机器学习入门(一)--MNIST(pytorch)模型的构造以及使用(详细)
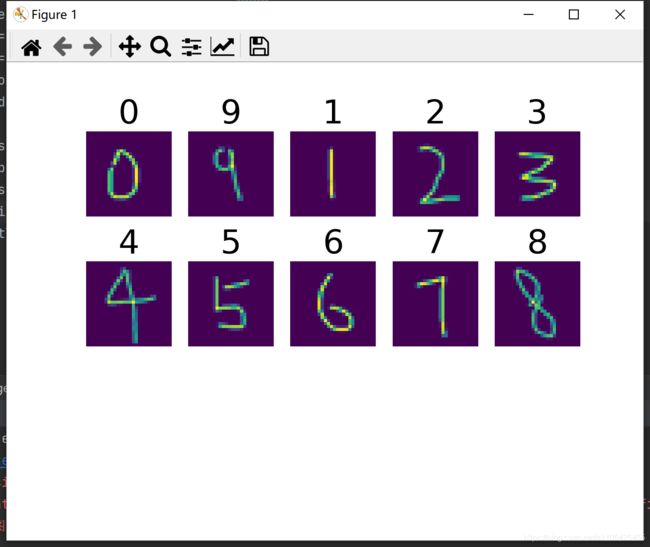
识别手写数字(MNIST数据集)
model的构建
1.加载必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
2.确定超参数
BATCH_SIZE = 64#每批处理的数据 一次性多少个
DEVICE = torch.device("cuda")#使用GPU
EPOCHS =10 #训练数据集的轮次
如果不知道有没有cuda:DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
3.图像的处理(transform)
pipeline = transforms.Compose([transforms.ToTensor(), #将图片转换为Tensor
transforms.Normalize(mean = (0.1307,),std = (0.3081,))#正则化 降低模型复杂度
])
函数解析
torchvision.transforms是pytorch中的图像预处理包。一般用Compose把多个步骤整合到一起
torchvision.transforms.ToTensor():将shape为(H, W, C)的nump.ndarray或img转为shape为(C, H, W)的tensor,其将每一个数值归一化到[0,1],其归一化方法比较简单,直接除以255即可。
torchvision.transforms.Normalize(mean = (0.1307, ),std = (0.3081, )):正则化,均值和均方差(标准差)应该指的是数据集中所有像素点的均值和方差,只写一个数值是因为只有一个通道( R G B)
4.下载,加载数据
下载
train_set = datasets.MNIST("data",train=True,download=True,transform=pipeline)
test_set = datasets.MNIST("data",train=False,download=True,transform=pipeline)
torchvision.datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False):
train : train =True : 训练集(数据中training.pt创建),= False : 测试集(数据中test.pt创建) ;
download : = True :从互联网上下载数据集,并把数据集放在root目录下;
transform:对接收的PIL图像进行预处理变换并返回
加载
#一次性加载BATCH_SIZE个打乱顺序的数据
train_loader = DataLoader(train_set,batch_size=BATCH_SIZE,shuffle=True)
test_loader = DataLoader(test_set,batch_size=BATCH_SIZE,shuffle=True)
torch.utils.data.DataLoader(dataset,batch_size,shuffle,drop_last,num_workers):
dataset: 加载torch.utils.data.Dataset对象数据(torchvision.datasets中的MNIST);
batch_size: 每个batch的大小(自己定义的超参数);
shuffle:是否对数据进行打乱;
drop_last:是否对无法整除的最后一个datasize进行丢弃(默认否)
5.构建网络模型(在这里是对导入minst数据集中的图片的处理)
class module(nn.Module):
def __init__(self):
super().__init__()#继承父类的函数
self.conv1 = nn.Conv2d(1,10,5)# 卷积 输入通道1,输出通道10,卷积核5(5*5)
self.conv2 = nn.Conv2d(10,20,3)# 10 20 3*3
self.fc1 = nn.Linear(20*10*10,500)#全连接层
self.fc2 = nn.Linear(500,10)#0到9十个数字 输出10
def forward(self,x):#定义了forward函数,backward函数就会被自动实现(利用Autograd)
input_size = x.size(0) # batch_size *1 *28 *28
x = self.conv1(x) # 输入 batch_size *1 *28 *28,输出 batch_size *10 *24 *24(28卷积5:28-5+1)
x = F.relu(x) #激活函数 使其变为非线性函数
x = F.max_pool2d(x,2,2)#池化层 保持shape不变 输出 batch_size *10 *12 *12(24/2)
