datawhale 8月学习——NLP之Transformers:Transformers解决机器翻译任务
前情回顾
- attention和transformers
- BERT和GPT
- 编写BERT模型
- BERT的应用、训练和优化
- Transformers解决文本分类任务、超参搜索
- Transformers解决序列标注任务
- Transformers解决抽取式问答任务
结论速递
与前面应用BERT的任务不同,此次的任务是transformer整体的应用,解决的是一个经典的Seq2seq,机器翻译问题。
解决的流程还是与之前类似,导入完数据,首先要对它进行tokenize预处理,由于是Seq2seq,需要对source和target都进行相应的预处理。随后加载预训练模型,定义模型训练所需要的相关参数,以及将数据输入模型所使用的data collator,并且需要定义处理数据以放入metric计算的方法(此处不止使用了预训练导入的metric,还定义了一个别的metric)。最后构建trainer,然后进行训练和验证。
由于训练用时比较长,这里尝试了导出训练好的模型及重新载入的方法。
本文索引
-
- 前情回顾
- 结论速递
- 1 机器翻译任务
-
- 1.1 任务简介
- 1.2 基础库的安装和datasets及metric的加载
- 1.3 数据的展示
- 2 机器翻译任务的实现
-
- 2.1 数据预处理
- 2.2 微调模型
-
- 2.2.1 加载预训练模型
- 2.2.2 数据收集器的创建
- 2.2.3 评估方法
- 2.2.4 训练
- 2.2.5 模型的导出和重载
- 参考阅读
1 机器翻译任务
1.1 任务简介
本任务中使用的是WMT dataset数据集。
这个数据集涉及到的翻译任务有很多,最常见的任务是新闻翻译任务,涉及下述语言间的翻译:

本次选择的任务是英语和罗马尼亚语的翻译。
model_checkpoint = "Helsinki-NLP/opus-mt-en-ro"
# 选择一个模型checkpoint
机器翻译是一个序列到序列的任务,使用BERT显然是不够的,我们所要用到的是整个Transformer。
1.2 基础库的安装和datasets及metric的加载
这个地方需要保证安装正确一些版本的库,不然就会报错。
需要保证版本正确的库包括但不限于
datasets==1.6.2
transformers==4.4.2
sacrebleu==1.5.1
tqdm==4.62.2
其中sacrebleu的版本很重要,否则会出现datasets的加载错误。
datasets和metric的加载方法如下
from datasets import load_dataset, load_metric
raw_datasets = load_dataset("wmt16", "ro-en")
metric = load_metric("sacrebleu")
1.3 数据的展示
载入的datasets依然由三个部分组成train,test,validation。
可以看到训练集的一个举例
[IN]: raw_datasets["train"][0]
# 我们可以看到一句英语en对应一句罗马尼亚语言ro
[OUT]: {'translation': {'en': 'Membership of Parliament: see Minutes',
'ro': 'Componenţa Parlamentului: a se vedea procesul-verbal'}}
2 机器翻译任务的实现
2.1 数据预处理
第一步依然是tokenize,在这个任务里头在调用上没有十分特别的地方。
但是tokenizer本身具有一定特点。
为了达到数据预处理的目的,我们使用
AutoTokenizer.from_pretrained方法实例化我们的tokenizer,这样可以确保:
- 我们得到一个与预训练模型一一对应的tokenizer。
- 使用指定的模型checkpoint对应的tokenizer的时候,我们也下载了模型需要的词表库
vocabulary,准确来说是tokens vocabulary。
from transformers import AutoTokenizer
# 需要安装`sentencepiece`: pip install sentencepiece
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
在这里所使用的mBART模型需要正确设置source语言和target语言。
if "mbart" in model_checkpoint:
tokenizer.src_lang = "en-XX"
tokenizer.tgt_lang = "ro-RO"
这里我们设置的是,从英语翻译到罗马尼亚语。
这个地方特别需要注意的是,我们需要给模型准备翻译好的targets,这里可以使用as_target_tokenizer来控制targets所对应的特殊token。
with tokenizer.as_target_tokenizer():
print(tokenizer("Hello, this one sentence!"))
model_input = tokenizer("Hello, this one sentence!")
tokens = tokenizer.convert_ids_to_tokens(model_input['input_ids'])
# 打印看一下special toke
print('tokens: {}'.format(tokens))
打印出来是这样的
{'input_ids': [10334, 1204, 3, 15, 8915, 27, 452, 59, 29579, 581, 23, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
tokens: ['▁Hel', 'lo', ',', '▁', 'this', '▁o', 'ne', '▁se', 'nten', 'ce', '!', '']
整个预处理函数是这样的
max_input_length = 128
max_target_length = 128
source_lang = "en"
target_lang = "ro"
if model_checkpoint in ["t5-small", "t5-base", "t5-larg", "t5-3b", "t5-11b"]:
prefix = "translate English to Romanian: "
else:
prefix = ""
def preprocess_function(examples):
inputs = [prefix + ex[source_lang] for ex in examples["translation"]]
targets = [ex[target_lang] for ex in examples["translation"]]
model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(targets, max_length=max_target_length, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
与上一个任务类似,我们用truncation=True来确保超长的句子被截断。
prefix的作用是,类似于T5的预训练模型,需要有特定的前缀来告诉模型要做的任务。
我们依然借助map函数来对所有的样本进行预处理。
tokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
2.2 微调模型
2.2.1 加载预训练模型
首先还是先加载预训练模型
from transformers import AutoModelForSeq2SeqLM, DataCollatorForSeq2Seq, Seq2SeqTrainingArguments, Seq2SeqTrainer
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
还是依然需要设定训练的参数,需要注意的是这里是一个序列到序列的任务,所以用到的是整个Transformer,和之前的任务有所不同,所以对应的训练参数也有所不同Seq2SeqTrainingArguments。
batch_size = 16
args = Seq2SeqTrainingArguments(
"test-translation",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=1,
predict_with_generate=True,
fp16=False,
)
由于我们的数据集比较大,同时Seq2SeqTrainer会不断保存模型,所以我们需要告诉它至多保存save_total_limit=3个模型。
可以查看model的内容。
可以看到model由编码器encoder 和解码器decoder组成。encoder一共有6个MarianEncoderLayer,每个layer由一个selfattention层,以及两个全连接层构成,attention及全连接部分的后面都有normalization。
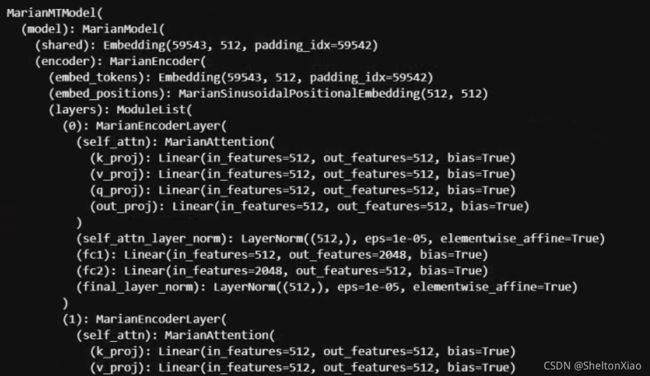
decoder由6个MariaDecoderLayer构成,每个Layer有一个SelfAttention,一个EncoderAttention和两个全连接层构成,SelfAttention、EncoderAttention和全连接部分的后面都有normalization。

