爬虫爬疫情数据(基础练习)
学习周记2022/9/23
本周练习为python爬虫的练习,目标是爬取一些实时的疫情数据,并作可视化处理。首先是补习了一些关于网络协议的知识,单纯看代码的可以跳转至后面。
目录
关于网络协议的相关基础知识
爬虫示例(粗略爬取疫情数据)
关于网络协议的相关基础知识
HTTP协议:它是一个简单的请求--响应协议。一般用于TCP端。过程大约为:客户端发送一个请求,服务器返回一个响应。
HTTP统一使用资源标识符URI来传输数据和建立连接。
HTTP原理:
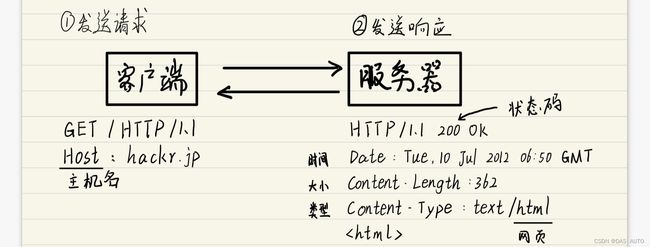
利用一个网址来举例:
https://user:[email protected]:80/dir/index/htm?uid=1#ch1
其中:
https 代表 协议
user:pass 代表 登录信息
www.example.cn 代表 服务器地址
80 代表 端口号
dir/index.htm? 代表 带层次的文件路径
uid=1 代表 查询字符串
ch1 代表 片段标识符
HTTP特点:①无连接(每次只能处理一个请求)
②是媒体独立的
③无状态(HTTP是无状态协议,无记忆能力)
RFC1945定义了HTTP/1.0版本,RFC2616定义了现在的普遍版本HTTP/1.1
服务器记忆客户端的方法:使用Cookie
过程:客户端在请求之后,服务器生成cookie,并且在响应中添加cookie后返回响应
查看网站cookie方法:
在网站中找到“开发者工具”(用Edge浏览器示例)
然后找到“Application”(或者“应用程序”)
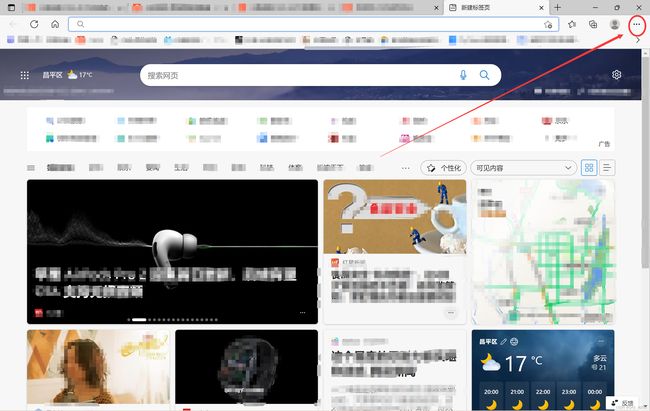
如何获取HTML文件:(用百度网站示例)
首先新建一个文本文档

在随便一个浏览器中打开百度网站,打开“开发者工具”
在“元素”中我们可以看到该网站的前端代码
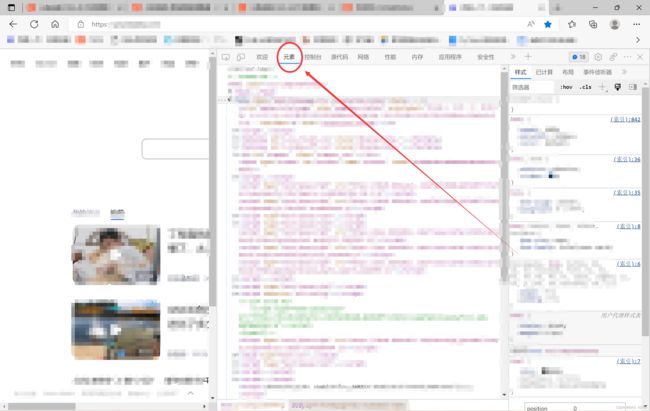
复制outerHTML,到刚才的文本文件中粘贴,随后将文本文件重命名,把文件后缀改为“.html”

双击打开后便可直接进入百度。
ROBOTS协议:robots.txt 阻止爬虫协议
网站状态码:
1XX Informational(信息性状态码) 表示 接受的请求正在处理
2XX Success(成功状态码) 表示 请求正在处理
3XX Redirection(重定向状态码) 表示 需要进行附加操作以完成请求
4XX Client Erro(客户端错误码) 表示 服务器无法处理请求
5XX Sever Error(服务器错误码) 表示 服务器处理请求出错
爬虫示例(粗略爬取疫情数据)
获取数据部分
#安装库
# pip install numpy
# pip install pandas
# pip install matplotlib
# pip install requests
# pip install lxml
# 导入模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import json
import requests
from lxml import etree# 疫情网址:https://ncov.dxy.cn/ncovh5/view/pneumonia?from=timeline&isappinstalled=0
# 指定url
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia?from=timeline&isappinstalled=0"