x = self.conv2(x)#输出: batch_size *20 *10 *10(12-3+1)
x = F.relu(x)#激活函数
x = x.view(input_size,-1)#拉伸 -1(自动计算长度):20*10*10 = 2000
x = self.fc1(x)#输入:2000 输出:500
x = F.relu(x)#激活函数
x = self.fc2(x)#输入:500 输出:10
output = F.log_softmax(x,dim=1)#计算分类后,每个数字的概率值
return output
torch.nn.Module:继承 nn.Module(它本身是一个类并且能够跟踪状态)建立子类。
torch.nn.Conv2d(in_channels=3,out_channels=64,kernel_size=4,stride=2,padding=1)
in_channels:输入通道数;
out_channels:卷积后输出通道数;
kernel_size:卷积核 5:55 数值不一样要写(3,5) 35;
stride:步长 默认为1
在Tensorflow中都是先定义好weight和bias,再去定义卷积层,在Pytorch的nn模块中,它是不需要你手动定义网络层的权重和偏置的(nn.Functional函数就需要)
nn.Linear(in_features, out_features):全连接层(分类更加准确) 特征提取(卷积)后对子特征分类激活神经元
torch.nn.functional.relu():F.relu()是函数调用,一般使用在foreward函数里。而nn.ReLU()是模块调用,一般在定义网络层的时候使用。
torch.nn.functional.max_pool2d():池化层 取最大值
x = x.view(x.size(0), -1)简化 x = x.view(batchsize, -1):拉伸成一维 拉伸后进入全连接层
torch.nn.functional.log_softmax(x,dim=1) == log(F.softmax(x,dim=1)):对列进行非负性和归一化(和为1)处理,最后得到0-1之内的分类概率
6.定义优化
model = module().to(DEVICE)#创建模型并将模型加载到指定设备上
optimizer = optim.Adam(model.parameters())#优化函数
optimizer = optim.Adam(model.parameters(),lr = …)#优化函数(在这里使用Adam优化) lr:学习率
7.训练
def train_model(model,device,train_loader,optimizer,epoch):
model.train()#模型训练
for batch_index,(data ,target) in enumerate(train_loader):#一批中的一个,(图片,标签)
data,target = data.to(device),target.to(device)#部署到DEVICE上去
optimizer.zero_grad()#梯度初始化为0
output = model(data)#训练后的结果
loss = F.cross_entropy(output,target)#多分类计算损失函数
loss.backward()#反向传播 得到参数的梯度参数值
optimizer.step()#参数优化
if batch_index %3000 == 0:#每3000个打印一次
print("Train Epoch: {} \t Loss:{:.6f}".format(epoch,loss.item()))
model.train():如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train(),在测试时添加model.eval()。其中model.train()是保证BN层用每一批数据的均值和方差,model.eval()是保证BN用全部训练数据的均值和方差;而对于Dropout,model.train()是随机取一部分网络连接来训练更新参数,而model.eval()是利用到了所有网络连接。
enumerate():和for一起使用可以实现同时输出索引值和元素内容
optimizer.zero_grad()初始化梯度 后 loss.backward()反向传播得到参数的梯度值 再 optimizer.step()使用反向传播得到的参数
F.cross_entropy(x,y):交叉熵方法计算分类损失(多分类的一种计算算法);其第一参数的元素需要为浮点张量,不然做softmax出不了小数会报错,而第二参数的元素则必须是0-n中的某一整数
8.测试
def test_model(model,device,text_loader):
model.eval()#模型验证
correct = 0.0#正确
Accuracy = 0.0#正确率
text_loss = 0.0
