Mask RCNN 网络详解
1.Mask RCNN介绍
Mask R-CNN论文地址:https://arxiv.org/abs/1703.06870,论文于2017年发表在ICCV上,获得了2017年ICCV的最佳论文奖。
我们可以看到论文的一作是ResNet的何凯明,还有提出Faster RCNN系列的Ross Girshick.
2. Mask RCNN
Mask R-CNN是在Faster R-CNN的基础上加了一个用于预测目标分割Mask的分支(即可预测目标的Bounding Boxes信息、类别信息以及分割Mask信息)。
Mask R-CNN不仅能够同时进行目标检测与分割,还能很容易地扩展到其他任务,比如再同时预测人体关键点信息。
2.1 Mask RCNN网络结构
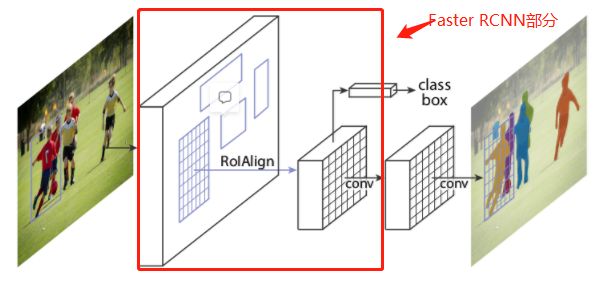
- 图中红框的部分是
Faster RCNN,Mask R-CNN的结构也很简单,就是在通过RoIAlign(在原Faster R-CNN论文中是RoIPool)得到的RoI基础上并行添加一个Mask分支(小型的FCN)。通过Mask分支我们就能对我们检测的每一个目标生成一个Mask分割蒙版。如果想检测每个人的关键点信息,也可以并联一个keypoints detection分支。 - 其实在
Faster -RCNN源码中使用的也是RoiAlign,而不是RoIPooling
对于Mask分支论文中作者也讲到其实它跟FCN非常相似,下图是作者给出Mask分支更加详细的结构,我们可以看到其实它有两个不同的形式。
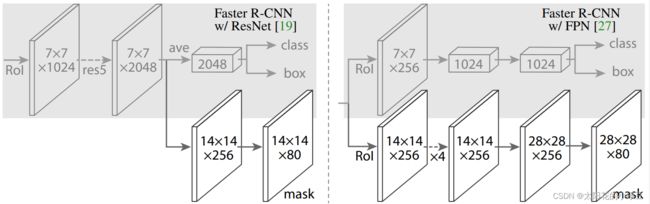
左边的结构是不带有FPN(特征金字塔结构),右边是带有FPN结构(FPN使用在Faster-RCNN的backbone中)的,并且在我们日常使用过程中,更加常用的也是右边的分支,接下来我们也会以右边为例进行网络讲解。
2.2 RoIAligin
2.2.1 RoIPool
在之前的Faster RCNN中,会使用RoIPool将RPN得到的Proposal池化到相同大小。这个过程会涉及quantization或者说取整操作,这会导致定位不是那么的准确(文中称为misalignment问题)。
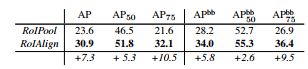
- 图中表格右半部分是针对目标检测任务的,我们如果采用之前的
RoI Pooling的话,对应的AP值为28.2,如果采用RoIAlign的话就能达到34,很明显提升了5.8个点,提升的效果非常明显。图中左半部分是针对分割的场景,同样采用RoI Pooling的话对应的AP为23.6,如果采用RoIAlign的话AP就能达到30.9,一下子就提升了7.3个点。通过这几组数据,很明显使用RoIAlign它的定位会更加准确
下面的示意图就是RoIPool的执行过程,其中会经历两次quantization。假设通过RPN得到了一个Proposal,它在原图上的左上角坐标是 ( 10 , 10 ) (10,10) (10,10),右下角的坐标是 ( 124 , 124 ) (124 , 124 ) (124,124) ,对应要映射的特征层相对原图的步距为32,通过RoIPool期望的输出为2x2大小
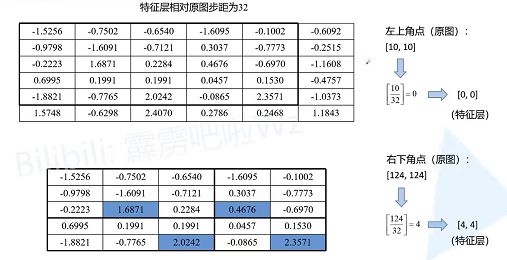
- 将
Proposal映射到特征层上,对于左上角坐标 ( 10 , 10 ) (10,10) (10,10),进行32倍下采样。 很明 10 32 \frac{10}{32} 3210 是不能被整除的,在RoIPooling中会对它进行四舍五入,就得到了对应特征图上左上角点后(0,0);同理对于右下角坐标 124 32 \frac{124}{32} 32124进行四舍五入得到右下角点的坐标为 ( 4 , 4 ) (4,4) (4,4)。将proposal映射到对应上图特征层上从第0行到第4行,从第0列到第4列的区域(黑色矩形框)。这是第一次quantization。 - 由于期望的输出为
