilde{Q} Q~的特征维度)
- and d Q \sqrt{d_Q} dQ serves as a scale factor. (用作比例因子)
-
(2) In our case, the self-attention operation takes the query embeddings Q ∈ R c × d Q \in R^{c×d} Q∈Rc×d and the reference embeddings R ∈ R k × d R \in R^{k×d} R∈Rk×d as inputs, converts them to three matrices through linear projections, and feeds them into an attention layer: (在我们的例子中,self-attention操作将查询嵌入 Q ∈ R c × d Q \in R^{c×d} Q∈Rc×d与参考嵌入 R ∈ R k × d R \in R^{k×d} R∈Rk×d作为输入,通过 线性投影 将其转换为三个矩阵,并将其输入到 注意层:)
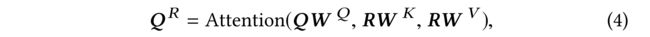
- where the projection matrices W Q W^Q WQ, W K W^K WK, and W V ∈ R d × d W^V \in R^{d×d} WV∈Rd×d. (其中 投影矩阵)
- The self-attention result Q R Q^R QR learns the embedding of a query by comparing the closeness between the query and all references. (自我关注结果 Q R Q^R QR通过比较查询和所有参考之间的接近度来学习查询的嵌入。)
- Q R Q^R QR is a weighted sum of reference embeddings, where each weight gauges the behavior similarity between the query and a reference. (是参考嵌入的加权和,其中每个权重衡量查询和参考之间的 行为相似性 。)
- In this way, Q R Q^R QR encodes the user-business behavior of the query explained by references. (编码由参考解释的查询的用户业务行为。)
- We employ residual shortcut connection [5] to derive the final representations for queries Q Q Q, denoted as Q c o m Q^{com} Qcom, as follows: (我们使用残差直连[5]来推导查询 Q Q Q的最终表示,表示为 Q c o m Q^{com} Qcom,如下所示:)
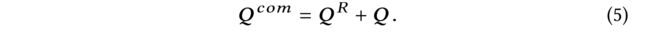
3.2.2 Reference embedding:
-
(1) for the references, we calculate the reference representative R ˉ \bar{R} Rˉ as a weighted sum of each reference, where the weights can be derived from a second attention mechanism.
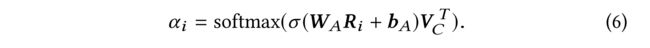

-
(2) Equations 6 and 7 summarize the representative calculation.
- Each reference R i Ri Ri is first fed into a one-layer neural network, the outputs of which, together with the context vector V C V_C VC, are further used to generate the importance weight α i \alpha_i αi for each reference R i R_i Ri through a softmax function. (每个参考 R i Ri Ri首先被送入一个 单层神经网络 ,其输出与上下文向量 V C V_C VC一起 , 进一步用于生成重要性权重 α i \alpha_i αi,对于每个参考 R i R_i Ri,通过softmax函数。)
- The representative R ˉ \bar{R} Rˉ is calculated as a weighted sum of the references based on the derived weights. (表征 R ˉ \bar{R} Rˉ根据导出的权重作为 参考的加权和 进行计算。)
3.2.3 Similarity and loss function:
- (1) Given a set of references R R R and a query q q q, the similarity s i m ( R , q ) sim(R,q) sim(R,q) between R R R and q q q is defined as the dot product between R ˉ \bar{R} Rˉ and q c o m q^{com} qcom. Formally, (给定一组参考 R R R和一个查询 q q q, R R R和 q q q之间的相似性 s i m ( R , q ) sim(R,q) sim(R,q),定义为 R ˉ \bar{R} Rˉ and q c o m q^{com} qcom之间的点积。正式地)
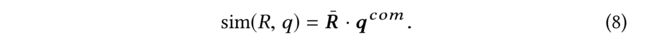
- (2) We apply hinge loss to gauge the ranking error defined on references R R R, a positive query q + q^+ q+, and a negative query q − q^− q−: (我们应用铰链损失来衡量参考 R R R、正查询 q + q^+ q+和负查询 q − q^- q−上定义的 排名误差 )
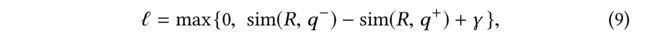
- where γ \gamma γ is the margin. (其中 γ \gamma γ是边缘)
- Losses are generated only when the negative query is closer to the references than the positive query regarding a margin γ \gamma γ. (只有当关于保证边缘 γ \gamma γ的否定查询比肯定查询更接近参考时,才会产生损失。)
4 EXPERIMENTS
In this section, we conduct extensive experiments on two real-world datasets to evaluate the performance of the proposed method. (在本节中,我们在两个真实数据集上进行了大量实验,以评估所提出方法的性能)
4.1 Datasets and Experimental Settings
- (1) The experiments are conducted on two datasets. (实验在两个数据集上进行。)
- One is the dataset from the Yelp challenge. (一个是来自Yelp挑战的数据集。)
- The other is the Foursquare dataset. (另一个是Foursquare数据集。)
- For the Yelp dataset, we investigate the recommendation tasks in six large cities. (对于Yelp数据集,我们调查了六个大城市的推荐任务。)
- The Foursquare dataset contains interactions between customers and businesses in Los Angeles and New York. (Foursquare数据集包含洛杉矶和纽约的客户和企业之间的互动。)
- Table 1 shows the statistics for the eight cities in the two datasets. (表1显示了两个数据集中八个城市的统计数据)

4.2 Baselines
-
(1) To compare our approach with others, the following 13 methods are adopted as baselines. (为了与其他方法进行比较,我们采用了以下13种方法作为基线。)
-
(2) The proposed method, which utilizes SElf-Attention and few-shoT LEarning, is denoted as SEATLE. (该方法利用了自我注意和few-shot学习,被称为SEATLE。)
-
(3) Recommendation methods without considering geographical influence: (不考虑地理影响的推荐方法:)
- WRMF minimizes the square error loss by assigning both observed and fake check-ins with different weights [7]. (通过使用不同的权重分配 观察到的 和 虚假的 签入,将 平方误差损失 降至最低[7]。)
- MMMF minimizes the hinge loss based on matrix factorization [31]. (基于矩阵分解将铰链损失降至最低[31]。)
- BPRMF optimizes pairwise bpr losses of observed check-ins and sampled fake check-ins [22]. (优化观察到的签入和抽样的假签入的成对bpr损失[22]。)
- CofiRank, [30] optimizes the estimation of a ranking loss based on normalized discounted cumulative gain. (基于NDCG优化了排名损失的估计。)
- CLiMF, [24] optimizes a different ranking-oriented mean reciprocal rank loss. (优化不同的排名为导向的平均倒数排名损失。)
-
(4) Conventional methods with geographical influence involved: (涉及地理影响的常规方法:)
- USG, [39] is a collaborative filtering method. It utilizes distances between users and businesses as extra guidance to conduct recommendations. (是一种协同过滤方法。它利用用户和企业之间的距离作为进行推荐的额外指导。)
- GeoMF, [16] explicitly learns user activity areas (distance-based) and business influences areas via matrix factorization. (通过矩阵分解明确了解用户活动区域(基于距离)和业务影响区域。)
- Rank-GeoFM, ranking-based geographical factorization [14] incorporates business neighborhood information via matrix factorization. (基于排名的地理因子分解[14]通过矩阵因子分解将商业邻域信息结合起来。)
- ASMF, [10] mainly leverages social network information to improve recommendations. (主要利用社交网络信息改进推荐。)
- ARMF, [10] extends ASMF by further optimizing ranking losses. (通过进一步优化排名损失扩展ASMF。)
- CORALS, [11] models geographical convenience and business reputation to improve recommendations. (模拟地理便利性和商业声誉,以改进建议。)
-
(5) Deep learning methods with geographical influence involved: (涉及地域影响的深度学习方法:)
- SAE-NAD, self-attentive encoder and neighbor-aware decoder [21] applies auto-encoders to make recommendations. (自我关注编码器和邻居感知解码器[21]应用自动编码器提出建议。)
- PACE, preference and context embedding [35], a deep neural architecture that jointly learns the embeddings of users and businesses by building a context graph. (偏好和上下文嵌入[35],一种深度神经架构,通过构建上下文图,共同学习用户和企业的嵌入。)
4.3 Recommendation Performance
-
(1) In this section, we evaluate the performances of SEATLE against the 13 baseline methods.
