机器学习基础
机器学习和大数据的区别和联系
首先,回顾大数据的4V特征:
- 数据量大
TB-PB-ZB
HDFS分布式文件系统 - 数据种类多
结构化数据-Mysql为主的存储和处理
非结构化数据-文本、图像、音频-HDFS、MR、Hive
半结构化数据-XML、HTML形式-HDFS、MR、Hive、Spark - 速度快
数据的增长速度快-TB-PB-ZB- HDFS
数据的处理的速度快MR-HIVE-PIG-Impala(离线)-Spark-Flink(实时) - 价值密度低
价值密度=有价值的数据/ALL、价值高
机器学习算法解决的问题
大数据框架实现基础的数据存储和数据计算,如果从大量的数据中发现和挖掘出有价值的信息,需要借助机器学习算法,结合数据,构建机器学习模型实现对现实事件的预测。不同于以往的硬编码规则的方式,机器学习是通过机器学习算法发现或挖掘出数据中存在的规律或模式。
1. 机器学习引入
试想这样一个场景,傍晚小街路面上沁出微雨后的湿润,和煦的细风吹来,抬头看看天边的晚霞。心里想着明天又是一个好天气。走到水果摊旁,挑了个色泽青绿、敲起来声音浊响的青绿西瓜,一边期待着西瓜皮薄肉厚瓤甜的爽落感,一边愉快地想着,明天学习Python机器学习一定要狠下功夫,基础概念搞得清清楚楚,案例作业也是信手拈来,我们的学习效果一定差不了。
希望大家在学习完之后有这样的感觉,我们首先大致了解什么是“机器学习”(machine learning)。
回想刚刚我们买西瓜的场景,我们会发现这里涉及很多基于经验做出的预判。
(1)为什么看到微湿路面、感到和风、天边晚霞就认为明天是好天呢?
答:这是因为在我们的生活经验中已经遇见过很多类似的情况,前一天观察到上述特征后,第二天天气通常会很好。
(2)为什么色泽青绿、敲声浊响就能判断出是正熟的好西瓜呢?
答:这是因为我们吃过、看过很多的西瓜,所以基于色泽、敲声这几个特征我们就可以做出相当好的判断。
再进一步深入机器学习概念之前首先了解下机器学习或人工智能在当下的应用场景。
首先,人工智能对我们未来生活的改变,大家试想几年后,人工智能将可能取代世界上90%的岗位:
人工智能不是模仿人类,而通常是超越人类。我们试想几年后我们能够每天自我对弈100万盘棋,并从中学习的AlphaGO吗?
随着人工智能的发展,人工智能的热门方向和应用越来越多,如下图,这里总结六个方面:
2. 机器学习三次浪潮
机器学习的三次浪潮也可以说是人工智能的三次浪潮,因为机器学习是人工智能(Artificial Intelligence)研究发展到一定阶段的必然产物。
- 1956 Artificial Intelligence提出
1956年夏季,以麦卡赛、明斯基、罗切斯特和申农等为首的一批有远见卓识的年轻科学家在一起聚会,共同研究和探讨用机器模拟智能的一系列有关问题,并首次提出了“人工智能”这一术语,它标志着“人工智能”这门新兴学科的正式诞生。IBM公司“深蓝”电脑击败了人类的世界国际象棋冠军更是人工智能技术的一个完美表现。人工智能的目的就是让计算机这台机器能够像人一样思考。 - 1950-1970
符号主义流派:专家系统占主导地位
1950:图灵设计国际象棋程序
1962:IBM Arthur Samuel的跳棋程序战胜人类高手(人工智能第一次浪潮) - 1980-2000
统计主义流派
主要用统计模型解决问题
Vapnik 1993—SVM支持向量机
1997:IBM 深蓝战胜卡斯帕罗夫(人工智能第二次浪潮) - 2010-至今
神经网络、深度学习、大数据流派
Hinton 2006
2016:Google AlphaGO 战胜李世石(人工智能第三次浪潮)
刚才说到我们三次浪潮,前两次每次都是这样,说人类要毁灭了,后来发现其实并不是这样。我们现在就处在这个状态,人类又要毁灭了。其实和前两次比,还是有一点区别。
最大的一个区别就是它现在真的是深入到我们生活的每一个角落,打开你的手机看看,淘宝,智能推荐,拍一拍,谷歌翻译,搜索引擎,智能出行,智能规划,微信,智能助理,头条,智能推荐,还有机器识别,其实它已经深入的改变了我们生活的每一个角落,而将来它会改变更多。
3. 人工智能领域基础概念区别
3.1 人工智能、机器学习、深度学习关系
机器学习是人工智能的一个分支,深度学习是实现机器学习的一种技术。如下图:
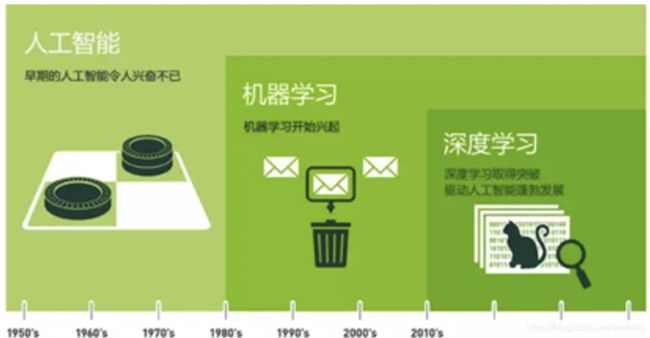
机器学习是研究如何使计算机能够模拟或实现人类的学习功能,从大量的数据中发现规律,提取知识,并在实践中不断地完善和增强自我。机器学习是机器获取知识的根本途径,只有让计算机系统具有类似人的学习能力,才可能实现人工智能的终极目标。
机器学习是人工智能研究的核心问题之一,也是当前人工智能研究的一个热门方向,同时也是人工智能理论研究和实际应用的主要瓶颈之一。
3.2 数据分析、数据挖掘基本概念区别
首先我们了解什么是数据,什么是信息?