2x2大小,所以需要将映射在特征层上的Proposal划分成2x2大小区域。但现在映射在特征层上的Proposal是5x5大小,无法整除均分,所以强行划分后有的区域大有的区域小,如上图所示。这是第二次quantization。 - 对划分后的每个子区域进行
maxpool即可得到RoIPool的输出, ( 1.6874 0.4676 2.0242 2.3571 ) \bigl( \begin{matrix} 1.6874 & 0.4676 \\ 2.0242 & 2.3571 \end{matrix} \bigr) (1.68742.02420.46762.3571),对应图中每个区域用蓝色标出来的4个数值。这边用torchvison中的RoIPool做了相关实验,代码如下:
import torch
from torchvision.ops import RoIPool
def main():
torch.manual_seed(1)
x=torch.randn(1,1,6,6)
print(f"feature map:\n{x}")
proposal=[torch.as_tensor([[10,10,124,124]],dtype=torch.float32)] #定义proposal 左上角点(10,10) 右下角度(124,124)
roi_pool=RoIPool(output_size=2,spatial_scale=1/32) #输出大小2x2 下采样为32倍
roi_pool(x,proposal)
print(f"roi pool":\n{roi})
if __name__=='__main__':
main()
终端输出:
feature map:
tensor([[[[-1.5256, -0.7502, -0.6540, -1.6095, -0.1002, -0.6092],
[-0.9798, -1.6091, -0.7121, 0.3037, -0.7773, -0.2515],
[-0.2223, 1.6871, 0.2284, 0.4676, -0.6970, -1.1608],
[ 0.6995, 0.1991, 0.1991, 0.0457, 0.1530, -0.4757],
[-1.8821, -0.7765, 2.0242, -0.0865, 2.3571, -1.0373],
[ 1.5748, -0.6298, 2.4070, 0.2786, 0.2468, 1.1843]]]])
roi pool:
tensor([[[[1.6871, 0.4676],
[2.0242, 2.3571]]]])
得到的输出和上面图片展示的是一样的。
2.2.2 RoIAlign
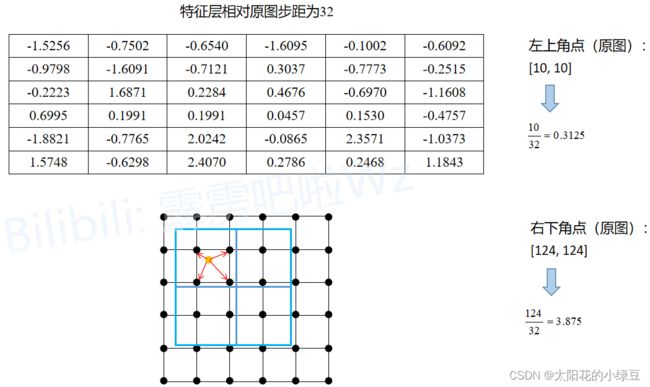
下面的示意图就是RoIAlign的执行过程。同样假设通过RPN得到了一个Proposal,它在原图上的左上角坐标是(10,10),右下角的坐标是 (124,124) (124,124),对应要映射的特征层相对原图的步距为32,通过RoIAlign期望的输出为2x2大小:
- 将
Proposal映射到特征层上,通过RoIAlign方式不会进行取整。根据 10 32 = 0.3125 \frac{10}{32}=0.3125 3210=0.3125,映射到特征图上左上角坐标为( 0.3125 , 0.3125 )(不进行四舍五入),同理右下角坐标根据$\frac{124}{32}=3.875,映射到特征图上右下角点坐标为( 3.875 , 3.875 )(不进行四舍五入)。为了方便理解,将特征层上的每个元素用一个点表示,就能得到图中下方的grid网格。图中蓝色的矩形框就是Proposal(没有quantization) - 由于期望输出为