-
Mean Average Precision (MAP) is adopted as the evaluation metric, which is also used in [10, 11, 13].
-
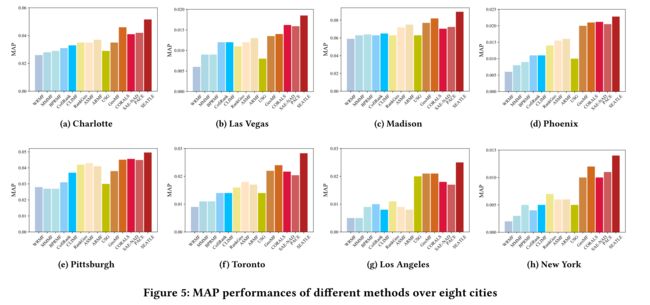
(2) Figure 5 shows the recommendation performances of different methods on the eight cities from the two datasets. Figures from 5a to 5f show the performances based on the six cities in the Yelp dataset, while the last two Figures 5g and 5h show the performances based on the two cities in the Foursquare dataset. (图5显示了两个数据集中八个城市不同方法的推荐性能。5a到5f的图显示了Yelp数据集中六个城市的性能,而最后两个图5g和5h显示了Foursquare数据集中两个城市的性能。)
-
(2) Among methods which do not consider geographical influence, MMMF, BPRMF, CofiRank, and CLiMF achieve better recommendation performances than WRMF in general. This demonstrates that point-wise methods, such as WRMF, which achieve low prediction errors, do not necessarily have high recommendation accuracy. In other words, directly optimizing the predicted check-ins may not provide the best recommendation lists to businesses. (在不考虑地理影响的方法中,MMMF、BPRMF、FECORANK和GILF一般比WRMF具有更好的推荐性能。这表明,点式方法,如WRMF,可以实现较低的预测误差,不一定具有较高的推荐精度。换句话说,直接优化预测入住可能无法为企业提供最佳推荐列表。)
-
(3) After leveraging geographical influence, Rank-GeoMF, ASMF, ARMF, GeoMF, CORALS, SAE-NAD, and PACE outperform the five above methods, which do not incorporate any ancillary features. (在利用地理影响后,排名GeoMF、ASMF、ARMF、GeoMF、CORALS、SAE-NAD和PACE优于上述五种方法,它们不包含任何辅助功能。)
- It verifies that modeling ancillary information can offer extra guidance and compensate for the sparsity issue in location-based recommendation tasks. (验证了在基于位置的推荐任务中,建模辅助信息 可以提供额外的指导和补偿 稀疏性问题。)
- USG, with geographical influence modeled, does not perform as well as expected in some cities, such as Charlotte, Las Vegas, etc. (USG在模拟地理影响的情况下,在夏洛特、拉斯维加斯等城市的表现不如预期。)
- This is due to its oversimplified model design, which is a straightforward linear combination of user preference and geographical distance scores without proper optimizations. (这是因为它的模型设计过于简单,是用户偏好和地理距离分数的直接线性组合,没有适当的优化。)
- The performances of ASMF and ARMF on the foursquare dataset are not as good as it usually achieves on the Yelp dataset. ASMF and ARMF mainly focus on leveraging social network information. (ASMF和ARMF在foursquare数据集上的性能不如通常在Yelp数据集上实现的性能。ASMF和ARMF主要致力于利用社交网络信息。)
- This demonstrates that social network information may not always be reliable, while comprehensively utilizing geographical influence might be a better choice to improve performances in location-based recommendation tasks. (这表明社交网络信息可能并不总是可靠的,而综合利用地理影响可能是提高基于位置的推荐任务性能的更好选择。)
- In general, CORALS outperforms Rank-GeoMF, GeoMF, SAE-NAD, and PACE. This mainly results from the geographical convenience incorporated in CORALS rather than distance-based metrics employed in other models. (总的来说,CORALS的表现优于GeoMF、GeoMF、SAE-NAD和PACE。这主要是因为CORALS中融入了 地理便利性,而不是其他模型中采用的基于距离的指标。)
-
(4) Among the deep learning-based methods, SEATLE achieves the best performance. (在基于深度学习的方法中,SEATLE的性能最好。)
-
The reasons could be explained as follows. (原因可以解释如下。)
