时序动作定位 | ActionFormer: 使用Transformers动作时刻
目录
ActionFormer: Localizing Moments of Actions with Transformers
摘要
3 ActionFormer: A Simple Transformer Model for Temporal Action Localization
A Simple Representation for Action Localization(动作定位的一个简单表示)
Method Overview
3.1 使用Transformer对视频进行编码
3.2 Decoding Actions in Time
3.3 ActionFormer: Model Design
ActionFormer: Localizing Moments of Actions with Transformers
摘要
基于自我注意的Transformer模型在图像分类和目标检测方面展示了令人印象深刻的结果,最近在视频理解方面也展示了令人印象深刻的结果。受此启发,作者研究了Transformer网络在视频中用于时间动作定位的应用。
ActionFormer 一个简单而强大的模型,可以及时识别动作,并在一个镜头中识别它们的类别,不需要使用action proposals或依赖预定义的anchor windows。ActionFormer 将多尺度特征表示与局部自注意力相结合,使用轻型解码器对每个时刻进行分类并估计相应的动作边界。这种精心安排的设计结果在以前的工作上的重大改进。没有bells and whistles,ActionFormer 实现71.0% mAP在tIoU=0.5上的THUMOS14,超过最佳先验模型14.1个绝对百分点。此外,ActionFormer在ActivityNet 1.3(平均mAP 36.6%)和EPIC-Kitchens 100(平均mAP比之前的作品高出13.5%)上展示了强劲的结果。
论文:https://arxiv.org/pdf/2202.07925v2.pdf
代码:https://github.com/happyharrycn/ actionformer_release
# 在 linux 上下载代码
git clone https://github.com/happyharrycn/actionformer_release.git3 ActionFormer: A Simple Transformer Model for Temporal Action Localization

给定一个输入视频X,假设X可以用一组特征向量X = {x1, x2,…, xT}定义在离散时间步长t ={1,2,…, T},其中总时长T随视频变化。例如,xt可以是从三维卷积网络中提取出时刻t的视频片段的特征向量。时间动作定位的目标是预测动作标签Y = {y1, y2,…, yN}基于输入视频序列x。Y包含N个动作实例yi,其中N也随视频变化。每个实例yi = (si, ei, ai)由其开始时间si(起始),结束时间ei(偏移)和其动作标签ai定义,其中si∈[1,T], ei∈[1,T], ai∈{1,.., C} (C个预定义类别)和si < ei。因此,TAL的任务是一个具有挑战性的结构化输出预测问题。
A Simple Representation for Action Localization(动作定位的一个简单表示)
该方法建立在动作定位的无anchor表示基础上,灵感来自[77,35]。关键思想是将每个时刻归类为动作类别或背景,并进一步回归这个时间步与动作开始和偏移之间的距离。在此过程中,我们将结构化输出预测问题(X = {x1, x2,…, xT}→Y = {y1, y2,…, yN})转化为一个更平易近人的序列标记问题:
![]()
在 t 时刻的输出 ![]() = (p(