(1)数据—即观测值,例如测量数据,你的身高,体重都是测量数据。
(2)信息:(信息抽象地说就是)可信的数据。
数据------>信息:数据和信息最大的区别就是一个是客观一个是主观。如:用尺子量桌子宽度,测量得到的值就是数据,这是客观存在的。
而对于用户而言只会关心桌子是长还是短、高还是低,大了买小的等。这种主观对客观数据的接受和在描述,就是信息。
(3)数据分析:对数据的一种操作手段,目标是经过先验(已有经验)的约束,对数据进行整理、筛选和加工,最后得到信息。【从数据到信息的转化过程】
(4)数据挖掘:是对数据分析之后的信息,进行价值化的分析。【信息的价值化】
(5)数据挖掘和数据分析的关系
数据分析:针对历史数据,分析得出各项指标,经过数据分析我们得到的是信息。
数据挖掘[大量的数据挖掘规律]:经过数据挖掘我们得到的是有价值的信息,即对信息进行价值提取或数据挖掘。
举例:啤酒和尿布的故事
数据分析(信息):根据沃尔玛历史销售数据,分别分析买各种商品的人各自具有什么特征。
数据挖掘(有价值的信息):根据历史销售数据,使用关联规则挖掘,分析买了啤酒的人还会购买什么,从而得出尿布。
3.3 各技术交叉点
了解了数据挖掘,我们在介绍下机器学习和数据挖掘的关系。
用机器学习的方法来进行数据挖掘。机器学习是一种方法;数据挖掘是一件事情;还有一个相似的概念就是模式识别,这也是一件事情。而现在流行的深度学习技术只是机器学习的一种;
人工智能是研究如何让机器具有类人智能的学科,目标是让机器具有人类的智能。机器学习,是达到人工智能目标的手段之一;模式识别也是达到人工智能的手段之一;
如上图所示,对数据挖掘而言,数据库提供数据管理技术,机器学习和统计学提供数据分析技术。
人工智能范围比较大,机器学习相对来说属于人工智能的范畴。数据挖掘则是将机器学习作为工具,利用机器学习的算法用来完成数据挖掘。另外数据挖掘也使用到其他很多内容。
4. 什么是机器学习
在开始讲解术语概念之前我们首先梳理下之前讲到的一些概念。
(基本认识)机器学习专门研究计算机怎样模拟或实现人类的学习行为,使之不断改善自身性能。是一门能够发掘数据价值的算法和应用,它是计算机科学中最激动人心的领域。我们生活在一个数据资源非常丰富的年代,通过机器学习中的自学习算法,可以将这些数据转换为知识。
(机器学习库)借助于近些年发展起来的诸多强大的开源库,我们现在是进入机器学习领域的最佳时机。
(机器学习目的)从20世纪后半段,机器学习已经逐渐演化成为人工智能的一个分支,其目的是通过自学习算法从数据中获取知识,进而对未来进行预测。与以往通过大量数据分析而人工推导出规则并构造模型不同,机器学习提供了一种从数据中获取知识的方法,同时能够逐步提高预测模型的性能,并将模型应用于基于数据驱动的决策中去。
(应用)机器学习技术的存在,使得人们可以享受强大的垃圾邮件过滤带来的便利,拥有方便的文字和语音识别软件,能够使用可靠的网络搜索引擎,同时在象棋的网络游戏对阵中棋逢对手,而且Google已经将机器学习技术应用到了无人驾驶汽车中。
机器学习模型=数据+机器学习算法
4.1 确定是否为机器学习问题
机器学习:从已有的经验中学习经验,从经验中去分析,接下来的若干问题请大家思考哪些问题
-
可以用机器学习方式处理?
(1)计算每种颜色箱子的个数?----确定的问题
(2)计算一组数据平均值大小?----数值计算问题 -
机器学习的目的是建立预测模型–看是否有预测的过程
(1)确定收到的邮件是否为垃圾邮件?
(2)获取2014年世界杯冠军的名字?2018年?
(3)自动标记你在Facebook中的照片
(4)选择统计课程中成绩最高的学生(不是)
(5)考虑购物习惯,推荐相关商品?
(6)根据病人状况确定属于什么疾病?
(7)预测2018年人民币汇率涨or不涨?
(8)计算公司员工的平均工资?
5. 基于规则学习和基于模型的学习
5.1 基于规则学习
5.2 基于模型学习
5.3房价预测问题
机器学习学习的是什么?
构建机器学习模型,如:y=kx+b,k和b是参数,x和y是特征和类别标签列。机器学习学习的是k和b的参数,如果k和b知道了,直接利用y=kx+b进行预测分析。
6. 机器学习数据的基本概念
6.1 机器学习数据集基本概念强化实践
鸢尾花Iris Dataset数据集是机器学习领域经典数据集,该数据集可以从加州大学欧文分校(UCI)的机器学习库中得到。鸢尾花数据集包含了150条鸢尾花信息,每50条取自三个鸢尾花中之一:Setosa、Versicolour和Virginica,每个花的特征用下面5种属性描述。
(1)萼片长度(厘米)
(2)萼片宽度(厘米)
(3)花瓣长度(厘米)
(4)花瓣宽度(厘米)
(5)类(Setosa、Versicolour、Virginica)
花的萼片是花的外部结构,保护花的更脆弱的部分(如花瓣)。在许多花中,萼片是绿的,只有花瓣是鲜艳多彩的,然而对与鸢尾花,萼片也是鲜艳多彩的。下图中的Virginica鸢尾花的图片,鸢尾花的萼片比花瓣大并且下垂,而花瓣向上。如下图:
在鸢尾花中花数据集中,包含150个样本和4个特征,因此将其记作150x4维的矩阵, ,其中R表示向量空间,这里表示150行4维的向量,记作:
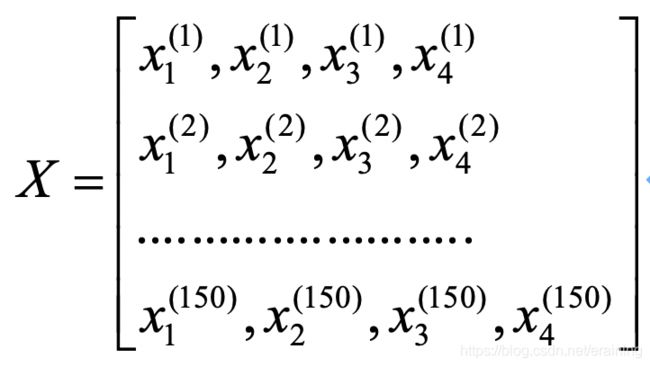
我们一般使用上标(i)来指代第i个训练样本,使用小标(j)来指代训练数据集中第j维特征。一般小写字母代表向量,大写字母代表矩阵。
表示第150个花样本的第2个特征萼片宽度。在上述X的特征矩阵中,每一行表代表一个花朵的样本,可以记为一个四维行向量
数据中的每一列代表样本的一种特征,可以用一个150维度的列向量表示:
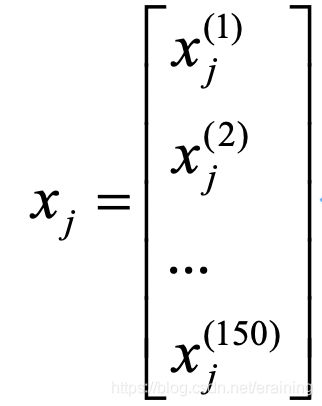
类似地,可以用一个150维度的列向量存储目标变量(类标)

总结:
6.2 机器学习数据集基本概念强化
下面是西瓜数据集,可以通过西瓜的色泽、根蒂、敲声确定一个西瓜是好瓜或坏瓜 :
要进行机器学习,先要有数据。假定我们收集了一批关于西瓜的数据:
{颜色=乌黑,敲声=浊响}
{颜色=青绿,敲声=清脆}
【基础概念1】将这组记录的集合称为一个“数据集”(data set),其中每条记录是关于一个事件或对象(这里说的是西瓜)的描述,也称为一个“样本”(sample)。
【基础概念2】而我们所说的西瓜的色泽,这种可以反应事件或对象在某方面的表现或性质的事项,称为“特征”(feature)或“属性”(attribute)”
属性上的取值,如色泽青绿等,这个取值称为属性值(attribute value)。
【基础概念3】属性构成的空间称为“属性空间”或样本空间(sample space)或输入空间。比如将西瓜的颜色,敲声作为两个坐标轴,则它们可以张成一个用于描述西瓜的二维空间,每个西瓜都可以在这个空间中找到自己的坐标位置。由于空间中的每个点都对应一个坐标向量,因此我们也把一个样本称作一个“特征向量”(feature vector)。
假设 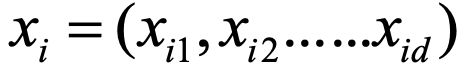
是西瓜数据集 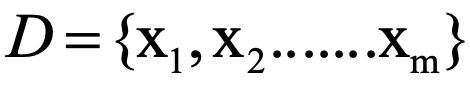
的第i个样本,其中 是 在第j个属性上的取值,如第3个西瓜在第1个属性(颜色)上取值为“乌黑”。d称为样本 的“维度数或维数”(dimensionality)。数据集D中的 表示第i个样本或示例。
【基础概念4】从数据中学得模型得过程称为“学习”(learning)或训练(training),这个过程是通过执行某个学习算法来完成的。训练过程中使用的数据称为“训练数据”(training set)。
训练数据:由输入X与输出Y对组成。训练集在数学上表示为:

【基础概念5】模型有时也称为“学习器”(learner),可以看作是学习算法在给定数据和参数空间上的实例化。
【基础概念6】如果希望学得一个能帮助我们判断西瓜是不是“好瓜”的模型,仅仅有前面的样本数据是不够的,要建立这样的关于“预测(prediction)”的模型,我们需要获得训练样本的“结果”信息,如:{(颜色=青绿,敲声=浊响),好瓜}。这里的结果信息,称为样本的“标记(label)”;拥有了标记信息的样本,则称为“样例(example)”。用
表示第i个样例,yi是样本x的标识,一般把标记的集合称为标记空间(label space)或输出空间。
学习完模型后,就需要进行预测,预测的过程称为“测试”(testing),被预测的样本称为“测试样本”(testing sample)。
测试数据:也是由输入X与输出Y组成,是用于测试训练好的模型对于新数据的预测能力。例如在中学阶段的函数可表示为y=f(x),这里的f指的是通过学习得到的模型,对于测试x,可得到其预测标记y=f(x)。
有了上面基本概念铺垫,我们可以学习机器学习的三种不同方法
6.3 电商数据集基本概念强化
首先,通过电商购买数据集了解机器学习数据集的构成:其中每一个用户都由age年龄、income收入、student是否为学生、credit_rating信用级别和buy_computer是否购买电脑组成。

如果通过机器识别用户是否购买电脑,需要将数据集中各字段进行数字化:
数据集的描述:
7. 机器学习分类及场景应用
7.1 监督学习
监督学习(supervised learning)从训练数据(training data)集合中学习模型,对测试数据(test data)进行预测。
通俗易懂地讲:监督学习指的是人们给机器一大堆标记好的数据,比如一大堆照片,标记住那些是猫的照片,那些是狗的照片,然后让机器自己学习归纳出算法或模型,然后所使用该算法或模型判断出其他照片是否是猫或狗。代表的算法或模型有Linear regression、Logistic regression、SVM、Neural network等。如下图流程所示:
(1)利用分类对类标进行预测
分类是监督学习的一个核心问题。在监督学习中,当输出变量Y取有限个离散值时,预测问题便成了分类问题。监督学习从数据中学习一个分类模型或分类决策函数,称为分类器(classifer),分类器对新的输入进行输出的预测(prediction),称为分类(classification)。
分类的类别是多个时,称为多类分类问题。
分类问题包括学习和分类的两个过程。在学习过程中,根据已知的训练数据集利用有效的学习方法学习一个分类器;在分类的过程中,利用学习的分类器对新的输入实例进行分类。
