NLP 论文领读|无参数机器翻译遇上对比学习:效率和性能我全都要!
欢迎关注「澜舟论文领读」专栏!关注“澜舟科技”公众号探索更多 NLP 前沿论文!
本期分享者:付宇
澜舟科技算法研究实习生,天津大学硕士二年级,研究方向为检索增强机器翻译、文本摘要。邮箱:[email protected]
写在前面
检索式增强在各种自然语言处理任务中被广泛应用,其主要目的是基于一定的检索范式来利用现存数据,影响模型最终得到的结果,从而降低模型参数的负担。之前澜舟公众号已经发布了一篇相关的论文领读《别再第四范式:看看新热点检索增强怎么做文本生成!》对检索增强的任务进行了概述。本文我们聚焦在机器翻译领域,介绍在机器翻译中最新的利用检索来进行增强的范式!
论文标题
Efficient Cluster-Based k-Nearset-Neighbor Machine Translation
论文作者
Dexin Wang, Kai Fan, Boxing Chen, Deyi Xiong
论文单位
天津大学,阿里巴巴达摩院
论文链接:
https://aclanthology.org/2022.acl-long.154/
KNN 背景介绍
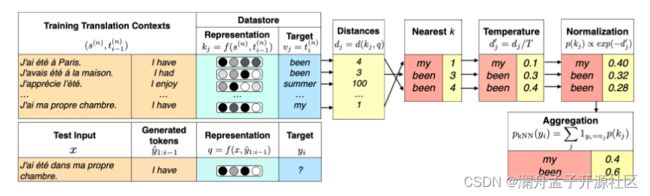
图 1 基于 KNN 的机器翻译模型
基于 KNN 的检索式增强首先在 Language Model 上被提出 [1],在 2021 的 ICLR 文章 [2] 中,首先将 KNN 增强的方法应用到了机器翻译上, 通过 KNN 的词级别的检索和融合,能够在不进行特定领域训练的前提下,有效提高模型在领域数据集上的效果。
其包含两个主要的步骤:首先是创建数据库(Datastore),也就是使用基础模型来进行正向传播,利用在解码时候映射到词表前的特征和对应的目标词作为键值对存储在 Datastore 中,对应图 1 中 Datastore 的 Representation 和 Target。正式翻译时,在每个具体的解码步骤中,使用相同位置的特征,从 Datastore 中进行向量检索,使用检索的结果以及对应的距离(Distances),结合温度超参数来计算得到最终的概率(对应公式 1),将得到的概率作为目标词概率按照一定比例融合到原始模型输出词表的概率分布上(对应公式 2)。
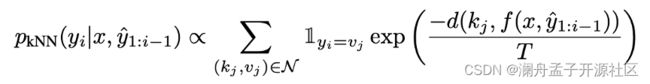
(公式 1)
其中 N \mathcal{N} N 表示在 Datastore 中进行向量检索得到的 N 个键值对, T T T 表示温度超参数, I y i = v i \mathbb{I}_{y_i=v_i} Iyi=vi 代表指示函数,表示只在对应满足条件的位置添加概率。
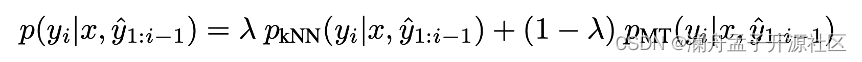
(公式 2)
其中 λ \lambda λ 是比例超参数, p k N N p_{kNN} pkNN 是上面介绍的 kNN 检索过程计算得到的对应概率,也就是对应公式 1, p M T p_{MT} pMT 表示基础模型得到的词表上的概率分布。
研究动机
虽然 2021 的 ICLR 文章 [2] 在实验部分进行了不同领域的实验,并且得到了良好的效果,展现出来了 KNN 无参数机器翻译在实际应用上的前景,但是在实际应用中存在两个主要的问题:
1. 存储大小。 对于 KNN 无参数机器翻译而言,在创建 Datastore 的时候,使用词以及对应的特征来作为存储的键值对,最终的 Datastore 的大小跟词的数量以及特征的维度是正相关的。
2. 时间延迟 。 因为 KNN 的向量检索是在每个解码步骤中进行的,随着 Datastore 的增大,向量检索的延迟会严重影响最终整体翻译的速度。
因此,在《Efficient Cluster-Based k-Nearset-Neighbor Machine Translation》这篇论文中,作者首先给出了一个在领域数据集上原始的机器翻译和 KNN 机器翻译的速度对比,其中 MT 表示的是原始机器翻译模型,AK-MT [3] 是 KNN-MT 的一个变种,也是该论文的 Base 模型。上述的两个主要的问题都与 Datastore 的大小有着密切的关系,作者基于对特征的可视化分析,提出了两个不同方向改进:
1. 特征维度。 使用一个额外的网络(Compact Network)来对模型的特征进行降维。并且基于不同的语义单元应该互相不重合的假设下,使用对比学习的方法来在降维的同时对不同的语义单元进行分割,增强向量检索的准确度。
2. 词数量。 使用一个剪枝策略来对 Datastore 中冗余的部分进行修剪从而降低 Datastore 的大小,进一步提升翻译的速度。
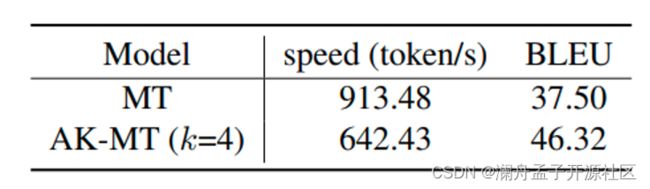
图 2 翻译速度对比
下面详细介绍该论文提出的两个方法。
基于聚类的特征维度压缩
在 KNN 机器翻译研究中使用的原始模型的特征维度通常是 1024 维,并且是在通用的数据上训练得到的模型。因此模型是缺少领域相关的知识的,并且高维语义空间下,向量是稀疏的并且带有噪声。使用传统的降维方法(比如 PCA),在相关的研究中 [4] 中被证明效果比较差,对于 1024 维而言,在保证性能的前提下,最多只能够降低到 512 维。
在这个部分,基于不同的语义单元以及对比学习的方法,作者不仅对特征维度进行进一步的压缩(1024 维 – 64 维),而且进一步提升了领域数据集上的性能。具体主要分为两个步骤:

图 3 Compact network
1. 形成基础的语义单元。 在这里引入了一个概念——Cluster Family。其表示的就是在 Datastore 中所有相同的目标词的键值对集合。对于一个 Cluster Family,使用传统的聚类方法来形成若干个簇(Cluster),使用得到的簇来作为最终的语义单元,体现在图 3 中的就是 Token A 和 Token B 分别形成了两个不同的簇,也就是得到四个基础语义单元。从图 3 中也可以看到,不同的簇之间可能是会存在重叠的部分,因此就需要下面的第二个步骤。
2. 对比训练。 不同的语义单元应该是互相不重合,因为重合会导致在检索时候的不准确问题,从而影响最终的翻译性能。具体的,在这里使用了两种不同模式的对比学习 loss,来对压缩后的特征进行训练。分别为:Triplet Noise-Contrastive Estimation (NCE) 和 Trplet Distance Ranking(DR),其中前者是使用一个额外的线性层来转成了一个分类任务,而后者是直接使用压缩后的特征来计算 L2 距离进行排序。
在对比学习的训练中,锚点和正例是从同一个簇中获得,而负例是从不同目标词的簇中获得。另外还有一个额外的 Word Prediction Loss(WP),是为了将语言学的信息融入到训练压缩特征的网络中。
从图 3 中可以看到,Compact Network 主要分为两个部分,也分别对应两个不同的作用,其中 f ( α ) f(\alpha) f(α) 是特征压缩层,用来对特征的维度进行压缩。 f ( θ ) f(\theta) f(θ) 是对比学习层,用来适应 NCE 的训练需要。特别的,训练 NCE 的 f ( θ ) f(\theta) f(θ) 的输出维度是 1,训练 WP 的 f ( θ ) f(\theta) f(θ) 的输出维度是目标语言的词表大小,训练 DR 的时候不需要 f ( θ ) f(\theta) f(θ) ,因为它是直接对压缩后的特征进行操作。
基于聚类的数据库剪枝
除了特征以外,词的数量是另一个影响 Datastore 大小,进而影响最终翻译速度的重要因素。针对 KNN 的具体过程,一个直观的动机就是:在具有相同目标词的情况下,如果对应特征之间的区分度足够小,那么是可以视为冗余部分并且进行删除的。作者从统计机器翻译中短语级别的剪枝策略更有效这一结果得到启发,设计了一种基于 N-Gram 的剪枝策略。
