ICCV2021 SDR2HDR论文笔记:A New Journey from SDRTV to HDRTV
code: https://github.com/chxy95/HDRTVNet
本文是ICCV2021文章《A New Journey from SDRTV to HDRTV》的阅读笔记,个人认为该文章是sdr2hdr领域比较重要的一篇文章,其完成了视频sdr2hdr问题的定义、问题特性的分析、提出了一种方法、公开了一个数据集HDRTV1K、提出了5种评价指标,接下来记录了文章的要点。
1. introduction
-
为什么需要sdr2hdr算法?
(1) 视频内容正在从标清、高清向超高清发展,而高动态范围则是超高清内容的一个重要的特点
(2) 高动态范围视频所呈现出的内容更接近于人眼在自然场景中的感官
(3) 而随着支持高动态范围的设备越来越普及,但大部分视频内容仍是hdr格式
-
为什么这么重要,相关研究却这么少?
作者认为原因有两个:
(1)hdr10和hlg这些hdr标准最近才被定义好;
(2)缺少大规模数据集用于训练和测试;
-
分析了sdr2hdr与相关课题的关系
(1)sdr2hdr是高度病态的问题,他们具有不同的动态范围、色域和位深
In actual production, contents of SDRTV and HDRTV are derived from the same Raw file but are processed under different standards. Thus, they have different dynamic ranges, color gamuts and bit-depths.
在实际制作中,SDRTV和HDRTV的内容来源于同一个Raw文件,但处理的标准不同。因此,它们具有不同的动态范围、色域和位深度。(2) 在某种程度上,与image-to-image translation such as Pixel2Pixel [11] and CycleGAN有些相似
(3) ldr2hdr在名字上跟sdr2hdr相近,其实并不是一个东西,ldr2hdr旨在预测线性域中的HDR场景亮度,本质上更接近raw file
On the contrary, the task of LDR-to-HDR, which is similar in terms of name, has completely different connotations. LDR-to-HDR methods [21, 26, 10, 24, 5] aim to predict the HDR scene luminance in the linear domain, which is closer to Raw file in essence
(4) 同时进行超分和sdr2hdr的工作
Deep SR-ITM and JSI-GAN -
介绍evaluation metrics
PSNR: mapping accuracy
SSIM, SR-SIM [36]: structural similarity
∆E_ITP [17]: color difference
HDR-VDP3: visual quality
-
贡献
(1)对sdr2hdr问题进行了建模分析
(2)我们提出了一个三步 SDRTV-to-HDRTV解决方案法,在定量和定性比较中表现最好
(3)我们提出了一个全局色彩映射网络,只有35k参数量,效果最好
(4)提出了一个数据集,并为这个任务选择了五个性能指标
2. 前言
(1)sdr格式定义
ITU-R. Parameter values for the hdtv standards for production and international programme exchange. Technical re- port, ITU-R Rec, BT.709-6, 2015. 2
ITU-R. Reference electro-optical transfer function for flat panel displays used in hdtv studio production. Technical report, ITU-R Rec, BT.1886, 2011. 2
(2)hdr格式定义
wide color gamut
ITU-R. Parameter values for ultra-high definition televi- sion systems for production and international programme ex- change. Technical report, ITU-R Rec, BT.2020-2, 2015. 2
PQ or HLG OETF
ITU-R.Image parameter values for high dynamic range television for use in production and international programme exchange. Technical report, ITU-R Rec, BT.2100-2, 2018. 2, 3
与ldr2hdr问题的不同
ldr2hdr通常指的是摄影中的概念,完成的是线性光域的映射;sdr2hdr指的是sdr视频与对应的符合hdr标准的视频像素值之间的映射
3. 分析
接下来作者做了一系列比较有逻辑性的分析,梳理sdr/hdr视频制作的pipeline -> 建模sdr2hdr任务 -> 提出自己对sdr2hdr任务特性的见解 -> 根据这些见解抽象出自己的基于深度学习的方法
(1)SDRTV/HDRTV Formation Pipeline

考虑了四项操作:tone mapping, gamut mapping, opto-electronic transfer function and quantization
这里还有很多操作没有考虑:denoising and white balance in camera pipeline, color grading in HDR content production
- tone mapping
Tone mapping is used to transform the high dynamic range signals to low dynamic range signals for adapting different display devices.
色调映射指的是为了适应不同显示能力的显示设备,将高动态范围信号转成低动态范围信号
色调映射可以分为全局色调映射(global tone mapping)和局部色调映射(local tone mapping), 全局色调映射在所有像素上使用相同的函数进行映射,函数的参数通常与全局统计量相关(比如平均亮度)。局部色调映射通常可以针对局部内容进行动态调整,但通常计算量很大,而且容易引入artifacts;
It is noteworthy that S-shape curves are commonly used for global tone mapping and clipping operations often exist in actual process of tone mapping.
通常global tone mapping是S形状的曲线,且通常存在clip操作。
- gamut mapping
Gamut mapping is to convert colors from source gamut to target gamut while still preserving the overall look of the scene
色域映射,是指在保持整体观感的前提下,将颜色从原色域转换到目标色域。
- Opto-electronic transfer function (OETF)
完成线性光信号到非线性电信号的转换
sdr: gamma
hdr: pq, hlg
- Quantization