2x2大小,故将Proposal均分为2x2四个子区域(没有quantization)。接着根据sampling_ratio在每个子区域中设置采样点,原论文中默认设置的sampling_ratio为2,区域内长宽位置均匀取4个采样点(当采用多个采样点时,每个区域的输出取所有采样点的均值),这里为了方便讲解将sampling_ratio设置成1,只采样一个点。 - 然后计算每个子区域中每个采样点的值,采样点值计算以离它最近的4个点通过双线性插值计算,最后对每个区域内的所有采样点取均值即为该子区域的输出。
这里以第一个子区域为例,因为这里将sampling_ratio设置成为1,所以每个子区域只需要设置一个采样点。第一个子区域的采样点为图中黄色的点(即为该子区域的中心点),坐标为 ( 1.203125 , 1.203125 ) ,然后找出离该采样点最近的四个点(即图中用红色箭头标出的四个黑点),然后利用双线性插值即可计算得到采样点对应的输出− 0.8546 (如果不了解双线性插值可参考博文),又由于该子区域只有一个采样点,故该子区域的输出就为 − 0.8546。同理其他子区域也是一样,分别找到各自区域的中心点,以及离中心点最近的4个点,利用双线性差值计算得到采样点的输出。
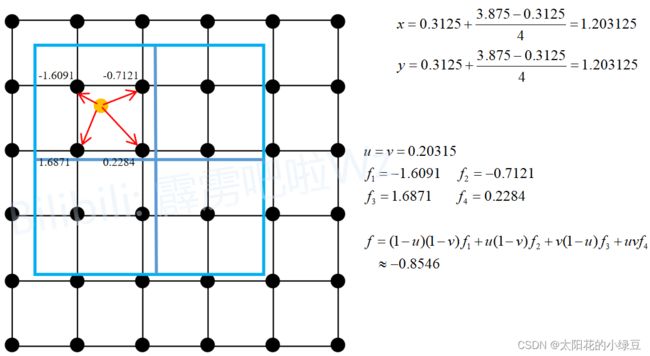
图中x,y为采样点的坐标位置, f 1 , f 2 , f 3 , f 4 f_1,f_2,f_3,f_4 f1,f2,f3,f4分别对应离采样点最近的四个点的数值, u u u表示采用点到所在网格Top距离, v v v表示采用点离所在网格的left距离。
下面是使用Torchvision库中实现的RoIAlign方法,通过对比计算结果和我们刚刚讲的是一样的。
import torch
from torchvision.ops import RoIAlign
def bilinear(u, v, f1, f2, f3, f4):
return (1-u)*(1-v)*f1 + u*(1-v)*f2 + (1-u)*v*f3 + u*v*f4
def main():
torch.manual_seed(1)
x = torch.randn((1, 1, 6, 6))
print(f"feature map: \n{x}")
proposal = [torch.as_tensor([[10, 10, 124, 124]], dtype=torch.float32)]
roi_align = RoIAlign(output_size=2, spatial_scale=1/32, sampling_ratio=1)
roi = roi_align(x, proposal)
print(f"roi align: \n{roi}")
u = 0.203125
v = 0.203125
f1 = x[0, 0, 1, 1] # -1.6091
f2 = x[0, 0, 1, 2] # -0.7121
f3 = x[0, 0, 2, 1] # 1.6871
f4 = x[0, 0, 2, 2] # 0.2284
print(f"bilinear: {bilinear(u, v, f1, f2, f3, f4):.4f}")
if __name__ == '__main__':
main()
终端输出:
feature map:
tensor([[[[-1.5256, -0.7502, -0.6540, -1.6095, -0.1002, -0.6092],
[-0.9798, -1.6091, -0.7121, 0.3037, -0.7773, -0.2515],
[-0.2223, 1.6871, 0.2284, 0.4676, -0.6970, -1.1608],
[ 0.6995, 0.1991, 0.1991, 0.0457, 0.1530, -0.4757],
[-1.8821, -0.7765, 2.0242, -0.0865, 2.3571, -1.0373],
[ 1.5748, -0.6298, 2.4070, 0.2786, 0.2468, 1.1843]]]])
roi align:
tensor([[[[-0.8546, 0.3236],
[ 0.2177, 0.0546]]]])
bilinear: -0.8546
可以看到torchvision实现的RoIAlign和我们计算的输出是一样的。通过我们讲的例子我们可以知道的RoIAlign在计算过程是没有涉及到任何取整操作的,所以它的定位会更加准确。作者在论文中也提到采样点的个数和位置对最终的结果并没什么影响,所以我们一般都把sample_rate设置为2,默认每个区域设置4个采样点。
Mask分支
前面有提到,对于带有FPN和不带有FPN的Mask R-CNN,他们的Mask分支不太一样。下图左边是不带FPN结构的Mask分支,右侧是带有FPN结构的Mask分支(灰色部分为原Faster R-CNN预测box, class信息的分支,白色部分为Mask分支)
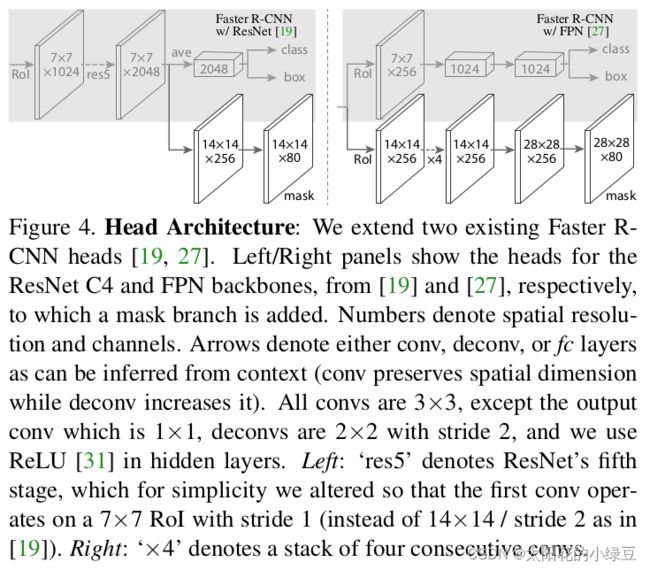
由于在我们日常使用中,一般都是·使用的带有FPN的网络,对于带FPN结构的Mask RCNN,它上面一个分支是Faster-RCNN预测器,注意它所使用的RoIAlign和下面的Mask分支采用的RoIAlign其实是不一样的,也就是这两个分支并不共用RoIAlign ,上面一个分支通过RoIAlign得到的RoI大小是7x7,但是在Mask分支中,我们通过RoIAlign得到的大小是14x14,因为对于分割任务而言,我们要求的分割结果,精度要高一些,所以需要保留更多的细节信息,所以Mask分支没有池化到7x7大小,而是池化到14x14。
绘制了带有FPN结构的Mask-RCNN的Mask分支。
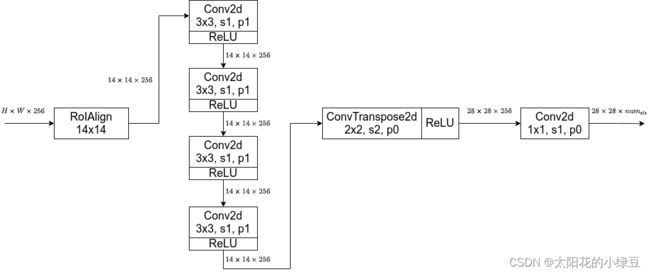
- 假设输入的特征矩阵是
HxWx256,经过RoIAlign之后被池化为14x14x256,接下来依次通过4个卷积层,这个四个卷积层后面都跟了ReLU激活函数,并且都是kernel为3x3,步距为1的卷积层。经过这4个卷积层我们得到的输出依旧是14x14x256,接下来再通过一个转置卷积,通过转置卷积会将输入特征的高宽进行翻倍,由14x14变为28x28,然后在通过一个1x1卷积来调整输出channel,使得channel等于分类的个数 n u m c l s num_{cls} numcls,最终输出的特征层大小为 28 ∗ 28 ∗ n u m c l a s s 28*28*num_{class} 28∗28∗numclass,也就是说针对每个类别我们都预测了一个蒙版,并且这个蒙版大小都是28x28。
在Mask R-CNN中,对预测的Mask以及Class进行解耦
之前在讲FCN的时候有提到过,FCN是对每个像素针对每个类别都会预测一个分数,然后对每个像素沿channel方向做softmax处理,得到每个像素归属每个类别的概率,不同类别之间存在竞争关系,哪个概率高就将该像素分配给哪个类别。(因为softmax处理后所有类别概率之和为1,某些概率值大了的话,其他类型额概的率就会变小,所以不同类别间存在竞争关系,也就是mask和class之间存在耦合关)但在Mask R-CNN中,作者将预测Mask和class进行了解耦,即对输入的RoI针对每个类别都单独预测一个Mask,但是我么不会针对每个像素沿channel方向做softmax处理,而是最终根据box, cls分支预测的classes信息来选择对应类别的Mask(不同类别之间不存在竞争关系)。作者说解耦后带来了很大的提升。下表是原论文中给出的消融实验结果,其中softmax代表原FCN方式(Mask和class未解耦),sigmoid代表Mask R-CNN中采取的方式(Mask和class进行了解耦)。
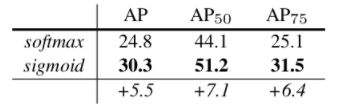
- 对应采用softmax耦合的方式,获得的
AP为24.8,采用sigmoid解耦的方式,获得的AP达到了30.3,提升了5.5个点。也就是说在Mask R-CNN中,对预测的Mask以及Class进行解耦是非常必要的。 - 这里还有一个需要注意的细节。在训练网络的时候输入Mask分支的目标是由RPN提供的,即Proposals,但在
