pycharm不认识numpy?_深度学习(CV方向)入坑不完全指南
前言:这篇文章算是我研究生期间在深度学习这块摸爬滚打收获到的一点皮毛之见。对于刚刚接触这一块,尤其是计算机视觉这块的萌新而言,或许有一定的参考价值。因为这篇文章算是对一些基础知识点的汇总,主要目的在于建立一套完整的知识体系,对具体某个知识点不会做太多深入的讲解。因此对于某个具体知识点不了解的童鞋,不妨充分发挥自己的主观能动性,充分利用互联网来学习相关知识点~
01.
框架选择:Pytorch
从易用性上来看,Pytorch要比TensorFlow好不少。如果是设计到工程落地,或许应该选择TensorFlow。但是至少在学术界,已经有越来越多的研究使用Pytorch来实现模型。个人还是比较推荐用Pytorch作为入门框架。
02.
Pytorch环境配置
既然要使用Pytorch作为深度学习框架,那么电脑或者服务器上就必须安装好Pytorch以及相应的配件。具体怎么安装,在网上搜索“Pytorch环境配置”就会有不少教程,因此这里就不重复罗嗦了。不过总的来说,安装大体分为这几个环节:1.安装显卡驱动、cuda以及cudnn→2.安装Anaconda→3.利用conda安装Pytorch→4.安装opencv等相关库。
此外,还需要注意是在Window系统还是Linux系统下安装。因为二者安装的过程会略有区别。
03.
远程连接服务器
如果我们是用个人电脑来写代码跑程序,那么这一步可以跳过。但往往我们在实验室或者公司,都是使用服务器来跑程序的。这就不得不提到两款软件:Xshell和WinSCP。
Xshell可以以终端的形式连接服务器,并通过命令行在服务器上完成各种操作。对于之前一直使用Window图形界面操作系统的童靴,也需要适应一下用命令行的形式来操作系统。
图片来源:
http://mmbiz.qpic.cn/mmbiz_png/JibUibkrNSbX3NlzgZJGyYZgU9cqgbvh1VnRMib60uJuJNc0AxlD1jPlnU264iblicG1qa5QuoAv6rsUWWw4ENFSKaQ/0?wx_fmt=pngWinSCP的主要功能是完成本地与服务器的文件互传。
图片来源:http://mmbiz.qpic.cn/mmbiz_png/JibUibkrNSbX3NlzgZJGyYZgU9cqgbvh1VxUngh9RpKJlTgQOjGphmLibDSt5icFMY0xibQSWgOnFa0drou6WHmyPiaQ/0?wx_fmt=png
04.
开发环境
所谓开发环境就是指我们写代码、运行和调试代码的地方。通常我所采用的开发环境主要有终端+Vim、jupyter和Pycharm三种。它们各有利弊,可以根据不同场景选择最适合的开发环境。
1.终端+Vim。这种组合主要针对Linux系统。采用这种组合的好处是,你不需要装什么额外的东西,只要系统里装了Vim就可以写代码,然后用终端命令来运行代码,甚至可以写shell脚本来一次性运行多个文件。而且如果能熟练使用Vim编辑器的话,可以做到手不离键盘,代码敲到飞起~当然了终端+Vim在刚开始用的时候很不顺手,而且如果不进行额外配置的话不方便代码调试,因此比较适合有一定基础的童靴。
2.jupyter notebook。jupyter notebook是最适合新手入门的开发环境。它界面简洁,操作方便,可以做到写一段代码运行一段,结果可视化非常方便,而且和markdown完美结合。
图片来源:
http://mmbiz.qpic.cn/mmbiz_png/JibUibkrNSbX3NlzgZJGyYZgU9cqgbvh1VwoibF2lsAPjAT01n29PibJFtV8qLRHDfgGtIum895yWxSmA1JqbMcvqw/0?wx_fmt=png
3.Pycharm。用Pycharm最大的好处在于它强大的代码调试功能。当遇到要运行别人写好的一个比较复杂的项目文件的时候,这一点是尤为关键的。因为在这样一个比较复杂的情况下,通过debug工具来调试代码,比自己吭哧吭哧啃代码然后纯人工去debug,效率要高得多的多(别问我是怎么知道的T_T)
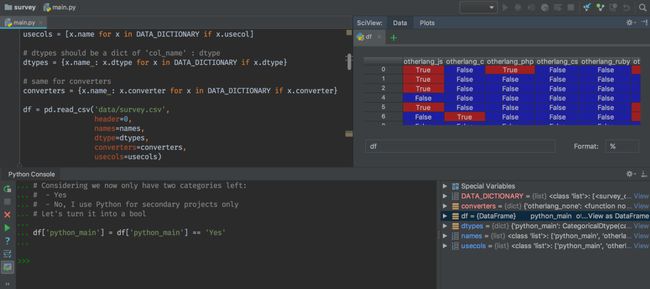
05.
需要熟练使用的库和包
1.Pytorch相关的包(深度学习),包括torch、torchvision、tensorboardX等。下图对一些常用的包进行了分类总结。
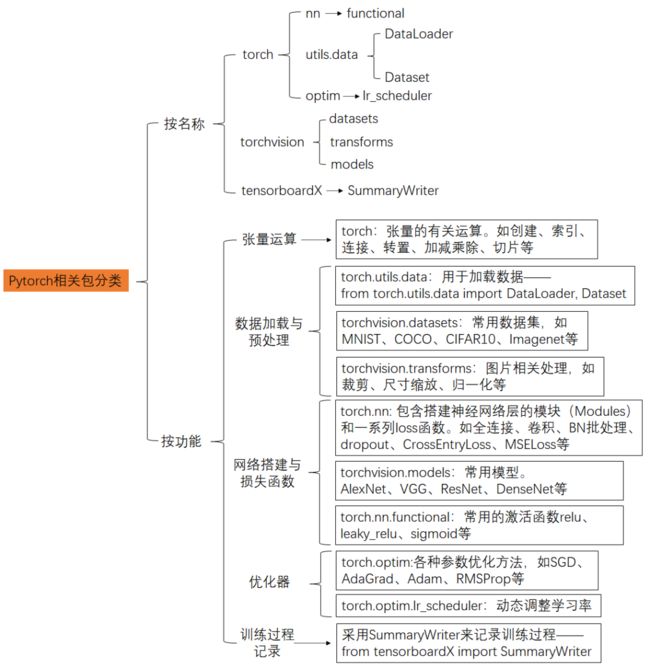
该部分在整理的过程中参考了如下资料:
1. Pytorch常用包:https://blog.csdn.net/qq_43270479/article/details/104077232
2.PyTorch系列 (一): pytorch使用总览:https://likewind.top/2019/01/17/Pytorch-introduction/
3.(第一篇)pytorch数据预处理三剑客之——Dataset,DataLoader,Transform:https://blog.csdn.net/qq_27825451/article/details/96130126
4.torchvision的理解和学习(翻译torchvision在pypi上的文档):
https://blog.csdn.net/tsq292978891/article/details/79403617
2.其他相关库:
2.1.Numpy(矩阵操作)。因为图像在计算机中就是以矩阵的形式存在,所以图像处理会涉及很多矩阵操作,如矩阵生成、转换、运算、拼接、转置、维度扩张等等。
2.2.OpenCV(图像处理)。这是一个跨平台的计算机视觉库,内包含图片读取、二值化、颜色通道转换等函数,以及各种传统图像处理算法。
2.3.matplotlib(结果可视化)。其实使用OpenCV也能对一些结果进行显示,但有时在服务器上,用OpenCV来显示结果不是很方便。因此我们通常用matplotlib来对结果进行可视化,尤其是使用jupyter作为开发环境时。它包括显示图片,绘制直方图、散点图,创建子图等功能。
2.4.sklearn(机器学习库)。在划分训练集与测试集,以及计算一些性能指标,如准确率、召回率、混淆矩阵、ROC时会用到。
06.
卷积神经网络:原理与实现
因为计算机视觉任务中,最常用的网络是卷积神经网络(Convolutional Neural Network),因此需要掌握关于它的一些基本概念,如卷积操作的定义、卷积网络的组成单元(卷积层、激活层、池化层)、感受野等等。
掌握了这些基本原理后,接下来,很多入门教程里会提到如何手动搭建一个神经网络,或者用一个公开的数据集来跑一个已有的模型。当然了,这样学也能够有所收获,但我觉得最锻炼人的,还是用自定义的数据集去训练和测试一个网络,例如我当时学分类网络的时候,就用爬虫在网上爬了猫、狗、猪的图片各500张,然后做三分类。因为用公开的数据集,格式都是固定好的,按照教程上的步骤来,基本不会出什么错。但如果是用自定义的数据集,便很有可能会遇到各种各样的问题,尤其是在数据加载这一环节。数据加载环节是新手跑代码时报错的重灾区。基本上只要正确地将数据用DataLoader加载了,后面基本不会有什么问题。
在前期,我们并不需要对模型做多大改进,因此这地方的代码相对来所不会有什么变动。但是,由于我们实际训练的数据是多种多样的,因此就需要我们彻底掌握数据的结构和格式,灵活编写代码,使得我们的数据集能够被正确地预处理、加载并送入网络进行学习。
这一环节常出现的问题包括:数据导入时的路径不正确、图片格式问题(注意每个环节图片被要求是什么格式,如PIL格式、numpy格式、tensor格式,以及它实际是什么格式;注意图片是以灰度图被读取的还是彩色图,如果是灰度图,它有三维还是两维,如果彩色图,它是RGB格式还是RGBA格式;图片的尺寸是否满足网络要求;宽和高有没有弄反;送入网络前输入的张量是否满足NCHW顺序[5]?、标签格式问题(标签是一个数还是mask;是数的话,数的格式是int还是float还是str;是否为独热编码形式)。
之后,就是掌握一些经典网络的使用,如:
分类模型:VGG,ResNet,Inception等
检测模型:RCNN系列和YOLO系列
分割模型:U-net,FCN,mask-rcnn, deeplabv3
GAN模型:GAN,cGAN,WGAN,info-GAN,CycleGAN
参考资料:
5.NCHW与NHWC的区别:
https://www.jianshu.com/p/d8a699745529
07.
创建自己的Project
当我们按部就班地一路学下来,也跑了不少别人的Project后,我们也要开始学会自己写代码,创建自己的Project。下图给出了一个比较典型的Project的基本组成结构。其中加粗的表示文件夹。当然不是说非得用这个结构来写代码,只是我比较习惯这样的组织逻辑。
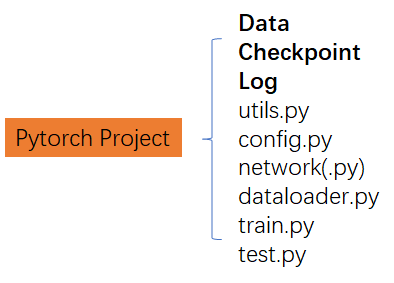
Data文件夹用于保存数据;Checkpoint文件夹用于保存训练过程中的权重文件;Log文件夹用于存放训练日志,如Loss和准确率变化曲线等等;utils.py用于定义一些自定义的子函数,具体内容因项目而异;config.py用于一些参数设置,如数据读入路径、学习率大小、迭代步长等等。
network(.py)用于定义网络结构。之所以加括号是因为network有时候是一个文件夹(或者说包),因为在网络结构比较复杂的时候,我们采用多个py文件(或者叫模块)对网络进行嵌套定义会更加方便。下图是一个Net类的基本结构。

更加详细的网络搭建方法可以参考如下博客:
6.pytorch学习:构建网络模型的几种方法
https://www.cnblogs.com/denny402/p/7593301.html
在网络搭建完成后,可以简单地测试一下自己搭的网络有没有问题。我一般会采用如下代码来测试。如果能跑通且输出与预期一致,则至少中间层的输入输出的格式是对上的:

除了自己搭网络,也可以使用torchvision.models中已有的网络模型,或者在这些已有模型的基础上进行适当修改。
dataloader.py用于定义数据加载与预处理相关的变量。其中Dataset子类定义了数据集读取的方式;Dataloader则是将实例化后的Dataset子类包装成一个可迭代的对象,用大白话说就是将单个单个的样本打包成一个个的batch,在后续的训练环节通过迭代,源源不断地输入网络进行训练。而transforms用于定义数据增强的方式。
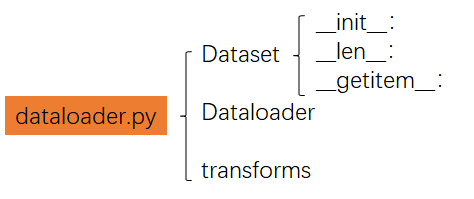
关于Dataset,DataLoader,Transform具体的写法,可以参考如下两篇文章:
7.(第一篇)pytorch数据预处理三剑客之——Dataset,DataLoader,Transform:
https://blog.csdn.net/qq_27825451/article/details/96130126
8.PyTorch 学习笔记(三):transforms的二十二个方法:
https://blog.csdn.net/u011995719/article/details/85107009
前文说到,数据加载环节是一个很重要的环节。因此在完成数据加载后,可以对dataloader中的数据进行可视化,检查数据是否被正确地加载。下面是我在实践时用到的一段测试代码。
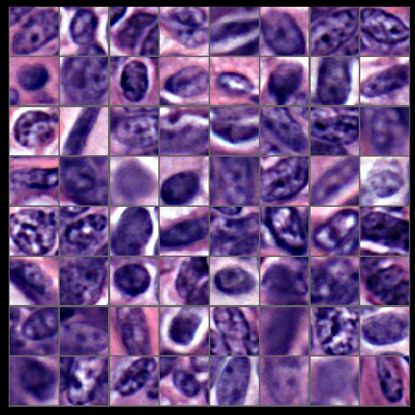
下图是代码运行的结果。简单说明一下,这段代码的功能是迭代一次dataloader,然后将迭代得到的batch中的图片显示出来,且每行显示8个样本。我的数据的batch size为64,所以这里一共显示了8行数据。
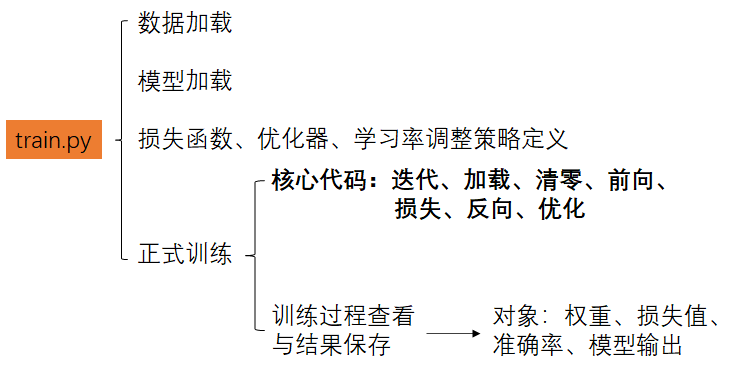
train.py文件,顾名思义,就是模型训练的代码。而它大抵又可分为1.数据加载,2.模型加载,3.损失函数、优化器、学习率调整策略定义,4.正式训练四个环节,如下图所示。
在正式训练环节,它的核心代码我总结为七个短语:迭代、加载、清零、前向、损失、反向、优化。下面贴一段代码来更好地说明这七个词语。
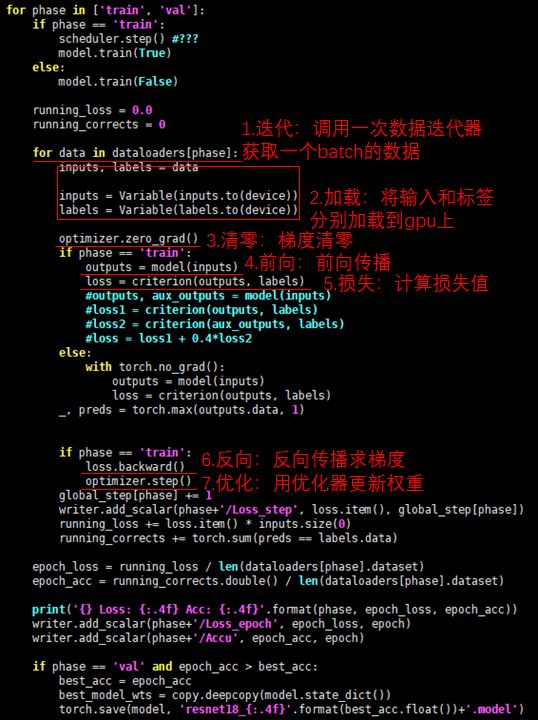
不管训练代码如何繁杂,这几句代码是必不可少的。而其余代码的主要功能,则是训练过程查看与结果保存,而查看和保存的对象通常为权重、损失值、准确率与模型输出。值得一提的是,我们通常采用一个叫TensorBoard的工具来对训练过程进行监控。TensorBoard的使用可参考如下资料:
9.学习笔记|Pytorch使用教程20(TensorBoard使用(一)):
https://blog.csdn.net/qq_24739717/article/details/103068009
test.py是对模型进行测试的代码。对比train.py而言,test.py中没有反向传播的过程,而且会多一些性能指标测试以及测试结果输出的环节。
08.