如上述的垃圾邮件就是一个2分类问题,使用相应的机器学习算法判定邮件属于垃圾邮件还是非垃圾邮件。如下图给出了30个训练样本集实例:15个样本被标记为负类别(negative class)(图中圆圈表示);15个样本被标记为正类别(positive class)(图中用加号表示)。由于我们的数据集是二维的,这意味着每个样本都有两个与其相关的值: ,现在我们可以通过有监督学习算法获得一条规则,并将其表示为图中的一条黑色的虚线将两类样本分开,并且可以根据 值将新样本划分到某个类别中(看位于直线的那一侧)。
分类的任务就是将具有类别的、无序类标分配给各个新样本。
总结:
输出变量为有限个离散值的情况称为分类问题(classification)
如果类别为正类或负类的时候,这个是一个二分类问题
如果类别是一个多类别的时候,这就是一个多分类问题。
分类问题包括了学习和分类两个过程:
(1)学习:根据已知的训练数据集利用有效的学习方法学习一个分类器。
(2)分类:利用学习到的算法判定新输入的实例对其进行分类。
(2)利用回归预测连续输出值
另一类监督学习方法针对连续型输出变量进行预测,也就是所谓的回归分析(regression analysis)。回归分析中,数据中会给出大量的自变量和相应的连续因变量(对应输出结果),通过尝试寻找自变量和因变量的关系,就能够预测输出变量。
如下图中,给定了一个自变量x和因变量y,拟合一条直线使得样例数据点与拟合直线之间的距离最短,最常采用的是平均平方距离来计算。如此,我们可以通过样本数据的训练来拟合直线的截距和斜率,从而对新的输入变量值所对应的输出变量进行预测。
比如生活中常见的房价问题,横轴代表房屋面积,纵轴代表房屋的售价,我们可以画出图示中的数据点,再根据使得各点到直线的距离的平均平方距离的最小,从而绘制出下图的拟合直线。根据生活常识随着房屋面积的增加,房价也会增长。
回归问题的分类有:根据输入变量的个数分为一元回归和多元回归;按照输入变量和输出变量之间的关系分为线性回归和非线性回归(模型的分类)。
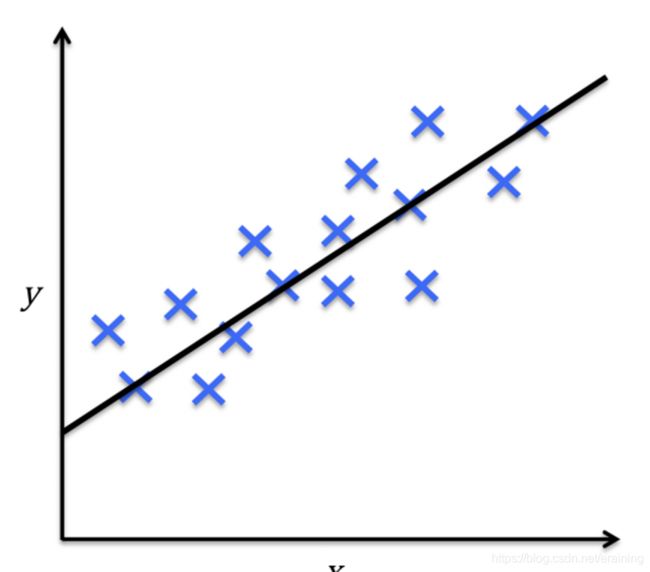
(3)标注问题
标注问题是分类问题的一种推荐,输入是一个观测序列,输出是一个标记序列或状态序列。标注问题的目标在于学习一个模型,使它能够对观测序列给出标记序列作为预测。
标注问题常用的方法有:隐马尔科夫模型、条件随机场。
自然语言处理中的词性标注就是一个标注问题:给定一个由单词组成的句子,对这个句子中的每一个单词进行词性标注,即对一个单词序列预测起对应的词性标注序列。
7.2 无监督学习
通俗地讲:非监督学习(unsupervised learning)指的是人们给机器一大堆没有分类标记的数据,让机器可以对数据分类、检测异常等。
(1)通过聚类发现数据的子群
聚类是一种探索性数据分析技术,在没有任何相关先验信息的情况下(相当于不清楚数据的信息),它可以帮助我们将数据划分为有意义的小的组别(也叫簇cluster)。其中每个簇内部成员之间有一定的相似度,簇之间有较大的不同。这也正是聚类作为无监督学习的原因。
下图中通过聚类方法根据数据的 两个特征值之间的相似性将无类标的数据划分到三个不同的组中。
【例子】我们可以用下图表示西瓜的色泽和敲声两个特征,分别为 ,我们可以将训练集中的西瓜分成若干组,每一组称为一个“簇”,这些自动形成的簇可能对应一些潜在的概念划分,如“浅色瓜”、“深色瓜”、“本地瓜”或“外地瓜”。通过这样的学习我们可以了解到数据的内在规律,能为更深入地分析数据建立基础。
需要注意的是我们事先并不知道西瓜是本地瓜、浅色瓜,而且在学习过程中使用的训练样本通常不拥有标记(label)信息。
(2)数据压缩中的降维
数据降维(dimensionality reduction)是无监督学习的另一个子领域。通常,面对的数据都是高维的,这就对有限的数据存储空间以及机器学习算法性能提出了挑战。无监督降维是数据特征预处理时常用的技术,用于清除数据中的噪声,能够在最大程度保留相关信息的情况下将数据压缩到额维度较小的子空间,但是同时也可能会降低某些算法准确性方面的性能。
如下图一个三维空间的数据映射到二维空间的实例。
7.3 半监督学习
半监督学习的现实需求也非常强烈,因为在现实生活中往往能容易地收集到大量未“标记”的样本,而获取有标记的样本却需要耗费人力、物力。在互联网应用的最为明显,例如在进行网页推荐时需要请用户标记出感兴趣的网页,但是很少的用户愿意花很多时间来提供标记,因此,有标记的网页样本少,但互联网上存在无数网页可作为未标记样本使用。
半监督学习就是提供了一条利用“廉价”的未标记样本的途径。
通常在处理未标记的数据时,常常采用“主动学习”的方式,也就是首先利用已经标记的数据(也就是带有类标签)的数据训练出一个模型,再利用该模型去套用未标记的数据,通过询问领域专家分类结果与模型分类结果做对比,从而对模型做进一步改善和提高,这种方式可以大幅度降低标记成本,但是“主动学习”需要引入额外的专家知识,通过与外界的交互来将部分未标记样本转化有标记的样本。但是如果不与专家进行互动,没有额外的信息,还能利用未标记的样本提高模型的泛化性能吗?
