语音识别(Speech Recognition)综述
文章目录
- 1. 语音识别的基本单位
-
- 1.1 Phoneme(音位,音素)
- 1.2 Grapheme(字位)
- 1.3 Word(词)
- 1.4 Morpheme(词素)
- 1.5 bytes
- 2. 获取语音特征(Acoustic Feature)
- 2. 语音识别的网络结构
- 3. 语音识别模型
-
- 3.1 LAS(Listen, Attend, and Spell)
-
- 1. down sampling(下采样)
- 2. Beam search
- 3. LAS 中的 Attention
- 4. Location-aware attention
- 5. LAS 训练过程
-
- teacher forcing
- 6. LAS的局限
- 3.2 CTC(Connectionist Temporal Classification)
- 3.3 RNN-T(RNN Transducer)
- 3.4 Neural Transducer
- 3.4 (MoCha)Monotonic Chunkwise Attention
- 3.5 几种seq2seq语音识别模型的区别
1. 语音识别的基本单位
1.1 Phoneme(音位,音素)
a unit of sound 是声音的最基本单位,每个词语token的声音由多个 phoneme 组成
1.2 Grapheme(字位)
smallest unot of a writing system 每个单词书写最基本的单位,简单来说:
英文的grapheme可以认为是词缀, 由 [26个英文字母 + 空格 + 标点符号]组成
中文的grapheme是汉字
1.3 Word(词)
英文可以用单词作为语音识别的最基本单位,但包括中文在内的很多语言无法使用word作为最基本的单位(word数量太过于庞大,word之间难于分隔等)
1.4 Morpheme(词素)
the smallest meaningful unit 类似英文单词中词缀
1.5 bytes
用byte的序列来表示计算机中的每个字符(比如使用utf-8对字符编码),用用byte作为语音识别的基本单位可以让是识别系统将不同的语言统一处理,和语言本身无关,英文上叫 The system can be language independent
2. 获取语音特征(Acoustic Feature)
获取语音特征的方法从难到易依次是:
waveform -> spectrogram -> filter bank output -> MFCC

2. 语音识别的网络结构
语音识别的结构一般可以分为两种,一种是直接输出 word embedding(feature base);一种将语音识别模型和和其他模型相组合的end2end结构,如:speech recognition + 翻译模型、speech recognition + 分类模型、speech recognition + Slot filling模型,这里主要分析这一种类型
3. 语音识别模型
主流的语音模型总体上可以分为seq2seq结构和HMM结构,而seq2seq结构有LAS、CTC、RNN-T、Neural Transducer、MoChA等
3.1 LAS(Listen, Attend, and Spell)
LAS网络是一个 seq2seq的结构(encoder-decoder),其中:
- Listen(encoder) 部分可以使用多种网络结构,主要作用是进行注意力机制和过滤噪声等工作,encoder可以是CNN、LSTM、BILSTM、CNN+RNN、Self-Attention或多层上述的组合结构等
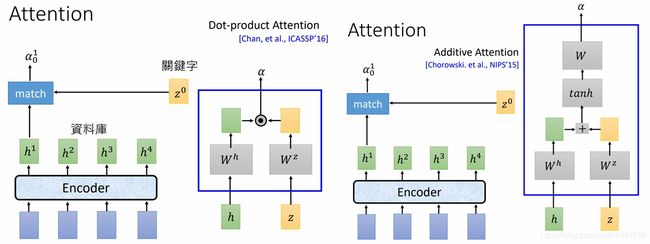
- Attend 就是一般的Attention结构,由encoder的输出和decoder(RNN)上一时刻的输入变换后经过点乘或相加得到,如下图所示
- Spell(decoder )一般是RNN(LSTM)结构,这部分可以认为是模型中的 Language Model,因此LAS可以不在模型之后添加其他的Language Model,但是后再在接一个Language Model 会得到更好的效果
注意:Attend中的 Attention 和 encoder 中的 Self-Attention 没有关系:
- encoder 中的 Self-Attention 用来对输入数据去噪同时提取有效数据
- Attend 中的 Attention 用来得到当前时刻encoder和decoder之间的语义向量(content vector)
LAS过程:
- encoder端将输入数据转化为高维隐层嵌入
- Attention过程:将 decoder上一时刻的输出和 encoder 的每个输出分别做 match 得到每个encoder输出的权重参数 a i a_i ai ,然后对 a i a_i ai 进行softmax,最后将 a i a_i ai 作为权重对 h i h_i hi 进行加权求和得到语义变量 c i c_i ci
- 将 c i c_i ci 作为decoder(RNN)当前时刻的输入传入decoder,并将decoder结果作为LAS当前时刻的输出返回