= (p(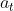 ),
), ![]() ,
,![]() )被定义为
)被定义为
• p()由C个值组成,每个值代表一个二项式变量,表示动作类别(∈{1,2,…, C}),这可以认为是C二进制分类的输出。
• ![]() >0 和
>0 和 ![]() >0分别是当前时间t到动作开始和偏移的距离。如果时间步长t位于背景,则不定义
>0分别是当前时间t到动作开始和偏移的距离。如果时间步长t位于背景,则不定义![]() 和
和![]() 。
。
直观上,这个公式将视频X中的每一个时刻t视为候选动作,识别动作的类别,并估计当前步骤与动作边界( ![]() 和
和 ![]() )之间的距离(如果出现动作)。动作定位结果可以通过
)之间的距离(如果出现动作)。动作定位结果可以通过 ![]() = (p(),
= (p(), ![]() ,
,![]() ) 轻松解码:
) 轻松解码:
![]()
Method Overview
ActionFormer 学习标记一个输入视频序列f(X)→ 。具体来说,f是通过一个深度模型来实现的。ActionFormer遵循编码器-解码器架构,在许多视觉任务中被证明是成功的,并分解为h◦g。这里g: X→Z将输入编码为潜在向量Z, h: Z→随后将Z解码为序列标签。
。具体来说,f是通过一个深度模型来实现的。ActionFormer遵循编码器-解码器架构,在许多视觉任务中被证明是成功的,并分解为h◦g。这里g: X→Z将输入编码为潜在向量Z, h: Z→随后将Z解码为序列标签。
图2展示了我们的模型的概览。重要的是,我们的编码器g是由Transformer网络参数化的[64]。我们的解码器h采用轻量级卷积网络。为了捕捉不同时间尺度下的动作,我们设计了一个多尺度特征表示 Z = {![]() ,
, ![]() ,…,
,…, 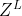 } 形成不同分辨率的特征金字塔。注意,模型运行在由特征网格定义的时间轴上,而不是绝对时间,这使得它能够适应不同帧率的视频。
} 形成不同分辨率的特征金字塔。注意,模型运行在由特征网格定义的时间轴上,而不是绝对时间,这使得它能够适应不同帧率的视频。
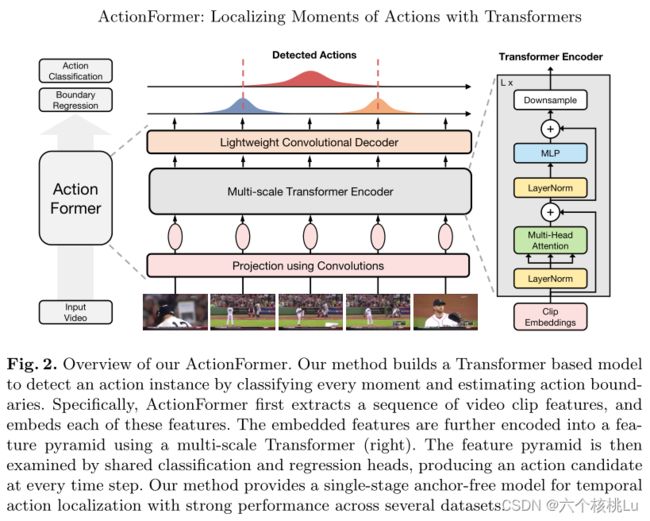
3.1 使用Transformer对视频进行编码
模型首先编码了一个输入视频X = {x1, x2,…, xT}转化为多尺度特征表示Z = {Z1, Z2,…, ZL}使用编码器g。
编码器g包括:(1)一个投影函数,使用卷积网络将每个特征(xt)嵌入到d维空间;(2)将所述嵌入特征映射到所述输出特征金字塔Z的Transformer网络。
Projection. 投影E是一个以ReLU为激活函数的浅卷积网络,定义为
![]()
其中E(xi)∈RD是xi的嵌入特征。最近发现,在Transformer网络之前添加卷积有助于更好地合并时间序列数据[32]定位上下文,并有助于稳定视觉Transformer的训练[71]。位置嵌入[64]Epos∈RT ×D可选添加。然而,作者发现这样做会降低模型的性能,因此在默认情况下删除了模型中的位置嵌入。
Local Self-Attention. Transformer网络进一步将Z0作为输入。Transformer的核心是自我注意[64]。简要介绍了使论文完备的关键思想。具体来说,自我注意计算特征的加权平均值,权重与输入特征对之间的相似度分数成正比。给定Z0∈RT ×D, D维特征的时间步长为T,用WQ∈RD×Dq, WK∈RD×Dk, WV∈RD×Dv投影Z0,提取特征表示Q、K、V,分别称为查询、键、值,Dk = Dq。输出Q, K, V计算为
![]()
自注意力的输出是由
![]()
其中S∈RT ×D, softmax按行执行。多头自注意(MSA)进一步增加了多个并行的自注意力操作。
