【图神经网络综述】A Comprehensive Survey on Graph Neural Networks(V4)

Paper: A Comprehensive Survey on Graph Neural Networks
Published in: IEEE Transactions on Neural Networks and Learning Systems ( Volume: 32, Issue: 1, Jan. 2021)
摘要:近年来,深度学习彻底改变了许多机器学习任务,从图像分类和视频处理到语音识别和自然语言理解。这些任务中的数据通常用欧氏空间表示。然而,在越来越多的应用中,数据是由非欧式域中生成的,并将其表示为具有复杂关系和对象之间相互依赖关系的图。图数据的复杂性对现有的机器学习算法提出了重大挑战。近年来,出现了许多有关扩展图数据深度学习方法的研究。本文综述了图神经网络(GNNs)在数据挖掘和机器学习领域中的应用。我们提出了一种新的分类法,将最新的图神经网络分为四类,即递归图神经网络,卷积图神经网络,图自动编码器和时空图神经网络。我们进一步讨论了图神经网络在各个领域中的应用,并总结了开源代码,基准数据集和图神经网络的模型评估。最后,我们提出了在这个快速发展的领域中潜在的研究方向。
关键词:深度学习,图神经网络,图卷积网络,图表示学习,图自动编码,网络嵌入
1 介绍
最近神经网络的成功促进了模式识别和数据挖掘的研究。许多机器学习任务,如目标检测、机器翻译和语音识别,曾经严重依赖手工制作的特征工程来提取信息特征集,最近已经被各种端到端的深度学习方式彻底改变,如卷积神经网络(CNNs),循环神经网络(RNNs)和自动编码器。深度学习在许多领域的成功部分归因于有效开发计算资源(例如GPU),大量训练数据的可用性以及深度学习从欧几里得数据(例如图像,文本和视频)中提取潜在表示的有效性。以图像数据为例,我们可以将图像表示为欧几里得空间中的规则网格。卷积神经网络(CNN)能够利用图像数据的平移不变性,局部连通性和组合性。因此CNN能够为各种图像分析任务提取整个数据集共享的局部特征。
虽然深度学习在欧式数据上取得了巨大的成功,但是,越来越多的应用需要对非欧式数据进行分析。例如,在电子商务中,基于图的学习系统可以利用用户和产品之间的交互来做出高度准确的推荐。在化学中,分子被建模为图,并且需要确定其生物活性才能用于药物发现。在引文网络中,论文通过引文相互链接,因此需要将它们分类为不同的组。图数据的复杂性对现有的机器学习算法提出了重大挑战。由于图数据不规则的,具有可变大小的无序节点,并且节点具有不同数量的邻居,从而导致一些重要的操作(例如卷积)容易在图像数据上计算,但难以适用于图数据。此外,现有机器学习算法的核心假设是实例彼此独立。 该假设不再适用于图数据,因为每个实例(节点)通过引用,关系和交互等各种类型的链接与其他实例关联。
最近,人们越来越关注扩展图数据的深度学习方法。在CNN、RNN和来自深度学习的自动编码器的推动下,在过去的几年中,重要的操作有了新的概括和定义,以处理图形数据的复杂性。例如,图卷积可以从2D卷积中概括出来。如图1所示,图像可被视为图的特殊情况,其中像素由相邻像素连接。与2D卷积类似,可以通过获取节点邻域信息的加权平均值来执行图卷积。
关于图神经网络(GNNs)的研究,现有的文献数量有限。Bronstein等人使用术语Geometric Deep learning 概述了非欧几里德域中的深度学习方法,包括图和流形。虽然这是第一次对GNNs的综述,但本综述主要对卷积GNNs进行综述。Hamilton等人涵盖了有限数量的GNN,重点是解决网络嵌入问题。Battaglia等人将位置graph networks 作为构建块学习关系数据,使用统一的框架对部分神经网络做了回顾。Lee等人对应用不同注意机制的GNN进行了部分调查。总而言之,现有的调查仅包括一些GNN,并检查了有限数量的工作,从而缺少了GNN的最新发展。我们的调查为想要进入这个快速发展领域的感兴趣的研究者和想要比较GNN模型的专家提供了GNN的全面概述。为了涵盖更广泛的方法,本调查认为GNNs是所有图数据的深度学习方法。
我们的贡献 我们的论文做出了重要贡献,总结如下:
- 新分类法 我们提出了一种新的图神经网络分类法。图神经网络分为四类:循环图神经网络,卷积图神经网络,图自动编码器和时空图神经网络。
- 综合审查 我们对图数据的现代深度学习技术提供了最全面的概述。对于每种类型的图神经网络,我们都对代表性模型进行详细说明,进行必要的比较,并总结相应的算法。
- 资源丰富 我们收集了丰富的图神经网络资源,包括最新模型,基准数据集,开源代码和实际应用。该调查可用作理解,使用和开发适用于各种现实应用的不同深度学习方法的操作指南。
- 未来方向 我们讨论了图神经网络的理论方面,分析了现有方法的局限性,并就模型深度,可伸缩性,异质性和动态性提出了四个可能的未来研究方向。
文章结构 该调查的其余部分的结构组织如下。第二节概述了图神经网络的背景,列出了常用的符号,并定义了与图相关的概念。第三节阐明了图神经网络的分类。第四至第七节概述了图神经网络模型。第八节介绍了各个领域的应用。第九节讨论了当前的挑战并提出了未来的方向。第十节总结全文。
2 背景与定义
在本节中,我们概述了图神经网络的背景,列出了常用的符号,并定义了与图相关的概念。
A 背景
图神经网络(GNNs)简史 Sperduti等人 (1997)首先将神经网络应用于有向无环图,这激发了对GNN的早期研究。图神经网络的概念最初是在Goriet等人(2005)中概述的,并进一步在Scarselli等人(2009)和Gallicchio等人(2010)中进行了阐述 。这些早期研究属于递归图神经网络(RecGNNs)类别。通过迭代传播邻居信息,学习目标节点的表示,直到达到稳定的不动点。 这一过程的计算量非常大,最近为克服这些挑战已经付出了越来越多的努力。
受到CNN在计算机视觉领域的成功的启发,并行开发了许多重新定义图 convolution 概念的方法。这些方法属于卷积图神经网络(ConvGNNs)的范畴。ConvGNNs分为两大主流:基于频谱(spectral-based)的方法和基于空间(spatial-based)的方法。Bruna等人(2013)提出了基于谱的卷积神经网络的第一个重要研究,它基于谱图理论发展了图卷积。从那时起,基于谱的ConvGNN的改进、扩展和逼近越来越多。基于空间的ConvGNN的研究比基于频谱的ConvGNN的研究要早得多。 2009年,Micheli等人首先通过在结构上组合非递归层,同时继承从RecGNNs传递消息的思想来解决图形相互依赖问题。但是,这项工作的重要性被忽略了。直到最近,出现了许多基于空间的ConvGNN。Table II的第一栏中显示了代表RecGNN和ConvGNN的时间线。除了RecGNN和ConvGNN,在过去几年中还开发了许多新的GNN,包括图自动编码器(GAE)和时空图神经网络(STGNN)。这些学习框架可以建立在RecGNN,ConvGNN或其他用于图建模的神经体系结构上。这些方法的分类细节在第三节中给出。
图神经网络与网络嵌入 GNN的研究与图嵌入或网络嵌入密切相关,是数据挖掘和机器学习日益关注的另一个课题。网络嵌入将网络节点表示为低维向量表示,同时保留了网络拓扑结构和节点内容信息,便于后续的图形分析任务,例如分类,聚类和推荐等,能够使用简单的现成机器学习算法(例如,用于分类的支持向量机)。同时,GNN是深度学习模型,旨在以端到端的方式解决与图相关的任务。许多GNN明确地提取高级表示形式。GNN与网络嵌入之间的主要区别在于,GNN是一组为各种任务而设计的神经网络模型,而网络嵌入则涵盖了针对同一任务的多种方法。 因此,GNN可以通过图自动编码器框架解决网络嵌入问题。另一方面,网络嵌入包含其他非深度学习方法,例如矩阵分解和随机游走。
图神经网络与图内核方法 图内核是解决图分类问题的主流技术。这些方法利用核函数来度量图的两部分之间的相似性,以便基于内核的算法(如支持向量机)可用于图上的监督学习。与GNN相似,图内核可以通过映射功能将图或节点嵌入向量空间。不同之处在于此映射函数是确定性的,而不是可学习的。由于采用了成对的( pair-wise)相似度计算,图内核方法受到了计算瓶颈的严重影响。GNN基于提取的图形示直接执行图分类,因此比图内核方法更有效。
B 定义
在整个本文中,我们使用粗体大写字母表示矩阵,并使用粗体小写字母表示矢量。除非特别说明,否则本文中使用的符号在表I中进行了说明。现在我们定义一下理解本文所需的最低限度的一组定义。
表I 常用符号
| 符号 | 含义 | 符号 | 含义 |
|---|---|---|---|
| ∣ ⋅ ∣ \vert \cdot \vert ∣⋅∣ | 集合大小 | d d d | 节点特征向量的维数 |
| ⊙ \odot ⊙ | 逐元素相乘 | b b b | 隐藏节点特征向量的维数 |
| G G G | 图 | c c c | 边特征向量的维数 |
| V V V | 图中节点的集合 | X ∈ R n × d X \in R^{n \times d} X∈Rn×d | 图的特征矩阵 |
| v v v | 节点 | X ∈ R n X \in R^n X∈Rn | 图的特征向量 d = 1 d=1 d=1 |
| E E E | 图中边的集合 | x v ∈ R d x_v \in R^d xv∈Rd | 节点 v v v的特征向量 |
| e i j e_{ij} eij | 边 | X e ∈ R m × c X^{e} \in R^{m \times c} Xe∈Rm×c | 图的边特征矩阵 |
| N ( v ) N(v) N(v) | 节点 v v v的邻居 | X ( v , u ) e ∈ R c X^{e}_{(v,u)} \in R^{c} X(v,u)e∈Rc | 边 ( v , u ) (v,u) (v,u)的边特征向量 |
| A A A | 图邻接矩阵 | X ( t ) ∈ R n × d X^{(t)} \in R^{n \times d} X(t)∈Rn×d | 图在时间步 t t t的节点特征矩阵 |
| A ⊤ A^{\top} A⊤ | 矩阵的转置 | H ∈ R n × b H \in R^{n \times b} H∈Rn×b | 节点隐藏特征矩阵 |
| A n , n ∈ Z A^n, n\in Z An,n∈Z | A A A的 n n n阶幂 | h v ∈ R b h_v \in R^b hv∈Rb | 节点 v v v的隐藏特征向量 |
| [ A , B ] [A, B] [A,B] | 矩阵连接 | k k k | 层数 |
| D D D | A A A的度矩阵, D i i = ∑ j = 1 n A i j D_{ii} = \sum_{j=1}^{n}A_{ij} Dii=∑j=1nAij | σ \sigma σ | σ \sigma σ激活函数 |
| n n n | 节点数, n = ∣ V ∣ n = \vert V \vert n=∣V∣ | σ h ( ⋅ ) \sigma_{h}(\cdot) σh(⋅) | 正切双曲激活函数 |
| m m m | 边数, m = ∣ E ∣ m = \vert E \vert m=∣E∣ | W , Θ , w , θ W,\Theta,w,\theta W,Θ,w,θ | 可学习的模型参数 |
图: 图 G = ( V , E ) G=(V, E) G=(V,E),其中 V V V 节点集合, E E E 边集合 。 v i ∈ V v_{i} \in V vi∈V 描述一个点, e i j = e_{i j}= eij= ( v i , v j ) ∈ E \left(v_{i}, v_{j}\right) \in E (vi,vj)∈E 表示节点 v j v_j vj到 v i v_i vi之间的边。节点 v v v的邻居表示为 N ( v ) = { u ∈ V ∣ ( v , u ) ∈ E } N(v) = \{ u\in V|(v,u)\in E \} N(v)={u∈V∣(v,u)∈E}。邻接矩阵 A A A 是一个 n × n n \times n n×n 的矩阵,其中
A i j = { 1 if e i j ∈ E 0 if e i j ∉ E A_{i j}=\left\{\begin{array}{lll} 1 & \text { if } & e_{i j} \in E \\ 0 & \text { if } & e_{i j} \notin E \end{array}\right. Aij={10 if if eij∈Eeij∈/E
图与节点属性 X X X 关联, X ∈ R n × d X \in R^{n \times d} X∈Rn×d 是一个特征矩阵,其中 X v ∈ R d X_{v} \in R^{d} Xv∈Rd 表示节点 v v v 的特征向量。 同时,图可能具有边属性 X e X^{e} Xe, X e ∈ X m × c X^{e} \in X^{m \times c} Xe∈Xm×c是边特征矩阵,其中 x v , u e ∈ R c x^{e}_{v,u} \in R^c xv,ue∈Rc 表示边 ( v , u ) (v,u) (v,u) 的特征向量。
有向图: 有向图是一个所有边都从一个节点指向另一个节点的图。无向图被认为是有向图的一个特例,如果两个节点相连,就会有一对方向相反的边。当且仅当邻接矩阵是对称的时,图才是无向的。
时空图:时空图是一个属性图,其中节点属性随时间动态变化。 时空图定义为 G ( t ) = ( V , E , X ( t ) ) G^{(t)}=(V, E, X^{(t)}) G(t)=(V,E,X(t)),其中 X ( t ) ∈ R n × d X^{(t)} \in R^{n \times d} X(t)∈Rn×d。
3 分类与框架
在本节中,我们介绍了图神经网络(GNNs)的分类法,如表II所示。我们将神经网络(GNNs)分为循环图神经网络(RecGNNs),卷积图神经网络(ConvGNNs),图自动编码器(GAE)和时空图神经网络(STGNNs)。图2给出了各种模型架构的示例。下面我们简要介绍每个类别。
表II:图神经网络(GNNs)的分类法和代表性方法
| 分类 | 文献 | |
|---|---|---|
| 递归图神经网络(RecGNN) | [15], [16], [17], [18] | |
| 卷积图神经网络(ConvGNN) | 频谱方法 | [19], [20], [21], [22], [23], [40], [41] |
| 空间方法 | [24], [25], [26], [27], [42], [43], [44], [45], [46], [47], [48], [49], [50], [51],[52], [53], [54], [55], [56], [57], [58] | |
| 图形自动编码器(GAE) | 网络嵌入 | [59], [60], [61], [62], [63], [64] |
| 图生成 | [65], [66], [67], [68], [69], [70] | |
| 时空图神经网络(STGNN) | [71], [72], [73], [74], [75], [76], [77] | |
A 图神经网络(GNN)的分类法
递归图神经网络(RecGNNs) 大部分是图神经网络的先驱著作。RecGNNs旨在通过递归神经体系结构学习节点表示。他们假设图中的一个节点不断与其邻居交换信息/消息,直到达到稳定的平衡。RecGNNs 的研究对卷积图神经网络具有重要的理论意义和启发意义。特别地,基于空间的卷积图神经网络继承了消息传递的思想。