答案是肯定的,因为未标记样本虽然未直接包含标记信息,但它们与有标记样本有一些共同点,我们可以利用无监督学习的聚类方法将数据特征相似的聚在一个簇里面,从而给未标记的数据带上标记。这也是在半监督学习中常用的“聚类假设”,本质上就是“利用相似的样本拥有相似的输出”这个基本假设。
半监督学习进一步划分为了纯半监督学习和直推学习(transductive learning),前者假定训练数据中的未标记样本并不是待测数据,而直推学习假设学习过程中所考虑的未标记样本恰恰是待预测样本。无论是哪一种,我们学习的目的都是在这些未标记的样本上获得最优的泛化性能(泛化简单的指的是模型无论对训练集表现效果好,对测试集效果也很不错,在模型选择中我们会详细讲解)。
7.4 强化学习
【基础概念】强化学习(Reinforcement Learning)是机器学习的一个重要分支,主要用来解决连续决策的问题。比如围棋可以归纳为一个强化学习问题,我们需要学习在各种局势下如何走出最好的招法。还有我们要种西瓜的过程中需要多次种瓜,在种瓜过程中不断摸索,然后才能总结出好的种瓜策略,将例子中的过程抽象出来就是“强化学习”。
强化学习不像无监督学习那样完全没有学习目标,又不像监督学习那样有非常明确的目标(即label),强化学习的目标一般是变化的、不明确的,甚至可能不存在绝对正确的标签。最近火热的无人驾驶技术是一个非常复杂、非常困难的强化学习任务,在深度学习出现之前,几乎不可能实现,无人驾驶汽车通过摄像头、雷达、激光测距仪、传感器等对环境进行观测,获取到丰富的环境信息,然后通过深度强化学习模型中的CNN、RNN等对环境信息进行处理、抽象和转化,在结合强化学习算法框架预测出最应该执行的动作(是加速、减速、转向等),来实现自动驾驶。当然,无人驾驶汽车每次执行的动作,都会让它到目的地的路程更短,即每次行动都会有相应奖励。
深度强化学习最具有代表性的一个里程碑是AlphaGo,围棋是棋类游戏中最复杂的游戏,19*19的棋盘给它带来了3361种状态,这个数量级别已经超过了宇宙中原子数目的状态数。因此,计算机是无法通过像IBM深蓝那样暴力搜索来战胜人类,就必须给计算机抽象思维的能力,而AlphaGo做到了这一点。
如下图所示,强化学习目标是构建一个系统Agent,在于环境Environment交互过程中提高系统的性能。环境的当前状态信息中通常包含一个反馈(Reward)信号和行为State。Agent通过与环境Environment交互,Agent可以通过强化学习来得到一系列行为,通过探索性的试错或借助精心设计的激励系统使得正向反馈最大化。
Agent可以根据棋盘上的当前局势(环境)决定落子的位置,而游戏结束时胜负的判定可以作为激励信号。如下图:
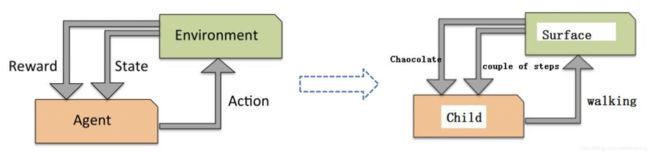
7.5 总结
除了上述学习方式,还有深度学习、迁移学习等学习方式,一般深度学提取特征、强化学习解决连续决策,迁移学习解决模型适应性问题。
下面对迁移学习能解决那些问题?
-
小数据的问题。比方说新开一个网店,卖一种新的糕点,没有任何的数据,就无法建立模型对用户进行推荐。但用户买一个东西会反映到用户可能还会买另外一个东西,所以如果知道用户在另 外一个领域,比方说卖饮料,已经有了很多很多的数据,利用这些数据建一个模型,结合用户买 饮料的习惯和买糕点的习惯的关联,就可以把饮料的推荐模型给成功地迁移到糕点的领域,这样, 在数据不多的情况下可以成功推荐一些用户可能喜欢的糕点。这个例子就说明,有两个领域,一 个领域已经有很多的数据,能成功地建一个模型,有一个领域数据不多,但是和前面那个领域是 关联的,就可以把那个模型给迁移过来。
-
个性化的问题。比如每个人都希望自己的手机能够记住一些习惯,这样不用每次都去设定它,怎么才能让手机记住这一点呢?其实可以通过迁移学习把一个通用的用户使用手机的模型迁移到个性化的数据上面。
最后总结机器学习分类:
8. 如何理解机器学习三要素
统计学习=模型+策略+算法
模型:规律y=ax+b
策略:什么样的模型是好的模型?损失函数
算法:如何高效找到最优参数,模型中的参数a和b
8.1 模型
机器学习中,首先要考虑学习什么样的模型,在监督学习中,如模型y=kx+b就是所要学习的内容。
模型通常分为决策函数或条件概率分布
由决策函数表示的模型为非概率模型,由条件概率分布表示的模型为概率模型。
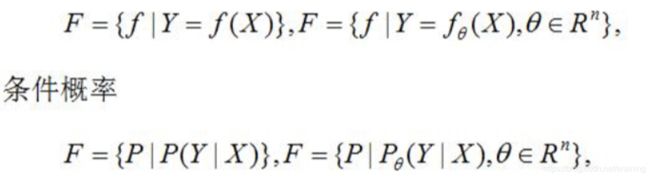
8.2 策略
评价模型的好坏,使用损失函数进行度量,模型给出的值与实际真实值存在的差别。
损失函数度量模型一次预测的好坏,常用的损失函数有:

8.3 算法
机器学习的算法就是求解最优化问题的算法。如果最优化问题有显示的解析解,这个最优化问题就比较简单,但通常这个解析解不存在,所以就需要利用数值计算的方法来求解。机器学习可以利用已有的最优化算法,也可以开发独自的最优化算法。
9. 构建机器学习模型
我们使用机器学习预测模型的工作流程讲解机器学习系统整套处理过程。
整个过程包括了数据预处理、模型学习、模型验证及模型预测。其中数据预处理包含了对数据的基本处理,包括特征抽取及缩放、特征选择、特征降维和特征抽样;我们将带有类标的原始数据划按照82原则分为训练数据集和测试集。使用训练数据集用于模型学习算法中学习出适合数据集的模型,再用测试数据集用于验证最终得到的模型,将模型得到的类标签和原始数据的类标签进行对比,得到分类的错误率或正确率。
当有新数据来的时候,我们可以代入模型进行预测分类。
注:特征缩放、降维等步骤中所需的参数,只可以从训练数据中获取,并能够应用于测试数据集及新的样本,但仅仅在测试集上对模型进行性能评估或许无法监测模型是否被过度优化(后面模型选择中会提到这个概念)。
9.1 数据预处理(特征工程)
数据预处理是机器学习应用的必不可少的重要步骤之一,以提到的Iris Dataset为例,将花朵的图像看做原始数据,从中提取有用的特征,其中根据常识我们可以知道这些特征可以是花的颜色、饱和度、色彩、花朵整体长度以及花冠的长度和宽度等。首先了解一下几个数据预处理方法:
- (数据归一化与标准化,缺失值处理)大部分机器学习算法为达到性能最优的目的,将属性映射到[0,1]区间,或者使其满足方差为1、均值为0的标准正态分布,从而提取出的特征具有相同的度量标准。
- (数据降维)当源数据的某些属性间可能存在较高的关联,存在一定的数据冗余。此时,我们使用机器学习算法中的降维技术将数据压缩到相对低纬度的子空间中是非常有用的。数据降维算法不仅可以能够使得所需的存储空间更小,而且还能够使得学习算法运行的更快。
- (数据集切分)为了保证算法不仅在训练集上有效,同时还能很好地应用于新数据,我们通常会随机地将数据集划分为训练数据集和测试数据集,使用训练数据集来训练及优化我们的机器学习模型,完成后使用测试数据集对最终模型进行评估。
数据预处理也称作特征工程,所谓的特征工程就是为机器学习算法选择更为合适的特征。当然,数据预处理不仅仅还有上述的三种。
9.2 选择预测模型进行模型训练
任何分类算法都有其内在的局限性,如果不对分类任务预先做一些设定,没有任何一个分类模型会比其他模型更有优势。因此在实际的工作处理问题过程中,必不可少的一个环节就是选择不同的几种算法来训练模型,并比较它们的性能,从中选择最优的一个。
(1)如何选择最优的模型呢?我们可以借助一些指标,如分类准确率(测量值和真实值之间的接近程度)、错误率等指标衡量算法性能。
(2)疑问:选择训练模型的时候没有使用测试数据集,却将这些数据应用于最终的模型评估,那么判断究竟哪一个模型会在测试数据集有更好的表现?
