利用朴素贝叶斯原理过滤垃圾邮件(TF-IDF算法)
本人是新手,为了还原该过程用了自己的方法,可能时间复杂度较高,并且在训练数据时也没有用到SKlearn模块中的贝叶斯分类器,是为了尝试自己去还原求后验条件概率这个过程。
目录
一、简述朴素贝叶斯原理
二、导入邮件数据集并提取出邮件正文部分,同时匹配标注好该正文是垃圾邮件还是正常邮件
三、将全体邮件的每个邮件正文进行分词,剔除停用词,并计算出每个分词的TF-IDF权重值
四、分割出训练集,利用TF-IDF值计算出每个分词出现的先验条件概率
五、在测试集中计算每封邮件的预测类,并计算出测试误差率,准确率,精确率,召回率,F1值。
一、简述朴素贝叶斯原理
记![]() ,其中
,其中![]() 表示该邮件不包含第
表示该邮件不包含第 个关键词,
个关键词,![]() 表示该邮件包含第个关键词,同时记
表示该邮件包含第个关键词,同时记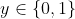 ,其中
,其中 表示该邮件为健康邮件,
表示该邮件为健康邮件, 表示该邮件为垃圾邮件。
表示该邮件为垃圾邮件。
现在有已经标注好的数据集![]()
我们的目标是求得![]() ,表示在该邮件包含一些关键词向量时,邮件是垃圾或者健康的概率为多少,可以由贝叶斯公式得到:
,表示在该邮件包含一些关键词向量时,邮件是垃圾或者健康的概率为多少,可以由贝叶斯公式得到:
![]()
![]()
即比较上述两式哪个概率更大,即为后验概率最大化,由于上述两式的分母一样,所以可得:
![]()
之所以叫朴素贝叶斯,即默认邮件中出现各个关键词的情况是相互独立的,比如认为一封邮件中出现类似“发票”、“优惠”、‘服务’这样的字样是互不影响的,即作了条件独立性假设,但是在现实情况中,关键词的出现并不是完全独立,这也是朴素贝叶斯的缺点,所以朴素贝叶斯适合小规模数据的分类,有了上述假设,那么上述的公式可以大大化简为:
![]()
即是通过训练样本用最大似然估计的方法求得每个关键词特征的先验条件概率,当面临一封新邮件时就通过后验概率最大化来判断这是健康邮件还是垃圾邮件。
二、导入邮件数据集并提取出邮件正文部分,同时匹配标注好该正文是垃圾邮件还是正常邮件
邮件数据集可以在https://plg.uwaterloo.ca/cgi-bin/cgiwrap/gvcormac/foo06下载,共6万封邮件,垃圾邮件:正常邮件的比例约为65:35左右。下载出来的文件包包含data文件夹和index文件夹,data文件夹下有子目录,在子目录下才是邮件的列表,而index文件夹其中只有一个index文件,即为每封邮件的标注,第一个目的是将邮件正文提取,然后与标注对应好



可以看到邮件的正文部分都是源于文件中的第一个出现的空行
我们先用for循环提取出每个邮件的地址
import codecs #解码器
import os #文件执行模块
import re #字符串匹配库
import csv
path = 'E:\Study\训练数据集\垃圾邮件\\trec06c\data'
"""将所有邮件中的正文部分剔除掉所有非中文字符和空格并提取出来"""
groups = os.listdir(path) #返回一个路径下的所有目录名
main_content_dic = {} #创建一个空字典,留着存储邮件编号和对应的正文内容
for group in groups: #迭代子目录
group_path = path + '\\' + group #将文件路径再深入一级
mail_number = os.listdir(group_path) #再返回深入一级的文件目录
for mail in mail_number: #迭代邮件文件目录
mail_path = group_path + '\\' + mail #定义根目录的路径
key = str(mail_path)[-8:-4] + str(mail_path)[-3:] #作为字典的键
mail_content = codecs.open(mail_path,'r','gbk',errors='ignore') #打开每个邮件
count = 1 #记录初始行数为1然后定位到每封邮件出现正文的那一行,记录行数,同时再记录邮件总行数
"""下面为了定位到正文开始的那一行"""
for line in mail_content.readlines(): #逐行读取这封邮件
line_noblank = line.rstrip() #剔除空行
if line_noblank != '': #搞个条件判断,如果该行不为空,那么行数就加1
count += 1
else:
break #退出的条件就是该行为空了,也就是邮件正文内容了
mail_content.seek(0) #指针返回开头
rows = len(mail_content.readlines()) #统计该邮件总行数
mail_content.seek(0) #指针再返回开头
main_content = mail_content.readlines()[count:rows] #只读取有正文开始前的空白行到邮件末尾然后再利用两个记录好的行数(正文开始行、正文结束行)来提取邮件正文,剔除所有空格和非中文字符,并用字典的值保存正文,字典的键是可以和index文件中索引相匹配的邮件地址后几位