卷积图神经网络(ConvGNNs) 一般化从网格数据到图数据的卷积运算。其主要思想是通过聚集节点自身的特征 x v x_v xv 和邻居的特征 x u x_u xu 来生成节点 v v v 的表示,其中 u ∈ N ( v ) u \in N(v) u∈N(v) 。与RecGNNs不同,ConvGNNs堆叠多个图卷积层以提取高级节点表示形式。ConvGNNs在建立许多其他复杂的GNN模型中起着核心作用。图2a显示了用于节点分类的ConvGNNs。图2b演示了用于图分类的ConvGNNs。
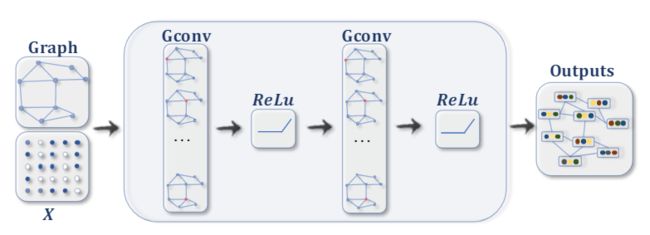
(2a) 具有多个图卷积层的ConvGNNs。图卷积层通过聚集来自其邻居的特征信息来封装每个节点的隐藏表示。特征聚合后,将非线性变换应用于结果输出。通过堆叠多层,每个节点的最终隐藏表示形式从邻居接收消息。
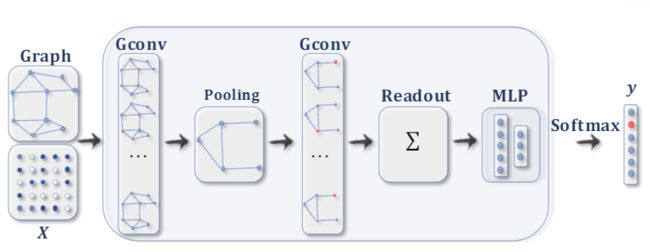
(2b) 带有池和读出层的ConvGNN用于图分类。图卷积层之后是池化层,以将图粗化为子图,从而使粗化图上的节点表示表示更高的图级表示。读出层通过获取子图的隐藏表示的总和/平均值来汇总最终图的表示。
图形自动编码器(GAEs) 是一种无监督学习框架,它将节点/图编码到一个潜在的向量空间中,并从编码的信息中重建图数据。GAE用于学习网络嵌入和图生成分布。对于网络嵌入,GAE通过重建图结构信息(例如图邻接矩阵)来学习潜在节点表示。对于图生成,某些方法逐步生成图的节点和边,而其他方法则一次输出图。图2c展示了一个用于网络嵌入的GAE。
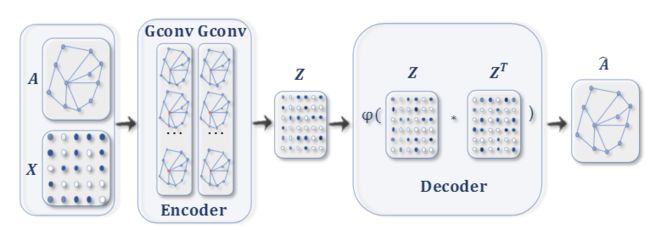
(2c) 用于网络嵌入的GAE [61]。编码器使用图卷积层获得每个节点的网络嵌入。解码器在给定网络嵌入的情况下计算成对(pair-wise)距离。在应用非线性激活函数之后,解码器重建图邻接矩阵。通过最小化实际邻接矩阵和重构的邻接矩阵之间的差异来训练网络。
时空图神经网络(STGNNs) 目的从时空图中学习隐藏模式,这在交通速度预测、驾驶员操纵预测和人类行为识别等各种应用中变得越来越重要。STGNN的关键思想是同时考虑空间依赖性和时间依赖性。许多当前的方法将图卷积集成在一起,以捕获具有RNN或CNN的空间相关性,以对时间相关性进行建模。图2d说明了用于时空图预测的STGNN。
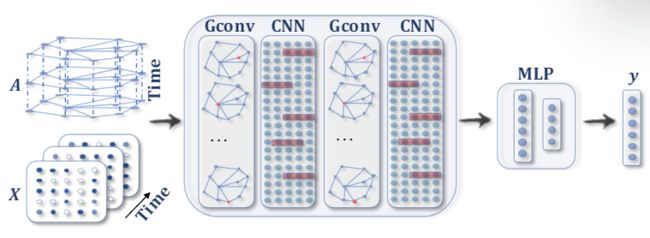
(2d) STGNN用于时空图预测。图卷积层之后是1D-CNN层。图卷积层在 A A A 和 X ( t ) X^{(t)} X(t)上运行以捕获空间相关性,而1D-CNN层在 X X X轴上沿时间轴滑动以捕获时间相关性。输出层是线性变换,为每个节点生成一个预测,比如下一个时间步的未来值。
B 框架
使用图结构和节点内容信息作为输入,GNN的输出可以通过以下机制之一专注于不同的图分析任务:
- Node-level 输出用于节点回归和分类任务。RecGNN和ConvGNN可以通过信息传播/图卷积来提取高级节点表示。通过使用多感知机或softmax层作为输出层,GNNs能够以端到端的方式执行节点级任务。
- Edge-level 输出与边分类和链路预测任务相关。为了预测一条边的标签/连接强度,可以利用相似度函数或神经网络从图卷积模型中提取两个节点的潜在表示作为输入。
- Graph-level 输出与图分类任务有关。为了在图级别上获得紧凑的表示,GNNs通常与池化和读出操作相结合。
训练框架 :许多GNNs(例如convGNNs)可以在端到端学习框架内以(半)监督或纯无监督的方式进行训练,具体取决于手头的学习任务和标签信息。
-
node-level 半监督分类 给定一个部分节点被标记而其他节点未标记的网络,GCN可以学习一个鲁棒的模型,有效地识别未标记节点的类标签。为此,可以构建一个端到端的多分类框架,通过叠加几个图卷积层,紧跟着一个softmax层。
-
graph-level 监督分类。图分类旨在预测整个图的类标签。可以通过图卷积层,图池化层和/或读出层的组合来实现此任务的端到端学习。图卷积层负责提取高级节点表示,而图池层则起到下采样的作用,每次都将每个图粗化为一个子结构。读出层将每个图的节点表示变为图表示。通过将多层感知器和softmax层应用于图表示,我们可以构建图分类的端到端框架。图2b给出了一个示例。
-
graph embedding 无监督学习 当图中没有类标签时,我们可以在端到端框架中以纯无监督的方式学习图的嵌入。这些算法通过两种方式利用 edge-level 信息。一种简单的方法是采用自动编码器框架,其编码器使用图卷积层将图嵌入到隐藏表示中,在该隐藏表示中使用解码器来重构图结构。另一种方法是利用负采样方法,该方法将一部分节点对采样为负对,而图中具有链接的现有节点对为正对。然后应用逻辑回归层来区分正对和负对。
在表III中,我们总结了代表性RecGNN和ConvGNN的主要特征。比较了不同模型的输入源、输出层、读出层和时间复杂度。更详细地说,我们仅比较每种模型中消息传递/图形卷积运算的时间复杂度。Spectral networksand locally connected networks on graphs和Convolutional neural networks on graphs with fast localized spectral filtering 需要特征值分解,时间复杂度为 O ( n 3 ) O(n^3) O(n3)。On filter size in graph convolutional networks的时间复杂度也是 O ( n 3 ) O(n^3) O(n3),这是因为节点对(pair-wise)的最短路径计算。其他方法会产生等价的时间复杂度,如果图邻接矩阵稀疏,则为 O ( m ) O(m) O(m),否则为 O ( n 2 ) O(n^2) O(n2)。这是因为在这些方法中,每个节点 v i v_i vi的表示的计算都涉及邻居 d i d_i di,并且所有邻居节点 d i d_i di的总和等于边数。
表III:RecGNN和ConvGNN的总结。池化和读出层中缺少值(“-”)表示该方法仅在node-level/edge-level上进行实验。
| 方法 | 分类 | 输入 | 池化 | 读出 | 时间复杂度 |
|---|---|---|---|---|---|
| GNN* (2009) [15] | RecGNN | A , X , X e A,X,X^e A,X,Xe | - | a dummy super node | O ( m ) O(m) O(m) |
| GraphESN (2010) [16] | RecGNN | A , X A,X A,X | - | mean | O ( m ) O(m) O(m) |
| GGNN (2015) [17] | RecGNN | A , X A,X A,X | - | attention sum | O ( m ) O(m) O(m) |
| SSE (2018) [18] | RecGNN | A , X A,X A,X | - | - | - |
| Spectral CNN (2014) [19] | Spectral-based ConvGNN | A , X A,X A,X | spectral clustering+max pooling | max | O ( n 3 ) O(n^3) O(n3) |
| Henaff et al. (2015) [20] | Spectral-based ConvGNN | A , X A,X A,X | spectral clustering+max pooling | - | O ( n 3 ) O(n^3) O(n3) |
| ChebNet (2016) [21] | Spectral-based ConvGNN | A , X A,X A,X | efficient pooling | sum | O ( m ) O(m) O(m) |
| GCN (2017) [22] | Spectral-based ConvGNN | A , X A,X A,X | - | - | O ( m ) O(m) O(m) |
| CayleyNet (2017) [23] | Spectral-based ConvGNN | A , X A,X A,X | mean/graclus pooling | - | O ( m ) O(m) O(m) |
| AGCN (2018) [40] | Spectral-based ConvGNN | A , X A,X A,X | max pooling | sum | O ( n 2 ) O(n^2) O(n2) |
| DualGCN (2018) [41] | Spectral-based ConvGNN | A , X A,X A,X | - | - | O ( m ) O(m) O(m) |
| NN4G (2009) [24] | Spatial-based ConvGNN | A , X A,X A,X | - | sum/mean | O ( m ) O(m) O(m) |
| DCNN (2016) [25] | Spatial-based ConvGNN | A , X A,X A,X | - | mean | O ( n 2 ) O(n^2) O(n2) |
| PATCHY-SAN (2016) [26] | Spatial-based ConvGNN | A , X , X e A,X,X^e A,X,Xe | - | sum | - |
| MPNN (2017) [27] | Spatial-based ConvGNN | A , X , X e A,X,X^e A,X,Xe | - | attention sum/set2set | O ( m ) O(m) O(m) |
| GraphSage (2017) [42] | Spatial-based ConvGNN | A , X A,X A,X | - | - | - |
| GAT (2017) [43] | Spatial-based ConvGNN | A , X A,X A,X | - | - | O ( m ) O(m) O(m) |
| MoNet (2017) [44] | Spatial-based ConvGNN | A , X A,X A,X | - | - | O ( m ) O(m) O(m) |
| LGCN (2018) [45] | Spatial-based ConvGNN | A , X A,X A,X | - | - | - |
| PGC-DGCNN (2018) [46] | Spatial-based ConvGNN | A , X A,X A,X | sort pooling | attention sum | O ( n 3 ) O(n^3) O(n3) |
| CGMM (2018) [47] | Spatial-based ConvGNN | A , X , X e A,X,X^e A,X,Xe | - | sum | - |
| GAAN (2018) [48] | Spatial-based ConvGNN | A , X A,X A,X | - | - | O ( m ) O(m) O(m) |
| FastGCN (2018) [49] | Spatial-based ConvGNN | A , X A,X A,X | - | - | - |
| StoGCN (2018) [50] | Spatial-based ConvGNN | A , X A,X A,X | - | - | - |
| Huang et al. (2018) [51] | Spatial-based ConvGNN | A , X A,X A,X | - | - | - |
| DGCNN (2018) [52] | Spatial-based ConvGNN | A , X A,X A,X | sort pooling | - | O ( m ) O(m) O(m) |
| DiffPool (2018) [54] | Spatial-based ConvGNN | A , X A,X A,X | differential pooling | mean | O ( n 2 ) O(n^2) O(n2) |
| GeniePath (2019) [55] | Spatial-based ConvGNN | A , X A,X A,X | - | - | O ( m ) O(m) O(m) |
| DGI (2019) [56] | Spatial-based ConvGNN | A , X A,X A,X | - | - | O ( m ) O(m) O(m) |
| GIN (2019) [57] | Spatial-based ConvGNN | A , X A,X A,X | - | sum | O ( m ) O(m) O(m) |
| ClusterGCN (2019) [58] | Spatial-based ConvGNN | A , X A,X A,X | - | - | - |
4 递归图神经网络
递归图神经网络(RecGNNs)是图神经网络的重要组成部分。它们在图中的节点上应用相同的参数集来提取高级节点表示。受计算能力的限制,较早的研究主要集中在有向无环图上。
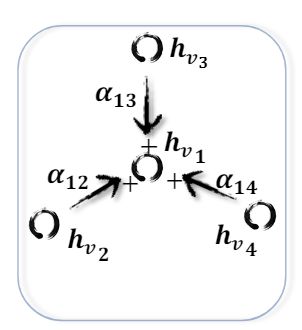
Scarselli等人提出的图神经网络(GNN*)扩展了先前的递归模型来处理一般类型的图,例如非循环图,循环图,有向图和无向图。基于信息扩散机制,GNN*通过不断地交换邻域信息来更新节点的状态,直到达到一个稳定的平衡点。节点的隐藏状态为
h v ( t ) = ∑ u ∈ N ( v ) f ( x v , x ( v , u ) e , x u , h u ( t − 1 ) ) , (1) h^{(t)}_v = \sum_{u \in N(v)} f(x_v, x^{e}_{(v,u)},x_u,h^{(t-1)}_u), \tag{1} hv(t)=u∈N(v)∑f(xv,x(v,u)e,xu,hu(t−1)),(1)
其中 f ( ⋅ ) f(\cdot) f(⋅)是参数函数, h v ( 0 ) h^{(0)}_v hv(0)随机初始化。求和运算使 GNN* 可以适用于所有节点,即使邻居的数量不同并且已知非邻居排序也是如此。为了确保收敛,当前函数 f ( ⋅ ) f(\cdot) f(⋅)必须是压缩映射,将其投影到潜在空间后缩小两点之间的距离。如果是神经网络,则必须对参数的雅可比矩阵施加惩罚项。当满足收敛标准时,将最后一步节点的隐藏状态转发到读取层。GNN* 交替了节点状态传播的阶段和参数梯度计算的阶段,以最小化训练目标。这种策略使GNN* 可以处理循环图。在后续工作中,图回波状态网络(GraphESN,IEEE2010)扩展回波状态网络以改善GNN*的训练效率。GraphESN由一个编码器和一个输出层组成。编码器是随机初始化的,不需要训练。它实现了收缩状态转换功能,以循环更新节点状态,直到全局图状态达到收敛为止。之后,通过将固定节点状态作为输入来训练输出层。
门控图神经网络(GGNN, ICLR2015)使用门控递归单元(GRU)作为递归函数,将该循环减少到一个固定的步数。优点是它不再需要约束参数以确保收敛。节点隐藏状态由其先前的隐藏状态及其相邻的隐藏状态更新,定义为
