Word2Vec算法详解(相关背景介绍)
本节开始将介绍几种比较前言的NLP算法,主要是和神经网络进行结合的,和深度学习进行结合的算法原理和思想,前面的NLP算法都是传统的经典NLP算法思想,都没有涉及到实战方面的,实战方面的我计划明年开始进行,所以这个系列的都是理论,本人一直很注重理论方面的学习,因为只有搞懂算法的原理你才有可能去改进去创新,本节开始讲解目前使用比较成熟效果比较好的算法即Word2Vec算法,这个算法,和神经网络很好的结合了在一起,本节主要涉及到一些背景知识,大家需要搞懂这些背景才有可能深入理解Word2Vec算法,好,废话不多说,下面开始:
Word2Vec算法背景
Word2Vec是Google公司于2013年发布的一个开源词向量工具包。该项目的算法理论参考了Bengio在2003年设计的神经网络语言模型。由于此神经网络模型使用了两次非线性变换,网络参数很多,训练缓慢,因此不适合大语料。Mikolov团队对其做了简化,实现了Word2Vec词向量模型。它简单、高效,特别适合从大规模、超大规模的语料中获取高精度的词向量表示。因此,项目一经发布就引起了业界的广泛重视,并在多种NLP任务中获得了良好的效果,成为NLP在语义相似度计算中的重大突破。Word2Vec及同类的词向量模型都基于如下假设:衡量两个词在语义上的相似性,决定于其邻居词分布是否类似。显然这是源于认知语言学中的“距离象似性”原理:词汇与其上下文构成了一个“象”。当从语料中训练出相同或相近的两个“象”时,无论这两个“象”的中心词汇在字面上是否一致,它们在语义上都是相似的。
自从Word2Vec框架发布之后,无论是在国外还是在国内,该框架都引起了巨大的反响。由于TomasMikolov在相关的论文中并没有谈及太多的算法细节,因此对许多NLP的研究人员来说,对该算法的研究一度成为重要的课题。经过两三年的研究,到目前为止,根据发布出来的研究成果,对相关理论的研究己经非常充分,在网络上可以很容易地找到。
词向量及其表达
词的向量化就是将语言中的词进行数学化,也即把一个词表示成一个向量。词的向量化主要有以下2种表达方式。
(1)one-hot representation方式
这是一种最简单的方式,用一个很长的向量来表示一个词。向量的长度为词典的大 小(通 常 达 到 ![]() ),向 量 的 分 量只有一个1,其余全为0,1的位置对应该词在词典中的位置。比如,“土豆”表示为[0 0 0 0 0 1 0 0 0 0 0 0 0 00 … ],而 “马 铃 薯 ”表 示 为 [0 1 0 0 0 0 0 0 00 0 0 0 0 0 …]。这种方式虽然可以 简 单 明 了 地 表 达 一个词语,但是却无法有效表达它们的语义信息。“土豆”和“马铃薯”虽然是同一种食物,但利用常规的向量距离公式,比如欧几里德距离或者余弦距离公式,都无法有效计算它们的相似度,显然这种方式不能很好地表达词之间的相似性。
),向 量 的 分 量只有一个1,其余全为0,1的位置对应该词在词典中的位置。比如,“土豆”表示为[0 0 0 0 0 1 0 0 0 0 0 0 0 00 … ],而 “马 铃 薯 ”表 示 为 [0 1 0 0 0 0 0 0 00 0 0 0 0 0 …]。这种方式虽然可以 简 单 明 了 地 表 达 一个词语,但是却无法有效表达它们的语义信息。“土豆”和“马铃薯”虽然是同一种食物,但利用常规的向量距离公式,比如欧几里德距离或者余弦距离公式,都无法有效计算它们的相似度,显然这种方式不能很好地表达词之间的相似性。
(2)Distributed representation (词向量)
这种方式能很好地克服one-hot representation方式的缺点,最早由 Hinton提出,它是将词映射到一个低维、稠密的实数向量空间中(空间大小一般为100或者200),使得词义越相近的词在空间的距离越近。上面的例子可以类似地表达如下
,“土 豆”可 以 表 示 为:[0.843 -0.125 0.734 -0.3450.654 …],而“马铃薯”为[0.923 -0.231 0.698 -0.233 0.743 …],显然,这种表示方式有利于使用距离向量公式比较词向量之间的相似度。
下面我们在系统的讲解一下,在NLP任务中,我们将自然语言交给机器学习算法来处理,但机器无法直接理解人类的语言,因此首先要做的事情就是将语言数学化,如何对自然语言进行数学化呢?词向量提供了一种很好的方式.一种最简单的词向量是one-hot representation就是用一个很长的向量来表示一个词,向量的长度为词典的大小N,向量的分量只有一个1,其它全为0,1的位置对应该词在词典中的索引,但这种词向量表示有一些缺点,如容易受维数灾难的困扰,尤其是将其用于DeepLearning场景时;又如,它不能很好地刻画词与词之间的相似性,另一种词向量是Distributed Representation,它最早是Hinton于1986年提出的,可以克服one-hot representation的上述缺点,其基本想法是:通过训练将某种语言中的每一个词映射成一个固定长度的短向量(当然这里的“短"是相对于one-hot representation的“长”而言的),所有这些向量构成一个词向量空间,而每一向量则可视为该空间中的一个点,在这个空间上引人“距离",就可以根据词之间的距离来判断它们之间的(词法、语义上的)相似性了.word2vec中采用的就是这种Distributed Representation的词向量.
