FCOS (ICCV2019)
总结:
1. 相当于换了一种形式的anchor, 多层预测, 每层预测指定的尺寸, 然后使用si(也没有讲这个是怎么来的)来平衡尺寸基数.
2. 主要困难点在于目标之间overlap的处理 和 尺寸不变形问题, 可以说两者都是通过FPN处理的,
前者假设多数overlap的目标都是尺寸差距较大的, 后者通过每层限定回归范围以及设置si来平衡.
3. ICCV2019的, 整篇读下来很顺畅, 看有人要拿来做一阶段实例分割, 有点意思.
介绍
基于anchor的几个缺点:
1. faster rcnn的性能受anchor的sizes, aspect ratios 和数量影响. RetinaNet仅仅改变这些参数就使得性能提升4%.
2. 固定的比例和尺寸不利于多样的目标检测, 尤其是小目标.
3. anchor数量太多, 另外过多的anchor还会导致正负比例失衡
4.过多的anchor也增加了IOU计算时的时间和内存成本

论文方法
3.1 Fully convolutional one-stage object detector
对于每一层特征层, 有两个分支, 一个分支负责每个点的分类: C个通道(80 of COCO), 一个分支负责预测当前点距离box上下左右的距离, 对于重叠区域(如下图右面)的处理方式, 学习的目标是贪心的选择最小范围, (那么类别应该回归什么呢?? 应该是多个类别同时回归吗??)具体处理在后面会介绍.
损失函数如下:

3.2 Multi-level prediction with FPN for fcos:
FCOS网络的两个可能问题:
1. 具有较大stride的深层特征图结果有一个比较低的recall. 对于基于anchor的detectors. 可以降低判定为正anchor box需要的IoU分数来提高recall. 但是FCOS并不存在由于步幅较大而最终特征图上没有位置的对象的召回率低的问题.
2. 当存在覆盖的问题时, 对于当前特征点, 应该对哪个目标进行回归?
针对覆盖问题, 一个方法可以很大的缓解这个问题, 就是用多层预测不同大小的目标, 这里使用了5层, 只要两个覆盖的目标有较大的尺寸差异, 就可以在回归的时候只回归在指定范围内的.(作者说多数存在覆盖的目标尺寸差距也比较大, 就好比人手里拿着球拍, 存在覆盖, 但是不同层回归就没事了)
基于anchor 的方案是在不同深度的特征图分配不同大小的特征图. 这里直接限制边界框回归的范围: 显示计算在gt box内的特征点的(l, t, r, b) 只要这四个值得最大值在指定范围内, 就可以回归.
还有就是面对不同的特征层使用相同级别(exp(x))回归是不合理的,最终使用一个带有可训练的标量si对于第i层特征图, 使用exp(si * x)来调整当前层的基数, 最终改善性能.(其实这里不用anchor肯定存在尺度不变形问题, 说白了用si就是达到尺度不变性的目标)
3.3 Center-ness for FCOS
经过上面的一堆操作, 发现还是有问题, 主要是由于很多远离边界框中心点的特征点预测出了很多低质量的框. 本篇的mvp操作来了:
在分类这个分支的head再插入一个分支"center-ness", 差不多的意思就是定位在box内的点距离中心点的距离来得分, 具体计算方式如下:
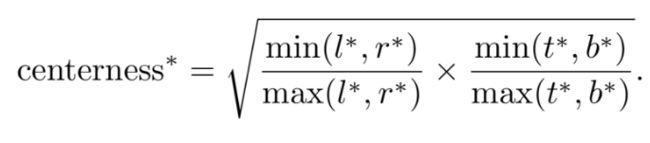
可以算出, 距离中心点越近, 这个值越接近1, 越偏越小
然后使用BCE损失函数. 把这个损失加入之前那个损失函数.
然后再推理阶段把个分数当做NMS的分数. 就可以有效排除那些远离边界框中心点的特征点的预测结果.
实验结果: