2019年全国研究生数学建模 D题 汽车行驶工况构建 建模及经历分享
目录
- 前言
- 解题和建模
-
- 题目
- 题目分析
-
- 问题一
- 问题二
- 问题三
- 参考文献
- 建模经历分享
-
- 组队与队友
- 关于选题
- 建模开始
前言
距离2019年的研究生数学建模国赛结束有将近三个月了,前不久比赛结果公布,拿了个小奖。尽管没有拿到一等奖,觉得可以把比赛的经历和当时的模型记录一下做个分享和纪念。

文章主要分成两个大块,一个是解题和建模,一个是抛开技术性因素的经历分享。
解题和建模
题目
原题太长了,我把我们队缩略的版本放上来。
本世纪初,我国直接采用欧洲的 NEDC 行驶工况对汽车产品能耗/排放的认证. 但近年来,我国道路交通和汽车保有量发生较大变化,发现以 NEDC 工况为基准所优化标定的汽车,实际油耗与法规认证结果偏差越来越大. 同时,欧洲也发现 NEDC 工况的不足,从而采用世界轻型车测试循环(WLTC). 但该工况怠速时间比和平均速度这两个最主要的工况特征,与我国实际汽车行驶工况的差异更大. 所以制定出反映我国实际道路行驶状况的测试工况愈发重要. 另一方面,我国地域辽广,各个城市的发展程度、气候条件及交通状况的不同,使得各个城市的汽车行驶工况特征存在明显的不同. 因此,基于城市自身的汽车行驶数据进行城市汽车行驶工况的构建研究也越来越迫切,希望所构建的汽车行驶工况与该市汽车的行驶情况尽量吻合.
本文主要解决以下三个问题:
1、 对附件中不良数据的主要类型进行处理,并给出处理后的记录数.
2、 对处理后的数据进行运动学片段的提取.
3、 通过科学、有效的构建方法(数学模型或算法),构建一条能体现参与数据采集汽车行驶特征的汽车行驶工况曲线(1200-1300 秒),同时该曲线需满足以下要求:
(1) 具备合理的汽车运动特征评估体系;
(2) 按照所构建的汽车行驶工况及汽车运动特征评估体系,分别计算出汽车行驶
工况与该城市所采集数据源的各运动特征的值,并说明所构建的汽车行驶工况的合理性.
原始题目我上传CSDN了,点这里下载可看 汽车行驶工况构建0914.docx
题目分析
问题一
问题一是分别对附件中各个文件的车辆行驶数据进行预处理,为后续构建科学合理的行驶工况曲线做好铺垫. 在处理不良数据时,方法是对其进行修正、剔除或填充,从而保证行驶数据能有效反映正常车辆在实际道路上行驶的情况. 若将不良数据如数删除则必然会影响数据的连贯性;若将所有缺失数据填充将导致大量数据的产生,导致处理后的行驶数据偏离实际,所以在进行数据预处理时应针对不同类型的不良数据,采用合理的方法.
主要对五种类型的不良数据进行处理,包括:1.由于建筑覆盖过隧道导致数据丢失的情况(丢失数据),2.加减速异常情况(异常数据),3.长期停车所采集的数据,4.长时间堵车,5.怠速过长等五种类型不良数据.
对于丢失数据(第 1 类)应采用合理的填充,以保证数据连贯;对于第 2-4 类不良数据可采用修正的方法进行处理;对于最后一类的数据可用剔除的方法处理. 最后给出修改后的数据记录数.
对于建筑覆盖和过隧道导致的数据丢失情况,采取填充的方法进行处理,由于汽车通过隧道或建筑时保持一定速度,所当两条速度不为 0 的数据其间隔小于 5s 时,可认为是由于 GPS 信号丢失导致的数据缺失. 对于这样的数据,采用间断时间段左右的速度均值进行填充.
对于加减速异常的情况,先计算当前时刻的加速度,把高于题目中所给上限的都改成上限值3.78,下限-8同理。
长期停车所采集的数据,表示发动机转速为 0,但设备依旧在采集,本文采用剔除的方法进行处理.
长时间堵车的数据,是指在一段时间内最高车速都小于 10的数据。在 180 秒内最高速度都小于10,则该段数据按照怠速处理(车速修正为 0).
怠速异常的数据,是指怠速时长超过 180 秒的时间段,通过剔除多余时常的方法进行处理,由于处理第 3,4 类数据后会产生怠速数据,故处理怠速异常数据放在最后进行.