为什么叫做Distributed Representation?很多人问到这个问题.我的一个理解是这样的:对于one-hot representation,向量中只有一个非零分量,非常集中(有点孤注一掷的感觉);而对于Distributed Representation,向量中有大量非零分量,相对分散(有点风险平摊的感觉),把词的信息分布到各个分量中去了.这一点,跟并行计算里的分布式并行很像.为更好地理解上述思想,我们来举一个通俗的例子.
假设在二维平面上分市有a个不同的点,给定其中的某个点,现在想在平面上找到与这个点最相近的一个点.我们是怎么做的呢?首建立一个直角坐标系,基于该坐标系其上的每个点就唯一地对应一个坐标![]() .接着引入欧式距;最后分别计算这个词与其他
.接着引入欧式距;最后分别计算这个词与其他![]() 个词之间的距离,对应最小距离值的那个(或那些)词便是我们要找的词了·上面的例子中,坐标
个词之间的距离,对应最小距离值的那个(或那些)词便是我们要找的词了·上面的例子中,坐标![]() 的地位就相当于词向量,它用来将平面上一个点的位置在数学上作量化,坐标系建立好以后,要得到某个点的坐标是很容易的,然而,在NLP任务中,要得到词向量就复杂得多了,而且词向量并不唯一,其质量依赖于训练语料、训练算法等因素。
的地位就相当于词向量,它用来将平面上一个点的位置在数学上作量化,坐标系建立好以后,要得到某个点的坐标是很容易的,然而,在NLP任务中,要得到词向量就复杂得多了,而且词向量并不唯一,其质量依赖于训练语料、训练算法等因素。
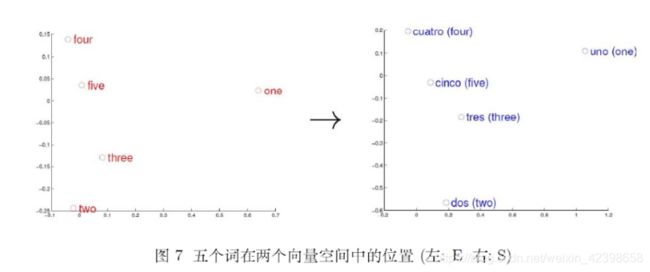
考虑英语和西班牙语两种语言,通过训练分别得到它们对应的词向量空间(Enghsh)和(Spanish).从英语中取出五个词one,two,three,four,five,设其在E中对应的词向量分别为uno,dos,tres,cuatro,cinco,为方便作图,利用主成分分析(PCA)降维,得到相应的二维向量,在二维平面上将这五个点描出来,如图7左图所示.类似地:在西班牙语中取出(与one,two,three,fo些five对应的)uno,dos,tres,cuatro,cinco,设其在S中对应的词向量分别为![]() ,用PCA降维后的二维向量分别为
,用PCA降维后的二维向量分别为![]() ,将它们在二维平面上描出来(可能还需作适当的旋转),如图7右图所示.观察左、右两幅图:容易发现:五个词在两个向量空间中的相对位置差不多,这说明两种不同语言对应向量空间的结构之间具有相似性,从而进一步说明了在词向量空间中利用距离刻画词之间相似性的合理性,注意,词向量只是针对“词”来提的,事实上,我们也可以针对更细粒度或更粗粒度来进行推广,如字向量,句子向量和文档向量,它们能为字、句子、文档等单元捍供更好的表示.
,将它们在二维平面上描出来(可能还需作适当的旋转),如图7右图所示.观察左、右两幅图:容易发现:五个词在两个向量空间中的相对位置差不多,这说明两种不同语言对应向量空间的结构之间具有相似性,从而进一步说明了在词向量空间中利用距离刻画词之间相似性的合理性,注意,词向量只是针对“词”来提的,事实上,我们也可以针对更细粒度或更粗粒度来进行推广,如字向量,句子向量和文档向量,它们能为字、句子、文档等单元捍供更好的表示.
这里就不介绍了n-gram模型了,不懂的请自行百度吧,下面直接看神经概率语言模型。
神经概率语言模型
Bengio等人在文《A neural probabilistic language model. Journal Of Machine Learning Research》(2003)中提出的一种神经概率语言模型。该模型中用到了一个重要的工具一词向量.