"""这时候才是返回出正文并生成字典"""
for line in main_content: #再次迭代
line_noblank = line.strip('\n') #再次将正文中的空行剔除
email += line_noblank #给加到空字符串中
email_noblank = email.replace(" ", "") #剔除掉正文中所有空格
email_noblank = re.sub("([^\u4e00-\u9fa5])", '', email_noblank) #剔除掉正文中所有非中文字符
main_content_dic[key] = email_noblank下面将index文件中的邮件标注和地址提取出来建立一个字典,将地址索引作为键,标注作为值
"""将邮件的标签提取出来建立字典"""
index_content = codecs.open('E:\Study\训练数据集\垃圾邮件\\trec06c - 副本\\full\\index',
'r','gbk',errors='ignore') #打开索引文件
index_list = [] #定义空列表
index_dic = {} #定义空字典
for line in index_content.readlines(): #逐行读取索引文件
line_noblank = line.strip() #剔除空行
line_sub = line_noblank.replace("/",'\\') #将每行里的斜杠替换成跟邮件地址序号一致的(方便后续匹配)
index_list.append(line_sub) #列表加入一个该行内容
for i in index_list: #再迭代这个列表
label = str(i)[:4] #将标签提取出
if label == 'spam': #将是否为垃圾邮件定义为1或0
label = 1
else:
label = 0
index = str(i)[-8:-4] + str(i)[-3:]
index_dic[index] = label #添加字典,将地址序号作为键,标签作为值
然后将两个字典写到一个CSV文件里,6万行问题不大
with open("main_content_dic.csv", "w", encoding="gbk", newline="") as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["index", "main_content"])
for index,main_content in main_content_dic.items():
csv_writer.writerow([str(index),main_content])
print("写入数据成功")
f.close()
with open("index_dic.csv", "w", encoding="gbk", newline="") as g:
csv_writer = csv.writer(g)
csv_writer.writerow(["index", "label"])
for index,label in index_dic.items():
csv_writer.writerow([str(index),label])
print("写入数据成功")
g.close()通过在CSV文件中VLOOKUP一下,可以得到这样的一个文件,即把邮件正文和标注对应了

三、将全体邮件的每个邮件正文进行分词,剔除停用词,并计算出每个分词的TF-IDF权重值
用jieba把每行邮件正文分词
import jieba.analyse #导入分词库
import numpy as np #导入numpy库
import pandas as pd #导入pandas库
from sklearn.feature_extraction.text import TfidfVectorizer #导入求解TF-IDF值的SKlearn库
import csv #导入csv库
from functools import reduce #导入reduce,方便连乘条件概率
jieba.setLogLevel(jieba.logging.INFO) #该声明可以避免分词时报错
with open('E:\Study\训练数据集\垃圾邮件\\trec06c\stopwords.txt','r',encoding='utf-8') as file1: #打开停用词文件
stopwords = file1.read()
stopwords_list = stopwords.split('\n') #去除该txt文件里的换行
main_content = pd.read_csv('E:\Study\PY\Study\Spam_mail_classification\main_content_dic.csv',
encoding='gbk') #读入上一部分导出的邮件正文对应标注好的文件
mail_text = main_content['main_content'] #提取邮件正文列
cutwords_list = [] #建立一个分词空列表
for line in mail_text: #对这个每行邮件正文迭代
cutwords = [i for i in jieba.lcut(line) if i not in set(stopwords_list)] #每行正文分词并且剔除停用词
cutwords_list.append(cutwords) #分好的一组词加入到分词列表
cutwords_list_deal = [' '.join(text) for text in cutwords_list] #将分词列表里的词用空格相连然后计算每封邮件每个词组的TF-IDF值,并转换为稀疏矩阵
TF是指某个词组在该篇文章中的频次,TF值越大,说明这个词组在该篇文章中代表性越高
但是有些词语,例如“你好”这种,无论在哪篇文章中TF值都很大,但其没有什么代表性,所以不能单看TF值,所以又有IDF值,这是用(总文档数/包含该词的文档数+1),然后取对数,总体意思是如果IDF值高,那么代表该词在其他文档中出现的次数少,就避免了“你好”这种作为特征词的出现,所以TF和IDF是相互折中的存在,所以二者相乘做了一个调和,TF-IDF值的高低就表明了该词在这篇文章中的代表性。
"""开始计算每行邮件正文分词的TF-IDF值"""
tfidf = TfidfVectorizer(token_pattern=r"(?u)\b\w\w+\b",max_features=7000,max_df=0.6,min_df=5)
#剔除非中文字符,最大特征词数量控制在7000,同时在所有邮件中出现超过60%的不要(无代表性),也剔除仅出现小于5条的词汇
wrod_tfidf_array1 = tfidf.fit_transform(cutwords_list_deal) #将特征词的TF-IDF值转换为稀疏矩阵
keyword = tfidf.get_feature_names_out() #获取特征词的名称
wrod_tfidf_array2 = pd.DataFrame(wrod_tfidf_array1.toarray(),columns=keyword)
#将特征词的名称,对应其TF-IDF值建立一个矩阵
print(wrod_tfidf_array1) #打印TF-IDF稀疏矩阵
print(wrod_tfidf_array2) #打印包含特征词的矩阵
print(tfidf.vocabulary_) #打印特征词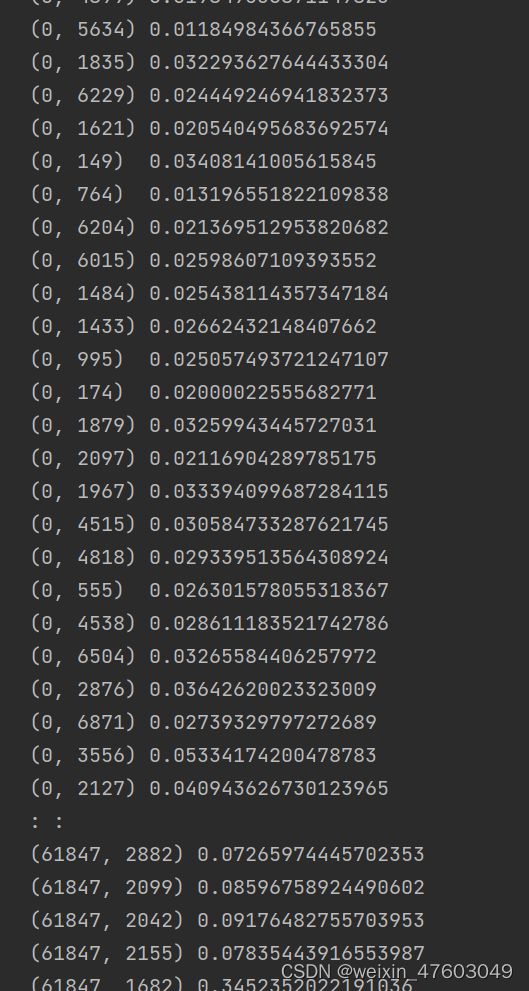
如第一行(0, 4899) 0.019849536871149823,0表示第一封邮件,4899表示序号为4899的词组,也就是‘电话传真’这个词的TF-IDF值为0.019849536871149823
四、分割出训练集,利用TF-IDF值计算出每个分词出现的先验条件概率
然后分割出训练集70%,计算出每个词组的先验条件概率,这里的先验条件概率我并不是通过查每封邮件出现的个数来计算的,是分别将垃圾邮件和健康邮件的每个特征词的TF-IDF值经过正则化然后分组求和,再分别求每个词的总TF-IDF值在垃圾邮件和健康邮件中的占比,这样虽然不是严格意义上的条件概率,但是他代表了条件概率的意义,就是例如在y=1的条件下x(1)=1发生的可能性,因为TF-IDF值越大,也代表当这封邮件是垃圾邮件或健康邮件时,他包含这个词语的可能性越大,然后把条件概率表导出来供后续测试使用。
"""切割好训练集,此时来计算每个词组的先验条件概率"""
label = main_content['label'] #把标注列提取出来
wrod_tfidf_array2.insert(0,'label',label) #加入到TF-IDF矩阵中的第一列前
word_tfidf_array2_train = wrod_tfidf_array2.iloc[:int(wrod_tfidf_array2.shape[0]*0.7),:]
#选取前70%的数据作为训练集
deal1 = word_tfidf_array2_train.groupby('label') #用groupby分组统计
wrod_tfidf_array2_train_deal = pd.DataFrame(deal1.sum()) #分别给各个特征词的在标注为1和0时把TF-IDF值求和
spam_health_situation = pd.DataFrame(deal1.size()) #看下训练集里垃圾邮件和健康邮件数量
print(spam_health_situation.iloc[0,0]) #看下健康邮件数量
print(spam_health_situation.iloc[1,0]) #看下垃圾邮件数量
"""下面注意正则化,防止0概率的出现影响结果"""
health_tfidf_sum = sum(wrod_tfidf_array2_train_deal.iloc[0]) + wrod_tfidf_array2_train_deal.shape[1]