- PACE models the geographical influence by a context graph, which does not explicitly model the user reachability to businesses. (PACE通过上下文图对地理影响进行建模,上下文图没有明确地建模用户对企业的可达性。)
- SAE-NAD captures the geographical dependency through a neighbor-aware auto-encoder, but it fails to incorporate geographical convenience. (SAE-NAD通过邻居感知自动编码器捕获地理依赖性,但它未能结合地理便利性。)
-
In general, SEATLE outperforms all baseline methods in the eight cities over the two datasets. (总的来说,在这两个数据集上,SEATLE的表现优于八个城市的所有基线方法。)
-
SEATLE models both geographical convenience and dependency, which collaboratively express the power of geographical influence. (SEATLE对地理便利性和依赖性进行了建模,它们共同表达了地理影响力的力量。)
-
Moreover, SEATLE adopts few-shot learning, designed for learning with limited data, as the framework to fully utilize the sparse training instances. (此外,SEATLE采用了为有限数据学习而设计的少镜头学习作为框架,以充分利用稀疏的训练实例。)
-
These appropriate designs make SEATLE a good fit for new user recommendations in LBSNs. (这些合适的设计使SEATLE非常适合LBSNs中的新用户推荐。)
4.4 Geographical Influence Analysis
-
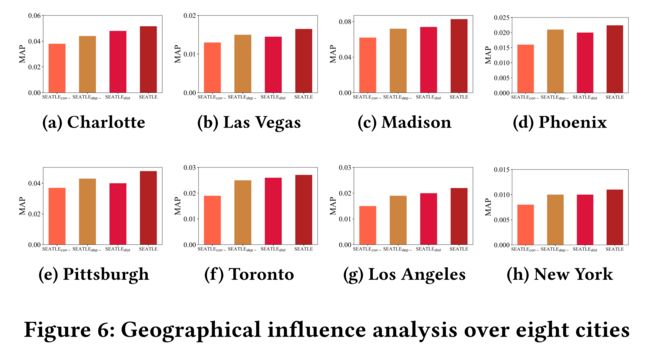
(1) In this section, we investigate the effectiveness of geographical convenience and dependency modelings. (在本节中,我们将研究 地理便利性 和 依赖性 建模的有效性。)
- We develop SEATLEcon− and SEATLEdep− by removing the convenience and dependency feature from SEATLE, respectively. (我们开发SEATLEcon− 还有SEATLEdep− 通过 删除分别来自SEATLE的便利性和依赖性功能。)
- To compare convenience-based and distance-based influence, we further develop SEATLEdist by replacing the convenience feature by a distance-based kernel metric, adopted from SAE-NAD. (为了比较基于便利性和基于距离的影响,我们进一步开发了SEATLEdist,用SAE-NAD中采用的基于距离的内核度量替换便利性特征。)
- More precisely, the metric is given by e x p ( γ ∣ l i − l j ∣ ) exp(\gamma |l_i − l_j| ) exp(γ∣li−lj∣), (更准确地说,度量是由)
- where l i l_i li and l j l_j lj are both location coordinates, (其中 l i l_i li和 l j l_j lj都是位置坐标)
- and γ \gamma γ is used to control the correlation level of the two locations. ( γ \gamma γ用于控制两个位置的相关性级别。)
- More precisely, the metric is given by e x p ( γ ∣ l i − l j ∣ ) exp(\gamma |l_i − l_j| ) exp(γ∣li−lj∣), (更准确地说,度量是由)
-
(2) Figure 6 shows the MAP performances. (图6显示了MAP性能。)
-
We observe that when the geographical convenience and dependency features are removed from SEATLE, MAP performance drops correspondingly. (我们观察到,当从SEATLE中删除地理便利性和依赖性特征时,地图性能会相应下降。)
-
The performance decreases more when eliminating geographical convenience as compared to eliminating geographical dependency. (与消除地理依赖性相比,在消除地理便利性时,性能下降更多。)
-
This observation applies to all eight cities. (这一观察结果适用于所有八个城市。)
-
Therefore, we can safely conclude that both geographical convenience and dependency modelings improve the recommendation performance and the geographical convenience contributes more. (因此,我们可以安全地得出结论,地理便利性和依赖性模型都可以提高推荐性能,而地理便利性的贡献更大。)
-
We further compare SEATLEdist and SEATLE. SEATLEdist models distance-based geographical features, while SEATLE is convenience-based. (我们进一步比较了SEATLEdist和SEATLE。SEATLEdist模型基于距离的地理特征,而SEATLE模型基于便利性。)
-
We notice that SEATLE outperforms SEATLEdist on all eight cities. (我们注意到SEATLE在所有八个城市的表现都优于SEATLEdist。)
-