# 发送网络请求
res = requests.get(url)
# 指定编码格式
res.encoding = "utf-8"
# 响应网页内容
content = res.text
#content限制1000个字符
content[0:1000]# 使用HTML函数解析文件
html = etree.HTML(content)
# xpath路径:/html/body/script[1]
# 获取第一个script标签内的数据
con = html.xpath("/html/body/script[1]/text()")
con数据清洗部分:
因为数据不是标准的json格式,所以需要处理
开始位置:['try { window.getAreaStat = [{
结束位置:}catch(e){}']
# 转换成字符串
con = str(con)
# 截取起点
# begin = con.index('[{"provinceName":"台湾"')
begin = con.index("[{")
begin
# 截取终点
end = con.index("}catch(e){}']")
end
# 截取
con = con[begin : end]
con1=con[0:1000]
con1
# 读取数据
ls = json.loads(con)
# 类型,长度
type(ls),len(ls)
# 第一条数据
ls[0]
#最后一条数据
ls[len(ls)-1]
数据分析部分:
# 转换成DataFrame格式
df_data = pd.DataFrame.from_dict(ls)
df_data
# 分析currentConfirmedCount、suspectedCount
ls_province = [] # 省份
ls_currentConfirmedCount = [] # 当前确诊
for x in ls:
provinceName = x["provinceShortName"]
currentConfirmedCount = x["currentConfirmedCount"]
ls_province.append(provinceName)
ls_currentConfirmedCount.append(currentConfirmedCount)
for i in ls_province:
print(i)
for i in ls_currentConfirmedCount:
print(i)数据可视化部分:(输出图)
# 绘制柱状图
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')
plt.figure(figsize = (17,7))
x = np.array(ls_province)
y = np.array(ls_currentConfirmedCount)
plt.title("国内当前确诊人数",size = 25)
plt.xlabel("省份",size = 25)
plt.ylabel("人数",size = 25)
plt.bar(x, y)
plt.show()
# 优化柱状图(添加数字)
x = np.array(ls_province)
y = np.array(ls_currentConfirmedCount)
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')
plt.figure(figsize = (17,7))
