Wizard of Wikipedia Knowledge-Powered Conversational agents
Abstract:
背景:开放域对话对话机器人应该展示开放域知识的使用,然后现在很少。目前的seq2seq模型是可以实现对输入的记忆,而不是使用背景知识作为上下文。
难点:到目前为止,知识的使用一直被证明是困难的,部分原因是缺乏一个有监督的学习基准任务(benchmark),这个benchmark应该展现出知识渊博的、有明确背景知识的的开放域对话。
因此:我们收集并发布了一个大型数据集,其对话直接基于从维基百科中检索到的知识。然后,我们设计了能够检索知识、阅读和调节知识的架构,最后生成自然相应(对话机器人的回答)。我们表现最好的对话模型能够对通过自动度量和人工评估评估的开放领域主题进行知识渊博的讨论,而我们的新基准允许衡量在这一重要研究方向上的进一步改进。
Introduction
为了对一个特定的主题进行明智的交谈,演讲者显然需要关于这个主题的知识,而我们在这里的论点是,需要使用更直接的知识记忆机制。在这项工作中,我们考虑了可以自然地测量和建立它的设置。
我们考虑开放领域对话的任务,两个发言者给出最初的起始主题进行开放式聊天,在对话过程中,主题可以扩大或关注相关主题。在这样的对话中,对话者可以从他们的谈话伙伴那里收集新的信息和个人观点,同时为自己提供类似的信息。这是一项具有挑战性的任务,因为它需要几个在许多标准模型中都没有找到的组件。我们设计一组架构专门针对这个目标,结合记忆网络架构来实现检索知识和阅读知识和以这些知识为条件,和transformer架构(提供最先进的文本表示和序列模型生成输出,我们称Transformer Memory Networks。
新数据集的所有主题都是以Wikipedia的知识为基础。其中一个人类(向导)被要求将他们使用的知识与现有文章中的句子联系起来。通过这种方式,我们既有一种自然的方式来训练一个知识渊博的对话代理,通过使用一种能够回忆和基于现有文本的记忆组件,也有一种自然的方式来评估我们所建立的模型,通过评估它们定位和使用这些知识的能力。
我们的Transformer Memory Networks,包括在retrieval and generative versions,中,都在这个设置中使用自动指标和人工评估进行了测试。
retrieval:从现有知识库中检索出最合适的回答。???
generative:使用生成模型生成回答。???
Related work
我们的论文展示了在开放域设置中进行全多回合对话的模型,据我们所知,这是以前没有显示过的。
WIZARD OF WIKIPEDIA
我们考虑以下一般的开放域对话设置:两个参与者参与闲聊,其中一个参与者选择一个开始的主题,在对话过程中允许主题自然发生改变。
然而,这两个参与者并不完全对称:一个将扮演知识渊博的专家(Wizard),而另一个将是好奇的学习者(Apprentice)。
Apprentice:在谈话的每一个阶段,学徒都会自由地与巫师交谈,扮演一个Apprentice:好奇的学习者,渴望聊天。他们的目标是深入讨论一个让自己或同伴感兴趣的话题,同时保持对话的参与和有趣。请注意,深入研究一个主题的指令使其不同于更“肤浅”的聊天任务。在这项任务中,我们更加强调了对知识的使用。
Wizard:巫师得到了如下指示:“你刚刚遇到了另一个人,他看起来很好奇,你渴望和他们讨论一个话题!”他们的目标是告诉他们的谈话伙伴一个他们之一会选择的话题。至关重要的是,向导可以访问一个信息检索系统,该系统会显示他们从维基百科中找到可能与对话相关的段落,而这些段落是学徒没有观察到的。在每次对话结束之前,向导可以阅读这些段落,然后可能根据观察到的知识进行下一个回答。注意,向导被特别指示不要简单地鹦鹉学舌这些知识,而是使用它来编写相关的回复,并在可能的情况下以有趣和引人入胜的方式呈现任何相关知识。
对话流程
- 可以选择巫师或学徒中的一个来选择主题并先发言。另一个玩家会接收到主题信息,然后对话就开始了。
- 当学徒向向导发送消息时,向导会显示相关的知识(如下所述),并选择相关的句子来构建响应,否则会选择不使用的句子选项。
- 巫师会根据他们所选择的句子来回应学徒。
- 对话重复进行,直到其中一个对话伙伴结束聊天(每次至少转4或5圈,事先随机选择)。
在收集了人类之间巫师之间的对话数据后,目标是用一个学习的代理取代人类巫师,它将与人类学徒说话。
目标是训练出一个Wizard。
主题
我们众包收集了1365个自然的、开放领域的对话主题,每个主题都链接到维基百科上的一篇文章。这些话题包括不同的话题,如通勤、豪达奶酪、音乐节、播客、保龄球和阿诺德·施瓦辛格。 (众包:企业利用互联网来将工作分配出去、发现创意或解决技术问题的方式)
Knowledge Retrieval
在对话的每一步中,向导都可以访问一组可能与给定的对话上下文相关的知识段落。虽然这是模型的一个潜在的可学习的部分,但我们需要修复这个问题,以便在收集数据集时能够将结果呈现给注释器。因此,我们使用了与Chen等人(2017)中常用的开放squad数据集完全相同的检索器。它使用了一个简单的反向索引查找,然后是术语向量模型评分。文章和查询作为TF-IDF加权词袋和n-gram向量,使用哈希技巧。我们检索了最后两次对话(通过向导和学徒)的前7篇文章(仅限第一段)和原始主题的文章(仅限前10句),并将这些文章以及它们的标题作为知识上下文呈现给向导。请注意,虽然该系统用于构建数据集,但原则上模型可以在测试时学习和使用更好的方法。
