TF-IDF
词汇袋(BoW)通过计算文档中的词汇出现次数将文本转换为特征向量。它不考虑单词的重要性。Term frequency - Inverse document frequency (TFIDF)是基于Bag of Words (BoW)模型的,它包含了对文档中不太相关和比较相关的词的洞察力。一个词在文本中的重要性在信息检索中具有重要意义。
例如–如果你在搜索引擎上搜索一些东西,在TFIDF值的帮助下,搜索引擎可以给我们提供与我们的搜索最相关的文件。
我们将详细讨论TFIDF如何告诉我们哪个词更重要:
我们将首先分别研究术语频率(TF)和逆向文档频率(IDF),然后在最后将其合并。
术语频率(TF)
它是衡量一个词(w)在一个文档(d)中的频率。TF被定义为一个词在文档中出现的次数与文档中总词数的比率。公式中的分母项是为了规范化,因为所有的语料库文件都有不同的长度。
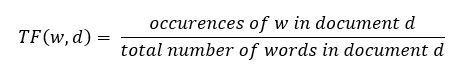
逆向文档频率(IDF)
它是对一个词的重要性的衡量。术语频率(TF)并不考虑单词的重要性。有些词,如 “的”、"和 "等,可能是最频繁出现的,但意义不大。IDF根据每个词在语料库D中的频率为其提供权重。
一个词(w)的IDF被定义为:

考虑以下语料库:
Train Document Set:
d1: The sky is blue.
d2: The sun is bright.
Test Document Set:
d3: The sun in the sky is bright.
d4: We can see the shining sun, the bright sun.
我们正在使用文档集中的文档d1和d2来创建训练文档集的索引词汇:

这里索引词汇用E(t)表示,其中t是术语。请注意,像 “is”、"the "这样的术语被忽略了,因为它们是经常重复的停顿词,给出的信息较少。
现在,我们可以将测试文档集转换为一个向量空间,向量中的每一个术语都被索引为我们的索引词汇表。例如,向量的第一个词代表我们词汇中的 “blue”,第二个词代表 “sun”,以此类推。现在我们要使用术语-频率,这意味着不仅仅是衡量术语在我们词汇中出现的次数(E(t))。我们可以把术语频率定义为计数函数。

这里的tf(t,d)返回的是术语t在文档d中出现了多少次。
当我们把测试文档集的d3和d4表示为向量时:

#import count vectorize and tfidf vectorise
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
train = ('The sky is blue.','The sun is bright.')
test = ('The sun in the sky is bright', 'We can see the shining sun, the bright sun.')
# instantiate the vectorizer object
# use analyzer is word and stop_words is english which are responsible for remove stop words and create word vocabulary
countvectorizer = CountVectorizer(analyzer='word' , stop_words='english')
terms = countvectorizer.fit_transform(train)
term_vectors = countvectorizer.transform(test)
print("Sparse Matrix form of test data : \n")
print(term_vectors.todense())
Sparse Matrix form of test data :
[[0 1 1 1]
[0 1 0 2]]
术语频率-逆向文档频率(TFIDF)
它是TF和IDF的乘积。
TFIDF给在语料库(所有文档)中罕见的词以更大的权重。
TFIDF为在文档中更频繁出现的词提供更多的重要性。
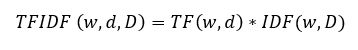
应用TFIDF后,两个文档中的文本可以表示为一个TFIDF向量,其维度等于词汇量。每个词所对应的值代表该词在特定文档中的重要性。
为什么我们在IDF公式中使用Ln?
TFIDF是TF与IDF的乘积。由于TF值介于0和1之间,不使用ln会导致一些词的IDF很高,从而主导了TFIDF。我们不希望这样,因此,我们使用ln,以便IDF不应该完全支配TFIDF。
TFIDF的缺点
它无法捕捉到语义。例如,两个同义词,TFIDF无法捕捉到这一点。此外,如果词汇量很大,TFIDF的计算成本会很高。
python实现
# TfidfVectorizer
# CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer,CountVectorizer
import pandas as pd
# set of documents
train = ['The sky is blue.','The sun is bright.']
test = ['The sun in the sky is bright', 'We can see the shining sun, the bright sun.']
# instantiate the vectorizer object
countvectorizer = CountVectorizer(analyzer= 'word', stop_words='english')
tfidfvectorizer = TfidfVectorizer(analyzer='word',stop_words= 'english')
# convert th documents into a matrix
count_wm = countvectorizer.fit_transform(train)
tfidf_wm = tfidfvectorizer.fit_transform(train)
#retrieve the terms found in the corpora
# if we take same parameters on both Classes(CountVectorizer and TfidfVectorizer) , it will give same output of get_feature_names() methods)
#count_tokens = tfidfvectorizer.get_feature_names() # no difference
count_tokens = countvectorizer.get_feature_names()
tfidf_tokens = tfidfvectorizer.get_feature_names()
df_countvect = pd.DataFrame(data = count_wm.toarray(),index = ['Doc1','Doc2'],columns = count_tokens)
df_tfidfvect = pd.DataFrame(data = tfidf_wm.toarray(),index = ['Doc1','Doc2'],columns = tfidf_tokens)
print("Count Vectorizer\n")
print(df_countvect)
print("\nTD-IDF Vectorizer\n")
print(df_tfidfvect)
输出
Count Vectorizer
blue bright sky sun
Doc1 1 0 1 0
Doc2 0 1 0 1
TD-IDF Vectorizer
blue bright sky sun
Doc1 0.707107 0.000000 0.707107 0.000000
Doc2 0.000000 0.707107 0.000000 0.707107
结论
Term Frequency - Inverse Document Frequency(TFIDF)是一种基于Bag of words(BoW)模型的文本矢量化技术。由于它考虑到了单词在文档中的重要性,因此表现得比BoW模型更好。主要的限制是它没有捕捉到单词的语义。TFIDF的这一局限性可以通过更先进的技术(如word2Vec)来克服。
reference:
[1]https://medium.com/@cmukesh8688/tf-idf-vectorizer-scikit-learn-dbc0244a911a
[2]https://towardsdatascience.com/text-vectorization-term-frequency-inverse-document-frequency-tfidf-5a3f9604da6d