spam_tfidf_sum = sum(wrod_tfidf_array2_train_deal.iloc[1]) + wrod_tfidf_array2_train_deal.shape[1]
#分别求和垃圾和健康邮件的TF-IDF值,并且都加上正则化值,这里取的是列数,因为后续分母上每个特征词的TF-IDF值都要加1
list_cp0,list_cp1 = [],[] #建立两个条件概率列表
for i in range(wrod_tfidf_array2_train_deal.shape[1]): #每列做迭代
conditional_probablity_0 = (wrod_tfidf_array2_train_deal.iloc[0,i]+1) / (health_tfidf_sum)
conditional_probablity_1 = (wrod_tfidf_array2_train_deal.iloc[1,i]+1)/ (spam_tfidf_sum)
list_cp0.append(conditional_probablity_0)
list_cp1.append(conditional_probablity_1)
#上述为每个元素都求好先验条件概率并加入健康和垃圾列表
for j in range(wrod_tfidf_array2_train_deal.shape[1]):
wrod_tfidf_array2_train_deal.iloc[0,j] = list_cp0[j]
wrod_tfidf_array2_train_deal.iloc[1,j] = list_cp1[j]
#上述为再把两行TF-IDF求和表改变成条件概率列表,这里已经正则化
"""把训练集的条件概率列表导出来留作备用,当然不导出CSV也行"""
wrod_tfidf_array2_train_deal.to_csv('wrod_tfidf_array2_train_deal.csv')
print(wrod_tfidf_array2_train_deal)先验条件概率表是下面这个样子:

五、在测试集中计算每封邮件的预测类,并计算出测试误差率,准确率,精确率,召回率,F1值。
最后就可以测试了,就是按照
![]()
该公式求出每封邮件的两个后验条件概率,比大小,大的就取其对应预测值
"""下面开始测试数据"""
probablity_health_tem = [] #建立一个健康条件概率临时表
probablity_spam_tem = [] #建立一个垃圾条件概率临时表
compute_y_list = [] #建立一个最终预测值表
word_tfidf_array2_test = wrod_tfidf_array2.iloc[int(wrod_tfidf_array2.shape[0]*0.7)+1:,:]
#取出后30%数据作为测试集
for i in range(0,word_tfidf_array2_test.shape[0]): #外面对每行测试数据迭代
for j in range(0,word_tfidf_array2_test.shape[1]-1): #里面迭代每一列
if word_tfidf_array2_test.iloc[i,j+1] != 0: #当测试分词的TF-IDF值不为0时,即说明该词在这封邮件里有代表性
probablity_health_tem.append(wrod_tfidf_array2_train_deal.iloc[0,j])
#健康列表加入对应到上面的条件概率表对应位置的概率
probablity_spam_tem.append(wrod_tfidf_array2_train_deal.iloc[1,j])
#垃圾列表加入对应到上面的条件概率表对应位置的概率
else:
pass
multiply_health = reduce(lambda x, y: x*y, probablity_health_tem,1) * \
(spam_health_situation.iloc[0,0] /
(spam_health_situation.iloc[0,0] + spam_health_situation.iloc[1,0]))
#计算这一封邮件为健康邮件时的后验条件概率
multiply_spam = reduce(lambda x, y: x*y, probablity_spam_tem,1) * \
(spam_health_situation.iloc[1,0] /
(spam_health_situation.iloc[0,0] + spam_health_situation.iloc[1,0]))
# 计算这一封邮件为垃圾邮件时的后验条件概率
if multiply_spam >= multiply_health: #一个简单的判断
y = 1
else:
y = 0
compute_y_list.append(y) #预测值加入预测列表
probablity_spam_tem.clear()
probablity_health_tem.clear() #两个中转列表清空准备下一次迭代然后经过差不多3个小时的计算,可以得出各项测试指标:
