[Transformer]U2Former:A Nested U-shaped Transformer for Image Restoration
U2Former:用于图像修复的U形嵌套Transformer
- Abstract
- Section I Introduction
- Section II Related Work
- Section III Method
- Section IV Experiments
-
- Part 1 Albation Study
- Part 2 Experiment on Image Deraining
- Part 3 Experiments on Image Dehazing
- Section V Conclusion
Paper
Abstract
虽然Transformer已在诸多高级视觉任务中取得了显著性能,但是将其用于图像修复仍有较大的探索空间。关键在于在传统的编解码框架中能嵌入的深度有限,受限于自注意力的计算复杂福和不同层次中低效的信息交互。
本文提出一种更高效的基于Transformer的U形网络称之为U2Former,主要使用嵌套的U形结构来促进不同尺度的特征图在不同层之间交互。
此外本文还引入一种特征过滤机制来压缩token从而提升Transformer的计算效率。除了传统的监督图像修复算法,本文还使用对比学习在去雨、去模糊等任务上均取得了优异的效果。
Section I Introduction
图像修复是计算机视觉汇总一大重要且有十分具有挑战性的任务,涉及到反射去处、图像去雨、图像去模糊等。为了无损修复图像,需要对不同的噪声模式进行准确建模,目前大多数SOTA方法主要基于CNN建立,但是由于卷积操作的固有局部属性,使得噪声模式的感知只能局限在局部感受野;但是在进行图像修复时获得对整个图像的全局感知是十分重要的。
不像CNN能够学习平移不变性的特征,也可以通过堆叠逐渐扩大局部感受野,Transformer通过自注意力可以计算全局的依赖性,因此Transformer的一个显著优势是每个特征学习时每个隐藏单元都能根据全局上下文进行处理,这种特征使得Transformer非常适合处理图像到图像的映射任务,因为在全局视图下更通域学习这种空间相关性,如图像噪声模式、背景模式。
尽管Transformer已经在一些高级视觉任务中取得了进展,但是还没有在图像修复方面得到充分应用。Uformer将自注意力模块嵌入到U型网路欧中,这样在图像修复时可以利用解码器中不同尺度的特征,但是它的问题在于深度优先,不可避免的限制了对噪声模式的学习,不利于图像修复。
主要由下述两方面局限性导致的:
(1)深层的U性网路使得不同尺度的信息交互十分低效,不利于反向传播模型的优化;
(2)自注意力的计算复杂度限制了编解码网络能搭建的深度
为了解决Uformer的局限性本文提出U2Former进行图像修复,主要有以下三方面的优势:
(1)U2Former通过嵌套的U性结构来促进不同尺度特征图的交互,主要有2种嵌套的U性结构,分别是内部基于自注意力模块的嵌套模块主要用于聚合不同尺度的特征图;还有就是外部的嵌套U型模块,利用内部的U形嵌套搭建较深层次的编码-解码网络结构来学习噪声模式,负责从背景图像中分离噪声;为了提升计算效率本文还提出一种特征过滤机制来压缩token。这样U2Former可以堆叠较大深度来分离背景和噪声。
(2)U2Former还进行多视图的对比学习从而更好的解耦图像中的噪声,主要从三方面进行对比学习:
1-将同一重建后的背景图中的两个patch作为positive pairs,引导模型确保不同区域之间的一致性;
2-将重建后的patch和对应的GT patch作为一对引导获得背景更干净的重建图像;
3-将重建后的图像patch和随机的GT 背景patch作为一对来引导模型学习与图像内容无关的噪声敏感的特征
(3)本文在图像去模糊、反射去处、去雨等试验中验证了U2Former的性能,均优于当前的SOTA模型。
Section II Related Work
Image Restoration
图像修复领域主要通过堆叠多个卷积层搭建CNN来完成,辅助有引入残差连接以及提取多尺度的特征来获得更丰富的全局上下文信息,编解码网络结构也在图像修复类网络中十分常见,还有注意力机制,比如空间注意力来捕获全局的长程依赖。
Vision Transformer
原始ViT比如IPY主要依赖在大规模数据集上预训练的结果,Swin Transformer则提出基于移位窗口的Transformer减轻了计算复杂福;UFormer则是基于Swin Transformer搭建了一个U型网络用于图像修复但是受限于计算成本,搭建的网络深度优有限。
本文受U2Net的启发打算搭建一个嵌套的U形Transformer结构,使得网络可以同时获得浅层局部和深层全局信息。