h v ( t ) = G R U ( h v ( t − 1 ) , ∑ u ∈ N ( v ) W h u ( t − 1 ) ) , (2) h^{(t)}_v = GRU(h^{(t-1)}_v, \sum_{u \in N(v)} Wh^{(t-1)}_u), \tag{2} hv(t)=GRU(hv(t−1),u∈N(v)∑Whu(t−1)),(2)
其中 h v ( 0 ) = x v h^{(0)}_v = x_v hv(0)=xv。与GNN*和GraphESN不同,GGNN使用反向传播时间(BPTT)算法来学习模型参数。对于大型图来说,这可能是个问题,因为GGNN需要在所有节点上多次运行递归函数,需要将所有节点的中间状态存储在内存中。
随机稳态嵌入(SSE, ICML2018)提出了一种学习算法,该算法对大型图更具可扩展性。SSE以随机和异步的方式循环更新节点隐藏状态。它交替采样一批节点进行状态更新和一批节点进行梯度计算。为了保持稳定性,将SSE的递归函数定义为历史状态和新状态的加权平均值,其形式为
h v ( t ) = ( 1 − α ) h v ( t − 1 ) + α W 1 σ ( W 2 [ x v , ∑ u ∈ N ( v ) [ h u ( t − 1 ) , x u ] ] ) , (3) h^{(t)}_v = (1-\alpha)h^{(t-1)}_v + \alpha W_1 \sigma(W_2 [x_v, \sum_{u \in N(v)}[h^{(t-1)}_u, x_u]]), \tag{3} hv(t)=(1−α)hv(t−1)+αW1σ(W2[xv,u∈N(v)∑[hu(t−1),xu]]),(3)
其中 α \alpha α是一个超参数, h v ( 0 ) h^{(0)}_v hv(0)随机初始化。虽然在概念上很重要,但SSE在理论上并不能证明通过反复应用公式3,节点状态会逐渐收敛到固定点。
5 卷积图神经网络
卷积图神经网络(ConvGNN)与递归图神经网络密切相关。ConvGNN不是使用收缩性约束来迭代节点状态,而是使用固定数量的每层中具有不同权重的层在体系结构上解决循环的相互依存关系。图3说明了这种关键区别。随着图卷积与其他神经网络进行组合的更有效、方便,近年来,ConvGNNs的普及迅速增长。ConvGNNs分为两类,基于频谱的和基于空间。基于频谱的方法通过从图信号处理的角度引入滤波器来定义图卷积,其中图卷积运算被解释为消除图信号中的噪声。基于空间的方法继承了RecGNN的思想以通过信息传播定义图卷积。自从GCN 填补了基于频谱的方法与基于空间的方法之间的差距以来,基于空间的方法由于其引人注目的效率,灵活性和通用性而迅速发展。
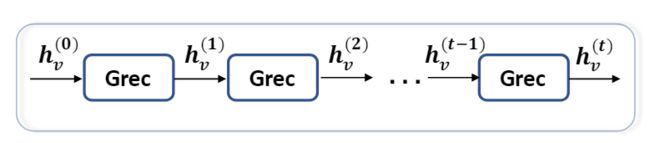
(3a) 递归图神经网络(RecGNNs)。 RecGNNs在更新节点表示时使用同一图循环层(Grec)
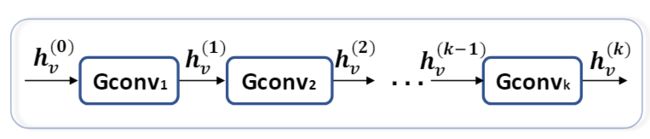
(3b) 卷积图神经网络(ConvGNNs)。 ConvGNNs在更新节点表示时使用不同的图卷积层(Gconv)。
图3:递归图神经网络与卷积图神经网络
A 基于频谱的卷积神经网络
Background 基于频谱的方法在图形信号处理中具有扎实的数学基础。他们认为图是无向的。归一化图拉普拉斯矩阵是无向图的数学表示,定义为 L = I n − D − 1 2 A D − 1 2 L=I_{n}-D^{-\frac{1}{2}} A D^{-\frac{1}{2}} L=In−D−21AD−21, D D D 是一个节点的度矩阵, D i i = ∑ j ( A i , j ) D_{i i}=\sum_{j}\left(A_{i, j}\right) Dii=∑j(Ai,j)。归一化图拉普拉斯矩阵具有实对称半正定的性质。利用这个性质,归一化拉普拉斯矩阵可以分解为 L = U Λ U T L=U \Lambda U^{T} L=UΛUT,其中 U = [ u 0 , u 1 , ⋯ , u n − 1 ] ∈ R n × n U=\left[u_{0}, u_{1}, \cdots, u_{n-1}\right] \in R^{n \times n} U=[u0,u1,⋯,un−1]∈Rn×n 是根据特征值排序的特征向量组成的矩阵, Λ \Lambda Λ 是特征值(谱域)的对角矩阵, Λ i i = λ i \Lambda_{i i}=\lambda_{i} Λii=λi 。图拉普拉斯矩阵的特征向量构成一个正交的空间, 即 U T U = I U^{T} U=I UTU=I。在图信号处理中,图信号 x ∈ R n x \in R^{n} x∈Rn 是图中第 i i i 个节点 x i x_{i} xi 的特征向量。信号 x x x 的图傅里叶变换定义为 F ( x ) = U T x F(x)=U^{T} x F(x)=UTx,逆傅里叶变换为 F − 1 ( x ^ ) = U x ^ F^{-1}(\widehat{x})=U \widehat{x} F−1(x )=Ux , x ^ \widehat{x} x 表示图傅里叶变换对信号 x x x 的输出。图傅里叶变换将输入图信号投影到正交空间中,该正交空间的基根据 L L L 的特征向量构成。变换后的信号 x ^ \widehat{x} x 的元素表示新空间中图的坐标,因此,输入信号能够被表示为 x = ∑ i x ^ i u i x=\sum_{i} \widehat{x}_{i} u_{i} x=∑ix iui,实际上是图信号的逆傅里叶变换。因此, 输入信号 x x x 用 g ∈ R N g \in R^{N} g∈RN 滤波的图卷积为:
x ∗ G g = F − 1 ( F ( x ) ⊙ F ( g ) ) = U ( U T x ⊙ U T g ) , (4) \begin{array}{c} x *_G g=F^{-1}(F(x) \odot F(g)) \\ \quad=U\left(U^{T} x \odot U^{T} g\right), \tag{4} \end{array} x∗Gg=F−1(F(x)⊙F(g))=U(UTx⊙UTg),(4)
其中 ⊙ \odot ⊙表示逐元素相乘(Hadamard乘积)。如果定义一个滤波器 g θ = g_{\theta}= gθ= diag ( U T g ) , \operatorname{diag}\left(U^{T} g\right), diag(UTg), 图卷积就简化为
x ∗ G g θ = U g θ U T x x *_G g_{\theta}=U g_{\theta} U^{T} x x∗Ggθ=UgθUTx
基于谱的GCN都遵循这个定义, 不同的是滤波器 g θ g_{\theta} gθ 的选择不同。
谱CNN 假设滤波器 g θ = Θ i , j k g_{\theta}=\Theta_{i, j}^{k} gθ=Θi,jk 是一个可学习参数的集合,并且假设图信号是多维的。频谱CNN的图卷积层定义为
H : , j k = σ ( ∑ i = 1 f k − 1 U Θ i , j k U T X : , i ( k − 1 ) ) ( j = 1 , 2 , ⋯ , f k ) H_{:, j}^{k}=\sigma\left(\sum_{i=1}^{f_{k-1}} U \Theta_{i, j}^{k} U^{T} X_{:, i}^{(k-1)}\right) \quad\left(j=1,2, \cdots, f_{k}\right) H:,jk=σ(i=1∑fk−1UΘi,jkUTX:,i(k−1))(j=1,2,⋯,fk)
其中 k k k 为层数, H ( k − 1 ) ∈ R n × f k − 1 H^{(k-1)} \in R^{n \times f_{k-1}} H(k−1)∈Rn×fk−1 是输入图信号, H ( 0 ) = X H^{(0)} =X H(0)=X, f k − 1 f_{k-1} fk−1 是输入通道的数量, f k f_{k} fk 是输出通道的数量, Θ i , j ( k ) \Theta_{i, j}^{(k)} Θi,j(k) 是一个可学习参数的对角矩阵。由于拉普拉斯矩阵的特征分解,谱CNN面临三个限制。首先,对图的任何扰动都会导致特征基的变化。第二,学习的滤波器是依赖于域的,这意味着它们不能应用于具有不同结构的图。第三,特征分解的计算复杂度为 O ( n 3 ) O(n^3) O(n3)。在后续工作中,ChebNet 和 GCN 通过进行一些近似和简化将计算复杂度降低到 O ( m ) O(m) O(m)。
Chebyshev谱CNN (ChebNet) Defferrard等人提出ChebNet, 定义特征向量对角矩阵的切比雪夫多项式为近似滤波器,即 g θ = ∑ i = 1 K θ i T k ( Λ ~ ) g_{\theta}=\sum_{i=1}^{K} \theta_{i} T_{k}(\widetilde{\Lambda}) gθ=∑i=1KθiTk(Λ ), Λ ~ = 2 Λ / λ max − I n \widetilde{\Lambda}=2 \Lambda / \lambda_{\max }-I_{n} Λ =2Λ/λmax−In, Λ ~ \widetilde{\Lambda} Λ 的值在 [-1,1] 之间。切比雪夫多项式递归定义为: T i ( x ) = 2 x T i − 1 ( x ) − T i − 2 ( x ) T_{i}(x)=2 x T_{i-1}(x)-T_{i-2}(x) Ti(x)=2xTi−1(x)−Ti−2(x),其中 T 0 ( x ) = 1 , T 1 ( x ) = x T_{0}(x)=1, T_{1}(x)=x T0(x)=1,T1(x)=x。图信号 x x x 与定义的滤波器 g θ g_\theta gθ 的卷积为:
x ∗ G g θ = U ( ∑ i = 0 K θ i T k ( Λ ~ ) ) U T x , (7) x *_G g_{\theta} = U\left(\sum_{i=0}^{K} \theta_{i} T_{k}(\widetilde{\Lambda})\right) U^{T} x, \tag{7} x∗Ggθ=U(i=0∑KθiTk(Λ ))UTx,(7)
其中 L ~ = 2 L / λ max − I n \widetilde{L}=2 L / \lambda_{\max }-I_{n} L =2L/λmax−In。因为 T i ( L ~ ) = U T i ( Λ ~ ) U T T_i(\widetilde{L}) = UT_i(\widetilde{\Lambda}) U^T Ti(L )=UTi(Λ )UT,可以通过归纳证明,ChebNet具有以下形式
x ∗ G g θ = ∑ i = 0 K θ i T i ( L ~ ) x , (8) x *_G g_{\theta} = \sum_{i=0}^{K} \theta_{i} T_{i}(\widetilde{L}) x, \tag{8} x∗Ggθ=i=0∑KθiTi(L )x,(8)
作为对谱CNN的改进,ChebNet定义的滤波器在空间上是局部的,这意味着滤波器可以独立于图的大小提取局部特征。ChebNet的频谱被线性映射到 [-1,1] 。CayleyNet进一步应用Cayley多项式,Cayley多项式是参数化的复变函数,用于捕捉窄频段。CayleyNet的频谱图卷积定义为
x ∗ G g θ = c 0 x + 2 R e { ∑ j = 1 r c j ( h L − i I ) j ( h L + i I ) − j x } x *_G g_{\theta} = c_0 x + 2Re\{ \sum_{j=1}^r c_j (hL-iI)^j (hL+iI)^{-j}x \} x∗Ggθ=c0x+2Re{j=1∑rcj(hL−iI)j(hL+iI)−jx}
其中 R e ( ⋅ ) Re(\cdot) Re(⋅) 返回复数的实部, c 0 c_0 c0 是实系数, c j c_j cj 是复系数, i i i 是虚数, h h h 是控制Cayley滤波器频谱的参数。在保留空间局部性的同时,CayleyNet表明ChebNet是CayleyNet的一个特例。
图卷积网络(GCN) Kip等人引入了一种一阶近似ChebNet。假设 K = 1 , λ max = 2 , K=1, \lambda_{\max }=2, K=1,λmax=2, 上式简化为:
x ∗ G g θ = θ 0 x − θ 1 D − 1 2 A D − 1 2 x . (10) x *_G g_{\theta}=\theta_{0} x-\theta_{1} D^{-\frac{1}{2}} A D^{-\frac{1}{2}} x. \tag{10} x∗Ggθ=θ0x−θ1D−21AD−21x.(10)
为了抑制参数数量防止过拟合, GCN 假设 θ = θ 0 = − θ 1 \theta=\theta_{0}=-\theta_{1} θ=θ0=−θ1,图卷积的定义就变为:
x ∗ G g θ = θ ( I n + D − 1 2 A D − 1 2 ) x . (11) x *_G g_{\theta} = \theta\left(I_{n}+D^{-\frac{1}{2}} A D^{-\frac{1}{2}}\right) x. \tag{11} x∗Ggθ=θ(In+D−21AD−21)x.(11)
为了融合多维图输入信号, GCN 对上式进行修改提出了图卷积层:
H = x ∗ G g θ = f ( A ‾ X k Θ ) , (12) H = x *_G g_{\theta} = f(\overline{A} X^{k} \Theta), \tag{12} H=x∗Ggθ=f(AXkΘ),(12)
其中 A ‾ = I n + D − 1 2 A D − 1 2 \overline{A}=I_{n}+D^{-\frac{1}{2}} A D^{-\frac{1}{2}} A=In+D−21AD−21, f ( ⋅ ) f(\cdot) f(⋅) 是一个激活函数。使用 I n + D − 1 2 A D − 1 2 I_{n}+D^{-\frac{1}{2}} A D^{-\frac{1}{2}} In+D−21AD−21 会导致GCN数值不稳定。为了解决这个问题,GCN应用了一个规范化技巧(renormalization trick)把 A ‾ = I n + D − 1 2 A D − 1 2 \overline{A} = I_n + D^{-\frac{1}{2}} A D^{-\frac{1}{2}} A=In+D−21AD−21 替换成 A ‾ = D ~ − 1 2 A ~ D ~ − 1 2 \overline{A}=\widetilde{D}^{-\frac{1}{2}} \widetilde{A} \widetilde{D}^{-\frac{1}{2}} A=D −21A D −21,其中 A ~ = A + I n \widetilde{A} = A+I_n A =A+In, D ~ i i = ∑ j A ~ i j \widetilde{D}_{ii} = \sum_{j} \widetilde{A}_{ij} D ii=∑jA ij。作为基于频谱的方法,GCN也可以解释为基于空间的方法。从基于空间的角度看,GCN可以看作是从节点邻域聚合特征信息。公式12可以表示为
h v = f ( Θ T ( ∑ u ∈ { N ( v ) ∪ v } A ‾ v , u x u ) ) ∀ v ∈ V . (13) h_v = f \left(\Theta^T (\sum_{u \in \{ N(v)\cup v \}} \overline{A}_{v,u}x_u) \right) \quad \forall v \in V. \tag{13} hv=f⎝⎛ΘT(u∈{N(v)∪v}∑Av,uxu)⎠⎞∀v∈V.(13)
最近的几项工作通过探索替代对称矩阵对GCN进行了改进。自适应图卷积网络(AGCN,AAAI2018) 学习图邻接矩阵未指定的隐藏结构关系。它通过一个可学习的距离函数构造一个所谓的残差图邻接矩阵,该函数将两个节点的特征作为输入。对偶图卷积网络(DGCN,WWW2018) 引入了对偶卷积架构,其中两个图卷积层并行。这两个层共享参数,它们使用归一化邻接矩阵 A ‾ \overline{A} A 和正点向互信息(positive pointwise mutual information, PPMI)矩阵,该矩阵通过从图中采样的随机游走捕获节点共现信息(co-occurrence information )。PPMI矩阵定义为
P P M I v 1 , v 2 = m a x ( l o g ( c o u n t ( v 1 , v 2 ) ⋅ ∣ D ∣ c o u n t ( v 1 ) c o u n t ( v 2 ) ) , 0 ) , (14) PPMI_{v_1,v_2} = max \left(log( \frac{count(v_1,v_2) \cdot |D|}{count(v_1)count(v_2)}), 0 \right), \tag{14} PPMIv1,v2=max(log(count(v1)count(v2)count(v1,v2)⋅∣D∣),0),(14)
其中 v 1 , v 2 ∈ V v_1,v_2 \in V v1,v2∈V, ∣ D ∣ = ∑ v 1 , v 2 c o u n t ( v 1 , v 2 ) |D| = \sum_{v_1,v_2} count(v_1,v_2) ∣D∣=∑v1,v2count(v1,v2), c o u n t ( ⋅ ) count(\cdot) count(⋅) 函数返回采样随机游动中节点 v v v 和/或 节点 u u u 同时发生的频率。通过合并来自对偶图卷积层的输出,DGCN可以对局部和全局结构信息进行编码,而无需堆叠多个图卷积层。
B 基于空间的卷积神经网络
类似于传统CNN在图像上的卷积操作,基于空间的方法根据节点的空间关系定义图的对话。图像可以被看作是一种特殊形式的图,每个像素代表一个节点。每个像素直接与其附近的像素相连,如图1a所示。
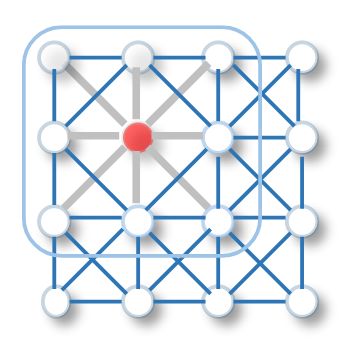
(1a) 二维卷积。 类似于一个图形,图像中的每一个像素都被当作一个节点,其中的邻居由滤波器大小决定。 二维卷积将红色节点的像素值的加权平均数与它的邻节点一起计算。节点的邻居是有序的,并且有一个固定的大小。
通过获取每个通道上中心节点及其邻居的像素值的加权平均值,将滤波器应用于一个3×3色块。类似地,基于空间的图卷积将中心节点的表示与其邻居的表示进行卷积,以导出中心节点的更新表示,如图1b所示。
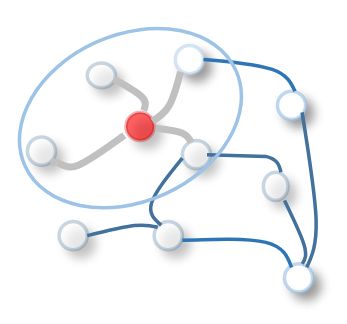
(1b) 图卷积。为了获得红节点的隐式表示,图卷积运算的一种简单解决方案是取红色节点及其邻居的节点特征的平均值。与图像数据不同,节点的邻居无序且大小可变。
从另一个角度来看,基于空间的ConvGNNs与RecGNNs共享相同的信息传播/消息传递思想。空间图卷积运算本质上沿着边传播节点信息。
与GNN* 并行提出的图神经网络(NN4G)是针对基于空间的ConvGNNs的第一项工作。与RecGNNs不同的是,NN4G通过在每一层具有独立参数的组合神经体系结构来学习图的相互依赖性。节点的邻域可以通过渐进式构建架构来扩展。 NN4G通过直接汇总节点的邻域信息来执行图卷积。它还会应用残差连接和跳过连接来存储每个层上的信息。结果,NN4G以下方式推导出下一层节点状态
h v ( k ) = f ( W ( k ) T x v + ∑ i = 1 k − 1 ∑ u ∈ N ( v ) Θ ( k ) T h u ( k − 1 ) ) , (15) h^{(k)}_v = f(W^{(k)^T}x_v + \sum_{i=1}^{k-1} \sum_{u \in N(v)} \Theta^{(k)^T} h^{(k-1)}_u), \tag{15} hv(k)=f(W(k)Txv+i=1∑k−1u∈N(v)∑Θ(k)Thu(k−1)),(15)
其中, f ( ⋅ ) f(\cdot) f(⋅) 是激活函数, h v ( 0 ) = 0 h^{(0)}_v = 0 hv(0)=0。等式15也可以用矩阵形式表示:
H ( k ) = f ( X W ( k ) + ∑ i = 1 k − 1 A H ( k − 1 ) Θ ( k ) ) , (16) H^{(k)} = f(XW^{(k)} + \sum_{i=1}^{k-1}AH^{(k-1) }\Theta^{(k)}), \tag{16} H(k)=f(XW(k)+i=1∑k−1AH(k−1)Θ(k)),(16)
类似于GCN的形式。一个区别是NN4G使用非规范的邻接矩阵,这可能会导致隐藏的节点状态具有极为不同的尺度。上下文图马尔可夫模型(CGMM)受NN4G启发,提出了一种概率模型。在保持空间局部性的同时,CGMM具有概率解释能力。
扩散卷积神经网络(DCNN)将图卷积看作扩散过程。它假设信息以一定的转移概率从一个节点转移到其相邻的节点之一,因此信息分布可以在几轮之后达到平衡。DCNN将扩散图卷积定义为
H ( k ) = f ( W ( k ) ⊙ P k X ) , (17) H^{(k)} = f(W^{(k)} \odot P^{k}X), \tag{17} H(k)=f(W(k)⊙PkX),(17)
其中, f ( ⋅ ) f(\cdot) f(⋅) 是激活函数,概率转移矩阵 P ∈ R n × n P\in R^{n \times n} P∈Rn×n 是由 P = D − 1 A P = D^{-1}A P=D−1A计算。请注意,在DCNN中,隐藏表示矩阵 H ( k ) H^{(k)} H(k) 的维数与输入特征矩阵 X X X 相同,并且不是其先前的隐藏表示矩阵 H ( k − 1 ) H^{(k-1)} H(k−1) 的函数。DCNN将 H ( 1 ) , H ( 2 ) , ⋯ , H ( K ) H^{(1)},H^{(2)},\cdots, H^{(K)} H(1),H(2),⋯,H(K) 串联在一起作为最终模型输出。由于扩散过程的平稳分布是概率转移矩阵的幂级数的总和,因此,扩散图卷积(DGC)将每个扩散步骤的输出相加,而不是合并。 定义了扩散图的卷积
H = ∑ k = 0 K f ( P k X W ( k ) ) , (18) H = \sum^{K}_{k=0} f(P^k X W^{(k)}), \tag{18} H=k=0∑Kf(PkXW(k)),(18)
其中 W ( k ) ∈ R D × F W(k) \in R^{D×F} W(k)∈RD×F, f ( ⋅ ) f(·) f(⋅) 是激活函数。使用转移概率矩阵的幂意味着远处的邻居对中心节点贡献的信息很少。PGC-DGCNN 基于最短路径增加了邻居的贡献。它定义了最短路径邻接矩阵 S ( j ) S(j) S(j)。如果从节点到节点的最短路径的长度为 j j j,则 S v , u ( j ) = 1 S^{(j)}_{v,u} = 1 Sv,u(j)=1 否则为 0。PGC-DGCNN采用超参数控制感受野大小,引入图卷积运算如下
H ( k ) = ∥ j = 0 r f ( ( D ~ ( j ) ) − 1 S ( j ) H ( k − 1 ) W ( j , k ) ) , (19) H^{(k)} = \|^{r}_{j=0} f \left( (\widetilde{D}^{(j)})^{-1} S^{(j)} H^{(k-1)} W^{(j,k)} \right), \tag{19} H(k)=∥j=0rf((D (j))−1S(j)H(k−1)W(j,k)),(19)
其中 D ~ i i ( j ) = ∑ l S i , l ( j ) \widetilde{D}^{(j)}_{ii}= \sum_{l} S^{(j)}_{i,l} D ii(j)=∑lSi,l(j), H ( 0 ) = X H^{(0)} =X H(0)=X, ∥ \| ∥表示向量的串联。最短路径邻接矩阵的计算在 O ( n 3 ) O(n^3) O(n3) 最大的情况下可能会很昂贵。分区图卷积(PGC)根据某些条件(不限于最短路径)将节点的邻居划分为 Q Q Q 组。PGC根据每个组定义的邻域构造邻接矩阵。然后,PGC将具有不同参数矩阵的GCN 应用于每个邻居组,并对结果求和
H ( k ) = ∑ j = 1 Q A ‾ ( j ) H ( k − 1 ) W ( j , k ) , (20) H^{(k)} = \sum^{Q}_{j=1} \overline{A}^{(j)} H^{(k-1)}W^{(j,k)}, \tag{20} H(k)=j=1∑QA(j)H(k−1)W(j,k),(20)
其中 H ( 0 ) = X H^{(0)}= X H(0)=X, A ‾ j = ( D ~ ( j ) ) − 1 2 A ~ ( j ) ( D ~ ( j ) ) − 1 2 \overline{A}^{j} = (\widetilde{D}^{(j)})^{-\frac{1}{2}} \widetilde{A}^{(j)} (\widetilde{D}^{(j)})^{-\frac{1}{2}} Aj=(D (j))−21A (j)(D (j))−21, A ~ ( j ) = A ‾ ( j ) + I \widetilde{A}^{(j)} = \overline{A}^{(j)} + I A (j)=A(j)+I。
消息传递神经网络(MPNN)概述了基于空间的ConvGNNs的一般框架。它将图卷积视为一个信息传递过程,其中信息可以沿着边直接从一个节点传递到另一个节点。MPNN运行 K K K 步信息传递迭代,让信息进一步传播。信息传递函数(即空间图卷积)定义为
h v ( k ) = U k ( h v ( k − 1 ) , ∑ u ∈ N ( v ) M k ( h v ( k − 1 ) , h u ( k − 1 ) , x v u e ) ) , (21) h_{v}^{(k)}=U_{k}\left(h_{v}^{(k-1)}, \sum_{u \in N(v)} M_{k}\left(h_{v}^{(k-1)}, h_{u}^{(k-1)}, x_{v u}^{e}\right)\right), \tag{21} hv(k)=Uk⎝⎛hv(k−1),u∈N(v)∑Mk(hv(k−1),hu(k−1),xvue)⎠⎞,(21)
其中 h v ( 0 ) = x v h^{(0)}_v = x_v hv(0)=xv, U k ( ⋅ ) U_k(\cdot) Uk(⋅) 和 M k ( ⋅ ) M_k(\cdot) Mk(⋅) 是具有可学习参数的函数。导出每个节点的隐藏表示后, h v ( K ) h^{(K)}_v hv(K) 可以传递到输出层以执行节点级的预测任务,也可以传递给读出功能以执行图级的预测任务。读出功能基于节点的隐藏表示形式生成整个图的表示形式。通常定义为
h G = R ( h v ( K ) ∣ v ∈ G ) , (22) h_G = R( h^{(K)}_v | v\in G), \tag{22} hG=R(hv(K)∣v∈G),(22)
其中, R ( ⋅ ) R(\cdot) R(⋅) 表示具有可学习参数的读出功能。通过假设 U k ( ⋅ ) U_k(\cdot) Uk(⋅), M k ( ⋅ ) M_k(\cdot) Mk(⋅) 和 R ( ⋅ ) R(\cdot) R(⋅) 的不同形式,MPNN可以覆盖许多现有的GNN。然而,图同构网络(GIN)发现,以前基于MPNN的方法不能根据它们产生的图嵌入来区分不同的图结构。为了弥补这一缺点,GIN通过可学习的参数 ϵ ( k ) \epsilon^{(k)} ϵ(k) 来调整中心节点的权重。它通过执行图卷积
h v ( k ) = M L P ( ( 1 + ϵ ( k ) ) h v ( k − 1 ) + ∑ u ∈ N ( v ) h u ( k − 1 ) ) , (23) h_{v}^{(k)}=M L P\left(\left(1+\epsilon^{(k)}\right) h_{v}^{(k-1)}+\sum_{u \in N(v)} h_{u}^{(k-1)}\right), \tag{23} hv(k)=MLP⎝⎛(1+ϵ(k))hv(k−1)+u∈N(v)∑hu(k−1)⎠⎞,(23)
其中 M L P ( ⋅ ) MLP(\cdot) MLP(⋅) 代表多层感知器。
由于一个节点的邻居的数量可能从1到1000甚至更多不等,因此获取节点邻居的完整大小是低效的。GraphSage 采用采样为每个节点获取固定数量的邻居。它通过执行图卷积
h v ( k ) = σ ( W ( k ) ⋅ f k ( h v ( k − 1 ) , { h u ( k − 1 ) , ∀ u ∈ S N ( v ) } ) ) , (24) h_{v}^{(k)}=\sigma\left(W^{(k)} \cdot f_{k}\left(h_{v}^{(k-1)},\left\{h_{u}^{(k-1)}, \forall u \in S_{\mathcal{N}(v)}\right\}\right)\right), \tag{24} hv(k)=σ(W(k)⋅fk(hv(k−1),{hu(k−1),∀u∈SN(v)})),(24)
其中, h v ( 0 ) = x v h^{(0)}_v = x_v hv(0)=xv, f k ( ⋅ ) f_k(\cdot) fk(⋅) 是一个聚合函数, S N ( v ) S_{\mathcal{N}(v)} SN(v) 是该节点 v v v 邻居的随机样本。聚合函数应该对节点排序的变化不产生影响,如平均、总和或最大函数。
图形注意力网络(GAT)假设相邻节点对中心节点的贡献既不像GraphSage那样完全相同,也不像GCN那样预先确定(这一区别在图4中得到说明)。GAT采用注意力机制来学习两个连接的节点之间的相对权重。图卷积运算定义为:
h v ( k ) = σ ( ∑ u ∈ N ( v ) ∪ v α v u ( k ) W ( k ) h u ( k − 1 ) ) , (25) h_{v}^{(k)}=\sigma\left(\sum_{u \in \mathcal{N}(v) \cup v} \alpha_{v u}^{(k)} W^{(k)} h_{u}^{(k-1)}\right), \tag{25} hv(k)=σ⎝⎛u∈N(v)∪v∑αvu(k)W(k)hu(k−1)⎠⎞,(25)
其中 h v ( 0 ) = x v h^{(0)}_v = x_v hv(0)=xv。注意力权重 α v u ( k ) \alpha_{v u}^{(k)} αvu(k) 衡量节点 v v v 与邻居 u u u 之间的连接强度:
α v u ( k ) = s o f t m a x ( g ( a T [ W ( k ) h v ( k − 1 ) ∥ W ( k ) h u ( k − 1 ) ) ) \alpha_{v u}^{(k)} = softmax\left(g\left(\mathbf{a}^{T}\left[W^{(k)} h_{v}^{(k-1)} \| W^{(k)} h_{u}^{(k-1)}\right)\right)\right. αvu(k)=softmax(g(aT[W(k)hv(k−1)∥W(k)hu(k−1)))
其中 g ( ⋅ ) g(\cdot) g(⋅) 是LeakyReLU激活函数,并且 a \mathbf{a} a 是可学习参数的向量。softmax函数可确保注意权重在节点 v v v 的所有邻居上总和为一。GAT进一步执行多头关注以提高模型的表达能力。.这显示出在节点分类任务上比GraphSage有了明显的改进。尽管GAT假定关注头的贡献是相等的,但门控关注网络(GAAN)介绍了一种自我注意机制,该机制可以为每个注意头计算一个额外的注意分数。除了在空间上应用图注意力外,GeniePath 进一步提出了一种类似于LSTM的门控机制,以控制跨图卷积层的信息流。还有其他可能引起关注的图注意力模型。但是,它们不属于ConvGNN框架。
(4a) GCN 明确将非参数权重 a i j = 1 d e g ( v i ) d e g ( v j ) a_{ij} = \frac{1}{\sqrt{deg(v_i)deg(v_j)}} aij=deg(vi)deg(vj)1分配给 v i v_i vi 的邻居 v j v_j vj,以证明聚合过程。
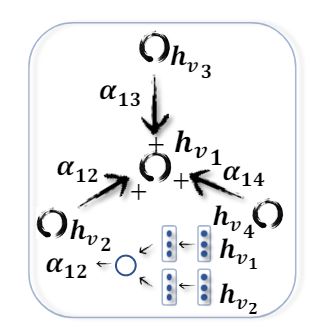
(4b) GAT 通过一个端到端的神经网络架构隐含地捕获了权重 a i j a_{ij} aij,因此,更重要的节点会得到更大的权重。
图4:GCN 和 GAT 之间的差异
混合模型网络(MoNet)采用不同的方法为节点的邻居分配不同的权重。它引入节点伪坐标以确定节点与其邻居之间的相对位置。一旦知道两个节点之间的相对位置,权重函数就会将相对位置映射到这两个节点之间的相对权重。这样,可以在不同位置之间共享图形过滤器的参数。在MoNet框架下,已有的几种流形方法,例如Geodesic CNN(GCNN),Anisotropic CNN (ACNN) , SplineCNN, 对于GCN、DCNN 这样的图,可以通过构造非参数权函数来推广为MoNet的特例。MoNet还提出了一个具有可学习参数的高斯核,以自适应地学习权重函数。
另一个独特的工作路线是通过基于某些标准对一个节点的邻居进行排名,并将每个排名与一个可学习的权重联系起来,实现不同位置的权重共享。PATCHY-SAN 根据每个节点的图标签对其邻居进行排序,并选择前 q q q 个邻居。图标记本质上是节点分数,可以通过节点度,中心性和Weisfeiler-Lehman颜色得出。由于现在每个节点都有固定数量的有序邻居,图结构的数据可以转化为网格结构的数据。PATCHY-SAN 应用标准的1D卷积过滤器来汇总邻域特征信息,其中过滤器权重的顺序与节点邻居的顺序相对应。PATCHY-SAN的排序标准仅考虑图结构,这需要大量计算才能进行数据处理。大型图卷积网络(LGCN)根据节点特征信息对节点邻居进行排序。对于每一个节点,LGCN集合了一个由其邻居组成的特征矩阵,并沿每一列对该特征矩阵进行排序。排序后的特征矩阵的前 q q q 行被作为中心节点的输入数据。
提高训练效率 训练ConvGNN,如GCN,通常需要将所有节点的全图数据和中间状态保存到内存。ConvGNNs 的全批训练算法受到内存溢出问题的严重影响,特别是当一个图包含数百万个节点时。为了节省内存,Graph-Sage 提出了一种针对ConvGNN的批量训练算法。它以固定的样本大小按 K K K 步递归扩展根节点的邻域来对每个节点的树进行采样。对于每个采样的树,GraphSage通过从下到上分层聚合隐藏节点的表示,计算根节点的隐藏表示。
图卷积网络快速学习(Fast-GCN) 为每个图卷积层采样一个固定数量的节点,而不是像GraphSage 那样为每个节点采样一个固定数量的邻域。它将图卷积解释为概率度量下的节点嵌入函数的积分变换。采用蒙特卡洛近似法和减少方差技术来促进训练过程。由于FastGCN对每一层的节点进行独立采样,层与层之间的连接有可能是稀疏的。Huang等人提出了一种适应性的层级取样方法,其中底层的节点取样以顶层为条件。与FastGCN相比,这种方法获得了更高的精度,但代价是采用了更复杂的采样方案。
在另一项工作中,图卷积网络的随机训练(StoGCN) 使用历史节点表示作为控制变量,将图卷积的接受域大小减小到任意小的规模。即使每个节点有两个邻居,StoGCN也能获得相当好的性能。然而,StoGCN仍然要保存所有节点的中间状态,这对大图来说是很耗内存的。
Cluster-GCN 使用图聚类算法对子图进行采样,并对采样子图中的节点进行图卷积。由于邻域搜索也被重新限制在采样子图内,Cluster-GCN能够处理更大的图,并同时使用更深的架构,在更短的时间和更少的内存。Cluster-GCN为现有的ConvGNN训练算法提供了一个直接的时间复杂度和内存复杂度的比较。我们根据表IV分析其结果。
表IV:ConvGNN训练算法的时间和内存复杂度比较。 n n n 节点总数, m m m 边总数, K K K 层数, s s s 批大小, r r r 每个节点采样的邻居数量。为简单起见,节点隐藏特征的尺寸保持不变,用 d d d 表示。
| 复杂度 | GCN[22] | GraphSage[42] | FastGCN [49] | StoGCN [50] | Cluster-GCN [58] |
|---|---|---|---|---|---|
| 时间 | O ( K m d + K n d 2 ) O(Kmd+Knd^2) O(Kmd+Knd2) | O ( r K n d 2 ) O(r^Knd^2) O(rKnd2) | O ( K r n d 2 ) O(Krnd^2) O(Krnd2) | O ( K m d + K n d 2 + r K n d 2 ) O(Kmd+Knd^2+r^Knd^2) O(Kmd+Knd2+rKnd2) | O ( K m d + K n d 2 ) O(Kmd+Knd^2) O(Kmd+Knd2) |
| 内存 | O ( K n d + K d 2 ) O(Knd+Kd^2) O(Knd+Kd2) | O ( s r K d + K d 2 ) O(sr^Kd + Kd^2) O(srKd+Kd2) | O ( K s r d 2 + k d 2 ) O(Ksrd^2 + kd^2) O(Ksrd2+kd2) | O ( K n d + K d 2 ) O(Knd+^Kd^2) O(Knd+Kd2) | O ( K s d + K d 2 ) O(Ksd+Kd^2) O(Ksd+Kd2) |
在表IV中,GCN 是基准方法,它进行了全批训练。GraphSage 以牺牲时间效率为代价来节省内存。同时,GraphSage 的时间和内存复杂性随着 K K K 和 r r r 的增加而呈指数级增长。StoGCN 的时间复杂度最高,并且内存瓶颈仍未解决。然而,StoGCN 可以在 r r r 非常小的情况下实现令人满意的性能。Cluster-GCN 的时间复杂度与基线方法相同,因为它没有引入多余的计算。在所有方法中,Cluster-GCN 实现了最低的内存复杂性。
谱系模型与空间模型之间的比较 频谱模型在图形信号处理方面有一个理论基础。通过设计新的图信号滤波器(如Cayleynets),人们可以建立新的ConvGNNs。但是,由于效率,通用性和灵活性问题,与频谱模型相比,空间模型更为可取。首先,频谱模型的效率不如空间模型。谱系模型要么需要进行特征向量计算,要么在同一时间处理整个图。空间模型对大图的扩展性更强,因为它们通过信息传播直接在图域中进行卷积。计算可以在一批节点中进行,而不是在整个图中进行。其次,依赖于图Fourier基的谱模型很难推广到新的图。他们假设一个固定的图。对图的任何扰动都会导致特征基的变化。另一方面,基于空间的模型在每个节点上局部地执行图卷积,不同的位置和结构可以很容易地共享权重。第三,基于谱系的模型仅限于在无向图上操作。基于空间的模型可以更灵活地处理多源图的输入,如边输入、有向图、有符号图和异构图,因为这些图输入可以很容易地整合到聚合函数中。
C 图池化模块
在GNN生成节点特征后,我们可以将其用于最终任务。但是直接使用所有这些特征可能在计算上具有挑战性,因此,需要一个向下采样的策略。根据目标及其在网络中所起的作用,该策略有不同的名称:(1) 池化操作的目的是通过对节点的下采样来减少参数的大小,以产生更小的表示,避免过拟合,排列不变性和计算复杂性问题;(2) 读出操作主要用于生成基于节点代表的图级表示。它们的机制是非常相似的。在本章中,我们用池化来指代应用于GNN的各种下采样策略。
在以前的一些工作中,基于拓扑结构的图粗化算法使用特征分解来粗化图(coarsen graphs )。然而,这些方法存在时间复杂性问题。Graclus 算法是特征分解的一种替代方法,用于计算原始图的聚类版本。最近的一些工作将图粗化算法作为一种对粗化图的池化操作。现在,平均/最大/和 池化是实现下采样的最原始和最有效的方法,因为在池化窗口中计算 平均/最大/和 值很快:
h G = m e a n / m a x / s u m ( h 1 ( K ) , h 2 ( K ) , ⋅ , h n ( K ) ) , (27) h_G = mean/max/sum(h^{(K)}_1, h^{(K)}_2,\cdot,h^{(K)}_n), \tag{27} hG=mean/max/sum(h1(K),h2(K),⋅,hn(K)),(27)
其中 K K K 是最后一个图卷积层的层数。
Henaff等人的研究表明,在网络的开始阶段进行简单的最大/均值池化,对于降低图域的维度和减轻昂贵的图傅里叶变换操作的成本尤为重要。此外,一些文献也使用注意机制来增强 均值/和 池。
即使使用注意力机制,减少操作(如求和池)也不令人满意,因为它使嵌入效率低下:无论图的大小,都会产生一个固定大小的嵌入。Vinyals等人提出了Set2Set方法来生成一个随输入大小而增加的内存。然后,它实现了一个LSTM,打算在应用减少操作之前,将与顺序有关的信息整合到内存嵌入中,否则会破坏这些信息。
Defferrard等人通过以有意义的方式重新安排图中的节点,以另一种方式解决这个问题。他们在自己的方法ChebNet中提出了有效的池化策略。输入图首先被Graclusal算法粗化为多个层。在粗化之后,输入图的节点及其粗化版本被重新排列成一个平衡的二叉树。任意地将平衡二叉树从下往上聚合,会将相似的节点安排在一起。池化这样一个重新安排的信号比池化原来的信号要有效得多。
Zhang等人提出的DGCNN有一个类似的池化策略,名为SortPooling,它通过将节点重新排列成一个有意义的顺序来执行池化。与ChebNet不同,DGCNN根据节点在图中的结构角色对节点进行排序。来自空间图卷积的图的无序节点特征被视为连续的WL颜色,然后它们被用来给节点排序。除了对节点特征进行排序外,它还通过 截断/拓展 节点特征矩阵,将图的大小统一为 q q q。如果 n > q n \gt q n>q,则删除最后 n − q n-q n−q 行,否则添加 q − n q-n q−n 个零行。
前面提到的集合方法主要考虑图的特征,而忽略了图的结构信息。最近,有人提出了一种可微分池(DiffPool),它可以生成图的分层表示。与以前所有的粗化方法相比,DiffPool 不是简单地对图中的节点进行聚类,而是在第 k k k 学习一个聚类的分配矩阵 S S S ,称为 S ( k ) ∈ R n k × n k + 1 S(k) \in R^{n_k \times n_{k+1}} S(k)∈Rnk×nk+1,其中 n k n_k nk 是第 k k k 层的节点数。矩阵 S ( k ) S^{(k)} S(k) 中的概率值是根据节点特征和拓扑结构生成的,使用了
S ( k ) = s o f t m a x ( C o n v G N N k ( A ( k ) , h ( k ) ) ) . (28) S^{(k)} = softmax(ConvGNN_k (A^{(k)}, h^{(k)})). \tag{28} S(k)=softmax(ConvGNNk(A(k),h(k))).(28)
其核心思想是学习全面的节点分配,同时考虑图的拓扑和特征信息,因此方程28可以用任何标准的ConvGNN来实现。然而,DiffPool的缺点是,它在池化后会产生密集图,此后的计算复杂度会变成 O ( n 2 ) O(n^2) O(n2)。
最近,SAGPool 方法被提出,它同时考虑了节点特征和图的拓扑结构,并以自我注意的方式来学习池化。
总的来说,池化是减少图形大小的一个基本操作。 如何提高池化的有效性和计算复杂性是一个有待研究的问题。
D 理论方面的讨论
我们从不同角度讨论图神经网络的理论基础。
感受野的形状 节点的感受野是有助于确定其最终节点表示的节点集。在合成多个空间图卷积层时,一个节点的感受野每次都会向其远处的邻居提前一步增长。Micheli 证明存在有限数量的空间图卷积层,使得对于每个结点 v ∈ V v\in V v∈V,结点 v v v 的感受野覆盖图中的所有结点。因此,ConvGNN能够通过叠加局部图卷积层来提取全局信息。
VC 维度 VC维度是对模型复杂性的衡量,被定义为一个模型可以破坏的最大点数。关于分析GNN的VC维度的工作很少。考虑到模型参数数 p p p 和节点数 n n n,Scarselli等人推导出GNN* 如果使用sigmoid或双曲正切激活,则VC维度是 O ( p 4 n 2 ) O(p^4n^2) O(p4n2),如果它使用分片多项式激活,则VC维度是 O ( p 2 n ) O(p^2n) O(p2n)。这一结果表明,如果使用sigmoid或正切双曲线激活,GNN* 的模型复杂性会迅速增加。
图同构 如果两个图在拓扑上相同,则它们是同构的。给定两个非同构图 G 1 G_1 G1 和 G 2 G_2 G2,Xu等人证明,如果一个GNN将 G 1 G_1 G1 和 G 2 G_2 G2 映射到不同的嵌入,这两个图可以通过Weisfeiler-Lehman(WL)的同构性测试被识别为非同构。他们表明,普通的GNN,如GCN和GraphSage都无法区分不同的图结构。Xu等人[57]进一步证明,如果GNN的聚合函数和读出函数具有映射性,则GNN最多与WL测试一样强大,可以区分不同的图。
等变性和不变性 GNN在执行节点级任务时必须是等变函数,而在执行图级任务时必须是不变函数。对于节点级任务,让 f ( A , X ) ∈ R n × d f(A,X)\in R^{n×d} f(A,X)∈Rn×d 是一个GNN, Q Q Q 是改变节点顺序的任何置换矩阵。如果一个GNN满足 f ( Q A Q T , Q X ) = Q f ( A , X ) f(QAQ^T,QX)=Qf(A,X) f(QAQT,QX)=Qf(A,X),那么它就是等价的。 对于图级任务,让 f ( A , X ) ∈ R d f(A,X)\in R^d f(A,X)∈Rd。如果一个GNN满足 f ( Q A Q T , Q X ) = f ( A , X ) f(QAQ^T,QX)=f(A,X) f(QAQT,QX)=f(A,X),那么它就是不变的。为了实现等变性或不变性,GNN的组成部分必须对节点排序不产生影响。Maron等人从理论上研究了图数据的互换不变和等价线性层的特性。