什么是词向量呢?简单来说就是,对词典D中的任意词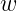 ,指定一个固定长度的实值向量
,指定一个固定长度的实值向量![]() ,
,![]() 就称为的词向量,m为词向量的长度.这里我们知道了词向量其实就是把一个词使用一个向量的实值函数去表示这个词,这样就可以计算各个词向量的欧氏距离了,这样就可以判断他们的相关性。既然是神经概率语模型,其中当然要用到一个神经网络啦.图给出了这个神经网络的结构示意图,它包括四个层:输人(Input)层、投影(Projection)层、隐藏(Hidden)层和输出(Output)层、其中
就称为的词向量,m为词向量的长度.这里我们知道了词向量其实就是把一个词使用一个向量的实值函数去表示这个词,这样就可以计算各个词向量的欧氏距离了,这样就可以判断他们的相关性。既然是神经概率语模型,其中当然要用到一个神经网络啦.图给出了这个神经网络的结构示意图,它包括四个层:输人(Input)层、投影(Projection)层、隐藏(Hidden)层和输出(Output)层、其中![]() 分别为投影层与隐藏层以及隐藏层和输出层之间的权值矩阵,
分别为投影层与隐藏层以及隐藏层和输出层之间的权值矩阵,![]() 分别为隐藏层和输出层上的偏置向量.
分别为隐藏层和输出层上的偏置向量.

对于语料C中的任意一个词w,将![]() 取为其前而的
取为其前而的![]() 个词(类似于n-gram),这样二元对
个词(类似于n-gram),这样二元对![]() 就是一个训练样本了.接下来,讨论样本
就是一个训练样本了.接下来,讨论样本![]() ,经过上图所示的神经网络时是如何参与运算的.注意,一旦语料c和词向量长度m给定后,投影层和输出层的规模就确定了,前者为
,经过上图所示的神经网络时是如何参与运算的.注意,一旦语料c和词向量长度m给定后,投影层和输出层的规模就确定了,前者为![]() ,后者为
,后者为![]() 即语料C的词汇量大小.而隐藏层的规模
即语料C的词汇量大小.而隐藏层的规模![]() 是可调参数由用户指定.
是可调参数由用户指定.
为什么投影层的规模是![]() 呢?因为输人层包含
呢?因为输人层包含![]() 中
中![]() 个词的词向量,而投影层的向量,是这样构造的:将输人层的
个词的词向量,而投影层的向量,是这样构造的:将输人层的![]() 个词向量按顺序首尾相接地拼起来形成一个长向量,其长度当然就是
个词向量按顺序首尾相接地拼起来形成一个长向量,其长度当然就是![]() 了.有了向量
了.有了向量![]() ,接下来的计算过程就很平凡了,具体为
,接下来的计算过程就很平凡了,具体为

其中tanh为双曲正切函数用来做隐藏层的激活函数,上式中,tanh作用在向量上表示它作用在向量的每一个分量上.


上式的待求参数为:
词向量:![]() ,
,![]() 以及填充向量.
以及填充向量.
神经网络参数:![]()
这些参数均通过训练算法得到.值得一提的是,通常的机器学习算法中,输人都是已知的,而在上述神经概率语言模型中,输人v(w)也需要通过训练才能得到.接下来,简要地分析一下上述模型的运算量.在如图所示的神经网络中,投影层、隐藏层和输出层的规模分别为![]() ,依次看看其中涉及的参数:
,依次看看其中涉及的参数:
(1) n是一个词的上下文中包含的词数,通常不超过5;
(2)m是词向量长度,通常是10~100量级;
(3)由用户指定,通常不需取得太大,如100量级;
(4)N是语料词汇量的大小,与语料相关,但通常是10000~100000量级.
结合上式,不难发现,整个模型的大部分计算集中在隐藏层和输出层之间的矩阵向量运算,以及输出层上的softmax归一化运算.因此后续的相关研究工作中,有很多是针对这一部分进行优化的,其中就包括了word2vec的工乍与n-gram模型相比,神经概率语言模型有什么优势呢?主要有以下两点:
1.词语之间的相似性可以通过词向量来体现
举例来说,如果某个(英语)语料中s1="A dog is running in the room”出现了10000次,而s2="A cat is running in the room”只出现了1次.按照n-gram模型的做法,![]() 肯定会远大于
肯定会远大于![]() .注意,
.注意,![]() 和
和![]() 的唯一区别在于dog和cat,而这两个词无论是句法还是语义上都扮演了相同的角色,因此,
的唯一区别在于dog和cat,而这两个词无论是句法还是语义上都扮演了相同的角色,因此,![]() 和
和![]() 应该很相近才对,然而,由神经概率语言模型算得的
应该很相近才对,然而,由神经概率语言模型算得的![]() 和
和![]() 是大致相等的.原因在于:(1)在神经概率语言模型中假定了“相似的”的词对应的词向量也是相似的;(2)概率函数关于词向量是光滑的,即词向量中的一个小变化对概率的影响也只是一个小变化.这样一来,对于下面这些句子:
是大致相等的.原因在于:(1)在神经概率语言模型中假定了“相似的”的词对应的词向量也是相似的;(2)概率函数关于词向量是光滑的,即词向量中的一个小变化对概率的影响也只是一个小变化.这样一来,对于下面这些句子:

只要语料中出现一次,其他的概率也会增大。这就把语言的相关性表现出来了。
下一节我们将介绍 Word2Vec算法。
这里参考了这篇文章《Word2Vec中的数学》,大家找到这篇文章,好好看看你会深入理解的。