图文实录|UIE:基于统一结构生成的通用信息抽取
第二期澜舟分享会在 8 月 20 日圆满落幕,本期主题为《金融 NLP 场景下,大模型技术应用趋势》,我们邀请到来自中科院软件所中文信息处理实验室研究员韩先培分享演讲“UIE:基于统一结构生成的通用信息抽取”。
错过直播的小伙伴可以通过 B 站“澜舟孟子开源社区”、微信视频号“澜舟科技”观看回放视频。另外,大家可以关注「澜舟科技」公众号,在后台回复关键词“0820”获取 PPT 资料。
本文根据中科院软件所中文信息处理实验室研究员韩先培在「澜舟 NLP 分享会」上的演讲整理。
背景
信息抽取,目的在于从各种信息源中抽取知识,并将其集成到现有的结构化知识库中。通常我们抽取的知识类别包含三种:实体、关系与事件。实体包括人名、地名、机构名等;关系包含如 CEO 的关系、亲子关系、部分整体关系等;事件通常与我们关心的事件有关,例如总统的选举、会议和恐怖袭击等。
信息抽取的难点
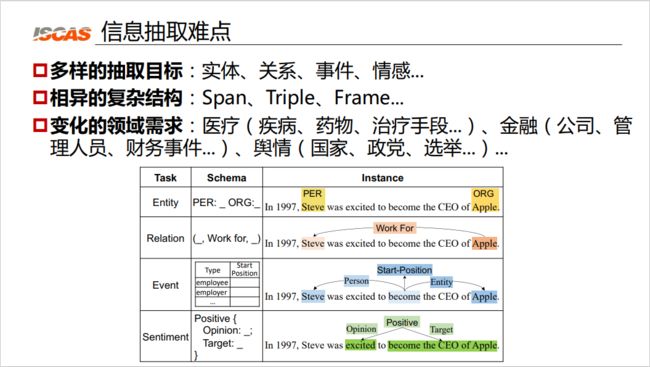
图 1:信息抽取难点
信息抽取的难点包括多样的抽取目标、相异的复杂结构与变化的领域需求等。
首先,与传统的 NLP 任务不一样,信息抽取的目标是非常多样的。我们可能需要抽取实体、关系、事件、情感等等。第二,信息抽取的目标具有复杂结构,如图 1 下方表格所示,第一行的实体是 Span 结构,即字符串结构,而关系是三元组的结构。在第二个例子中,关系是一个 Work-For 的关系,它表达的是 Steven 乔布斯和 Apple 之间的 Work-For 的关系。第三个例子就是一个复杂的框架结构。第三个难点是其变化的领域需求。例如,如果要抽取医疗领域的知识,通常抽取的对象是疾病、药物、治疗手段等。如果要做金融领域的相关应用,抽取的对象是公司、管理人员、财务事件等。如果要做舆情相关的应用,抽取的对象又会不同,需要抽取国家、政党和选举等。
信息抽取现状
首先,根据任务不同,会有任务特定的架构。例如,如果做命名实体识别,会使用序列标注模型。如果做关系抽取,会使用关系分类等模型。这就导致,要做信息抽取模型,就需要有专业人士进行调优,根据情况选择序列标注模型、 span 的分类模型或者阅读理解模型等。
第二,由于信息抽取任务的独立性,我们会训练非常多相互独立的模型。不同任务的信息抽取模型被单个训练,相互之间没有共享。最后导致的结果是一个公司可能需要管理成百上千个信息抽取的模型。
最后,信息抽取需要极高的构建成本。正如前文所说,做不同领域需求,需要训练不同的信息抽取模型,还需要专家设计特定的 schema 并构建训练的资源,如标注语料、收集词典等。
总的来说,多样的抽取任务,各种各样的监督信号,各种各样的模型架构和各种各样不同的知识领域,导致信息抽取目前的现状是:信息抽取是一个具有复杂架构,具有爆炸模型,成本还极高的过程。
信息抽取研究目标:Universal IE
针对上述问题,我们希望构建一个通用的信息抽取模型。因此,我们有以下三个研究目标:
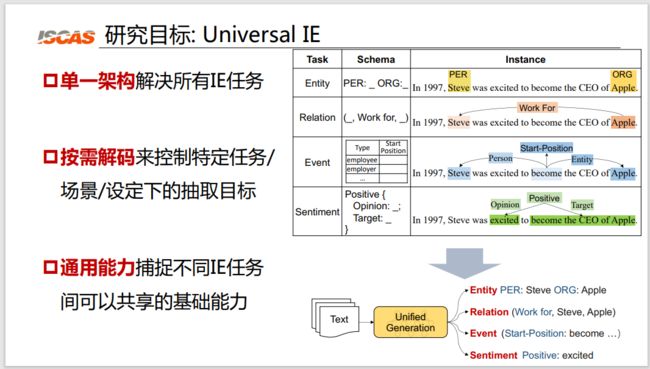
图 2:三个研究目标
首先,我们希望能够使用一个单一的架构来解决各种各样的信息抽取任务。正如图 2 右侧表格所示,我们希望把复杂的实体抽取、关系抽取、事件抽取和情感识别的所有任务,最终都能使用统一的架构解决。
第二,我们希望能够有一种按需解码机制,来控制特定的任务、场景和设定下的抽取目标。例如,我们希望有一种机制可以告诉模型,做医疗的时候,我们就只抽取医疗领域的知识;做情感的时候,就只需要抽取情感相关的知识。
第三个,我们希望有一种通用的能力来捕捉不同抽取任务间可以共享的基础能力。例如,我们希望所有的命名实体识别模型都可以共享命名实体识别的能力,所有关系抽取、事件抽取都可以共享结构抽取的能力。
信息抽取研究工作:Universal IE
针对上文提到的三个目标,我们也有对应的三种研究工作:
-
首先,针对单一架构的目标,我们提出了一个文本到结构(Text-to-Structure)的生成架构;
-
针对按需解码,我们提出了一种基于提示语(Prompt)结构的约束解码的机制;
-
针对通用能力的需求,我们提出了预训练信息抽取的大模型。
接下来将分三方面介绍我们的研究工作:
单一架构:Text2Structure 统一生成架构
如前文所述,信息抽取有各种各样的任务,因此在这个方面我们工作的目的是将各种任务特定的架构统一到一个任务的通用架构中。我们发现,不同的 IE 任务都可以定义为文本到结构的生成任务。
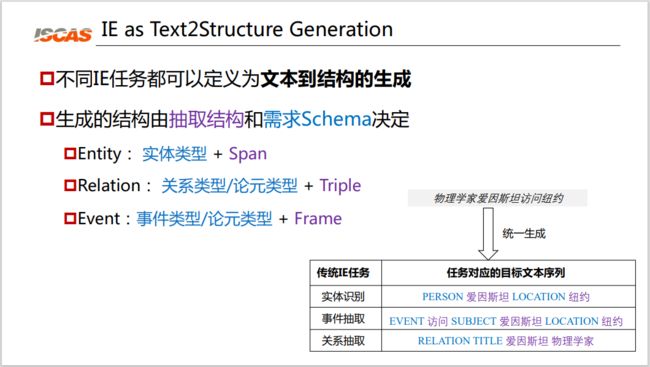
图 3:单一架构
如图 3 右下角所示,对于“物理学家爱因斯坦访问纽约”这样的任务,对于传统的实体识别任务来说,它的结构是“【人物】爱因斯坦【地点】纽约”。对于事件抽取任务来说,它的结构是“【事件】访问【主语】爱因斯坦【地点】纽约”。关系抽取则是“【关系名】爱因斯坦 物理学家”。我们可以发现,所有 IE 任务本质上都是文本到结构的生成。而生成的结构由抽取结构和需求 schema 决定:
-
实体的结构就是实体类型+Span;
-
关系就是关系类型/论元类型+Triple;
-
事件就是事件类型/论元类型+Frame 的结构。
基于这样的观察,我们认为所有的信息抽取任务都可以使用序列到结构生成网络来进行统一建模。例如输入一个句子,就可以生成出我们想要抽取出来的结构。这个过程的核心难点在于,我们的抽取目标是不同的。如对于命名实体识别,它的目标结构是文本块结构。而事件的结构是多元记录结构,例如对于离职这一事件是由触发词“离开”、人物和源供职地构成,对于入职是由触发词“加入”、任务和新供职地构成的。此外还有基于聚类的簇状结构。例如对于离职事件,可能会有多个句子来表示同一个事件。最后还可能存在嵌套结构,例如在“阿根廷国家队队长梅西”这句话中,“阿根廷”被嵌套在“阿根廷国家队队长”这一职位实体中。
针对这一挑战,我们的主要贡献是提出了信息抽取的基本能力启发的结构化抽取语言(SEL)。具体来说,
我们发现所有信息抽取的基本能力都包含以下两种:
-
定位信息点能力:发现文本中的信息点,例如实体、事件触发词等。
-
关联信息点能力:建立信息点之间联系,如关系论元、事件的论元等。

图 4:信息抽取结构化语言实例
基于这样的发现,我们提出了一种将这两种能力用统一的结构表示出来的信息抽取的结构化抽取语言。如图 4 下方所示,给出了针对“乔布斯在 1997 年成为了苹果公司的 CEO”这一句子的结构化抽取语言实例。
可以看到,我们会在抽取源中定位信息点并将他表示为 span 的一种形式,如乔布斯这里被我们用“[人物:乔布斯]”来表示;将关系表示为元组的结构,如“[人物:乔布斯(供职于:苹果公司)]”。通过这种统一的结构化表示语言,我们就可以把所有信息抽取目标转化为一个 token 序列。
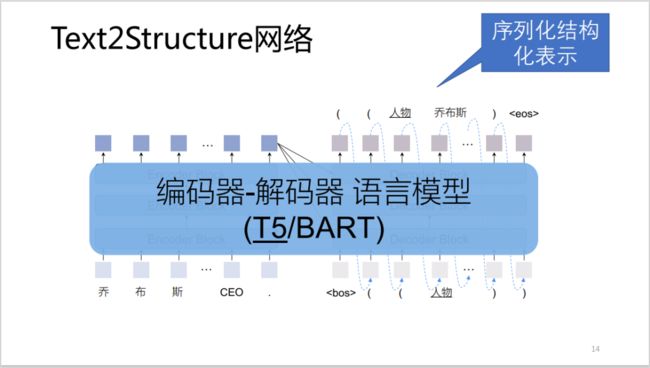
图 5:Text2Structure 架构示意图
如图 5,展示了 Text2Structure 网络的整体架构。
如前文所述,信息抽取的第二个难点在于如何告诉 Text2Structure 我们想要抽取的信息(需求 Schema)是什么以及如何约束文本到结构模型,使其能生成我们需要的、正确的目标结构,而不生成非法结构。针对这两个需求,我们分别做了两种工作:
-
针对如何在抽取过程中区分不同抽取任务的问题,我们提出了一种基于提示语 Prompt 的目标信息的指导机制;
-
针对如何生成合法的表达式,我们提出了一种结构约束的解码机制。
按需解码:基于 Prompt 的结构约束解码机制
首先,我们将介绍基于提示语 Prompt 的目标信息指导机制。具体来说,我们将 schema 的信息转换为生成过程的提示语,这样一个提示语就可以指导 UIE 模型生成正确的信息,同时也能够告诉模型从原始文本中定位正确的信息。那么大家可以看下面的例子。
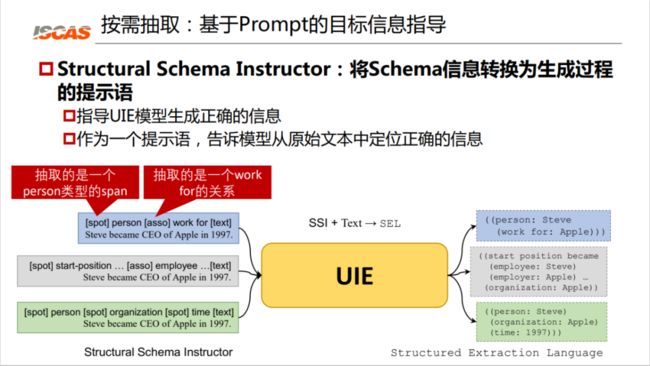
图 6:将 Schema 信息转换为提示语
如图 6 所示,spot 提示语告诉模型去定位 person 实体,asso 同时抽取 work for 的关系。可以看到,基于这样的提示语,我们就可以从这样一个句子中抽取出“乔布斯是为苹果公司工作”这样一条知识。如果给同样的句子的提示语是“开始职位 start-position”,它抽取出来的知识又不相同。
基于提示语,我们还做了第二个工作,就是结构受限的解码(Constrained Decoding)。我们将生成的过程视为对前缀树的搜索,生成合法的结构抽取表达式,并根据生成过程动态提供合法词表。通过将类别框架和文本片段建模为一个生成的前缀树的方式,将生成过程视为对前缀树的搜索,约束了解码空间并降低了解码难度,同时 schema 的约束还可以保证结构和语义上的合法性。
通用能力:预训练 IE 大模型
最后,在通用能力方面,我们提出了预训练信息抽取大模型。这一部分工作的主要问题包括如何建模并学习信息抽取的通用基础能力与面向异构监督的大规模预训练。
-
建模信息抽取的通用基础能力
不同信息抽取任务之间共享大量的基础能力。例如,不同的命名实体识别任务之间,都要共享名词短语的定位能力。如果我们能够共享名词的这种短语定位能力,我们就可以针对性地提升命名实体识别的性能。再如,不同关系抽取共享的都是实体的关联能力,不管是什么关系,本质上都是基于句子来识别实体之间的关系。最后,不管是关系抽取也好,事件抽取也好,它本质上建模的基础能力都是把自然语言句子转化为一个目标结构的能力。
-
面向异构监督的大规模预训练
我们发现互联网上存在海量的弱监督资源,例如结构化数据 DBpedia、Yago 等;还有远距离对齐数据,例如 Info 信息框、Wikidata 等;还有非结构化的数据,如 Wikipedia 等。
基于这些观察,通过把海量异质的弱监督资源如 Wikipedia、Wikidata 等,通过一种通用能力的大规模预训练,得到通用 IE 能力的大模型。基于这样一个大模型,我们可以再去设计能力迁移的按需微调和解码机制,最终将通用能力高效地应用于不同的信息抽取任务中,例如实体的识别任务、关系的抽取任务、事件的抽取任务等。
那么,如何从异质的监督中获取信息抽取的通用基础能力就成为我们主要关注的问题。最后我们完成了将不同的监督都转化为统一的学习任务,进行大规模的预训练任务的工作。
实验
具体来说,我们构建了三种类型的语料库,将异质间的数据统一成<文本,结构>形式:

图 7:预训练语料库的创建
如图 7 所示,第一种是平行数据的数据对,左侧是文本,右侧是它抽取出来的知识,大家可以看图 7 第一个例子。输入是“Steve 乔布斯在 1997 年成为了 Apple 苹果公司的 CEO”,输出是
-
文本到结构的预训练,输入是文本,输出是结构。通过这个预训练使得我们的 UIE 模型具备结构生成的能力;
-
结构生成的预训练,输入为空,输出是结构。基于这样一个预训练任务,我们希望使用结构单语数据预训练解码器;
-
文本的语义预训练,输入是文本,输出为空。在这个任务中我们希望 UIE 模型能够学习到编码文本语义的信息。
最后,我们的预训练任务综合了以上三种任务,分别是平行解码任务、单语解码任务和单语编码任务。由于信息抽取的生成目标是结构,所以其文本到结构的生成过程非常复杂。在预训练过程中,为了提升学习过程的稳定性,我们采用了课程表学习的策略。具体来说,让我们的预训练模型去生成简单的结构,从 label 和 span 等简单的一元结构开始再到更加复杂的结构,最终保证结构生成学习过程的稳定性。
实验结果
UIE 模型最后在四类信息抽取的任务,包括命名实体识别、关系抽取、事件抽取和情感抽取任务,以及 12 个数据集及 7 大领域上进行了实验。
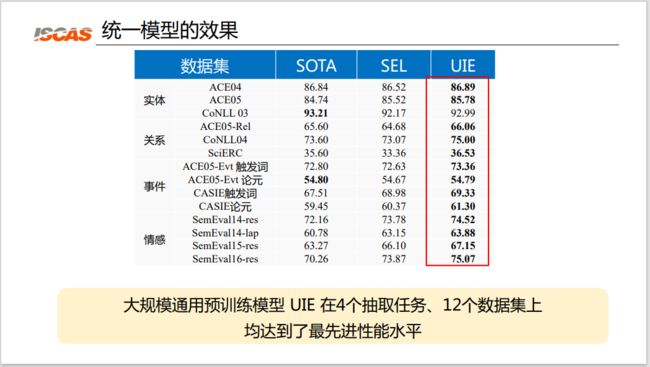
图 8:统一模型的效果
如图 8 所示,大规模的通用预训练语言模型 UIE 在 4 个抽取任务、12 个数据集上均达到了最先进性能水平。可以看到在这四类任务上,UIE 模型的结果相比当前的 SOTA 结果都取得了性能提升。第二个实验结果是,相比直接使用 T5 的这种结构化生成模型 SEL,使用预训练的 UIE 显著提升性能。同时,前文提到的三种预训练的任务和三种预训练的语料,不管是去掉哪一种预训练任务或语料都会导致一定的性能降低;而加入任何一种预训练的任务,都可以保证性能提升。因此,可以证明三种预训练语料都可以起到一定的预训练效果。