Contrastive Learning
对比学习已经广泛用于自监督的特征学习,但是由于构建对比样本和对比损失函数存在困难,很少将对比学习用于图像修复;最近有使用SR对比学习抽象表示,分别将模糊图像和清晰图像作为负正样本,本文则使用一种新提出的多视图方法进行对比学习。
![[Transformer]U2Former:A Nested U-shaped Transformer for Image Restoration_第1张图片](http://img.e-com-net.com/image/info8/80dc95222d434826b53370c258c4953d.jpg)
Section III Method
本节主要阐述U2Former的整体框架,详情参见Fig 1,主要包含两种基础模块:内部的U形Transformer模块(UTB)和外部的U形模块。外部UTB是一个U性的编解码网络,包含编码器和两个并行的解码器,分别用来解耦背景特征和噪声特征。一共包含5个stage,并且使用新提出的多视角对比学习来将噪声部分从背景中解耦出来。
UTB-L是一个轻量级的U形Transformer网路,L代表深度,每一个block具体结构参见Fig 2(c),分别在编码器和解码器中负责上采样和下采样,可以看到提取图像的局部和全局特征有利于从背景分支中分离出噪声分量,此外通过残差连接将UTB中的特征F(X)与原始输入X融合可以获得更复杂的信息。
Inner U-shaped Transformer block
Inner UTB的具体结构暂时在Fig 2(b)
Feature Filtering Mechnism
为了减少SA的计算复杂度,避免过拟合,本文还进一步提出了特征过滤的基于窗口的多头注意力(FW-MSA),主要通过注意力机制获得当前特征维度中输入特征的注意权重。
Fs代表本文选择的特征维度,具体如何选择参见Fig2(d)。为了防止过拟合还使用了残差连接。其中FFN前馈网络还是用深度可分离卷积来捕获局部依赖关系。
![[Transformer]U2Former:A Nested U-shaped Transformer for Image Restoration_第2张图片](http://img.e-com-net.com/image/info8/e36b51e25e404a629238444098d5faef.jpg)
Outer U-shaped Encoder-Decoder framework
外部UTB参见Fig2(a),可以看到编码器包含5个stage,解码器是两个并行的模块分别解码背景和噪声特征,4个stage。
每一个stage使用不同层数的block,分别是UTB-5,UTB-4,UTB-3,UTB-2。在Genc的第一阶段因为特征图的分辨率已经比较低下了本文为了尽可能保存有价值的特性本文没有使用下采样,而是值堆叠了6个Transformer block.最后使用1x1卷积重建清晰的背景图和噪声图。
Mulit-View Contrastive Learning
对比学习是一种基于判别的方法,间该内容相近和内容不同的组成一组进行鉴别。虽然在许多高级任务中证明了其有效性但是在图像修复方面仍有很大潜力。
本文提出一种新的基于多视图的对比学习方法来引导U2Former去除复杂的噪声模式。
如Fig 3中会现将同一批图像中的背景图像、噪声图像和GT切分成patch然后将背景patch和GT Patch标记为正样本,噪声patch标记为负样本。从以下视角进行对比学习:
(1)View-1:由于输入图像的噪声分布并不一定是均匀的,为了确保同一图像中不同区域之间恢复的一致性,本文从同一复原图像中取两个patch作为正对;
(2)View-2:将修复图像的背景与GT也作为一组正样本,用于恢复背景干净的图像;
(3)View-3:将具有不同图像内容的背景patch与GT作为一组正样本,来引导模型对噪声敏感的特征的学习,而不是图像内容。
按照同样的方式构造负样本对,总之通过多个角度构建对比来引导模型学习图像的退化而不是相似的图像内容。具体来说就是将这些构造好的patch提供给encoder然后通过MLP中两层FC来获得计算特征相似性的特征嵌入。
通过将query patch,正样本和负样本都映射到N维向量,最大化patch之间的相似性,使用噪声对比估计:
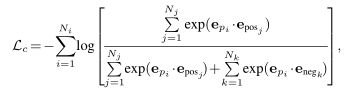
Multi-stage Pixel Reconstruction Loss
多阶段损失函数表示如下:
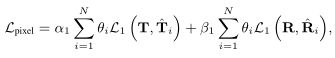
T,R分别表示GT和对应的噪声图像,阈值对比的是重建的图像和噪声图像二者的权重设置为0.7:0.3.