普遍近似 众所周知,具有一个隐藏层的多感知器前馈神经网络可以近似任何Borel可测量的函数。GNNs的普遍近似能力很少被研究。Hammer等人证明级联相关(cascade correlation)可以近似具有结构化输出的函数。Scarselli等人证明,RecGNN 可以近似任何保留了展开等价的函数,并达到任何精度程度。如果两个节点的展开树相同,则两个节点的展开等价,其中节点的展开树是通过将节点的邻域迭代扩展到一定深度而构造的。Xu等人表明,在消息传递的框架下,ConvGNNs 不是定义在多集合上的连续函数的通用近似器。Maron等人证明,一个不变图网络可以近似于定义在图上的任意不变函数。
6 图自动编码器
图自动编码器(GAE)是一种深度神经架构,它将节点映射到潜在的特征空间,并从潜在的表征中解码图信息。GAEs可以用来学习网络嵌入或生成新图。表V总结了所选GAE的主要特征。在下文中,我们从网络嵌入和图生成两个角度简要概述了GAE。
表V:选定GAE的主要特征
| 方法 | 输入 | 编码 | 解码 | 目标 |
|---|---|---|---|---|
| DNGR (2016) [59] | A A A | a multi-layer perceptron | a multi-layer perceptron | 重建PPMI矩阵 |
| SDNE (2016) [60] | A A A | a multi-layer perceptron | a multi-layer perceptron | 保留节点一阶和二阶相似度 |
| GAE* (2016) [61] | A , X A,X A,X | a ConvGNN | a similarity measure | 重建邻接矩阵 |
| VGAE (2016) [61] | A , X A,X A,X | a ConvGNN | a similarity measure | 了解数据的生成分布 |
| ARVGA(2018)[62] | A , X A,X A,X | a ConvGNN | a similarity measure | 对抗性地学习数据的生成分布 |
| DNRE(2018)[63] | A A A | an LSTM network | an identity function | 恢复网络嵌入 |
| NetRA (2018) [64] | A A A | an LSTM network | an LSTM network | 利用对抗训练恢复网络嵌入 |
| DeepGMG (2018) [65] | A , X , X e A,X,X^e A,X,Xe | a RecGNN | a decision process | 最大化预期的联合对数似然 |
| GraphRNN (2018) [66] | A A A | a RNN | an identity function | 最大化排列的可能性 |
| GraphVAE (2018) [67] | A , X , X e A,X,X^e A,X,Xe | a ConvGNN | a multi-layer perceptron | 优化重建损失 |
| RGVAE (2018) [68] | A , X , X e A,X,X^e A,X,Xe | a CNN | a deconvolutional net | 带有效性约束的重建损失优化 |
| MolGAN (2018) [69] | A , X , X e A,X,X^e A,X,Xe | a ConvGNN | a multi-layer perceptron | 优化生成对抗损失和RL损失 |
| NetGAN(2018)[70] | A A A | an LSTM network | an LSTM network | 优化生成对抗损失 |
A 网络嵌入
网络嵌入是一个节点的低维向量代表,它保留了一个节点的拓扑信息。GAE学习网络嵌入,使用编码器来提取网络嵌入,并使用解码器来强化网络嵌入,以保留图的拓扑信息,如PPMI矩阵和邻接矩阵。
早期的方法主要采用多层感知器来建立网络嵌入学习的GAE。图表示的深度神经网络(DNGR)使用堆叠的去噪自动编码器通过多层感知器对PPMI矩阵进行编码和解码。同时,结构深度网络嵌入(SDNE)使用堆叠式自动编码器共同保存节点的一阶接近度和二阶接近度。SDNE对编码器的输出和解码器的输出分别提出两个损失函数。第一个损失函数使学习到的网络嵌入能够通过最小化一个节点的网络嵌入和其邻居的网络嵌入之间的距离来保持节点的一阶接近性。第一个损失函数 L 1 s t L_{1st} L1st 被定义为
L 1 s t = ∑ ( v , u ) ∈ E A v , u ∥ e n c ( x v ) − e n c ( x u ) ∥ 2 , (29) L_{1st} = \sum_{(v,u) \in E} A_{v,u} \|enc(x_v)-enc(x_u)\|^2, \tag{29} L1st=(v,u)∈E∑Av,u∥enc(xv)−enc(xu)∥2,(29)
其中 x v = A v , : x_v = A_{v,:} xv=Av,:,而 e n c ( ⋅ ) enc(\cdot) enc(⋅) 是一个由多层感知器组成的编码器。第二个损失函数使学到的网络嵌入能够通过最小化节点的输出和其重建的输入之间的距离来保持节点的二阶接近性。具体地,第二损失函数 L 2 n d L_{2nd} L2nd 定义为
L 2 n d = ∑ v ∈ V ∥ d e c ( e n c ( x v ) − x v ) ⊙ b v ∥ 2 , (30) L_{2nd} = \sum_{v \in V} \| dec(enc(x_v)-x_v) \odot b_v \|^2, \tag{30} L2nd=v∈V∑∥dec(enc(xv)−xv)⊙bv∥2,(30)
其中
b v , u = { 1 if A v , u = 0 β > 1 if A v , u = 1 , b_{v,u}=\left\{\begin{array}{lll} 1 & \text { if } & A_{v,u} = 0 \\ \beta \gt 1 & \text { if } & A_{v,u} = 1, \end{array}\right. bv,u={1β>1 if if Av,u=0Av,u=1,
而 d e c ( ⋅ ) dec(\cdot) dec(⋅) 是一个由多层感知器组成的解码器。
DNGR 和 SDNE只考虑节点结构信息,即关于节点对之间的连接性。他们忽略了节点可能包含描述节点本身属性的特征信息。图自动编码器GAE*利用 GCN 来同时编码节点结构信息和节点特征信息。GAE* 的编码器由两个图卷积层组成,其形式为
Z = e n c ( X , A ) = G c o n v ( f ( G c o n v ( A , X ; Θ 1 ) ) ; Θ 2 ) , (31) Z = enc(X,A) = Gconv(f(Gconv(A,X;\Theta_1));\Theta_2), \tag{31} Z=enc(X,A)=Gconv(f(Gconv(A,X;Θ1));Θ2),(31)
其中 Z Z Z 表示图的网络嵌入矩阵, f ( ⋅ ) f(\cdot) f(⋅) 是一个ReLU激活函数, G c o n v ( ⋅ ) Gconv(\cdot) Gconv(⋅) 函数是一个由公式12定义的图卷积层。GAE* 的解码器旨在通过重建图的邻接矩阵,从它们的嵌入中解码节点的关系信息,其定义如下
A ^ v , u = d e c ( z v , z u ) = σ ( z v T z u ) , (32) \hat{A}_{v,u} = dec(z_v,z_u) = \sigma(z^T_v z_u), \tag{32} A^v,u=dec(zv,zu)=σ(zvTzu),(32)
其中 z v z_v zv 是节点 v v v 的嵌入。GAE* 是通过最小化负交叉熵来训练的,给定的是真实邻接矩阵 A A A 和重建的邻接矩阵 A ^ \hat{A} A^。
由于自动编码器的容量,简单地重建图的邻接矩阵可能会导致过度拟合。可变图自动编码器(VGAE)是GAE的变体版本,用于学习数据分布。VGAE优化了变量下限 L L L:
L = E q ( Z ∣ X , A ) [ l o g p ( A ∣ Z ) ] − K L [ q ( Z ∣ X , A ) ∥ p ( Z ) ] , (33) L = E_{q(Z|X,A)}[logp(A|Z)] -KL[q(Z|X,A) \|p(Z)], \tag{33} L=Eq(Z∣X,A)[logp(A∣Z)]−KL[q(Z∣X,A)∥p(Z)],(33)
其中 K L ( ⋅ ) KL(\cdot) KL(⋅) 是Kullback-Leibler发散函数,它衡量两个分布之间的距离, p ( Z ) p(Z) p(Z) 是高斯先验 p ( Z ) = ∏ i = 1 n p ( z i ) = ∏ i = 1 n N ( z i ∣ 0 , I ) p(Z) = \prod^{n}_{i=1} p(z_i) = \prod^{n}_{i=1} N(z_i|0,I) p(Z)=∏i=1np(zi)=∏i=1nN(zi∣0,I), p ( A i j = 1 ∣ z i , z j ) = d e c ( z i , z j ) = σ ( z i T z j ) p(A_{ij}=1 | z_i,z_j) = dec(z_i,z_j) = \sigma(z^T_i z_j) p(Aij=1∣zi,zj)=dec(zi,zj)=σ(ziTzj), q ( Z ∣ X , A ) = ∏ i = 1 n q ( z i ∣ X , A ) q(Z|X,A) = \prod^{n}_{i=1} q(z_i | X,A) q(Z∣X,A)=∏i=1nq(zi∣X,A),其中 q ( z i ∣ X , A ) = N ( z i ∣ μ i , d i a g ( σ 2 ) ) q(z_i | X,A) = N(z_i | \mu_i, diag(\sigma^2)) q(zi∣X,A)=N(zi∣μi,diag(σ2))。平均向量 μ i \mu_i μi 是方程31所定义的编码器输出的第 i t h i^{th} ith行, l o g σ i log \sigma_i logσi 与另一个编码器的 μ i \mu_i μi 类似地推导。根据等式33,VGA假定经验分布 q ( Z ∣ X , A ) q(Z | X,A) q(Z∣X,A) 应尽可能接近先验分布 p ( Z ) p(Z) p(Z)。为了进一步加强经验分布 q ( Z ∣ X , A ) q(Z | X,A) q(Z∣X,A) 近似于先验分布 p ( Z ) p(Z) p(Z),对抗正则化的变分图自动编码器(ARVGA) 采用了生成对抗网络(GAN)的训练方案。在训练生成模型时,GAN在生成器和鉴别器之间进行竞争。一个生成器试图生成尽可能真实的 “假样本”,而鉴别器则试图将 "假样本 "与真实样本区分开来。受GAN的启发,ARVGA努力学习一种编码器,该编码器产生的经验分布 q ( Z ∣ X , A ) q(Z | X,A) q(Z∣X,A) 与先验分布 p ( Z ) p(Z) p(Z) 不易区分。
与GAE* 类似,GraphSage用两个图卷积层对节点特征进行编码。GraphSage并没有优化重建误差,而是显示了两个节点之间的关系信息可以通过负采样来保留,以保持损失:
L ( z v ) = − l o g ( d e c ( z v , z u ) ) − Q E v n ∼ P n ( v ) l o g ( − d e c ( z v , z v n ) ) , (34) L(z_v) = -log(dec(z_v,z_u)) - QE_{v_n \sim P_n(v)} log(-dec(z_v,z_{v_n})), \tag{34} L(zv)=−log(dec(zv,zu))−QEvn∼Pn(v)log(−dec(zv,zvn)),(34)
其中,节点 u u u 是节点 v v v 的邻居,节点 v n v_n vn 是与节点 v v v 相距较远的节点,并从负采样分布 P n ( v ) P_n(v) Pn(v) 中抽样, Q Q Q 是负采样的数量。这个损失函数本质上是强制要求接近的节点有类似的表示,而较远的节点有不同的表示。DGI通过最大限度地提高局部互换信息来驱动局部网络嵌入以获取全局结构信息。 在实验中,它比GraphSage有明显的改进。
对于上述方法,它们基本上是通过解决一个链接预测问题来学习网络嵌入。然而,图的稀疏性导致正节点对的数量远远少于负节点对的数量。为了缓解学习网络嵌入中的数据稀少问题,另一项工作是通过随机排列或随机游走将图转换成序列。这样一来,那些适用于序列的深度学习方法就可以直接用于处理图。深度递归网络嵌入(DRNE)假设一个节点的网络嵌入应该近似于其邻域网络嵌入的聚合。它采用长短时记忆(LSTM)网络来聚合一个节点的邻居。DRNE的重建误差定义为
L = ∑ u ∈ V ∥ z v − L S T M ( { z u ∣ u ∈ N ( v ) } ) ∥ 2 , (35) L = \sum_{u \in V} \|z_v -LSTM(\{z_u | u \in N(v) \})\|^2, \tag{35} L=u∈V∑∥zv−LSTM({zu∣u∈N(v)})∥2,(35)
其中 z v z_v zv 是通过字典查询得到的节点 v v v 的网络嵌入,而LSTM网络则采用按其节点度排序的节点 v v v 邻居的随机序列作为输入。如公式35所示,DRNE通过LSTM网络隐含地学习网络嵌入,而不是使用LSTM网络来生成网络嵌入。它避免了LSTM网络对节点序列的排列不变的问题。网络表征与对抗性正则化自动编码器(NetRA)提出了一个具有通用损失函数的图编码器-解码器框架,定义为
L = − E z ∼ P d a t a ( z ) ( d i s t ( z , d e c ( e n c ( z ) ) ) ) , (36) L = - E_{z \sim P_data(z)}(dist(z,dec(enc(z)))), \tag{36} L=−Ez∼Pdata(z)(dist(z,dec(enc(z)))),(36)
其中, d i s t ( ⋅ ) dist(\cdot) dist(⋅) 是节点嵌入 z z z 和重建 z z z 之间的距离测量。NetRA的编码器和解码器是LSTM网络,其随机游走扎根在每个结点 v ∈ V v\in V v∈V上作为输入。与ARVGA类似,NetRA通过对抗性训练对预先分布的学习网络嵌入进行规范化。尽管NetRA忽略了LSTM网络的节点置换变量问题,但实验结果验证了NetRA的有效性。
B 图生成
通过使用多个图,GAE可以通过将图编码为隐藏表示,并解码给定隐藏表示的图结构来学习图的生成分布。大多数用于图形生成的GAE都是为解决分子图形生成问题而设计的,在药物发现中具有很高的实用价值。这些方法或者以顺序方式或者以全局方式提出一个新图。