plt.title("国内当前确诊人数",size = 25)
plt.xlabel("省份",size = 25)
plt.ylabel("人数",size = 25)
for i,j in zip(range(len(y)), y):
plt.text(i, j, j)
plt.bar(x, y)
plt.show()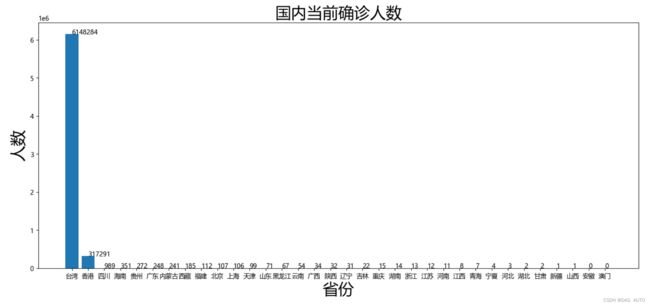
# 分析疑似病例:
ls_province = [] # 省份
ls_suspectedCount = [] # 疑似病例
for x in ls:
provinceName = x["provinceShortName"]
suspectedCount = x["suspectedCount"]
ls_province.append(provinceName)
ls_suspectedCount.append(suspectedCount)
for i in ls_suspectedCount:
print(i)
for i in ls_province:
print(i)# 绘制疑似病例柱状图
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')
x = np.array(ls_province)
y = np.array(ls_suspectedCount)
plt.figure(figsize=(20,10))
plt.title("国内疑似病例人数",size = 25)
plt.xlabel("省份",size = 25)
plt.ylabel("人数",size = 25)
for i,j in zip(range(len(y)), y):
plt.text(i, j, j)
plt.bar(x, y)
plt.show() 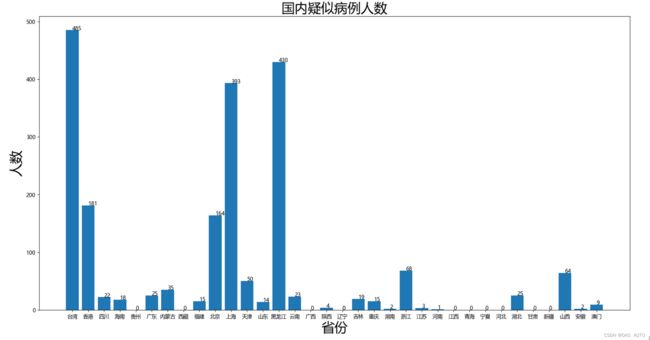
# 绘制当前确诊饼图
m=sum(ls_currentConfirmedCount)-ls_currentConfirmedCount[0]
x=[ls_currentConfirmedCount[0],m]
colors = ['#E2E2E2', '#6392BF']
explode = (-0.1,0,0.1,0)
labels = ["台湾","香港和其他省市",]
plt.pie(x,labels = labels,autopct = "%.2f%%",labeldistance=1.2,rotatelabels=True,colors=colors)
plt.title("国内当前确诊饼图")
plt.show() 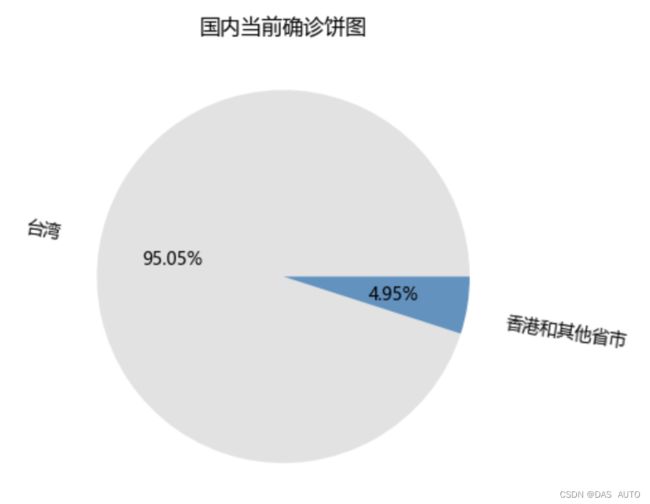
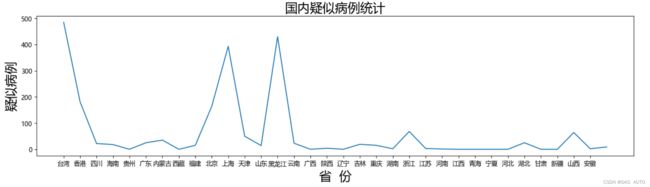
# 绘制疑似病例折线图
x = np.array(ls_province)
y = np.array(ls_suspectedCount)
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(17,4))
plt.xticks(range(0,i,1))
plt.plot(x,y)
plt.title('国内疑似病例统计',size = 20)
plt.xlabel("省 份",size = 20)
plt.ylabel("疑似病例",size = 20)
plt.show()
plt.show()