针对该问题,我们采用了交叉验证技术,如10折交叉验证,将训练数据集进一步分为了训练子集和测试子集,从而对模型的泛化能力进行评估。
(3)不同机器学习算法的默认参数对于特定类型的任务来说,一般都不是最优的,所以我们在模型训练的过程中会涉及到参数和超参数的调整。
什么是超参数呢?超参数是在模型训练之前已经设定的参数,一般是由人工设定的。
什么是参数呢?参数一般是在模型训练过程中训练得出的参数。
9.3 模型验证与使用未知数据进行预测
使用训练数据集构建一个模型之后可以采用测试数据集对模型进行测试,预测该模型在未知数据上的表现并对模型的泛化误差进行评估。如果对模型的评估结果表示满意,就可以使用此模型对以后新的未知数据进行预测。(模型评估部分会专门在下节讲解~)
但什么是泛化误差呢?我们带着这个问题分别对模型验证这块涉及到的基础概念做一个深入理解:
【基础概念】通常我们把分类错误的样本数占样本总数的比例称为“错误率(error rate)”,如果在m个样本中有a个样本分类错误,则错误率为E=a/m;从另一个角度,1-a/m则称为“分类精度(accurary)”,也就是“精度+错误率=1”。
我们将模型(或学习器)的实际输出与样本的真实值之间的差异称为“误差(error)”,学习器在训练集上的误差称为“训练误差(training error)”或经验误差(empirical error),在新的样本上的误差称为“泛化误差(generalization error)”。
我们在模型验证的时候期望得到泛化误差小的学习器。
9.4 模型验证与使用未知数据进行预测
使用训练数据集构建一个模型之后可以采用测试数据集对模型进行测试,预测该模型在未知数据上的表现并对模型的泛化误差进行评估。如果对模型的评估结果表示满意,就可以使用此模型对以后新的未知数据进行预测。
但什么是泛化误差呢?我们带着这个问题分别对模型验证这块涉及到的基础概念做一个深入理解:
【基础概念】通常我们把分类错误的样本数占样本总数的比例称为“错误率(error rate)”,如果在m个样本中有a个样本分类错误,则错误率为E=a/m;从另一个角度,1-a/m则称为“分类精度(accurary)”,也就是“精度+错误率=1”。
我们将模型(或学习器)的实际输出与样本的真实值之间的差异称为“误差(error)”,学习器在训练集上的误差称为“训练误差(training error)”或经验误差(empirical error),在新的样本上的误差称为“泛化误差(generalization error)”。
我们在模型验证的时候期望得到泛化误差小的学习器。
9.5 准确率和召回率、F1分数
预测误差(error,ERR)和准确率(accurary,ACC)都提供了误分类样本数量的相关信息。误差可以理解为预测错误样本与所有被预测样本数量量的比值,而准确率计算方法则是正确预测样本的数量与所有被预测样本数量的比值。

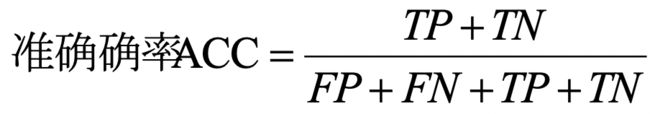
对类别数量不均衡的分类问题来说,真正率TPR与假正率FPR是更重要的指标:
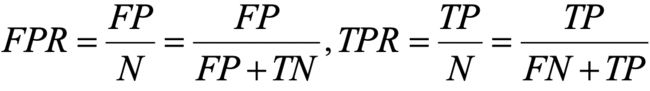
比如在肿瘤诊断中,我们更为关注是正确检测出的恶性肿瘤,使得病人得到治疗。然而降低良性肿瘤(假负FN)错误被划分为恶性肿瘤,但对患者影响并不大。与FPR相反,真正率提供了有关正确识别出来的恶性肿瘤样本(或相关样本)的有用信息。
由此提出了准确率(persoon,PRE)和召回率(recall,REC),是与真正率、真负率相关的性能评价指标,召回率实际上与真正率含义相同,定义如下:
(真正率是看矩阵的行,即实际情况)

准确率(模型的预测情况,看矩阵的列)定义:

实际中,常采用准确率与召回率的组合,称为F1-Score
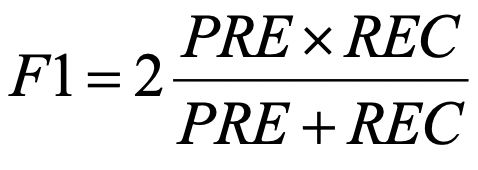
9.6 Khold评估模型性能
验证模型准确率是非常重要的内容,我们可以将数据手工切分成两份,一份做训练,一份做测试,这种方法也叫“留一法”交叉验证。这种方法很有局限,因为只对数据进行一次测试,并不一定能代表模型的真实准确率。因为模型的准确率和数据的切分是有关系的,在数据量不大的情况下,影响比较大。因此我们提出了K折交叉验证,K-Fold交叉验证。
K-Fold交叉验证,将数据随机且均匀地分成k分,常用的k为10,数据预先分好并保持不动。假设每份数据的标号为0-9,第一次使用标号为0-8的共9份数据来做训练,而使用标号为9的这一份数据来进行测试,得到一个准确率。第二次使用标记为1-9的共9份数据进行训练,而使用标号为0的这份数据进行测试,得到第二个准确率,以此类推,每次使用9份数据作为训练,而使用剩下的一份数据进行测试,这样共进行10次,最后模型的准确率为10次准确率的平均值。这样就避免了数据划分而造成的评估不准确的问题。
如下图:
10. 模型选择
一个模型可能有很多种情况出现,那么我们如何选择最优的模型呢?
10.1 那条曲线拟合效果是最好的?