首先定义了一个具体的衡量标准——翻译代价(Translation Cost) 。具体的,针对某一个目标词,其翻译代价就是在这个目标词的来源语料中,以这个目标词作为结束词的 N-Gram 的困惑度,为了更好衡量翻译代价,使用 1 到 N 的 N-Gram 中的最低困惑度作为最终的翻译代价。
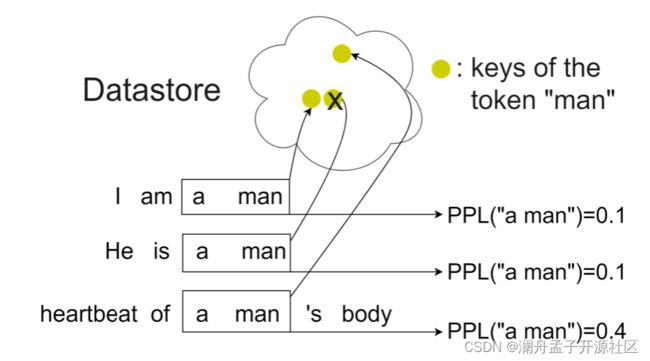
图 4 冗余的 2-gram 例子
如图 4 中,对于 Datastore 中的目标词 “man”来说,第一句和第二句得到的键值对相对而言就是冗余。在得到 Datastore 中所有目标词的翻译代价以后,在目标词的内部根据翻译代价来进行聚类,并且在剪枝的时候对所有得到的簇根据预设的比例进行随机采样,最终得到剪枝以后的 Datastore。
实验设置
论文中使用了 5 个不同的领域数据集分别为 IT、Koran、Medical、Law 和 Subtitles。其中前四个数据集是 Baseline 论文中使用的数据集,后者是包含了更多的数据用以表现剪枝的性能。对于特征维度也就是 f ( α ) f(\alpha) f(α) 的输出大小,实验中使用 IT 数据集在 [16, 32, 64, 128] 中进行搜索,并且最终确定为 64。剪枝策略中的 N-Gram 中的 1-N 设置为 1-2。
特征维度压缩性能
首先对论文中提出的不同损失和锚点选择方法进行了组合,在 IT 数据集上进行实验。其中 DY 代表随机选择簇中一个点,ST 表示选择簇中心作为固定的锚点。CL 代表在不同的 Cluster 间选择负例进行对比学习的训练,而不是把负例的选择约束在不同 Cluster Family 上的簇中。
值得注意的是,传统的降维方法(PCA & SVD)在性能上都有所降低。在三个 Loss 中,NCE 的效果表现最好,可能的原因是 NCE 的参数相较于 WP 来说更少,在使用少量验证集训练的情况下,能够得到更好的结果。而 DR 性能差在于本身得到的特征已经是训练好模型上的结果,最小化距离的约束可能过于强硬。

图 5 不同方法效果对比
在不同数据集上的实验结果如图 6 所示,基本的设置跟图 5 中最优设置一致。在不同数据集上均能够得到更好效果。并且为了测试训练的 Compact Network 的泛化能力,作者使用了一个大规模的通用语料库 Wikimatrix Corpus 来训练 Compact Network,然后直接在四个数据集上进行测试,可以看到在整体上得到的结果依旧是较好的。
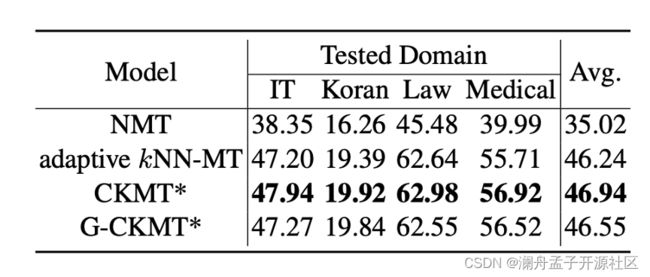
图 6 不同数据集上的结果
对于 Compact Network 降维后的特征进行可视化,结果如图 7 所示,随机选择 10 个目标词来可视化,左边是原始的特征,右边是降维以后的特征。可以看到右边不同点之间的聚类效应更加的明显,证明了对比学习在降维的时候确实起到了将不同簇分割的效果,验证了所提方法的有效性。
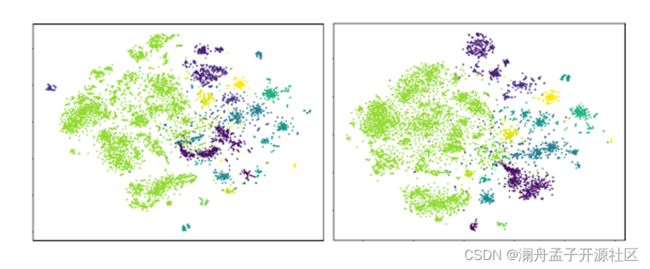
图 7 特征可视化
剪枝策略性能
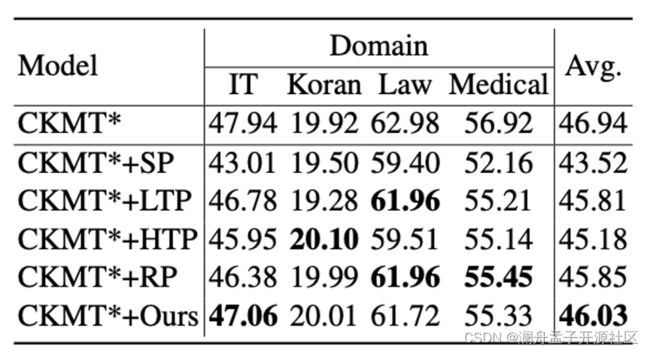
图 8 10%剪枝性能
在这个部分进行的是剪枝方法的实验,图 8 中给出了其他四种不同的简单剪枝方法和本文提出的方法在四个领域数据集上的效果。其中 SP 表示根据与聚类中心的距离来进行剪枝,LTP 和 HTP 分别代表对翻译中生成概率低和高的部分进行剪枝,RP 表示使用随机均匀采样的方法来进行剪枝。
从结果上看,本文提出的方法在总体上是优于其他方法的,但是效果的提升比较有限,反而是随机的方法依旧保持可比性。根据统计的 N-Gram 可以看到,出现这种情况的原因可能在于构成 Datastore 的数据集中的 N-Gram 的冗余度是很低的,大部分 N-Gram 都是独一无二的。