Multi-stage Perceptual Loss
还使用了多阶段感知损失函数

总损失函数表示为:
![]()
![[Transformer]U2Former:A Nested U-shaped Transformer for Image Restoration_第3张图片](http://img.e-com-net.com/image/info8/6c2e3135a6894b769f39c0aea1a00ddf.jpg)
从Fig 3可以看出提出的多视角对比学习,分别使用了三种视角,View-1是来自同一重建图像的不同patch;View-2是重建背景patc和对应的GT背景,二者内容是一致的;View-3是重建的背景图像和随机的背景GT,二者内容是不一致的
还会比较对应重建背景和噪声作为负样本。
Section IV Experiments
为了验证U2Former的有效性,本文进行了图像反射去处、图像去雨和图像去模糊任务。
评价指标主要是PSNR和SSIM。
计算卡:6块RTX 3090
Tranformer 窗口设置为8x8
图像512 x 512
Part 1 Albation Study
首先验证的是U2Former用于反射去处,对比网络有UNet,U2Ne,Uformer,Uformer-UTB-就是将Uformer中的Transformer换成本文提出的UTB,以及本文的Y2Foermer。
table 1展示了对比结果。
![[Transformer]U2Former:A Nested U-shaped Transformer for Image Restoration_第4张图片](http://img.e-com-net.com/image/info8/952faea074ef46d1b226d38391dcf5c8.jpg)
实验结果表明,本文提出的内部UTB模块性能更好、计算成本更低。当堆叠更多Transformer Block时U2Former的性能得到了明显改善;与with CL相比可以看到本文的多视角对比增强学习对于指导模型从背景图像中解耦噪声特征是有效的。并且一额有趣的实验现象是和基于CNN的UNet相比Transformer显示出更加优异的性能。
![[Transformer]U2Former:A Nested U-shaped Transformer for Image Restoration_第5张图片](http://img.e-com-net.com/image/info8/9c328a96a4a84b19ab34dca313f3d2a0.jpg)
![[Transformer]U2Former:A Nested U-shaped Transformer for Image Restoration_第6张图片](http://img.e-com-net.com/image/info8/4a1290d511f44b3d8f35a0d17bf07b43.jpg)
Effect of varying the compression ratio by the feature-
filtering mechanism
从Fig 4可以看出使用特征过滤机制不同的压缩比对模型性能和计算成本的影响。本文只统计了一个Transformer block的计算成本。当过滤50%特征时可以看到模型性能最好同时FLOPs也有所下降。充分证明了本文提出的特征过滤机制可以有效减少计算成本,同时找到了更有价值的特征用于自注意力的计算。
![[Transformer]U2Former:A Nested U-shaped Transformer for Image Restoration_第7张图片](http://img.e-com-net.com/image/info8/93ab1b12670d409fb48db3cffa90107d.jpg)
Part 2 Experiment on Image Deraining
本文在两个合成数据集上进行图像去雨实验,Table 3是实验结果,可以看到本文的方法达到了最佳的性能,在rain100L上提升了1.63dB,达到了39.31dB;在rain100H上提升了1.50dB,到达了30.87dB。Fig 6展示了可视化去雨结果,可以看到其他方法都存在过度平滑或者模糊的问题,本文则可以恢复更多细节。
![[Transformer]U2Former:A Nested U-shaped Transformer for Image Restoration_第8张图片](http://img.e-com-net.com/image/info8/5e03aa6209be44bdad2534e2aa6d31dd.jpg)
![[Transformer]U2Former:A Nested U-shaped Transformer for Image Restoration_第9张图片](http://img.e-com-net.com/image/info8/e8b27d3424ed473da863b708572ca45a.jpg)
Part 3 Experiments on Image Dehazing
Table 4是图像去雾任务的结果,类看到本文在室内和室外场景均达到了最佳的性能,尤其在室外数据集上有2.54dB的提升,Fig 7可视化了去雾对比结果,可以看到其他方法有明显的颜色失真等问题,本文取得了最佳的可视化结果。
![[Transformer]U2Former:A Nested U-shaped Transformer for Image Restoration_第10张图片](http://img.e-com-net.com/image/info8/02873df11b6542f5b06466dc8c762b65.jpg)
Section V Conclusion
本文提出一种U2Former用于图像修复,主要基于嵌套的U形网络用于不同层的信息交互,并且提出特征过滤机制来降低计算成本。因此本文的U2Former可以灵活的调控网络深度,进一步解耦图像的背景和噪声成本;并且通过构建多种视角的对比学习在多个图像修复任务上达到了SOTA。
这不和U2Net一样么…