"""可以计算各种误差值了"""
compute_y = np.array(compute_y_list)
real_y = np.array(word_tfidf_array2_test['label']) #将预测列表和真实列表值转换为数组方便运算
error_test = sum(compute_y-real_y) / len(compute_y) #计算测试误差
TP,FN,FP,TN = 0,0,0,0 #开始计算分类问题的四项指标
for i in range(0,len(compute_y)):
if real_y[i] == 1 and compute_y[i] == 1:
TP += 1
if real_y[i] == 1 and compute_y[i] == 0:
FN += 1
if real_y[i] == 0 and compute_y[i] == 1:
FP += 1
if real_y[i] == 0 and compute_y[i] == 0:
TN += 1
accurate_rate = TP/(TP+FP) #精确率
recall_rate = TP/(TP+FN) #召回率
correct_rate = (TP+TN)/(TP+TN+FP+FN) #准确率
F1_score = (2 * TP) / (2 * TP + FP + FN) #F1值
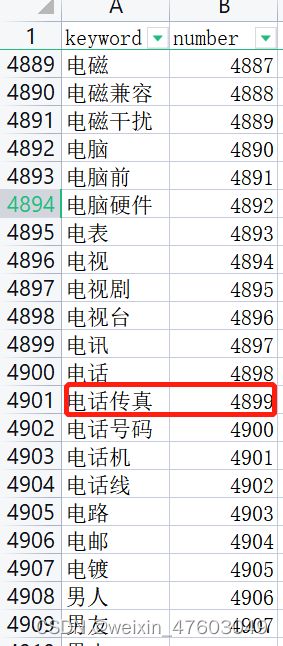
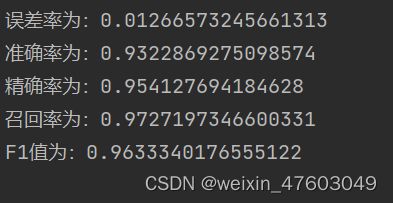
print(f"误差率为:{error_test}")
print(f"准确率为:{correct_rate}")
print(f"精确率为:{accurate_rate}")
print(f"召回率为:{recall_rate}")
print(f"F1值为:{F1_score}")最后得到的数据可见在测试中表现良好:
误差率的公式为:
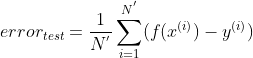
准确率——代表你预估对的概率
精确率——代表你认为是对的里面真正是对的的概率
召回率——代表本身是对的里面你真正算对的概率
F1值——是把精确率和召回率作了一个调和
至此,朴素贝叶斯分类垃圾邮件做完了,算法比较笨拙,还有很多提升空间,就当熟悉整个过程了,同时加深对贝叶斯方法的实践方法的了解
以下为全部代码:
import codecs #解码器
import os #文件执行模块
import re #字符串匹配库
import csv
path = 'E:\Study\训练数据集\垃圾邮件\\trec06c\data'
"""将所有邮件中的正文部分剔除掉所有非中文字符和空格并提取出来"""
groups = os.listdir(path) #返回一个路径下的所有目录名
main_content_dic = {} #创建一个空字典,留着存储邮件编号和对应的正文内容
for group in groups: #迭代子目录
group_path = path + '\\' + group #将文件路径再深入一级
mail_number = os.listdir(group_path) #再返回深入一级的文件目录
for mail in mail_number: #迭代邮件文件目录
mail_path = group_path + '\\' + mail #定义根目录的路径
key = str(mail_path)[-8:-4] + str(mail_path)[-3:] #作为字典的键
mail_content = codecs.open(mail_path,'r','gbk',errors='ignore') #打开每个邮件
count = 1 #记录初始行数为1
"""下面为了定位到正文开始的那一行"""
for line in mail_content.readlines(): #逐行读取这封邮件
line_noblank = line.rstrip() #剔除空行
if line_noblank != '': #搞个条件判断,如果该行不为空,那么行数就加1
count += 1
else:
break #退出的条件就是该行为空了,也就是邮件正文内容了
mail_content.seek(0) #指针返回开头
rows = len(mail_content.readlines()) #统计该邮件总行数
mail_content.seek(0) #指针再返回开头
main_content = mail_content.readlines()[count:rows] #只读取有正文开始前的空白行到邮件末尾
email = '' #定义一个空字符串用来存邮件正文
"""这时候才是返回出正文并生成字典"""
for line in main_content: #再次迭代
line_noblank = line.strip('\n') #再次将正文中的空行剔除
email += line_noblank #给加到空字符串中
email_noblank = email.replace(" ", "") #剔除掉正文中所有空格