模型调优与改进
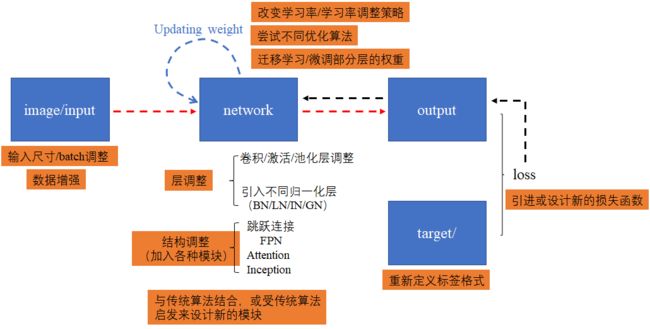
当我们跑通模型后,下一步想的通常是如何让模型输出的效果更好。如果不对模型本身做出改变,只是对一些超参数进行调整,让模型训练处一组更优的参数,那这就叫调参。当调参已经不能满足我们的需求时,就需要对输入的数据做进一步处理(如扩大样本量、数据清洗、数据增强等),或者对模型、损失函数进行改进。下图结合了模型的训练过程来说明我们可以在哪些方面对模型进行调优和改进。其中红色箭头代表前向传播的过程,黑色箭头代表反向传播的过程,蓝色箭头代表对模型权重进行更新,橙色背景的文字代表可以改进的点。
最后,送上全文的思维导图:
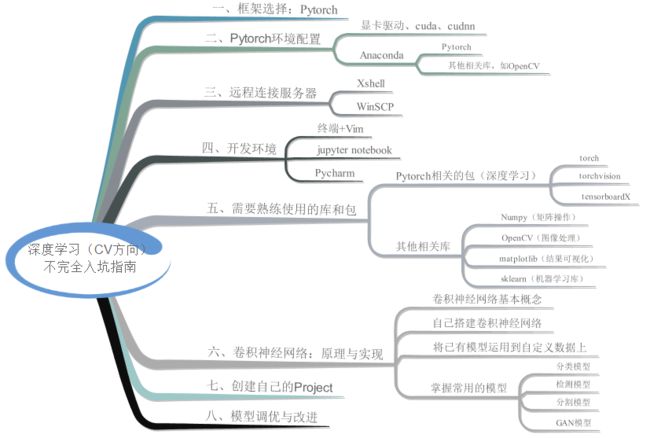
PS:其实在整理的过程中,也意外发现了一些我原来不知道的知识。比如torchvision里就自带了很多预训练好的模型,比如预训练的Faster R-CNN、Mask R-CNN以及Keypoint R-CNN等[10],再比如DataLoader中有定义不同的随机采样机制[11]。所以及时的输出整理还是很有好处的。最后,限于笔者水平,本文在很多方面都写得不够全面和深入,甚至有错误的地方。如有发现,恳请斧正,不胜感激。
10.视觉工具包torchvision重大更新:支持分割模型、检测模型,还有许多数据集:https://www.qbitai.com/2019/05/2638.html
11.(第一篇)pytorch数据预处理三剑客之——Dataset,DataLoader,Transform:
https://blog.csdn.net/qq_27825451/article/details/96130126
作者简介:617,清华SIGS生物医学工程专业博士在读,研究方向为数字病理图像智能分析。
原创不易,转载请声明出处。