Knowledge Selection and Response Generation
在数据收集期间,向导可以单击对话UI中检索到的任何文章标题,此时他们可以单击与他们想要的响应最相关的句子(为了简单起见,可以选择一个句子)。如果他们没有看到相关的文章或句子,他们可以选择任何句子来代替。然后,巫师会向学徒输入他们的反应。
Final Dialogue Dataset
我们收集的最终对话数据集包括22,311个对话,201,999个回合,我们将其分为166,787个训练,17,715个验证,17,497个测试。测试集被分为两个子集,已看到测试和未看到测试。测试看到包含533个与训练集重叠的主题,以及关于这些主题的新对话。“看不见测试”包括58个在培训或验证中从未见过的主题。总体数据统计数据见表1,附录A.2中进一步的统计数据和收集的对话示例。我们观察巫师和学徒都问和回答问题,并在他们的一般性讨论中互相提供事实和个人感受。
模型
在这项工作中,我们考虑用学习对话模型来取代我们的学习任务中的向导,即知识渊博的说话者。
因此,对话模型可以访问一个知识来源,在这种情况下是维基百科,以作为对话的基础。因此我们开发扩展的Memory Network和 Transformer模型可以(i)从一个基于对话历史的大记忆中检索相关信息(ii)仔细阅读并参加检索到的知识集,然后(iii)生成下一个对话话语。然后在每个回合上连续使用这个模型,与用户形成一个完整的对话。
我们开发了两类能够利用知识的模型: (i)检索模型,在一组候选反应(来自训练集的话语集)之间产生输出;(ii)生成逐字生成模型(使用一束beam)。
两个模型的输入都是相同的:在模型打算做出响应的每个对话回合中,给出当前对话上下文x1,……,t对话回合的xt回合,其中x1总是最初的起始主题,其余的回合在两个说话者之间交换。每个阶段的目标是输出下一个话语x+1。
Knowledge Retrieval 我们假设有一个很大的知识库(memory)m1,……,它被分层组织成由段落和句子组成的文档。由于目前的神经注意技术在这个尺度上是不可行的,我们使用标准信息检索(IR)技术(c=IR(=,m))作为第一步返回更小的候选mc1,…,mcK进行细粒度选择。
在我们的实验中,我们使用了在数据集创建过程中提供给人类注释者的红外系统,详见第3节。检索器操作topic(x1)和最后两个回合(xt和xt−1),如果它们存在,用三个不同的查询有效地调用IR系统三次。根据经验,与合并到一个查询中相比,这提供了更好的性能,可能是因为它可以处理完全不同的主题。我们为每次查找检索前7篇文章(仅限第一段),然后将所有结果平化成单独的句子(即删除属于文章的句子的组织),但在每个句子前面都加上文章标题。这样候选mc1,…,mcK在下一阶段交给神经模型的,就可以独立处理,而不必处理层次问题。
Knowledge Attention
我们使用注意机制来执行细粒度选择,知识句子将被用来产生下一轮对话。记忆中的每个句子都是用一个Transformer encoder独立编码的,然后使用同样的encoder对对话文本x进行编码。然后,我们在memory candidates和dialogue context.之间执行标准的 dot-product attention。
Utterance Prediction考虑到上述记忆注意过程中产生的隐藏状态,最后一个阶段是预测将形成下一个对话回合的输出话语。
当考虑到我们的模型的检索和生成变量时,我们考虑了上述两个阶段的不同变量,即Knowledge Attention和Utterance Prediction。现在,我们将依次详细介绍这些内容。
4.1 RETRIEVAL TRANSFORMER MEMORY NETWORK
首先:使用transformer对知识句子和对话文本进行编码。最后的输入是上文提到的对编码后的文本之间进行点积注意力生成的representation repLHS。对候选response进行编码repRHS

该模型被训练为最小化交叉熵损失,其中每个示例的negative候选项是对batch中其他示例的响应
4.2 GENERATIVE TRANSFORMER MEMORY NETWORK
我们考虑两个版本:一个两阶段版本和一个端到端版本。这两种模型都能找到最相关的知识的最佳部分,然后通过将其与对话上下文连接起来来执行编码步骤,允许解码器在制定其响应时同时参与知识和对话。我们使用5的beam搜索来选择我们的最佳响应。所有生成模型都采用BPE编码,我们发现它可以有效地使生成器从维基百科的句子中复制罕见的单词。
在End-to-end版本中,使用一个共享的transformer编码器来编码所有候选的mci和对话历史。使用Cer等人(2018)的归一化(计算句子长度的平方根,以平衡短句子和长句子),将编码的候选词压缩为向量,以产生对记忆的注意力预测。单个最高选择的知识最佳的全序列编码与对话的编码连接,并传递到transformer解码器。图1显示了我们的端到端模型的说明。我们训练这个模型来最小化反应话语的负对数似然性。我们可以通过强迫知识选择正确选择与训练集中相同的知识候选人来添加额外的监督,通过增加知识注意力的额外交叉熵损失,由权重λ调节:
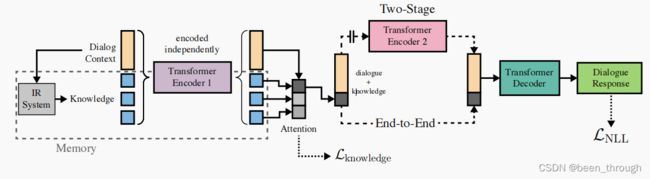
在两阶段的版本中,我们对这两个任务分别使用了两个单独训练的模型,即知识选择和话语预测。考虑到知识选择部分选择的结果会对生成器产生很大影响,我们发现最大化这个组件(知识选择)的性能是至关重要的。