python 使用卷积神经网络处理手写数字识别数据集
LeNet-5 网络模型
LeNet-5神经网络一共五层,其中卷积层和池化层可以考虑为一个整体。网络结构如下:
输入→卷积→池化→卷积→池化→卷积(全连接)→全连接→输出
| 层数 | in_channel | out_channel | kernel_size | stridep | adding |
|---|---|---|---|---|---|
| 卷积层c1 | 1 | 6 | 5 | 1 | 2 |
| 池化层s2 | 6 | 6 | 2 | 2 | 0 |
| 卷积层c3 | 6 | 16 | 5 | 1 | 0 |
| 池化层s4 | 6 | 16 | 2 | 2 | 0 |
| 卷积层c5 | 16 | 120 | |||
| 全连接层F6 | 120 | 84 | |||
| 输出层 | 84 | 10 |
使用小批量数据集训练,规模为64。
代码如下:
这里为了绘制一个好看的图,81行和82行参数为20,1自己训练时建议更改
import torchvision as tv # 专门用来处理图像的库
from torchvision import transforms # transforms用来对图片进行变换
import os # 用于加载旧模型使用
import numpy as np
import torch
import torch.nn as nn # 神经网络基本工具箱
import torch.nn.functional as fun
import matplotlib.pyplot as plt # 绘图模块,能绘制 2D 图表
from torchvision.transforms import ToPILImage
import torchvision
# 读取数据
def read_data(file):
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(), # 将图片类型由 PIL Image 转化成tensor类型。转换时会自动归一化
transforms.Normalize((0.5), (0.5))]) # 对图像进行标准化(均值变为0,标准差变为1)
# 从网上下载手写数字识别数据集
train_data = torchvision.datasets.MNIST(root=file, train=True, transform=transform, download=True)
test_data = torchvision.datasets.MNIST(root=file, train=False, transform=transform, download=True)
return train_data, test_data
# 定义卷积神经网络==========================================================
class ConvNet(nn.Module): # 类 ConvNet 继承自 nn.Module
def __init__(self): # 构造方法
# 下式等价于nn.Module.__init__.(self)
super(ConvNet, self).__init__() # 调用父类构造方法
# 使用了三个卷积层,两个全连接层
# 卷积层===========================================================
self.conv1 = nn.Conv2d(1, 6, 5, padding=2) # 输入1通道,输出6通道,卷积核为5*5,两端补2个零
self.conv2 = nn.Conv2d(6, 16, 5) # 输入6通道,输出16通道,卷积核为5*5
self.conv3 = nn.Conv2d(16, 120, 5) # 输入16通道,输出120通道,卷积核为5*5
# 全连接层=========================================================
self.fc1 = nn.Linear(120, 84) # 输入120,输84
self.fc2 = nn.Linear(84, 10) # 输入84,输出10
def forward(self, x):
# 最大池化步长为2
x = fun.max_pool2d(fun.relu(self.conv1(x)), 2) # 1*28*28 -> 6*28*28 -> 6*14*14
x = fun.max_pool2d(fun.relu(self.conv2(x)), 2) # 6*14*14 -> 16*10*10 -> 16*5*5
x = fun.relu(self.conv3(x)) # 16*5*5 -> 120*1*1
x = x.view(x.size()[0], -1) # 展开成一维
x = fun.relu(self.fc1(x)) # 全连接层 120 -> 84
x = self.fc2(x) # 全连接层 84 -> 10
return x
file = 'D:\\python_mnist\mnist\\train' # 数据文件地址
train_start, test_set = read_data(file)
print('训练及图像有:', len(train_start), '张。\n测试集图像有:', len(test_set), '张。')
# 打包数据集 python将多个数据打包处理,能够加快训练速度
batch_size = 64 # 批量大小为
# 将测试集和训练集每 4个 进行打包,并打乱训练集(shuffle)
train_set = torch.utils.data.DataLoader(train_start, batch_size=batch_size, shuffle=True) # 训练集
test_set = torch.utils.data.DataLoader(test_set, batch_size=batch_size, shuffle=False) # 测试集
print("已将将数据集%2d 个打包为一组,加快训练速度" % batch_size)
# 设置卷积神经网络和训练参数=================================
print("正在加载卷积神经网络=========================================")