2.2.2 数据收集器的创建
我们还需要一个数据收集器data collator,把我们处理好的输入喂给模型。
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
2.2.3 评估方法
设置好Seq2SeqTrainer还剩最后一件事情,那就是我们需要定义好评估方法。我们使用metric来完成评估。
但我们需要先把数据进行后处理,才能够送入评估。
import numpy as np
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [[label.strip()] for label in labels]
return preds, labels
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
result = {"bleu": result["score"]}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
result = {k: round(v, 4) for k, v in result.items()}
return result
这个维度是怎么确定的呢?
在什么地方会有-100出现,如何实现提取后维度的对齐。
这个地方可以看出来最后的result里头有两个部分,一个部分是bleu,就是metric对应的结果。gen_len是计算不相等的token个数。
2.2.4 训练
最后将所有的参数/数据/模型传给Seq2SeqTrainer。
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
调用train方法进行训练
trainer.train()
在colab pro里头训练结果如下

在本地主机(RTX 3080)训练结果如下

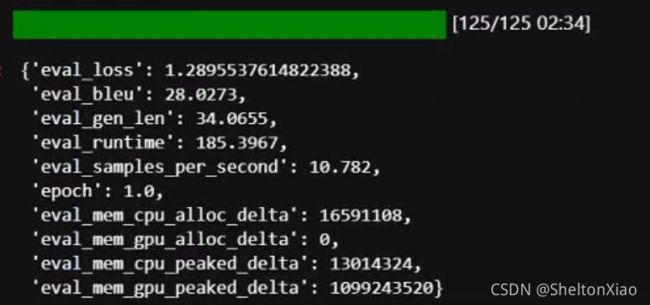
对模型进行evaluate
trainer.evaluate()
2.2.5 模型的导出和重载
由于模型的训练用时较长,为防止训练丢失,我们可以将模型导出存储
trainer.save_model("test-ml-trained")
如果在colab 上,则需要连接GoogleDrive才能将模型下载下来。
首先连接GoogleDrive
from google.colab import drive
drive.mount('/content/drive')
接着登陆账号填写对应的代码。
trainer.save_model("/content/drive/MyDrive/test-ml-trained")
存储的时候注意需要填好地址,如果在drive跟地址上,会显示没有权限。
存储好的模型长这样。

参考这篇博客,并且注意到trainer类对象没有对应的from_pretrained方法。
这边重载模型用的是model类对象。
model = AutoModelForSeq2SeqLM.from_pretrained("/content/drive/MyDrive/test-ml-trained")
tokenizer也可以重载,但因为我们训练过程没有修改,所以可以直接从checkpoints中重载。
重载完模型之后,一样需要建立trainer,代码和先前的一样。
我们将重载完的模型同样也evaluate一下,显示的结果是这样的。

可以看到计算的epoch数为1的信息没有被加载进来,但是模型还是原来那个模型,验证集上的计算结果没有发生更改。
参考阅读
- Datawhale教程