顺序方法通过一步步提出节点和边来生成图。Gomez等人、Kusner等人和Dai等人分别用deep和RNNs作为编码器和解码器来模拟分子图的字符串表示法的生成过程。虽然这些方法是针对特定领域的,但其他的解决方案也适用于一般的图,方法是在一个不断增长的图上反复增加节点和边,直到满足某个标准。图的深度生成模型(DeepGMG) 假定一个图的概率是所有可能的节点排列组合的总和:
p ( G ) = ∑ π p ( G , π ) , (37) p(G) = \sum_{\pi} p(G,\pi), \tag{37} p(G)=π∑p(G,π),(37)
其中 π \pi π 表示节点顺序。它捕捉了图中所有节点和边的复杂联合概率。 DeepGMG通过一连串的决策来生成图,即是否添加一个节点,添加哪个节点,是否添加一条边,以及哪个节点连接到新节点。生成节点和边的决策过程以RecGNN更新的增长图的节点状态和图状态为条件。在另一项工作中,GraphRNN提出了一个图级RNN和一个边级RNN来模拟节点和边的生成过程。图层面的RNN每次向节点序列添加一个新的节点,而边层面的RNN产生一个二进制序列,表明新的节点和先前在序列中生成的节点之间的联系。
全局性的方法一次就能输出一个图。图变自动编码器(GraphVAE)将节点和边的存在建模为独立随机变量。通过假设由编码器定义的后验分布 q φ ( z ∣ G ) q_{\varphi}(z|G) qφ(z∣G) 和由解码器定义的生成分布 p θ ( G ∣ z ) p_\theta(G|z) pθ(G∣z),GraphVAE优化了变分下界:
L ( ϕ , θ ; G ) = E q ϕ ( z ∣ G ) [ − log p θ ( G ∣ z ) ] + K L [ q ϕ ( z ∣ G ) ∥ p ( z ) ] , (38) L(\phi, \theta ; G)=E_{q_{\phi}(z \mid G)}\left[-\log p_{\theta}(G \mid z)\right]+K L\left[q_{\phi}(z \mid G) \| p(z)\right], \tag{38} L(ϕ,θ;G)=Eqϕ(z∣G)[−logpθ(G∣z)]+KL[qϕ(z∣G)∥p(z)],(38)
其中 p ( z ) p(z) p(z) 遵循高斯先验, φ \varphi φ 和 θ \theta θ 为可学习参数。用ConvGNN作为编码器,用简单的多层感知作为解码器,GraphVAE输出一个生成的图及其邻接矩阵、节点属性和边的属性。控制生成的图的全局属性,如图的连通性、有效性和节点的兼容性,是一个挑战。**正则化图变自动编码器(RGVAE)**进一步对图变自动编码器施加有效性约束,以正则化解码器的输出分布。分子生成对抗网络(MolGAN) 整合了convGNNs、GANs和强化学习目标来生成具有所需属性的图。MolGAN由一个生成器和一个鉴别器组成,相互竞争以提高生成器的真实性。在MolGAN中,生成器试图提出一个假图及其特征矩阵,而判别器则旨在将假样本与经验数据区分开来。此外,一个奖励网络与判别器平行引入,以鼓励生成的图形根据外部评估器拥有某些属性。NetGAN 将 LSTM 与 Wasserstein GAN 结合起来,从基于随机游走的方法生成图。NetGAN训练生成器通过LSTM网络生成合理的随机游动,并强制执行鉴别器以从真实的随机游动中识别出虚假的随机游动。训练后,通过标准化基于生成器产生的随机游走而计算出的节点的共现矩阵,可以得出新的图。
简而言之,顺序方法将图线性化为序列。由于存在循环,它们可能会丢失结构信息。全局方法一次产生一个图。由于GAE的输出空间高达 O ( n 2 ) O(n^2) O(n2),因此它们无法扩展到大型图。
7 时空图神经网络
许多现实世界的应用中的图在图结构和图输入方面都是动态的。时空图神经网络(STGNN)在捕获图的动态性方面占据重要位置。这类方法旨在为动态节点输入建模,同时假设连接节点之间的相互依赖性。例如,交通网络由放置在道路上的速度传感器组成,其边缘权重由一对传感器之间的距离决定。由于一条道路的交通状况可能取决于其相邻道路的状况,在进行交通速度预测时有必要考虑空间依赖性。作为一种解决方案,STGNNs同时捕捉到了图的空间和时间依赖性。STGNNs的任务可以在预测未来节点值或标签之前,或预测空间-时间图的标签。STGNNs遵循两个方向,基于RNN的方法和基于CNN的方法。
大多数基于RNN的方法通过使用图卷积过滤传递给当前单元的输入和隐藏状态来捕获时空依赖性。为了说明这一点,假设一个简单的RNN采用以下形式
H ( t ) = σ ( W X ( t ) + U H ( t − 1 ) + b ) , (39) H^{(t)} = \sigma(WX^{(t)} + UH^{(t-1)} + b), \tag{39} H(t)=σ(WX(t)+UH(t−1)+b),(39)
其中 X ( t ) ∈ R n × d X(t) \in R^{n\times d} X(t)∈Rn×d表示时间步 t t t 的节点特征矩阵。插入图卷积后,公式39变为
H ( t ) = σ ( G c o n v ( X ( t ) , A ; W ) + G c o n v ( H ( t − 1 ) , A ; U ) + b ) , (40) H^{(t)} = \sigma(Gconv(X^{(t)},A; W) + Gconv(H^{(t-1)},A; U) + b), \tag{40} H(t)=σ(Gconv(X(t),A;W)+Gconv(H(t−1),A;U)+b),(40)
其中 G c o n v ( ⋅ ) Gconv(\cdot) Gconv(⋅) 是图卷积层。图卷积循环网络(GCRN)结合了LSTM网络和ChebNet。扩散卷积神经网络(DCRNN)将提出的扩散图卷积层(公式18)纳入了GRU网络中。此外,DCRNN采用了编码器-解码器框架来预测节点值的未来 K K K 步。
另一项并行的工作使用节点级RNN和边级RNN来处理不同方面的时间信息。结构性RNN提出了一个递归框架,在每个时间步骤预测节点标签。它包括两种RNN,即一个节点RNN和一个边RNN。每个节点和每个边的时间信息分别通过一个节点-RNN和一个边-RNN进行传递。为了纳入空间信息,一个节点-RNN将边-RNN的输出作为输入。由于为不同的节点和边假设不同的RNN,大大增加了模型的复杂性,因此它把节点和边分成了语义组。同一语义组中的节点共享相同的RNN模型,从而节省了计算成本。
基于RNN的方法受到耗时的迭代传播和梯度爆炸问题的影响。作为替代解决方案,基于CNN的方法以非递归方式处理时空图,具有并行计算,稳定的梯度和低内存需求的优点。如图2d所示,基于CNN的方法将1D-CNN层与图卷积层交织以分别学习时间和空间依赖性。假设时空图神经网络的输入为张量 X ∈ R T × n × d X\in R^{T\times n\times d} X∈RT×n×d,一维CNN层沿时间轴在 X [ : , i , : ] \mathcal{X}[:,i,:] X[:,i,:] 上滑动,以聚集每个节点的时间信息,而图卷积层在 X [ i , : , : ] \mathcal{X}[i,:,:] X[i,:,:] 上操作,以汇总每个时间步上的空间信息。CGCN将一维卷积层与ChebNet或GCN层整合。它通过按顺序堆叠有门控的一维卷积层、图卷积层和另一个有门控的一维卷积层来构建一个空间-时间块。ST-GCN使用一个一维卷积层和一个PGC层组成了一个空间-时间块(公式20)。
以前的方法都是使用预定义的图结构。他们假定预定义的图结构反映了节点之间真正的依赖关系。然而,在空间-时间设置中,有了图数据的快照,就有可能从数据中自动学习潜在的静态图结构。为了实现这一点,Graph WaveNet 提出了自适应的邻接矩阵来进行图的卷积。自适应邻接矩阵定义为
A a d p = S o f t M a x ( R e L U ( E 1 E 2 T ) ) , (41) A_{adp} = SoftMax(ReLU(E_1E^T_2)), \tag{41} Aadp=SoftMax(ReLU(E1E2T)),(41)
其中,SoftMax函数是沿着行维度计算的, E 1 E1 E1 表示源节点嵌入, E 2 E2 E2 表示目标节点嵌入的可学习参数。通过将 E 1 E1 E1 乘以 E 2 E2 E2,可以得到源节点和目标节点之间的依赖权重。对于一个复杂的基于CNN的空间-时间神经网络,Graph WaveNet在没有得到邻接矩阵的情况下表现良好。
学习潜在的静态空间依赖关系可以帮助再研究者发现网络中不同实体之间的可解释和稳定的相关性。然而,在某些情况下,学习潜在的动态空间依赖关系可能会进一步提高模型的精度。例如,在一个交通网络中,两条道路之间的旅行时间可能取决于它们当前的交通状况。GaAN采用注意力机制,通过基于RNN的方法学习动态空间依赖关系。注意力函数用于在给定当前节点输入的情况下更新两个连接节点之间的边权重。ASTGCN进一步包括空间注意函数和时间注意函数,通过基于CNN的方法学习潜在的动态空间依赖和时间依赖。学习潜在的空间依赖关系的共同缺点是,它需要计算每对节点之间的空间依赖权重,其成本为 O ( n 2 ) O(n^2) O(n2)。
8 应用
由于图结构化数据无处不在,因此GNN具有广泛的应用。在本节中,我们分布总结了是基准图数据集、评估方法和开源实现。我们详细介绍了GNN在各个领域的实际应用。
A 数据集
我们主要将数据集分为四类,即引文网络,生化图,社交网络等。在表VI中,我们总结了选定的基准数据集。补充材料A中有更多详细信息。
表VI:选定基准数据集的汇总
| 分类 | 数据集 | 来源 | # 图 | #节点(平均) | #边(平均) | #特征 | #类 | #引文 |
|---|---|---|---|---|---|---|---|---|
| 引文网络 | Cora | 117 | 1 | 2708 | 5429 | 1433 | 7 | [22], [23], [25], [41], [43], [44], [45][49], [50], [51], [53], [56], [61], [62] |
| Citeseer | 117 | 1 | 3327 | 4732 | 3703 | 6 | [22], [41], [43], [45], [50], [51], [53][56], [61], [62] | |
| Pubmed | 117 | 1 | 19717 | 44338 | 500 | 3 | [18], [22], [25], [41], [43], [44], [45][49], [51], [53], [55], [56], [61], [62][70], [95] | |
| DBLP (v11) | 118 | 1 | 4107340 | 36624464 | - | - | [64], [70], [99] | |
| 生物化学图 | PPI | 119 | 24 | 56944 | 818716 | 50 | 121 | [18], [42], [43], [48], [45], [50], [55][56], [58], [64] |
| NCI-1 | 120 | 4110 | 29.87 | 32.30 | 37 | 2 | [25], [26], [46], [52], [57], [96], [98] | |
| MUTAG | 121 | 188 | 17.93 | 19.79 | 7 | 2 | [25], [26], [46], [52], [57], [96] | |
| D&D | 122 | 1178 | 284.31 | 715.65 | 82 | 2 | [26], [46], [52], [54], [96], [98] | |
| PROTEIN | 123 | 1113 | 39.06 | 72.81 | 4 | 2 | [26], [46], [52], [54], [57] | |
| PTC | 124 | 344 | 25.5 | - | 19 | 2 | [25], [26], [46], [52], [57] | |
| QM9 | 125 | 133885 | - | - | - | - | [27], [69] | |
| Alchemy | 126 | 119487 | - | - | - | - | - | |
| 社交网络 | 42 | 1 | 232965 | 11606919 | 602 | 41 | [42], [48], [49], [50], [51], [56] | |
| BlogCatalog | 127 | 1 | 10312 | 333983 | - | 39 | [18], [55], [60], [64] | |
| 其它 | MNIST | 128 | 70000 | 784 | - | 1 | 10 | [19], [23], [21], [44], [96] |
| METR-LA | 129 | 1 | 207 | 1515 | 2 | - | [48], [72], [76] | |
| Nell | 130 | 1 | 65755 | 266144 | 61278 | 210 | [22], [41], [50] |
B 评估和开源实施
节点分类和图分类是评估RecGNN和ConvGNN性能的常见任务。
节点分类 在节点分类中,大多数方法都遵循在基准数据集(包括Cora、Citeseer、Pubmed、PPI和Reddit)上进行训练和测试的标准划分。他们报告了在测试数据集上多次运行的平均准确性或F1得分。方法的实验结果的总结可以在补充材料B中找到。应该指出的是,这些结果不一定代表严格的比较。Shchur等人发现在评估GNNs在节点分类上的性能时有两个陷阱。首先,在所有实验中使用相同的训练/有效/测试划分会低估泛化误差。其次,不同的方法采用了不同的训练技术,例如超参数调整,参数初始化,学习率衰减和提前停止。详细比较请参考Shchur等人的文章。
图分类 在图分类中,研究人员通常采用10-fold交叉验证(cv)进行模型评估。然而,正如[132]所指出的,实验设置是模糊的,在不同的工作中并不统一。特别地,[132]引起了对模型选择与模型评估的数据分割的正确使用的关注。一个经常遇到的问题是,每个fold的外部测试集都被用于模型选择和风险评估。[132]在一个标准化的、统一的评估框架中比较GNN。他们使用外部10倍CV来评估模型的泛化性能和内部保持技术,并使用90%/ 10%的训练/验证来选择模型。另一种程序是双cv法,即用外部k-fold cv进行模型评估,用内部 k-fold cv进行模型选择。关于图分类的GNN方法的详细和严格的比较,请参考[132]。
开源实现 促进深度学习研究中的基线实验的工作。在补充材料C中,我们提供了本文回顾的GNN模型的开源实现的超链接。值得注意的是,Fey等人在PyTorch中发表了一个名为PyTorch Geometric的几何学习库,它实现了许多GNNs。最近,DeepGraph Library (DGL)被发布,它在流行的深度学习平台(如PyTorch和MXNet)上提供了许多GNN的快速实现。
C 实际应用
GNN在不同的任务和领域有许多应用。尽管一般的任务可以由GNN的每个类别直接处理,包括节点分类、图分类、网络嵌入、图生成和时空图预测,但其他与图相关的一般任务,如节点聚类、链接预测和图分区也可以由GNN来处理。 我们详细介绍了基于以下研究领域的一些应用。