最后我们处理后的结果如下表
| 文件名 | 处理前总数据量 | 预处理后的记录数 |
|---|---|---|
| 文件 1 | 185725 | 185869 |
| 文件 2 | 145826 | 148358 |
| 文件 3 | 164915 | 165720 |
问题二
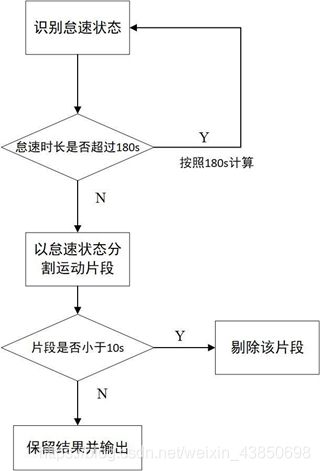
第二问是对处理后的数据进行运动片段的分割和提取. 由于数据除间断时间外都是连续,但在构建行驶工况时需要从中提取 1200-1300s 的运动片段,所以需要将预处理后的数据进行片段分割. 而对于运动片段的划分较为常见的方法是从汽车怠速状态开始至下一个怠速状态开始间的车速区间,也就是说该运动片段内基本包含一辆车的所有运动状态(怠速、加速、巡航、减速). 提取完运动学片段后,可根据相关的模型寻找出最为合理的多个片段进行拼接.
在划分运动学片段时是依据怠速和怠速间的状态进行分割,所以必然会遇到车速区间过短的片段,对于该类片段采取剔除.
问题三
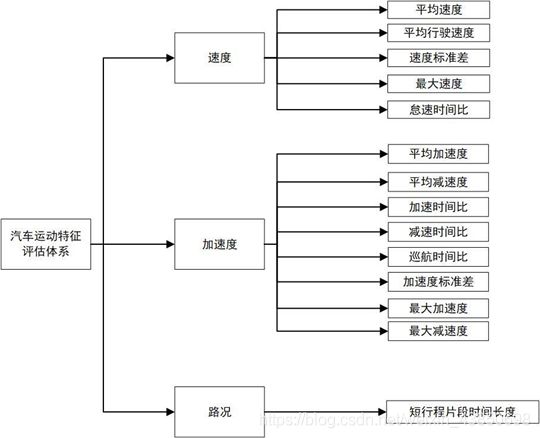
问题三是根据合理的汽车运动特征评估体系构建误差最小的汽车行驶工况曲线. 所以合理的特征评估体系至关重要,若考虑的指标过少,则无法反映该城市真实的交通状况,但是考虑的指标太多可能会造成计算的复杂度过大. 本文基于前人的文献和相关资料构建合理的运动特征评估体系. 在构建行驶工况曲线时,有两种思路进行构建.
第一种思路是计算出问题二所构建的每条运动学片段对应的各运动特征指标值,再进行聚类分析,将运动学片段中“亲密度”高的聚为一类,然后再从每类运动学片段中提取最具有代表性(误差最小)的片段,将其进行拼接,形成工况曲线. 最后对形成的工况曲线的误差和各运动特征指标值进行计算.
第二种思路则是用马尔可夫过程构建工况曲线. 由于汽车行驶过程中的状态只与前一秒状态有关,故可将行驶过程看成马尔可夫状态转移的过程. 对于该方法则不需要使用运动学片段,而是对预处理数据内的每个时间点按照速度和加速度等标准进行状态划分,将汽车行驶的变化视为状态之间的转移. 当随机给出一个状态时,可生成指定长度(1200s-1300s)的状态序列,即构成汽车行驶工况曲线.
从速度、加速度、路况三个大方面进行运动特征体系的构建.
主要思路就是这样,运算结果具有随机性,就先不放出了。如果有需要交流的可以给我发私信。
参考文献
[1] Bishop JDK, Axon CJ, McCulloch MD. A robust, data-driven methodology for real-world driving cycle development. Transportation Research Part D-Transport and Environment. 2012;17(5):389-97.
[2] Han DS, Choi NW, Cho SL, Yang JS, Kim KS, Yoo WS, et al. Characterization of driving patterns and development of a driving cycle in a military area. Transportation Research Part D-Transport and Environment. 2012;17(7):519-24.
[3] 仇多洋. 汽车行驶工况的构建及波动特性研究[D].合肥工业大学,2012.
[4] 姜平,石琴,陈无畏,黄志鹏.基于小波分析的城市道路行驶工况构建的研究[J].汽车工程,2011,33(01):70-73+51.
[5] 彭育辉,杨辉宝,李孟良,乔学齐.基于 K-均值聚类分析的城市道路汽车行驶工况构建方法研究[J].汽车技术,2017(11):13-18.
[6] 姜平. 城市混合道路行驶工况的构建研究[D].合肥工业大学,2011.
[7] 李耀华,任田园,邵攀登,宋伟萍,李忠玉,苟琦智.基于马尔可夫链的西安市城市公交工况构建[J].中国科技论文,2019,14(02):121-128.
[8] 曹骞,李君,刘宇,曲大为.基于大数据和马尔科夫链的行驶工况构建[J].东北大学学报
(自然科学版),2019,40(01):77-81.
[9] 曹骞,李君,刘宇,曲大为.基于马尔科夫链的长春市乘用车行驶工况构建[J].吉林大学学报(工学版),2018,48(05):1366-1373.