# 如果设备 GPU 能被调用,则转到 GPU 加快运算,否则使用CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = ConvNet().to(device) # 初始化模型
print(device)
print('可使用GPU加速' if (torch.cuda.is_available()) else '无法开启GPU加速')
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
# 模型加载==========================================
seat = './cnn.pth' # 保存位置(名称)
if os.path.exists(seat): # 如果检测到 seat 文件
print("检测到模型文件,是否加载已训练模型(Y\\N):")
shuru = input()
if shuru == 'Y' or shuru == 'y':
model.load_state_dict(torch.load(seat))
print("已加载已训练模型")
else:
print("未加载已训练模型")
else:
print("未检测到旧模型文件")
# 训练开始==========================================
loop_MAX = 20 # 外循环次数(测试)
loop = 1 # 内循环次数(训练)
print("训练次数为:", loop * loop_MAX)
print("每过 %d 轮执行自动测试以及模型保存" % loop)
print("开始训练===================================================")
Training_accuracy = [] # 记录训练集正确率
Test_accuracy = [] # 记录测试集正确率
process = [] # 记录训练时误差
i = 0 # 函数内使用,提前定义
lentrain = len(train_set)
learning_rate = 0.003 # 基础学习率
print("基础学习率为:", learning_rate)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) # 优化器:随机梯度下降算法
for j in range(loop_MAX): # j 测试轮数
for epoch in range(loop): # 训练 loop 次 epoch 当前轮训练次数
running_loss = 0.0 # 训练误差
# 下面这个作用是每轮打乱一次,没什么大用处,不想要可以删去
train_set = torch.utils.data.DataLoader(train_start, batch_size=batch_size, shuffle=True) # 训练集
# enumerate() 函数:用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标。
for i, (images, labels) in enumerate(train_set, 0):
# 转到GPU或CPU上进行运算
images = images.to(device)
labels = labels.to(device)
outputs = model(images) # 正向传播
loss = criterion(outputs, labels) # 计算batch(四个一打包)误差
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 打印loss信息
running_loss += loss.item() # batch的误差和
print("第%2d/%2d 轮循环,%6d/%6d 组,误差为:%.4f"
% (epoch + 1, loop, i + 1, lentrain, running_loss / i))
process.append(running_loss)
running_loss = 0.0 # 误差归零
# 模型测试==========================================
print("开始第%2d次测试===================================================" % (j + 1))
# 在训练集上测试====================================
correct = 0 # 预测正确图片数
total = 0 # 总图片数
ii = 0
for images, labels in train_set:
if ii > int(i / 10): # 训练集太多了,挑一点测试
break
ii = ii + 1
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
# 返回得分最高的索引(一组 64 个)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print("第%d轮训练集上的准确率为:%3d %%" % ((j + 1) * loop, 100 * correct / total), end=' ')
Training_accuracy.append(100 * correct / total)
# 在测试集上测试====================================
correct = 0 # 预测正确图片数
total = 0 # 总图片数
for images, labels in test_set:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
# 返回得分最高的索引(一组 64 个)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
total = 100 * correct / total
print("\t测试集上的准确率为:%3d %%" % total)
Test_accuracy.append(total)