计算机视觉 GNN在计算机视觉中的应用包括场景图生成、点云分类和动作识别。识别物体之间的语义关系有助于理解视觉场景背后的意义。场景图生成模型旨在将图像解析为语义图,该图由物体及其语义关系组成。另一个应用通过生成给定场景图的现实图像来逆转这一过程。由于自然语言可以被解析为语义图,其中每个词都代表一个对象,因此在给出文字描述的情况下合成图像是一种很有前途的解决方案。
对点云的分类和分割使LiDAR设备能够 "看到 "周围的环境。点云是由LiDAR扫描记录的一组三维点。将点云转换为K-近邻图或超点图,并使用ConvGNNs探索拓扑结构。
识别视频中包含的人类行为有助于从机器方面更好地理解视频内容。一些解决方案检测视频片段中人类关节的位置。由骨骼链接的人体关节自然形成一个图形。给定人类关节位置的时间序列,将STGNNs用于学习人类行为模式。
此外,GNNs在计算机视觉中的应用方向仍在不断增加。 它包括human-object交互,few-shot图像分类,语义分割,视觉推理,以及问题回答。
自然语言处理 GNN在自然语言处理中的一个常见应用是文本分类。GNN利用文档或词的相互关系来推断文档标签。尽管自然语言数据表现出顺序性,但它们也可能包含一个内部图结构,如句法依赖树。句法依赖树定义了句子中单词之间的句法关系。Marcheggiani等人提出了句法GCN,它在CNN/RNN句子编码器的基础上运行。Syntactic GCN根据句子的句法依赖树来聚合隐藏的词的表示。Bastings等人将句法GCN应用于神经机器翻译的任务。Marcheggiani等人进一步采用与Bastings等人相同的模型来处理一个句子的语义依赖图。
Graph-to-sequence 学习在给定抽象单词语义图的情况下生成具有相同含义的句子(被称为抽象意义表征)。Song等人提出了一个图-LSTM来编码图级语义信息。Beck等人将GGNN应用于graph-to-sequence 学习和神经机器翻译。 逆向任务是 sequence-to-graph 的学习。 在知识发现中,给定一个句子生成语义图或知识图是非常有用的。
交通 准确预测交通网络中的交通速度、交通量或道路密度在智能交通系统中具有根本的重要性。使用STGNN解决交通预测问题,将交通网络视为一个时空图,其中节点是安装在道路上的传感器,边缘是通过成对的节点之间的距离来测量的,并且每个节点具有窗口内的平均交通速度作为动态输入特征。另一个工业层面的应用是出租车需求预测。鉴于历史出租车需求、位置信息、天气数据和事件特征,Yao等人将LSTM、CNN和由LINE训练的网络嵌入结合起来,对每个位置进行联合表示,以预测一个时间间隔内一个位置的出租车需求数量。
推荐系统 基于图的推荐系统把项目和用户作为节点。 通过利用项目与项目、用户与用户、用户与项目以及内容信息之间的关系,基于图的推荐系统能够产生高质量的推荐。推荐系统的关键是对一个项目对用户的重要性进行评分。因此,它可以被视为一个链接预测的问题。为了预测用户和项目之间缺失的链接,Van等人和Ying等人提出了一个使用ConvGNNs作为编码的GAE。 Monti等人将RNNs与图卷积结合起来,以学习产生已知评级的基本过程。
化学 在化学领域,研究人员应用GNN来研究分子化合物的图形结构。在分子/化合物图中,原子被视为节点,化学键被视为边。节点分类、图分类和图生成是针对分子化合物图的三个主要任务,以便学习分子指纹,预测分子特性,推断蛋白质界面,并合成化学化合物。
其它 GNNs的应用并不限于上述领域和任务。 已有人探索将GNNs应用于各种问题,如程序验证、程序推理、社会影响预测、对抗性攻击预防、电子健康记录建模、大脑网络、事件检测和组合优化。
9 未来发展方向
尽管GNNs已经证明了其在学习图形数据方面的能力,但由于图形的复杂性,挑战仍然存在。在本节中,我们提出了GNN的四个未来方向。
模型深度 深度学习的成功在于深度神经架构。 然而,Li等人表明,随着图卷积层数量的增加,ConvGNN的性能急剧下降。理论上,随着图卷积将相邻节点的表示推向彼此更近,具有无限数量的图卷积层,所有节点的表示将收敛到单个点。这就提出了一个问题:深入学习是否仍然是学习图数据的好策略。
可伸缩性权衡 GNN的可扩展性是以破坏图的完整性为代价获得的。 无论是使用抽样还是聚类,一个模型都会失去部分图的信息。通过抽样,一个节点可能会错过其有影响力的邻居。通过聚类,一个图可能被剥夺了一个独特的结构模式。 如何权衡算法的可扩展性和图形的完整性可能是未来的研究方向。
异质性 当前的大多数GNN假设为同质图。很难直接应用当前的 GNNs 到异构图,该图可能包含不同类型的节点和边,或不同形式的节点和边输入,例如图像和文本。因此,应该开发新的方法来处理异构图。
动态性 图在本质上是动态的,节点或边可能会出现或消失,而且节点边的输入可能会随着时间而改变。为了适应图形的动态性,需要新的图卷积。尽管STGNNs可以部分解决图形的动态性问题,但很少有STGNNs考虑到在动态空间关系的情况下如何进行图卷积。
10 结论
在这项调查中,我们对图神经网络进行了全面的概述。我们提供了一个分类法,将图神经网络分为四类:递归图神经网络、卷积图神经网络、图自动编码器和空间-时间图神经网络。我们提供了一个全面的回顾、比较,并总结了类别内或类别之间的方法。然后,我们介绍了图神经网络的广泛应用。我们总结了图神经网络的数据集、开源代码和模型评估。 最后,我们提出了图神经网络的四个未来发展方向。
附录
A 数据集
引文网络 虽然引文网络是有向图,但在评估模型性能时,它们经常被当作无向图来处理,如节点分类、链接预测和节点聚类等任务。 有三个流行的论文引用网络的数据集,Cora、Citeseer和Pubmed。Cora数据集包含2708个机器学习出版物,分为七个类别。Citeseer数据集包含3327篇科学论文,分为六个类别。 Cora和Citeseer中的每篇论文都由一个 one-hot 向量表示,表明字典中的某个词的存在或不存在。Pubmed data集包含19717篇与糖尿病有关的出版物。Pubmed中的每篇论文都由一个术语频率-反向文档频率(TF-IDF)向量表示。 此外,DBLP是一个大型的引文数据集,有数百万篇论文和作者,这些都是从计算机科学书目中收集的。DBLP的数据集可以在https:/dblp.uni-trier.de上找到。DBLP论文引用网络的处理版本通过https:/aminer.orgcitation持续更新。
生化图 化学分子和化合物可以用化学图表示,原子是节点,化学键是边。这类图经常被用来评估图分类性能。 NCI-1和NCI-9数据集分别包含4110和4127个化合物,标明它们是否对阻碍人类癌症细胞系的生长有活性。MUTAG数据集包含188个硝基化合物,标明它们是芳香族还是杂芳香族。 D&D和PROTEIN数据集以图表形式表示蛋白质,标明它们是酶还是非酶。PTC数据集包括344种化合物,标明它们对雄性和雌性大鼠是否致癌。 QM9数据集记录了133885个重原子的分子的13种物理特性。Alchemy数据集记录了包含多达14个重原子的119487个分子的12个量子力学特性。另一个重要的数据集是蛋白质-蛋白质相互作用网络(PPI)。 它包含24个生物图,节点由蛋白质代表,边由蛋白质之间的相互作用代表。在PPI中,每个图与一个人体组织相关联。每个节点都被标记为其生物状态。
社交网络 是由BlogCatalog和Reddit等在线服务的用户互动形成的。 BlogCatalog数据集是一个由博主和他们的社会关系组成的社会网络。 博主的类别代表了他们的个人兴趣。Reddit数据集是一个由Reddit讨论区收集的帖子组成的无向图。如果两个帖子包含同一用户的评论,那么这两个帖子就有联系。每个帖子都有一个标签,表示它所属的社区。
其它 还有几个值得一提的数据集。MNIST数据集包含7万张大小为28×28的图像,上面标有10位数字。一个MNINST图像被转换为一个图,基于它的像素位置构建一个8-近邻图。METR-LA是一个时空图数据集。它包含由洛杉矶县高速公路上的207个传感器收集的四个月的交通数据。图的邻接矩阵是通过传感器网络距离和高斯阈值来计算的。NELL数据集是从Never-Ending Language Learning项目获得的知识图。它由三元组表示的事实组成,其中涉及两个实体及其关系。
B 报告的节点分类实验结果
表VII给出了遵循标准训练/有效/测试划分的方法的实验结果的总结。
表VII:在五个常用数据集上进行节点分类的报告实验结果。 Cora,Citeseer和Pubmed均通过分类准确性进行评估。 PPI和Reddit通过微观平均F1得分进行评估。
| 模型 | Cora | Citeseer | Pumbed | PPI | |
|---|---|---|---|---|---|
| SSE (2018) | - | - | - | 83.60 | - |
| GCN (2016) | 81.50 | 70.30 | 79.00 | - | - |
| Cayleynets (2017) | 81.90 | - | - | - | - |
| DualGCN (2018) | 83.50 | 72.60 | 80.00 | - | - |
| GraphSage (2017) | - | - | - | 61.20 | 95.40 |
| GAT (2017) | 83.00 | 72.50 | 79.00 | 97.30 | - |
| MoNet (2017) | 81.69 | - | 78.81 | - | - |
| LGCN (2018) | 83.30 | 73.00 | 79.50 | 77.20 | - |
| GAAN (2018) | - | - | - | 98.71 | 96.83 |
| FastGCN (2018) | - | - | - | - | 93.70 |
| StoGCN (2018) | 82.00 | 70.90 | 78.70 | 97.80 | 96.30 |
| Huang et al. (2018) | - | - | - | - | 96.27 |
| GeniePath (2019) | - | - | 78.50 | 97.90 | - |
| DGI (2018) | 82.30 | 71.80 | 76.80 | 63.80 | 94.00 |
| Cluster-GCN (2019) | - | - | - | 99.36 | 96.60 |
C 开源实现
在这里,我们总结了调查中回顾的图神经网络的开源实现。我们在表VIII中提供了GNN模型源代码的超链接。
表VIII:开源实现的总结
| 模型 | 框架 | Github链接 |
|---|---|---|
| GGNN (2015) | torch | https://github.com/yujiali/ggnn |
| SSE (2018) | c | https://github.com/Hanjun-Dai/steady_state_embedding |
| ChebNet (2016) | tensorflow | https://github.com/mdeff/cnn_graph |
| GCN (2017) | tebsorflow | https://github.com/tkipf/gcn |
| CayleyNet (2017) | tensorflow | https://github.com/amoliu/CayleyNet |
| DualGCN (2018) | theano | https://github.com/ZhuangCY/DGCN |
| GraphSage (2017) | tensorflow | https://github.com/williamleif/GraphSAGE |
| GAT (2017) | tensorflow | https://github.com/PetarV-/GAT |
| LGCN (2018) | tensorflow | https://github.com/divelab/lgcn/ |
| PGC-DGCNN (2018) | pytorch | https://github.com/dinhinfotech/PGC-DGCNN |
| FastGCN (2018) | tensorflow | https://github.com/matenure/FastGCN |
| StoGCN (2018) | tensorflow | https://github.com/thu-ml/stochastic_gcn |
| DGCNN (2018) | torch | https://github.com/muhanzhang/DGCNN |
| DiffPool (2018) | pytorch | https://github.com/RexYing/diffpool |
| DGI (2019) | pytorch | https://github.com/PetarV-/DGI |
| GIN (2019) | pytorch | https://github.com/weihua916/powerful-gnns |
| Cluster-GCN (2019) | pytorch | https://github.com/benedekrozemberczki/ClusterGCN |
| DNGR (2016) | matlab | https://github.com/ShelsonCao/DNGR |
| SDNE (2016) | tensorflow | https://github.com/suanrong/SDNE |
| GAE (2016) | tensorflow | https://github.com/limaosen0/Variational-Graph-Auto-Encoders |
| ARVGA (2018) | tensorflow | https://github.com/Ruiqi-Hu/ARGA |
| DRNE (2016) | tensorflow | https://github.com/tadpole/DRNE |
| GraphRNN (2018) | tensorflow | https://github.com/snap-stanford/GraphRNN |
| MolGAN (2018) | tensorflow | https://github.com/nicola-decao/MolGAN |
| NetGAN (2018) | tensorflow | https://github.com/danielzuegner/netgan |
| GCRN (2016) | tensorflow | https://github.com/youngjoo-epfl/gconvRNN |
| DCRNN (2018) | tensorflow | https://github.com/liyaguang/DCRNN |
| Structural RNN (2016) | theano | https://github.com/asheshjain399/RNNexp |
| CGCN (2017) | tensorflow | https://github.com/VeritasYin/STGCN_IJCAI-18 |
| ST-GCN (2018) | pytorch | https://github.com/yysijie/st-gcn |
| GraphWaveNet (2019) | pytorch | https://github.com/nnzhan/Graph-WaveNet |
| ASTGCN (2019) | mxnet | https://github.com/Davidham3/ASTGCN |