所以要体现剪枝算法的性能,需要一个更大的数据集来实验。在这里作者使用了 Subtitles 数据集来进行实验, 并且跟 RP 来进行对比,在 Subtitle 这个比较大的数据集上结果如图 9,剪枝能够起到更好的效果,并且相较于 RP 而言,本文提出的方法随着剪枝比例提高,效果更加稳定。

图 9 subtitles 上剪枝效果对比,k 表示检索数量
最后就是剪枝以后的速度和效果对比(图 10),在 Subtitles 数据集上能够进行更大比例的剪枝,并且模型性能得到了一定提升,证明了剪枝方法的有效性。从最终结果上,我们也可以看到,特征维度压缩和剪枝都能够起到提升翻译速度的作用。
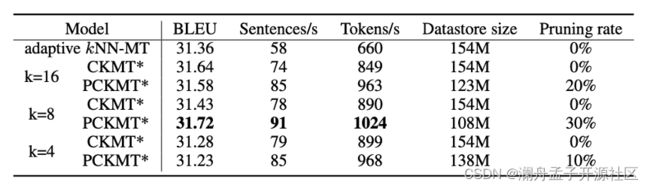
图 10 Subtitles 性能和速度对比(CKMT 表示添加了对比学习,PCKMT 表示在 CKMT 的基础上添加剪枝策略)
总结
该论文针对 KNN 无参数机器翻译中需要较大的存储空间和速度慢的两个主要问题,在创建的 Datastore 中引入语义单元的概念,并且基于不同语义单元不重合的假设,在特征维度进行压缩的时候使用对比学习来进行训练,在保证性能的前提下将特征维度从 1024 维降低到了 64 维,缓解了要求较大存储空间的问题。并且提出了基于 N-Gram 的剪枝策略,在大规模数据集上体现出来了较好的效果。两个方法都能够降低 KNN 所带来的额外时间损耗。实验表明,降维以后的特征中不同语义单元的聚集现象更加明显,并且在所有数据集上都能够取得 SOTA 的效果。
参考文献
[1]Khandelwal U, Levy O, Jurafsky D, et al. Generalization through memorization: Nearest neighbor language models[J]. arXiv preprint arXiv:1911.00172, 2019.
[2] Urvashi Khandelwal, Angela Fan, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. 2021. Nearest neighbor machine translation. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenRe- view.net.
[3] Xin Zheng, Zhirui Zhang, Junliang Guo, Shujian Huang, Boxing Chen, Weihua Luo, and Jiajun Chen. 2021a. Adaptive nearest neighbor machine translation. In Proceedings of the 59th Annual Meet- ing of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 368–374, Online. Association for Computa- tional Linguistics.
[4] Junxian He, Graham Neubig, and Taylor Berg- Kirkpatrick. 2021. Efficient nearest neighbor language models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5703–5714, Online and Punta Cana, Dominican Republic. Association for Compu- tational Linguistics.