(2)建模sdr2hdr问题:
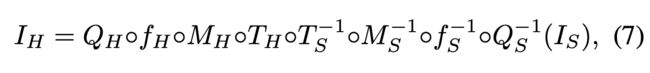
(3)基于上面的模型,作者提出自己的一些观察和见解:
(1)pipeline中的很多关键的操作都是全局操作都是全局操作,如全局色调映射、色域映射、oetf,而且这些操作的反向操作也可以近似看成全局操作;
(2)一些操作依赖于局部空间信息,比如局部色调映射、反量化,可以通过全部操作完成;
(3)存在严重的信息压缩/丢失, 例如高光区域在tonemapping时可能会因为clip操作丢失信息;
(4)基于这些见解,作者提出了一个三部sdr2hdr方案:
three-step solution pipeline including adaptive global color mapping, local enhancement and highlight generation.
方法分成三步:动态全局色彩映射、局部增强、高亮区域细节生成
(5)Comparison with Existing Solutions

- End-to-end solution
第一类是端到端的解决方案,如上图b所示,包括一些Image-to-Image translation方法和现存的超分和sdr2hdr联合的方法,都是通过cnn直接完成rgb到rgb的直接映射,这类方法由于丝毫没有考虑sdr和hdr的制作机制,通常会有obvious local artifacts and unnatural colors。
- LDR-to-HDR based solution
如上图c所示,LDR-to-HDR方法是在线性亮度空间进行转换,转换完成后要经过色域映射到bt.2020,PQ/HLG OETF, 量化,才是我们要的hdr视频。
4. Method
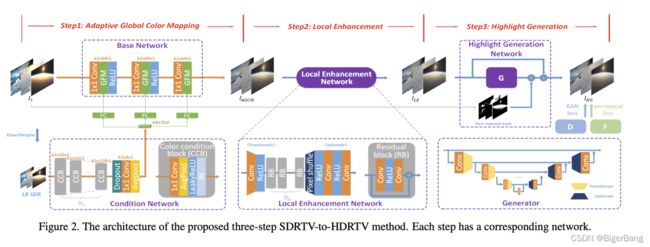
(1) Adaptive Global Color Mapping
第一步是完成sdr2hdr中的全局操作,如全局色调映射、色域映射、oetf,为了完成这一部分作者提出了两种网络:
- Base network
全局操作单独作用在每个像素上,根据CSRNet的结论,一个只有1x1卷积和激活函数的网络可以完成这种操作;因此这一块中的基础网络形式就是:

CSRNet: Conditional sequential modulation for efficient global image retouching
Although the base network can only learn a one- to-one color mapping, it also achieves considerable perfor- mances, as shown in Tab. 1.
尽管网络只学会了一对一的映射,这依然取得了不错的效果
It is noteworthy that the base network can perform like a 3D lookup table (3D LUT) with fewer parameters rather than learning 3D LUT directly, and please refer to supplementary material for more results.
这一部分可以实现成3D LUT
It performs like adding a multiplicative Bernoulli noise on features which has an effect similar to data augmentation.
将像素打乱顺序,依然可以得到很好的结果,说明该网络的操作不需要局部的信息。
-
AGCM : Base Network + Global Feature Modulation
网络示意图如下,相当于在base network的基础上插入了GFM这个模块,对1x1卷积映射的结果进行线性调整,线性调整的参数通过模型学习得到。其实可以理解成base network是一个3D lut,而AGCM是每张图有一个3d lut;


(2) Local Enhancement
尽管AGCM的效果已经很好,但是局部的增强还是不可或缺的。这里作者采用了一个resnet进行局部增强。另外作者还发现了一个比较重要的现象:
如果在全局映射之前就进行局部增强,通常会产生明显的artifacts,这可能是以前的方法artifacts很多的原因,这里作者没有进行进一步解释;
(3) Highlight Generation
这一部分从算法框图中看的比较清楚,就是用一个经典的gan网络,完成高光区域进一步的细节生成;从我实际测的结果来看,貌似这一步的效果有限;
5. HDRTV1K数据集
22段hdr10视频
Sdr由youTube下变换得到
Training set:1235
Test set: 117
下载链接在代码主页https://github.com/chxy95/HDRTVNet
6. 结果