此外,预训练大模型的主要目的是迁移学习,是为了让我们在低资源的条件下仍然可以取得好的效果。我们也做了相关迁移学习的实验设置。具体来说,我们在原事件类别上进行预训练,在新事件类别上进行模型的微调。我们采用了基于词级别标注和实体标注进行学习的文本块分类模型 OneIE 与基于词级别标注进行学习的阅读理解模型 EEQA 的基线模型。
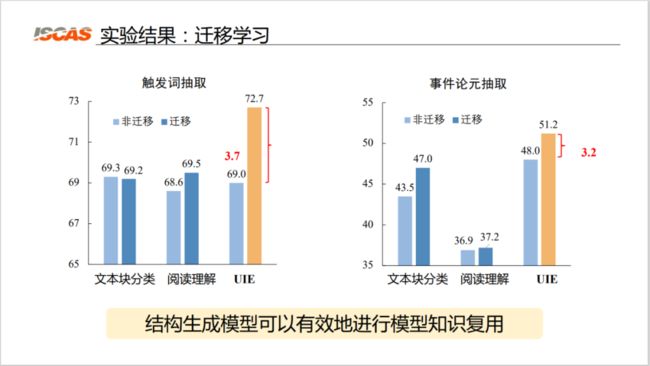
图 9:迁移学习效果
如图 9 所示,实验结果表明,基于 UIE 的模型在进行迁移学习后,其性能有非常显著的提升。两种基线模型在迁移后的性能几乎不变或提升效果非常微小;而基于 UIE 架构的模型在迁移后,其对于 F 值的提升非常显著,这表明结构生成模型可以有效地进行模型的知识复用。
最后,我们也进行了小样本通用信息抽取的实验设置。我们设定了一些小样本任务并对比了各种基线模型,包括 T5-v1.1-base,Fine-tuned T5-base 等。
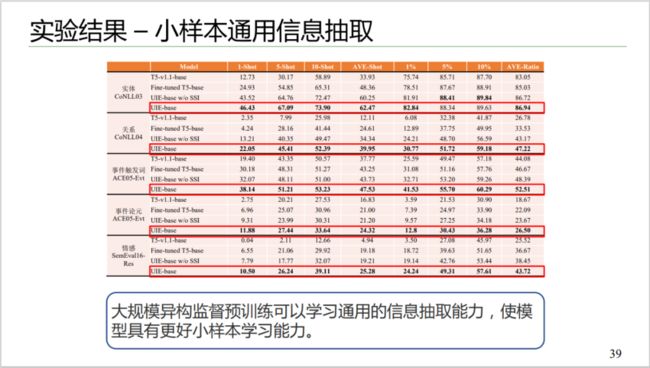
图 10:小样本通用信息抽取效果
实验结果表明,大规模异构监督预训练可以学习通用的信息抽取能力,使模型具有更好的小样本学习能力。如图 10 所示,基于预训练的模型在性能上有非常高幅度的提升。例如,在实体任务上,不预训练 1-shot 上的结果是 12.73,而预训练结果为 46.43。同时,加入前文提到的结构化抽取的提示语之后,模型迁移的学习能力更强。相比没有使用提示语的通用信息抽取,加入提示语后,例如,在情感任务上,其指标从 38 提升到 43。
总结
总的来说,我们认为,通过设计这种统一的文本到结构(Text2Structure)的生成的架构,加上按需基于提示语(Prompt)的结构约束解码算法,再加上基于海量语料的大规模信息抽取能力的预训练,最终可以达到通用信息抽取(Universal Information Extraction)的目标。
本文相关工作已发表,代码模型也已公开,感兴趣的读者可以查看下方链接阅读原文,欢迎大家批评指正。
相关链接:
1.《Unified Structure Generation for Universal Information Extraction. ACL 2022.》:https://arxiv.org/pdf/2203.12277.pdf
2.《Text2Event: Controllable Sequence-to-Structure Generation for End-to-end Event Extraction, ACL 2021.》:https://arxiv.org/pdf/2106.09232.pdf
3. 代码和模型:https://universal-ie.github.io/
4. 中文信息处理实验室:http://www.icip.org.cn