观察上述图示:
利用已知的样本点在图示的坐标轴上画出了绿色的曲线,表示源数据的大致分布状况。假设我们使用后面要学习的线性回归去解决样本点拟合问题, 比如用多项式表示线性回归模型: 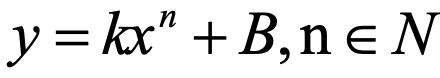
,当n=0时,y=k,就是图一的平行于x轴的直线,此时该直线不能很好的拟合样本数据;当n=1时,y=kx+B,得到图2的一次直线,我们可以注意到无论怎么调整该直线都不能很好的拟合样本数据;上述n=0或1时是模型的欠拟合情况。当n=3时,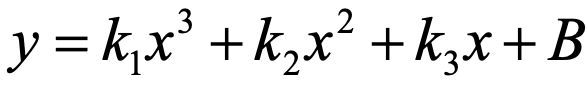
,得到图3的三次函数拟合曲线,这种情况是能够很好的拟合样本数据;但是,当n=9时,得到图4的拟合曲线。当n取值越高的时候,当前样本的数据能够很好的拟合,但是在新的数据上效果却很差,这时出现了过拟合情况。
通过上述图大家应该能看到,即便我们确定了使用线性回归模型去处理,我们在选择参数的时候也是有很多种情况。如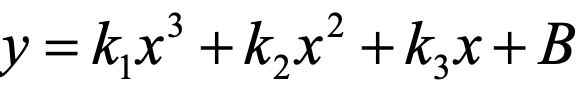
,可以调整不同的k1、k2和k3的值,同时也对应了不同的拟合直线,我们希望可以从这些参数中找到拟合较好的直线,但不能过分的好,因为我们要考虑当新数据来了模型的分类情况。
由此我们引入了模型的“泛化”能力的概念。
10.2 泛化
机器学习的目标是使学得的模型能很好地适用于“新样本”,而不是仅仅在训练样本上工作的很好;即便对聚类这样的无监督学习任务,我们也希望学得的簇划分能适用于没在训练集中出现的样本。学得模型适用于新样本的能力,称为“泛化”(generalization)能力。具有强泛化能力的模型能很好地适用于整个样本空间。(现实任务中的样本空间的规模通常很大,如20 个属性,每个属性有10个可能取值,则样本空间的规模是1020)。
还有一个泛化的概念:
【基础概念】模型具有好的泛化能力指的是:模型不但在训练数据集上表现的效果很好,对于新数据的适应能力也有很好的效果。
当我们讨论一个机器学习模型学习能力和泛化能力的好坏时,我们通常使用过拟合和欠拟合的概念,过拟合和欠拟合也是机器学习算法表现差的两大原因。
【基础概念】过拟合overfitting:模型在训练数据上表现良好,在未知数据或者测试集上表现差。
【基础概念】欠拟合underfitting:在训练数据和未知数据上表现都很差。
10.3 欠拟合
图1和图2都是模型欠拟合的情况:即模型在训练集上表现的效果差,没有充分利用数据,预测准确率很低,拟合结果严重不符合预期。
产生的原因:模型过于简单
出现的场景:欠拟合一般出现在机器学习模型刚刚训练的时候,也就是说一开始我们的模型往往是欠拟合也正是因为如此才有了优化的空间,我们通过不断优化调整算法来使得模型的表达能力更强。
解决办法:
(1)添加其他特征项:因为特征项不够而导致欠拟合,可以添加其他特征项来很好的解决。
(2)添加多项式特征,如图(3)我们可以在线性模型中通过添加二次或三次项使得模型的泛化能力更强。
(3)减少正则化参数,正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,需要减少正则化参数。
10.4 过拟合

上图是模型过拟合的情况:即模型在训练集上表现的很好,但是在测试集上效果却很差。也就是说,在已知的数据集合中非常好,再添加一些新数据进来效果就会差很多。
产生的原因:可能是模型太过于复杂、数据不纯、训练数据太少等造成。
出现的场景:当模型优化到一定程度,就会出现过拟合的情况。
解决办法:
(1)重新清洗数据:导致过拟合一个原因可能是数据不纯导致的,
(2)增大训练的数据量:导致过拟合的另一个原因是训练数据量太小,训练数据占总数据比例太低。
(3)采用正则化方法对参数施加惩罚:导致过拟合的原因可能是模型太过于复杂,我们可以对比较重要的特征增加其权重,而不重要的特征降低其权重的方法。常用的有L1正则和L2正则,我们稍后会提到。
(4)采用dropout方法,即采用随机采样的方法训练模型,常用于神经网络算法中。
注意:模型的过拟合是无法彻底避免的,我们能做的只是缓解,或者说减小其风险,因为机器学习面临的是NP难问题(这列问题不存在有效精确解,必须寻求这类问题的有效近似算法求解),但是有效算法必然是在多项式时间内运行完成的,因此过拟合是不可避免的。在实际的任务中往往通过多种算法的选择,甚至对同一个算法,当使用不同参数配置时,也会产生不同的模型。那么,我们也就面临究竟选择哪一种算法,使用哪一种参数配置?这就是我们在机器学习中的“模型选择(model select)”问题,理想的解决方案当然是对候选模型的泛化误差进行评估,然后选择泛化误差最小的那个模型。我们更详细的模型选择会有专门的专题讲到,如具体的评估方法(交叉验证)、性能度量准则、偏差和方差折中等。
补充:NP难问题
NP是指非确定性多项式(non-deterministic polynomial,缩写NP)。所谓的非确定性是指,可用一定数量的运算去解决多项式时间内可解决的问题。
例如,著名的推销员旅行问题(Travel Saleman Problem or TSP):假设一个推销员需要从香港出发,经过广州,北京,上海,…,等 n 个城市, 最后返回香港。任意两个城市之间都有飞机直达,但票价不等。假设公司只给报销 C 元钱,问是否存在一个行程安排,使得他能遍历所有城市,而且总的路费小于 C?
推销员旅行问题显然是 NP 的。因为如果你任意给出一个行程安排,可以很容易算出旅行总开销。但是,要想知道一条总路费小于 C 的行程是否存在,在最坏情况下,必须检查所有可能的旅行安排! 这将是个天文数字。
迄今为止,这类问题中没有一个找到有效算法。倾向于接受NP完全问题(NP-Complet或NPC)和NP难题(NP-Hard或NPH)不存在有效算法这一猜想,认为这类问题的大型实例不能用精确算法求解,必须寻求这类问题的有效的近似算法。
10.5 奥卡姆剃刀原则
奥卡姆剃刀原则是模型选择的基本而且重要的原则。
模型是越复杂,出现过拟合的几率就越高,因此,我们更喜欢采用较为简单的模型。这种策略与应用就是一直说的奥卡姆剃刀(Occam’s razor)或节俭原则(principe of parsimony)一致。
奥卡姆剃刀:给定两个具有相同泛化误差的模型,较简单的模型比较复杂的模型更可取。
11. 经验风险与结构风险
策略部分:
11.1 经验风险
模型f(x)关于训练数据集的平均损失称之为经验风险(emprical risk)或经验损失(empirical loss),记作R(emp)
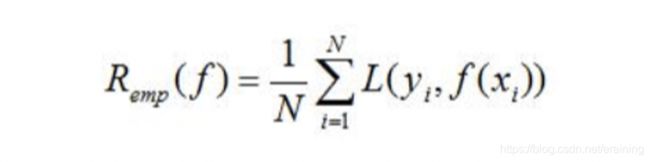
期望风险R(emp)是模型关于联合分布的期望损失,经验风险R(emp)是模型关于训练样本集的平均损失。根据大数定律,当样本容量N趋于无穷时,经验风险R(emp)趋于期望风险R(exp),所以一个很自然的想法就是利用经验风险估计期望风险。但是,由于现实中训练样本数目有限甚至很小,所以用经验风险估计期望风险常常不理想,要对经验风险进行一定的矫正,这就是关系到监督学习的两个基本策略:经验风险最小化和结构风险最小化。
11.2 经验风险最小化
在损失函数以及训练数据集确定的情况下,经验风险函数式就可以确定,经验风险最小化(emprical risk minimization,EMR)的策略认为,经验风险最小的模型是最优模型。
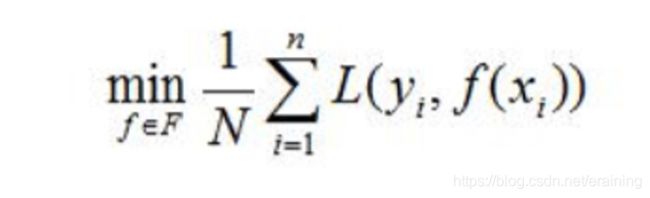
当样本容量足够大的时候,经验风险最小化能保证有很好的学习效果,在现实中被广泛应用,比如,极大似然估计(maximum likelihood estimation)就是经验风险最小化的一个例子,当模型是条件概率分布,损失函数是对数损失函数时,经验风险最小化就等价于极大似然估计。
11.3 结构风险
但是,当样本容量很小时,经验风险最小化的学习的效果就未必很好,会产生“过拟合”现象。
结构风险最小化(structural risk minimization,SMR)是为了防止过拟合而提出来的策略。结构风险在经验风险基础上加上表示模型复杂度的正则化项(regularizer)或罚项(penalty term)。在假设空间,损失函数以及训练数据集确定的情况下,结构风险的定义是:
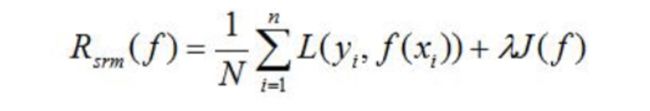
其中J(f)为模型的复杂度,是定义在假设空间F上的泛函,模型f越复杂。
11.4 结构风险最小化
复杂度J(f)就越大;反之,模型f就越简单,复杂度J(f)就越小,也就是说,复杂度表示对复杂模型的惩罚,lambda>=0是系数,是用以权衡经验风险和模型复杂度,结构风险小需要经验风险与模型复杂度同时小,结构风险小的模型往往对训练数据以及未知的测试数据都有较好的预测。
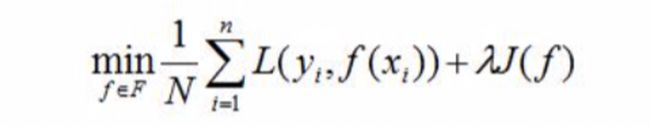
11.5 模型评估和模型选择
当损失函数给定时,基于损失函数的模型的训练误差和模型的测试误差就自然成为了学习方法评估的标准。

12. 正则化
模型选择的典型方法是正则化,正则化一般形式如下:
经验风险较小的模型可能较复杂,这时正则化项的值会较大,正则化的作用是选择经验风险与模型复杂度同时较小的模型。
正则化项符合奥卡姆剃刀原理,在所有的可能的模型中,能够很好的解析已知数据并且十分简单的模型才是最好的模型,从贝叶斯估计的角度来看,正则化项对应于模型的先验概率,可以假设复杂的模型有较小的先验概率,简单的模型有较大的先验概率。
13. 交叉验证
在机器学习中常用的精度测试方法,叫做交叉验证。它的目的是得到可靠稳定的模型,具体的做法是拿出大部分数据进行建模,留小部分样本用刚刚建立的模型进行预测,并求出这小部分样本预测的误差,交叉验证在克服过拟合问题上非常有效。接下来分别阐述:
13.1 简单交叉验证
简单交叉验证的方法是这样的,随机从最初的样本中选择部分,形成验证数据,而剩下的当作训练数据。一般来说,少于三分之一的数据被选作验证 数据。
13.2 K则交叉验证
10折交叉验证是把样本数据分成10份,轮流将其中9份做训练数据, 将剩下的1份当测试数据,10次结果的均值作为对算法精度的估计,通常情况下为了提高精度,还需要做多次10折交叉验证。
更进一步,还有K折交叉验证,10折交叉验证是它的特殊情况。K 折交叉验证就是把样本分为K份,其中K-1份用来做训练建立模型,留剩下的一份来验证,交叉验证重复K次,每个子样本验证一次。
13.3 留一验证
留一验证只使用样本数据中的一项当作验证数据,而剩下的全作为训练数据,一直重复,直到所有的样本都作验证数据一次。可以看出留 一验证实际上就是K折交叉验证,只不过这里的K有点特殊,K为样本数 据个数。
14. 机器学习库基础
借助于近些年发展起来诸多强大的开源库,我们现在是进入机器学习领域的最佳时机。不用像前些年那样需要自己使用编程语言一步一步实现机器学习算法,而是使用成熟的机器学习库帮我完成做好的算法,我们只需要了解清楚各个模型的参数如何调整就能够将模型应用于实际的业务场景。
基于Python的Sklearn库
- 简单高效的数据挖掘和数据分析工具
- 可供大家使用,可在各种环境中重复使用
- 建立在NumPy,SciPy和matplotlib上
- 开源,可商业使用-获取BSD许可证
基于Scala的SparkMLLIB
R与SparkR