# 模型保存==========================================
print("模型已训练完成,是否保存已训练模型(Y\\N):")
shuru = input()
if shuru == 'Y' or shuru == 'y':
torch.save(model.state_dict(), seat)
print("保存模型至%s======================================" % seat)
else:
print("未保存已训练模型")
# 绘制训练过程===========================================================
# 从GPU中拿出来才能用来画图
Training_accuracy = torch.tensor(Training_accuracy, device='cpu')
Test_accuracy = torch.tensor(Test_accuracy, device='cpu')
plt.figure(1) # =======================================
# 误差随时间变化
plt.plot(list(range(len(process))), process, label='loss')
plt.legend(loc='lower right') # 显示上面的label
plt.xlabel('time') # x_label
plt.ylabel('loss') # y_label
plt.title('loss about time') # 标题
plt.figure(2) # =======================================
# 正确率
plt.plot(list(range(len(Training_accuracy))), Training_accuracy, label='Train_set')
plt.plot(list(range(len(Test_accuracy))), Test_accuracy, label='Test_set')
plt.legend(loc='lower right') # 显示上面的label
plt.xlabel('time') # x_label
plt.ylabel('loss') # y_label
plt.title('Training_accuracy and Test_accuracy') # 标题
plt.figure(3) # =======================================
# 输出在测试集上一组(64个)的数据和预测结果===================
dataiter = iter(test_set) # 生成测试集的可迭代对象
images, labels = dataiter.next() # 得到一组数据
npimg = (tv.utils.make_grid(images / 2 + 0.5)).numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
print("实际标签:", labels)
show = ToPILImage() # 把tensor转为image
images = images.to(device)
labels = labels.to(device)
outputs = model(images) # 计算图片在每个类别上的分数
# 返回得分最高的索引
_, predicted = torch.max(outputs.data, 1) # 第一个数是具体值,不需要
# 一组 4 张图,所以找每行的最大值
print("预测结果:", predicted)
plt.show() # 显示========================================================
结果示例
训练及图像有: 60000 张。
测试集图像有: 10000 张。
已将将数据集64 个打包为一组,加快训练速度
正在加载卷积神经网络=========================================
cuda
可使用GPU加速
未检测到旧模型文件
训练次数为: 20
每过 1 轮执行自动测试以及模型保存
开始训练===================================================
基础学习率为: 0.003
第 1/ 1 轮循环, 938/ 938 组,误差为:2.2994
开始第 1次测试===================================================
第1轮训练集上的准确率为: 19 % 测试集上的准确率为: 20 %
第 1/ 1 轮循环, 938/ 938 组,误差为:2.2794
开始第 2次测试===================================================
第2轮训练集上的准确率为: 47 % 测试集上的准确率为: 47 %
第 1/ 1 轮循环, 938/ 938 组,误差为:2.0767
开始第 3次测试===================================================
第3轮训练集上的准确率为: 65 % 测试集上的准确率为: 66 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.7186
开始第 4次测试===================================================
第4轮训练集上的准确率为: 87 % 测试集上的准确率为: 88 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.3513
开始第 5次测试===================================================
第5轮训练集上的准确率为: 91 % 测试集上的准确率为: 91 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.2641
开始第 6次测试===================================================