MSA的一个主要优点是能够跨整个序列集成时间上下文,但这种优点是以计算为代价的。普通MSA在内存和时间上的复杂度为O(T 2D + D2T),因此对于长视频来说效率很低。最近有一些关于有效自我注意的研究[73,5,67,16]。在这里,作者通过将注意力限制在局部窗口内来调整来自局部的自注意力[16]。作者的直觉是,超出一定范围的时间背景对动作定位的帮助较小。这种局部的自注意力显著降低了复杂程度为O(w2t D + D2T),而局部的窗口大小为W(≪T)。重要的是,局部自注意与多尺度特征表示Z = {Z1, Z2,…, ZL},在每个金字塔层使用相同的窗口大小。通过这种设计,下采样特征图(16x)上的小窗口(19)将覆盖大的时间范围(304)。
Multiscale Transformer. 作者的Transformer有L层,每层由局部多头自注意(MSA)和MLP块交替层组成。
此外,在每个MSA或MLP块之前应用LayerNorm (LN),在每个块之后添加残差连接。GELU用于MLP。为了捕获不同时间尺度上的动作,可选附加下采样算子↓(·)。这是由

其中Zℓ−1,¯Zℓ,Zℓ∈RTℓ−1×D, Zℓ∈RTℓ×D。Tℓ−1/Tℓ为下采样比。αℓ和¯αℓ是可学习的每通道缩放因子,如[62]。
下采样算子↓由于效率高,是使用跨步深度1D卷积实现的。模型使用2倍的下采样。作者的Transformer块如图2(右)所示。模型进一步结合了几个Transformer块之间的下采样,得到一个特征金字塔Z = {Z1, Z2,…, ZL}。
3.2 Decoding Actions in Time
模型的Decoder即简单的分类预测头和回归预测头,只是不同于一般的全连接层实现,而使用一个轻量级的1D卷积网络实现。这个检测头接在特征金字塔各层的特征Z后面,它们共享参数。分类和回归头架构相似,除了分类最后用的Sigmoid激活函数,而回归使用ReLU函数。
3.3 ActionFormer: Model Design
损失函数包括分类损失和回归损失,公式如下:


实验细节 数据预处理。首先使用一个经过 Kinetics[12] 数据集预训练的 I3D[3] 模型来提取视频特征。具体来说,将 16 个连续的图像帧作为 I3D 的输入,使用一个 stride(步幅) 为 4 的滑动窗口,在I3D 最后一个全连接层之前的层中提取 1024 维的特征。同时,光流帧也按上述操作得到 1024 维的特征。之后再将这两部分的特征进一步 concatenate(连接) 为 2048 维作为模型的输入。
实验参数设置及细节
训练 使用 AdamW[21] 优化器,训练了 30 个 epoch,其中进行了 5 个 epoch 的 linear warm-up(线性热身)。初始 learning rate(学习率) 为 10−3,使用余弦退火进行学习率衰减。batch size(批量大小) 被设置为 2,weight decay(重量衰减) 为 0,momentum(动量) 为 0.9。
测试 测试集输入模型的仍然是数据预处理部分提到的 2048 维度的特征,不能达到实时处理的效果,需要先提取视频的特征,这也是该模型的缺点之一。而 soft-NMS 中的 t-IoU 阈值设置为 0.5。
实验结果及分析 作为第一个 TAL 任务下的 Transformer 模型的 ActionFormer 在没有任何数据增广的前提下,mAP 高达 66.5%,也使得 TAL 任务的 mAP 首次达到 60% 以上,取得的 state-of-the-art 的 mAP。而 ActionFormer 本身的设计较为简单,仅仅由 Transformer 编码器和轻量级 CNN 解码器组成,就能取得如此好的TAL 任务效果,由此可见,Transformer 是十分强力的一种结构。
参考:Actionformer: Localizing moments of actions with transformers 论文阅读笔记_Encounter84的博客-CSDN博客