预测的时候输入Mask分支的目标是由Fast R-CNN提供的(即预测的最终目标)。并且训练时采用的Proposals全部是Fast R-CNN阶段匹配到的正样本。这里说下我个人的看法(不一定正确),在训练时Mask分支利用RPN提供的目标信息能够扩充训练样本的多样性(因为RPN提供的目标边界框并不是很准确,一个目标可以呈现出不同的情景,类似于围着目标做随机裁剪。从另一个方面来看,通过Fast R-CNN得到的输出一般都比较准确了,再通过NMS后剩下的目标就更少了)。在预测时为了获得更加准确的目标分割信息以及减少计算量(通过Fast R-CNN后的目标数会更少),此时利用的是Fast R-CNN提供的目标信息。
Mask R-CNN的损失
Mask R-CNN损失
Mask R-CNN的损失就是在Faster R-CNN的基础上加上了Mask分支上的损失,即:
L o s s = L r p n + L f a s t r c n n + L m a s k Loss =L_{rpn} + L_{fast_rcnn} + L_{mask} Loss=Lrpn+Lfastrcnn+Lmask
关于Faster R-CNN的损失计算,这里就不在赘述,参考博文:RCNN、Fast-RCNN、Faster-RCNN理论合集,关于Mask分支上的损失就是二值交叉熵损失(Binary Cross Entropy)
Mask分支损失
- 在讲Mask分支损失计算之前,我们要弄清楚
logits(网络预测的输出)是什么,targets(对应的GT)是什么。前面有提到训练时输入Mask分支的目标是RPN提供的Proposals,所以网络预测的logits是针对每个Proposal对应每个类别的Mask信息(注意预测的Mask大小都是28x28)。并且这里输入的Proposals都是正样本(在Fast R-CNN阶段采样得到的),对应的GT信息(box、cls)也是知道的。 - 如下图所示,假设通过RPN得到了一个
Proposal(图中黑色的矩形框),通过RoIAlign后得到对应的特征信息(shape为14x14xC),接着通过Mask Branch预测每个类别的Mask信息得到图中的logits(logits通过sigmoid激活函数后,所有值都被映射到0至1之间)。通过Fast R-CNN分支正负样本匹配过程我们能够知道该Proposal的GT类别为猫(cat),所以将logits中对应类别猫的预测mask(shape为28x28)提取出来。然后根据Proposal在原图对应的GT上裁剪并缩放到28x28大小,得到图中的GT mask(对应目标区域为1,背景区域为0)。最后计算logits中预测类别为猫的mask与GT mask的BCELoss(BinaryCrossEntropyLoss)即可。

Mask Branch预测使用
这里再次强调一遍,在真正预测推理的时候,输入Mask分支的目标是由Fast R-CNN分支提供的。

如上图所示,通过Fast R-CNN分支,我们能够得到最终预测的目标边界框信息以及类别信息。接着将目标边界框信息(注意此处不是经过RPN得到的Proposals)提供给Mask分支,经过RoIAlign就能预测得到该目标的logits信息,再根据Fast R-CNN分支提供的类别信息将logits中对应该类别的Mask信息提取出来,即针对该目标预测的Mask信息(shape为28x28,由于通过sigmoid激活函数,数值都在0到1之间)。然后利用双线性插值将Mask缩放到预测目标边界框大小,并放到原图对应区域。接着通过设置的阈值(默认为0.5)将Mask转换成一张二值图,比如预测值大于0.5的区域设置为前景剩下区域都为背景。现在对于预测的每个目标我们就可以在原图中绘制出边界框信息,类别信息以及目标Mask信息
本博客参考:太阳花小绿豆的 Mask R-CNN网络详解