第6轮训练集上的准确率为: 92 % 测试集上的准确率为: 93 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.2144
开始第 7次测试===================================================
第7轮训练集上的准确率为: 93 % 测试集上的准确率为: 94 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.1807
开始第 8次测试===================================================
第8轮训练集上的准确率为: 94 % 测试集上的准确率为: 95 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.1568
开始第 9次测试===================================================
第9轮训练集上的准确率为: 95 % 测试集上的准确率为: 95 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.1393
开始第10次测试===================================================
第10轮训练集上的准确率为: 96 % 测试集上的准确率为: 96 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.1262
开始第11次测试===================================================
第11轮训练集上的准确率为: 96 % 测试集上的准确率为: 96 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.1163
开始第12次测试===================================================
第12轮训练集上的准确率为: 96 % 测试集上的准确率为: 96 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.1080
开始第13次测试===================================================
第13轮训练集上的准确率为: 97 % 测试集上的准确率为: 97 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.1011
开始第14次测试===================================================
第14轮训练集上的准确率为: 96 % 测试集上的准确率为: 96 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.0954
开始第15次测试===================================================
第15轮训练集上的准确率为: 97 % 测试集上的准确率为: 97 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.0903
开始第16次测试===================================================
第16轮训练集上的准确率为: 97 % 测试集上的准确率为: 97 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.0862
开始第17次测试===================================================
第17轮训练集上的准确率为: 97 % 测试集上的准确率为: 97 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.0821
开始第18次测试===================================================
第18轮训练集上的准确率为: 97 % 测试集上的准确率为: 97 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.0789
开始第19次测试===================================================
第19轮训练集上的准确率为: 97 % 测试集上的准确率为: 97 %
第 1/ 1 轮循环, 938/ 938 组,误差为:0.0757
开始第20次测试===================================================
第20轮训练集上的准确率为: 97 % 测试集上的准确率为: 97 %
模型已训练完成,是否保存已训练模型(Y\N):
N
未保存已训练模型
实际标签: tensor([7, 2, 1, 0, 4, 1, 4, 9, 5, 9, 0, 6, 9, 0, 1, 5, 9, 7, 3, 4, 9, 6, 6, 5,
4, 0, 7, 4, 0, 1, 3, 1, 3, 4, 7, 2, 7, 1, 2, 1, 1, 7, 4, 2, 3, 5, 1, 2,
4, 4, 6, 3, 5, 5, 6, 0, 4, 1, 9, 5, 7, 8, 9, 3])
预测结果: tensor([7, 2, 1, 0, 4, 1, 4, 9, 5, 9, 0, 6, 9, 0, 1, 5, 9, 7, 3, 4, 9, 6, 6, 5,
4, 0, 7, 4, 0, 1, 3, 1, 3, 4, 7, 2, 7, 1, 2, 1, 1, 7, 4, 2, 3, 5, 1, 2,
4, 4, 6, 3, 5, 5, 6, 0, 4, 1, 9, 5, 7, 8, 9, 3], device='cuda:0')
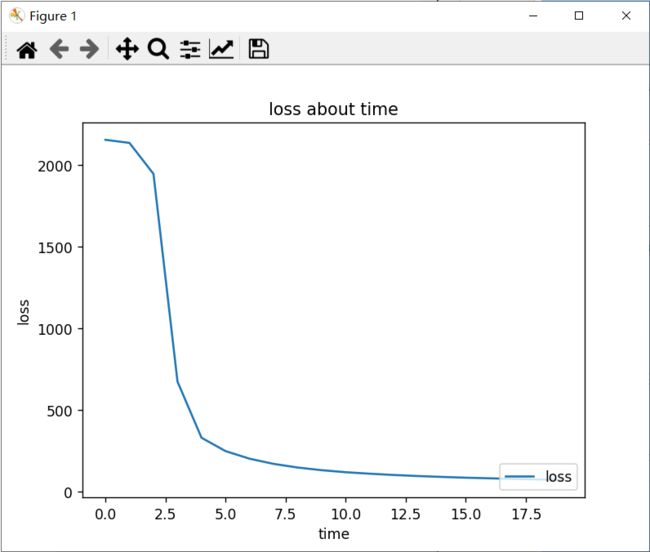
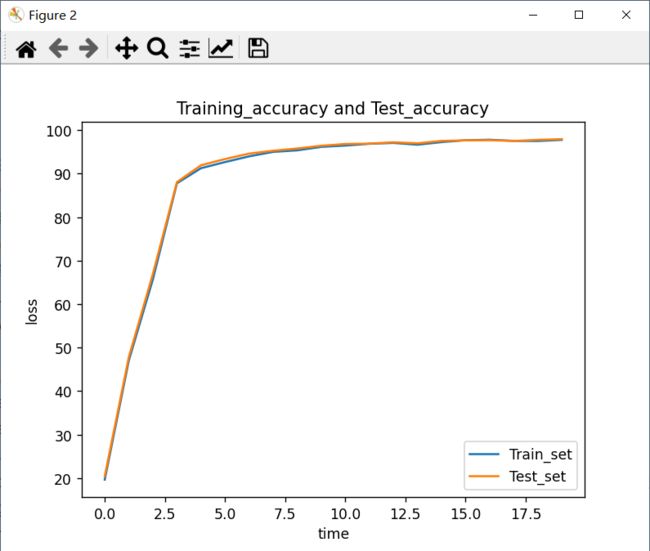
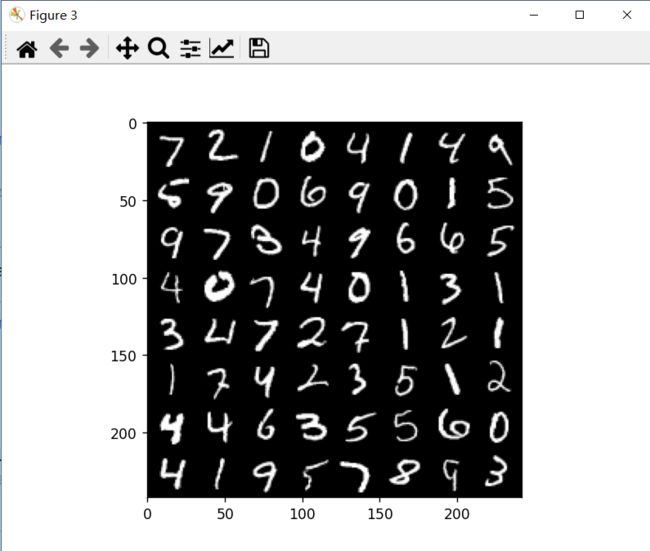
基本上15轮就能97%了
训练时间不长,这里就不放保存的模型文件了。