[10] 蔺宏良. 西安市交通环境轿车行驶工况与燃料消耗研究[D].长安大学,2013.
[11] 王昊,章桐,宋珂.上海市行驶工况构建与研究[J].内燃机与配件,2018(13):35-38.
[12] 王跃飞,章楠,孙召辉,吴源,刘白隽.基于 LVQ 模型的汽车行驶工况识别算法[J].农业装备与车辆工程,2019,57(05):1-4+8.
[13] 张锐. 城市道路汽车行驶工况的构建与研究[D].合肥工业大学,2009.
[14] 杨辉宝. 福州市区典型道路汽车行驶工况的研究[D].福州大学,2017.
[15] 史彦丽. 模糊聚类和模糊聚类有效性的研究[D].大连理工大学,2017.
[16] Ho S-H, Wong Y-D, Chang VW-C. Developing Singapore Driving Cycle for passenger cars to estimate fuel consumption and vehicular emissions. Atmospheric Environment. 2014;97:353-62.
[17] Knez M, Muneer T, Jereb B, Cullinane K. The estimation of a driving cycle for Celje and a comparison to other European cities. Sustainable Cities and Society. 2014;11:56-60.
[18] Zhao JY, Gao YH, Guo JH, Chu L. The creation of a representative driving cycle based on Intelligent Transportation System (ITS) and a mathematically statistical algorithm: A case study of Changchun (China). Sustainable Cities and Society. 2018;42:301-13.
建模经历分享
本科时大大小小的建模参加过几次,研究生阶段的算是第二次,第一次是校赛。个人感觉题目和本科题目比起来并没有其他地方说的变难了,只是6选1对选择困难症不太友好。
组队与队友
之前学校有组织过校赛,那时候找的队友,所以有过磨合。从本科到现在,队友组合换过很多次了。合作的比较好的经验就是一定要有至少一个人是之前比较熟悉的,这样会有利于沟通。真正比赛的时候,中后期都会比较崩溃,如果沟通还有问题,那就几乎判定game over了。本科的时候经常会听到一种说法,找一个数学的、一个编程的、一个写论文的,根据我的经验,不必强求这样的组合,能够有比较好的沟通更重要。有的人的观点是不要找差不多专业的,因为大家会的都差不多,思路会受限。这种情况确实存在问题,但也有好处,就是沟通起来会很容易,做题和写论文都会更快。还有就是大家的能力不要相差太多,不然都指望着某一个人去做,最后很容易出岔子,而且很难补救。合作愉快的几次,搭配就是大家能力差不多,可能能力侧重点不一样,做题也没有像其他人那样分工很明确,就是you can you up,谁做出来了就做,做不出的先写论文。不过队长还是需要心里有数的,否则时间上可能会有问题。
关于选题
选题来来回回纠结了很多次,这次的6道题里面有好几题都是我们感觉可以做一做但是不知道要怎么样才能做得好的。我们采取的是先把绝对做不了的删掉,三个人分别去找待选中的至少一道题的资料,并且尽量找到能进行下去的合适的方向,如果找不到方向则放弃。经过不停的查找资料和讨论,最后选择了D题。
有必要说明的是,能够做下去不仅仅是理论上能够做,还要考虑附件给出的数据资料,以及附件中没有给出但很可能又需要的资料的获取等一系列因素。也许还有其他的方法,但我们采用的是这种方式。大概用了6-8个小时才最终选定题目。
建模开始
选定好题目之后,开始疯狂找资料,然后和主攻编程的队友讨论思路程序化的可行性。把原题给的三个大问题拆成两部分,前面一部分主要在数据处理,后面一部分主要是数学模型。
和之前校赛一样,我跳过前面,直接去做数学模型,两个队友一个处理数据做前两问,一个写论文框架。具体的模型在这个部分就不再详细说啦。
在建模期间,能感受到每个人的心理状态很重要。校赛还挺顺利的,因为题目算是陈题,资料很丰富,方向也比较明确,所以即使我们没注意状态问题,还是比较轻松的拿到了总分第4名。这次面临的挑战比较大,中间遇到几个坎都很难过去,能够在过程中感觉到心理状态越来越崩溃。崩溃是没用的,只能互相鼓励,就算谁出了小差错也绝对不要用负面的话指责,实在搞不出了也要一起面对,找到退而求其次的办法。就算再难,再想放弃,也不要表现出来,一定要把论文写完再说。这里也要感谢队长一直沉着冷静,还会调节气氛,凌乱之中还能稳稳撑住,让头脑无比混乱的我一直坚持着。不过因为真的快崩溃了,比赛最后一天上午我们七八点钟把论文搞好了之后就散了……
总之,整个过程,太难了T_T
时隔三个月,还是能想起那时的一幕幕,痛并快乐着吧。