email_noblank = re.sub("([^\u4e00-\u9fa5])", '', email_noblank) #剔除掉正文中所有非中文字符
main_content_dic[key] = email_noblank
"""将邮件的标签提取出来建立字典"""
index_content = codecs.open('E:\Study\训练数据集\垃圾邮件\\trec06c - 副本\\full\\index',
'r','gbk',errors='ignore') #打开索引文件
index_list = [] #定义空列表
index_dic = {} #定义空字典
for line in index_content.readlines(): #逐行读取索引文件
line_noblank = line.strip() #剔除空行
line_sub = line_noblank.replace("/",'\\') #将每行里的斜杠替换成跟邮件地址序号一致的(方便后续匹配)
index_list.append(line_sub) #列表加入一个该行内容
for i in index_list: #再迭代这个列表
label = str(i)[:4] #将标签提取出
if label == 'spam': #将是否为垃圾邮件定义为1或0
label = 1
else:
label = 0
index = str(i)[-8:-4] + str(i)[-3:]
index_dic[index] = label #添加字典,将地址序号作为键,标签作为值
with open("main_content_dic.csv", "w", encoding="gbk", newline="") as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["index", "main_content"])
for index,main_content in main_content_dic.items():
csv_writer.writerow([str(index),main_content])
print("写入数据成功")
f.close()
with open("index_dic.csv", "w", encoding="gbk", newline="") as g:
csv_writer = csv.writer(g)
csv_writer.writerow(["index", "label"])
for index,label in index_dic.items():
csv_writer.writerow([str(index),label])
print("写入数据成功")
g.close()
import jieba.analyse #导入分词库
import numpy as np #导入numpy库
import pandas as pd #导入pandas库
from sklearn.feature_extraction.text import TfidfVectorizer #导入求解TF-IDF值的SKlearn库
import csv #导入csv库
from functools import reduce #导入reduce,方便连乘条件概率
jieba.setLogLevel(jieba.logging.INFO) #该声明可以避免分词时报错
with open('E:\Study\训练数据集\垃圾邮件\\trec06c\stopwords.txt','r',encoding='utf-8') as file1: #打开停用词文件
stopwords = file1.read()
stopwords_list = stopwords.split('\n') #去除该txt文件里的换行
main_content = pd.read_csv('E:\Study\PY\Study\Spam_mail_classification\main_content_dic.csv',
encoding='gbk') #读入上一部分导出的邮件正文对应标注好的文件
mail_text = main_content['main_content'] #提取邮件正文列
cutwords_list = [] #建立一个分词空列表
for line in mail_text: #对这个每行邮件正文迭代
cutwords = [i for i in jieba.lcut(line) if i not in set(stopwords_list)] #每行正文分词并且剔除停用词
cutwords_list.append(cutwords) #分好的一组词加入到分词列表
cutwords_list_deal = [' '.join(text) for text in cutwords_list] #将分词列表里的词用空格相连
"""开始计算每行邮件正文分词的TF-IDF值"""
tfidf = TfidfVectorizer(token_pattern=r"(?u)\b\w\w+\b",max_features=7000,max_df=0.6,min_df=5)