在 LAS 中,常用以下技术来优化模型性能
1. down sampling(下采样)
因为语音识别的数据量很大,因此在LAS的 encoder 内往往需要对数据进行下采样的操作,从而降低数据维度,在RNN中,一般使用如下两种方式进行下采样:
- 合并第一个RNN的输出(两个和并为1个)然后传入第二个RNN
- 在第一个RNN的输出中选择部分输出传入第二个RNN

对于TCNN,可以使用上左图的方式进行下采样操作:
一般的TCNN网络会读取整个范围内所有序列的数据,但是为了减少数据量,我们可以只输入序列的开始和结束的 embedding
对于 Self-Attention,为了减少数据量,我们可以只对一定范围内的序列数据进行 attention,如上右图所示,对于输入 x 3 x_3 x3,只对其周围的 x 2 x_2 x2 和 x 4 x_4 x4 进行 Attention
2. Beam search
下边使用一个例子来说明 Beam search 的过程
假如 token 的个数为2,分别为A和B,同时序列长度为3,我们可以使用下图来展示语音识别的整个过程:
对于第一个token,识别为A的概率是0.6,B的概率是0.4,我们将三个token识别出来的所有可能展示出来就如下图所示;如果每次我们都选择概率最大的token,我们会得到红色路径代表的结果,但是如果我们第一次没有选择概率最大的A,而是选择了B,那么我们会得到绿线代表的结果,我们发现绿线的结果反而更好;因此我们可以同时选择多条路线同时预测,最后选择效果最好的结果返回,其实这就是 beam search的思想,其中 beam size 就代表同时进行的路线数量

3. LAS 中的 Attention
LAS中的Attention可以有两种形式:
-
一种是上文提到的,将decoder的当前时刻隐含层数据 z t z^t zt在encoder的输出 h i h^i hi上做Attention,并将此生成的语义变量 c t c^t ct作为下一时刻decoder(RNN)的输入;
-
一种是将decoder的当前时刻隐含层 z t z^t zt和在encoder的输出上做Attention,并将此生成的语义变量和当前时刻的隐含层 z t z^t zt作为当前时刻decoder(RNN)的输入放入RNN中
这两种注意力的区别在,注意力得到的结果是下一个时间使用还是当前时间使用。第一篇拿Seq2Seq做语音识别的论文,用的是二者的合体版本。

4. Location-aware attention
Location-aware attention 在计算每个 h i h^i hi的权重时, 不仅考虑 z i z^i zi和 h i h^i hi,同时将上一时刻得到的部分权重;之所以是部分权重是因为只考虑上一时刻 h i h^i hi邻域内的权重,具体实现方式可以参考下图

5. LAS 训练过程
我们用 one-hot 编码来表示每个token, 同时计算模型输出和正确token one-hot编码的交叉熵,使模型输出的结果逐步接近正确token的one-hot编码,如下图所示:

teacher forcing
但是,有一点需要注意,在decoder端,我们并不会将上一时刻的输出作为当前时刻的输入,而是将上一时刻正确的token作为当前时刻输入,
如下图所示,当我们要预测cat中的a时,我们并关心上一时刻(第一个token)得到什么结果,而是直接将上一时刻的正确结果 c 作为当前时刻decoder的输入 这个训练方式叫做 teacher forcing

6. LAS的局限
由于LAS是seq2seq结构,而seq2seq结构需要将整个输入序列编码成一个语义向量,要得到整个输入序列之后才能开始输出第一个token,因此无法实现在线学习,或者说是在线语音识别
3.2 CTC(Connectionist Temporal Classification)
和LAS相比,CTC能够实现实时识别的功能,CTC模型的基本结构如下图所示:

首先,模型先通过一个encoder结构将输入的token转化为一个高维隐层嵌入,然后对于每一个token的输出使用一个分类器(全连接网络)进行分类,最终的到每个token对应的预测结果;虽然CTC网络没有Attention机制,但encoder往往使用LSTM网络,从而每个token也能够得到上下文的信息;CTC会遇到如下两个问题:因为 CTC模型的输入是音位,因此多个相邻的token可能出现重复或者某个token的输出为空的情况:
- 当某个token没有合适的输出时,我们输出 ∅ ∅ ∅,并在最后将输出结果中的 ∅ ∅ ∅符号删除;
- 当多个相邻token对应的输出重复时,我们会在最后将多个重复的输出结果合并
同样因为 CTC模型的输入是音位,因此我们无法准确的到每个序列对应的标签,以下边的例子为例,同样对于好棒这个语音的音位序列,他的标签可以是下边标签的任意一个,问题是我们要用哪一个做为这个语音序列的标签呢?CTC其实是用到了下边的所有标签,原理这里暂且不做讲解

3.3 RNN-T(RNN Transducer)
在认识 RNN-T之前,首先要认识一下RNA(Recurrent Neural Aligner)网络;前边我们了解了CTC网络,RNA网络就是将CTC中encoder后的多个分类器换成了一个RNN网络,使网络能够参考序列上下文信息
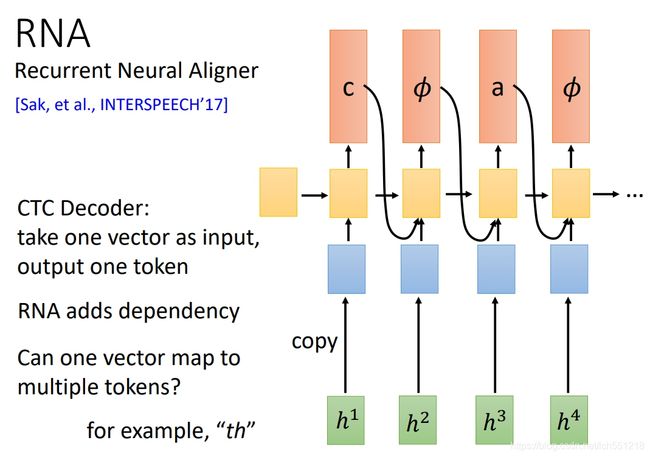
RNN-T 网络在RNA网络的基础上使每个输入token可以连续输出多个结果,当每个token输出符号 ∅ ∅ ∅ 时,RNN网络再开始接受下一个 token,具体过程如下图所示:

其实,在RNN-T中,RNN网络的的输出并不是简单的将上一时刻的输出作为当然时刻的一个输入,而是将上一时刻的输出放入一个额外的RNN中,然后将额外RNN的输出作为当前时刻的一个输入;这个额外的RNN可以认为是一个语言模型,可以单独在语料库上进行训练,因为在一般的语料库上并不包含 ∅ ∅ ∅ 符号,因此这个额外的RNN网络在训练时会忽略符号 ∅ ∅ ∅

3.4 Neural Transducer
和RNA、CTC、RNN-T不同,Neural Transducer 每次接受多个输入,并对这些输入做Attention,然后得到多个输出的语音识别模型;
和 LAS 对整个输入序列做 Attenton不同,Neural Transducer只对窗口内的多个输入做attention
Neural Transducer 模型结构如下图所示:

Neural Transducer 中 Attention 的实现方式在网上没有找到明确的说明,这里以后做补充
3.4 (MoCha)Monotonic Chunkwise Attention
MoCha 是一个窗口可变的语音识别模型,和 Neural Transducer 最大的区别是MoCha每次得到的窗口大小可以动态变化,每次的窗口大小是模型学习的一个参数;同时因为MoCha的窗口动态可变,因此MoCha的decoder端每次只输出一个token,MoCha模型结构如下图所示:

3.5 几种seq2seq语音识别模型的区别

| 模型 | Attention | 输入 | 输出 | 编码器 | 解码器 | 是否支持实时识别 |
|---|---|---|---|---|---|---|
| LAS | 对整个序列 Attention | 每次输入整个序列 | 每次输出一个Token | CNN、RNN、Self-Attention等 | LSTM | 否 |
| CTC | 无 | 单个Token | 每个分类器输出一个Token | 单向LSTM | 每个token对应一个独立的分类器 | 是 |
| RNA | 无 | 单个Token | 单个Token | 单向LSTM | LSTM | 是 |
| RNN-T | 无 | 单个token | 多个Token | 单向LSTM | 两个LSTM | 是 |
| Neural Transducer | 对同一窗口内的token做Attention | 多个Token(窗口大小固定) | 多个token | 单向LSTM | 两个LSTM | 是 |
| MoCha | 对同一窗口内的token做Attention | 多个Token(窗口大小动态) | 单向LSTM | 一个窗口输出一个Token | 两个LSTM | 是 |
下一篇文章将介绍 HMM+GMM 语音识别模型的基本原理->#透彻理解# GMM+HMM 语音识别模型过程