This demonstrates the advantage of convenience-based geographical modeling since it gauge users’ actual transportation efforts more accurately. (这证明了基于便利性的地理建模的优势,因为它可以更准确地衡量用户的实际交通努力。)
5 RELATED WORK
-
(1) To address the check-in sparsity issue, various ancillary information is incorporated when building recommendation models, such as POI popularity, social influence, temporal patterns, textual and visual contents [3, 4, 6, 10, 15, 18, 29, 32, 33, 39, 41, 43]. In this part, we focus on investigating geographical influence oriented works. (为了解决签入稀疏性问题,在构建推荐模型时,加入了各种辅助信息,例如POI受欢迎程度、社会影响、时间模式、文本和视觉内容[3、4、6、10、15、18、29、32、33、39、41、43]。在这一部分中,我们重点考察 地理影响 导向的工作。)
-
(2) To leverage geographical influence to improve recommendation performances, (为了利用地理影响提高推荐绩效,)
- Cheng et al. [1] first detect multiple centers for each customer based on their check-in histories. Recommendations are made by referring to the distance between the location of the business and the nearest customer center. (Cheng等人[1]首先根据每位客户的入住历史为他们检测多个中心。建议是指企业所在地与最近的客户中心之间的距离。)
- In [39], geographical influence is modeled by a power-law distribution between the check-in probability and the pair-wise distance of two check-ins. (在[39]中,地理影响由签入概率和两次签入的成对距离之间的 幂律分布 建模。)
- [17, 42] utilize the kernel density estimation to study customers’ check-ins and avoid employing a specific distribution. (利用 核密度估计 来研究客户的签入,避免采用特定的分布。)
- [20] exploits geographical neighborhood information by assuming that customers have similar preferences on neighboring POIs and POIs in the same region may share similar user preferences. (通过假设客户对相邻的POI有相似的偏好,以及同一地区的POI可能共享相似的用户偏好,利用地理邻域信息。)
- PACE [35] explores the use of deep neural networks to learn location embeddings and user preferences over POIs. (探索使用深度神经网络来学习位置嵌入和用户对POI的偏好。)
- SAE-NAD [21] applies auto-encoder to learn POI recommendations. (应用自动编码器去学习POI推荐。)
- APOIR [44] employs an adversarial generative model to make POI recommendations. (采用对抗性生成模型做出POI推荐。)
- SACRA [13] constructs dynamic adversarial examples to make robust recommendations in LBSNs. (构建 动态对抗性示例 ,在LBSNs中提出稳健的建议。)
-
(3) The proposed method, SEATLE, differs from most of the above work. (提出的方法SEATLE不同于上述大多数工作。)
-
SEATLE models both geographical convenience and dependency. (SEATLE对地理便利性和依赖性进行了建模。)
-
Moreover, SEATLE employs few-shot learning to fully utilize the training instances and strives to improve recommendations from limited data. (此外,SEATLE使用少量的镜头学习来充分利用训练实例,并努力从有限的数据中提升推荐。)
6 CONCLUSION
- (1) In this work, we study the problem of recommending new users to businesses in LBSNs. (在这项工作中,我们研究了在LBSNs中向企业推荐新用户的问题。)
- We formulate the recommendation problem as a metric-learning-based few-shot learning problem in order to fully utilize the sparse training instances. (为了充分利用稀疏训练实例,我们将推荐问题描述为一个 基于度量学习的少样本学习问题。)
- We look into the geographical influence and decompose it into geographical convenience and geographical dependency modeling. (我们研究 地理影响,并将其分解为 地理便利 和 地理依赖 建模。)
- Extensive experiments are conducted, which demonstrates the effectiveness of SEATLE on two real-world datasets.