#剔除非中文字符,最大特征词数量控制在7000,同时在所有邮件中出现超过60%的不要(无代表性),也剔除仅出现小于5条的词汇
wrod_tfidf_array1 = tfidf.fit_transform(cutwords_list_deal) #将特征词的TF-IDF值转换为稀疏矩阵
keyword = tfidf.get_feature_names_out() #获取特征词的名称
wrod_tfidf_array2 = pd.DataFrame(wrod_tfidf_array1.toarray(),columns=keyword)
#将特征词的名称,对应其TF-IDF值建立一个矩阵
print(wrod_tfidf_array1) #打印TF-IDF稀疏矩阵
print(wrod_tfidf_array2) #打印包含特征词的矩阵
print(tfidf.vocabulary_) #打印特征词
"""将特征词和序号导出一个表,方便自己看"""
with open("keyword_number.csv", "w", encoding="gbk", newline="") as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["keyword", "number"])
for keyword,number in tfidf.vocabulary_.items():
csv_writer.writerow([keyword,number])
print("写入数据成功")
f.close()
"""将每行邮件的特征词导出来,无可厚非,可以看看"""
with open("cutwords_list_deal.csv", "w", encoding="gbk", newline="") as f:
csv_writer = csv.writer(f)
for cutwords in cutwords_list_deal:
csv_writer.writerow([cutwords])
print("写入数据成功")
f.close()
"""切割好训练集,此时来计算每个词组的先验条件概率"""
label = main_content['label'] #把标注列提取出来
wrod_tfidf_array2.insert(0,'label',label) #加入到TF-IDF矩阵中的第一列前
word_tfidf_array2_train = wrod_tfidf_array2.iloc[:int(wrod_tfidf_array2.shape[0]*0.7),:]
#选取前70%的数据作为训练集
deal1 = word_tfidf_array2_train.groupby('label') #用groupby分组统计
wrod_tfidf_array2_train_deal = pd.DataFrame(deal1.sum()) #分别给各个特征词的在标注为1和0时把TF-IDF值求和
spam_health_situation = pd.DataFrame(deal1.size()) #看下训练集里垃圾邮件和健康邮件数量
print(spam_health_situation.iloc[0,0]) #看下健康邮件数量
print(spam_health_situation.iloc[1,0]) #看下垃圾邮件数量
"""下面注意正则化,防止0概率的出现影响结果"""
health_tfidf_sum = sum(wrod_tfidf_array2_train_deal.iloc[0]) + wrod_tfidf_array2_train_deal.shape[1]
spam_tfidf_sum = sum(wrod_tfidf_array2_train_deal.iloc[1]) + wrod_tfidf_array2_train_deal.shape[1]
#分别求和垃圾和健康邮件的TF-IDF值,并且都加上正则化值,这里取的是列数,因为后续分母上每个特征词的TF-IDF值都要加1
list_cp0,list_cp1 = [],[] #建立两个条件概率列表
for i in range(wrod_tfidf_array2_train_deal.shape[1]): #每列做迭代
conditional_probablity_0 = (wrod_tfidf_array2_train_deal.iloc[0,i]+1) / (health_tfidf_sum)
conditional_probablity_1 = (wrod_tfidf_array2_train_deal.iloc[1,i]+1)/ (spam_tfidf_sum)
list_cp0.append(conditional_probablity_0)
list_cp1.append(conditional_probablity_1)
#上述为每个元素都求好先验条件概率并加入健康和垃圾列表
for j in range(wrod_tfidf_array2_train_deal.shape[1]):
wrod_tfidf_array2_train_deal.iloc[0,j] = list_cp0[j]
wrod_tfidf_array2_train_deal.iloc[1,j] = list_cp1[j]
#上述为再把两行TF-IDF求和表改变成条件概率列表,这里已经正则化
"""把训练集的条件概率列表导出来留作备用,当然不导出CSV也行"""
wrod_tfidf_array2_train_deal.to_csv('wrod_tfidf_array2_train_deal.csv')
print(wrod_tfidf_array2_train_deal)
"""下面开始测试数据"""
probablity_health_tem = [] #建立一个健康条件概率临时表
probablity_spam_tem = [] #建立一个垃圾条件概率临时表
compute_y_list = [] #建立一个最终预测值表
word_tfidf_array2_test = wrod_tfidf_array2.iloc[int(wrod_tfidf_array2.shape[0]*0.7)+1:,:]
#取出后30%数据作为测试集
for i in range(0,word_tfidf_array2_test.shape[0]): #外面对每行测试数据迭代
for j in range(0,word_tfidf_array2_test.shape[1]-1): #里面迭代每一列
if word_tfidf_array2_test.iloc[i,j+1] != 0: #当测试分词的TF-IDF值不为0时,即说明该词在这封邮件里有代表性
probablity_health_tem.append(wrod_tfidf_array2_train_deal.iloc[0,j])
#健康列表加入对应到上面的条件概率表对应位置的概率
probablity_spam_tem.append(wrod_tfidf_array2_train_deal.iloc[1,j])
#垃圾列表加入对应到上面的条件概率表对应位置的概率
else:
pass
multiply_health = reduce(lambda x, y: x*y, probablity_health_tem,1) * \
(spam_health_situation.iloc[0,0] /
(spam_health_situation.iloc[0,0] + spam_health_situation.iloc[1,0]))
#计算这一封邮件为健康邮件时的后验条件概率
multiply_spam = reduce(lambda x, y: x*y, probablity_spam_tem,1) * \
(spam_health_situation.iloc[1,0] /
(spam_health_situation.iloc[0,0] + spam_health_situation.iloc[1,0]))
# 计算这一封邮件为垃圾邮件时的后验条件概率
if multiply_spam >= multiply_health: #一个简单的判断
y = 1
else:
y = 0
compute_y_list.append(y) #预测值加入预测列表
probablity_spam_tem.clear()
probablity_health_tem.clear() #两个中转列表清空准备下一次迭代
"""可以计算各种误差值了"""
compute_y = np.array(compute_y_list)
real_y = np.array(word_tfidf_array2_test['label']) #将预测列表和真实列表值转换为数组方便运算
error_test = sum(compute_y-real_y) / len(compute_y) #计算测试误差
TP,FN,FP,TN = 0,0,0,0 #开始计算分类问题的四项指标
for i in range(0,len(compute_y)):
if real_y[i] == 1 and compute_y[i] == 1:
TP += 1
if real_y[i] == 1 and compute_y[i] == 0:
FN += 1
if real_y[i] == 0 and compute_y[i] == 1:
FP += 1
if real_y[i] == 0 and compute_y[i] == 0:
TN += 1
accurate_rate = TP/(TP+FP) #精确率
recall_rate = TP/(TP+FN) #召回率
correct_rate = (TP+TN)/(TP+TN+FP+FN) #准确率
F1_score = (2 * TP) / (2 * TP + FP + FN) #F1值
print(f"误差率为:{error_test}")
print(f"准确率为:{correct_rate}")
print(f"精确率为:{accurate_rate}")
print(f"召回率为:{recall_rate}")
print(f"F1值为:{F1_score}")