【1】使用分类学习APP - Classification Learner App 训练分类模型
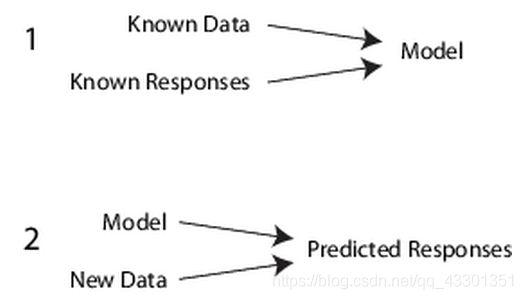
什么是有监督学习?
你可以使用分类学习器训练模型来对数据进行分类。使用这个APP时,你可以通过使用各种分类模型来探索监督机器学习。你可以浏览数据、选择特征、指定验证方案、训练模型和评估结果。你可以执行自动训练来寻找最佳的分类模型,包括决策树、判别分析、支持向量机、逻辑回归、最近邻和集成分类器等等。
通过提供一组已知的输入数据(观测量或示例值)和数据对应的已知响应(即标签或类别),来实施有监督的机器学习。使用这些数据来训练一个模型,该模型能得出对新数据的响应的预测。
若想在新数据上使用分类器,或学习编程式分类器,可以将模型导出到工作区或重新生成训练模型的MATLAB代码。
自动分类器训练
基于你的数据,你可以使用Classification Learner APP自动训练所选定的不同的分类模型。
- 从一次自动训练多个模型开始。你可以快速尝试选择模型,然后以交互地方式探索更有价值的模型。
- 如果你已经知道你想要什么类型的分类器,那就训练单个分类器。参见分类器训练手册。
1、在APP选项卡上的“数学、统计和优化”组中,单击“分类学习系统”。
2、单击“新建会话”,然后从工作区或文件中选择数据。指定一个响应变量以用作预测变量。请参见“分类问题中的选择数据和验证”。
3、在“分类学习系统”选项卡的“模型类型”区域中,单击“所有快速训练”。此选项将训练所有可用于数据集的预设模型,以实现快速训练。

4、点击“训练”。
将在“历史记录”列表中显示所选模型的类型。当完成训练时,最佳准确率分数会在一个框中突出显示。

5、单击“历史记录”列表中的“模型”以查看绘图中的结果。有关下一步,请参见“手动分类器训练”或“比较和改进分类模型”。
6、要尝试所有可用于数据集的分类器预设模型,请单击“全部”,然后单击“训练”。

人工分类器训练
如果你想探索单个模型类型,或者如果你已经知道你想要什么分类器类型,你可以一次训练一个分类器,或者训练一组相同类型的分类器。
1、选择分类器。在“分类学习系统”选项卡上的“模型类型”区域中,单击分类器类型。要查看所有可用的分类器选项,请单击模型类型部分最右侧的箭头以展开分类器列表。

模型类型库中的选项是具有不同设置的预设起点,适用于一系列不同的分类问题。要阅读每个分类器的描述,请切换到details视图。
有关每个选项的详细信息,请参见选择分类器选项。
2、选择分类器后,单击Train。
重复以上步骤,尝试使用不同的分类器。
3、如果决定要尝试所有模型类型或训练同一类型的组,请尝试模型类型库中的所有选项。
有关下一步,请参见“比较和改进分类模型”。
并行分类器训练
如果您有并行计算工具箱,您可以使用Classification Learner并行地训练模型。训练分类器时,应用程序会自动启动并行工作池,除非关闭默认的并行首选项,否则会自动创建并行池。如果一个工作池已经打开,应用程序将使用它进行训练。并行训练允许你一次训练多个分类器并连续工作。
1、第一次单击Train时,当应用程序打开一个并行的工作池,你会看到一个对话框。池打开后,可以一次训练多个分类器。
2、当分类器并行训练时,你可以在“历史记录”列表中看到每个模型及其正在排队的进度指示,如果需要,你也可以随时取消某个模型。在训练期间,你可以检查模型的结果和绘图,并启动更多的分类器以用于训练。

要控制并行训练,请切换应用程序中toolstrip中的“使用并行”按钮。只有当你有并行计算工具箱时,“使用并行”按钮才可用。

如果你有并行计算工具箱,那么在Classification Learner中可以使用并行训练,并且你不需要设置statset函数的UseParallel选项。如果关闭“并行”首选项以实现自动创建并行池,则应用程序将不会在未事先询问的情况下为你启动并行池。
比较和改进分类模型
1、单击“历史记录”列表中的“模型”以查看绘图中的结果。通过散点图和混淆矩阵中的检查结果来比较模型性能。检查在历史记录表中的每个模型的准确度(百分比格式)。参见Assess Classifier Performance in Classification Learner.
2、在“历史记录”列表中选择最佳模型,然后尝试在模型中包含和排除不同的特征。单击“要素选择”。
尝试使用平行坐标图来帮助您识别要删除的特征。看看是否可以通过删除预测能力低的功能来改进模型。指定要包含在模型中的预测值,并使用新选项训练新模型。比较历史记录列表中的模型之间的结果。你也可以尝试用PCA变换特征来降低维数。
参见See Feature Selection and Feature Transformation Using Classification Learner App.
个人笔记:
针对“平行坐标图”的使用方法,这里我使用MATLAB自带的鸢尾花数据集进行了尝试,
load fisheriris
T=array2table(meas);
T.species=species;
打开Classification Learner App,选择表T为要训练的数据集,Model Type选All,点“训练”,最高的模型准确度达到98%,见下图

打开“parallel coordinates plot”,

观察发现meas3和meas4两个特征变量在纵向坐标轴上对三种类别的区分度较好,因此下一步将meas1和meas2去掉进行重新训练。
选择“Feature Selection”,去掉meas1和meas2,再次选择所有模型,点击“训练”,

这时候最高的准确度为96%。说明去掉meas1和meas2,模型的精度有一定的下降,但不是特别明显。
3、要进一步改进模型,可以尝试在“高级”对话框中更改分类器参数设置,然后使用新选项进行训练。要了解如何控制模型灵活性,请参见Choose Classifier Options.
4、如果特征选择、PCA或新的参数设置改善了模型,请尝试使用新设置训练所有模型类型。查看其他类型的模型使用新设置是否也能表现出更好的性能。
下图显示了该app中包含了各种类型分类器的训练历史记录列表。
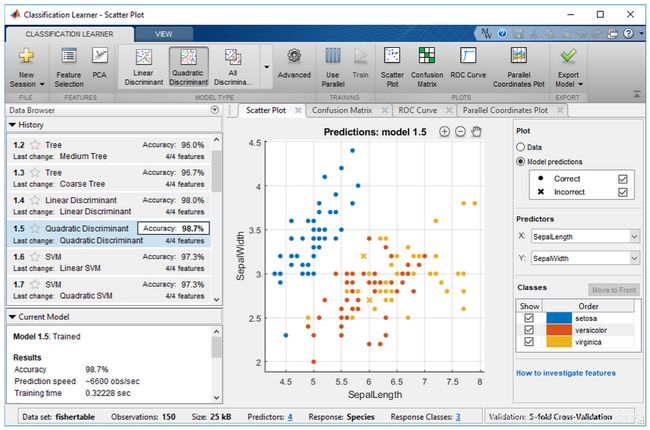
下一步工作则是,生成代码以使用不同的数据训练模型,或者将训练过的模型导出到工作区以使用新数据进行预测。请参见 Export Classification Model to Predict New Data.