with torch.no_grad():#不会计算梯度,也不会进行反向传播
for data,target in text_loader:
data,target = data.to(device),target.to(device)#部署到device上
output = model(data)#处理后的结果
text_loss += F.cross_entropy(output,target).item()#计算测试损失之和
pred = output.argmax(dim=1)#找到概率最大的下标(索引)
correct += pred.eq(target.view_as(pred)).sum().item()#累计正确的次数
text_loss /= len(test_loader.dataset)#损失和/数据集的总数量 = 平均loss
Accuracy = 100.0*correct / len(text_loader.dataset)#正确个数/数据集的总数量 = 正确率
print("Test__Average loss: {:4f},Accuracy: {:.3f}\n".format(text_loss,Accuracy))
with torch.no_grad():对于tensor的计算操作,默认是要进行计算图的构建的(可以进行梯度反传等操作),在这种情况下,可以使用 with torch.no_grad():,强制之后的内容不进行计算图构建。
pred.eq(target.view_as(pred)).sum().item():索引位置和真实值的索引位置比较是否相等
target.view_as(pred):返回被视作与给定的tensor相同大小的原tensor
pred.eq:比较是否相等 相等为1
sum():统计相等的个数 加了item只输出tensor里面的result数值,不返回其他东西 若都返回造成运行负担
loss.item():加了item只输出tensor里面的result数值,不返回其他东西 若都返回造成运行负担
9.调用
for epoch in range(1,EPOCHS+1):
train_model(model,DEVICE,train_loader,optimizer,epoch)
test_model(model,DEVICE,test_loader)
调用查看正确率后若不满意可以更改模型的参数,结构以及超参数;满意则可保存
10.保存模型
torch.save(model.state_dict(),'model.ckpt')#保存为model.ckpt
torch.save(model,’’)保存整个模型 torch.save(model.state_dict(),’’)保存训练好的权重
使用训练好的模型
MNIST数据集中的数据为黑底白字,若想用这个模型识别出手写字体具有更高的准确率,第一步需要对图片进行预处理,将白底黑字转换为黑底白字
图像预处理
import cv2 as cv
src = cv.imread('1.jpg')#读取图片
gray = cv.cvtColor(src, cv.COLOR_BGR2GRAY)
ret, binary = cv.threshold(gray, 0, 255,cv.THRESH_BINARY_INV|cv.THRESH_OTSU)#白底黑字转换为黑底白字
cv.imwrite('new1.jpg', binary)#将图像数据写入到图像文件中
cv.cvtColor(src,dst):对图像进行色彩空间的转换
src:原始图像
dst:目标图像:size与depth和原始图像要相等
cv.COLOR_BGR2GRAY:RGB/BGR与灰度、颜色转换之间的转换
cv.threshold(src,thresh,maxval,type[,dst]) : 返回2个值 第一个是处理前的 第二是处理后的
src:原始图像
thresh:最小阈值
maxval:最大阈值
cv.THRESH_BINARY_INV:反二值化阈值处理
cv.THRESH_OTSU:Otsu’s就可以自己找到一个认为最好的阈值
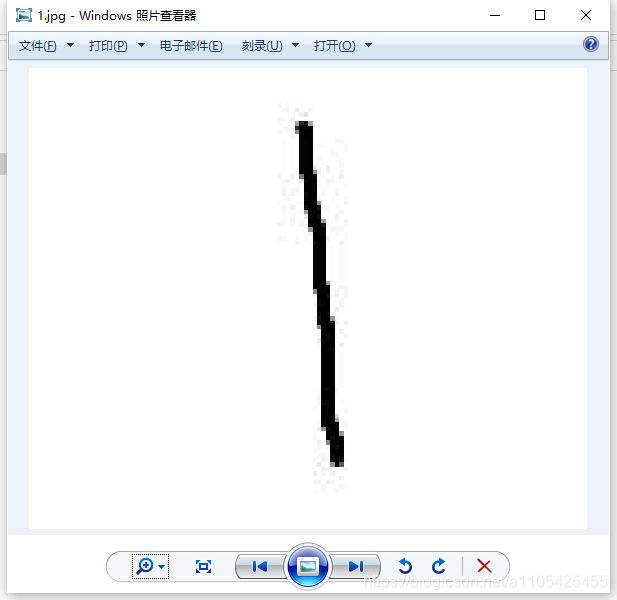
处理后
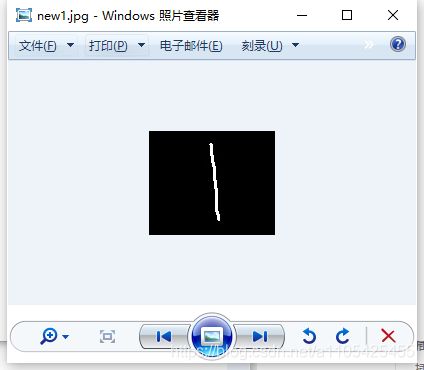
因为MNIST数据集中的图片的像素为(28,28)转换成黑底白字后还需要对图片进行尺寸操作
def imag():# 调整图片大小
im = plt.imread('new1.jpg') # 读入图片
images = Image.open('new1.jpg') # 将图片存储到images里面
images = images.resize((28,28)) # 调整图片的大小为28*28
images = images.convert('L') # 灰度化
transform = transforms.ToTensor()#转换为tentor
images = transform(images)#对图片进行transform
images = images.resize(1,1,28,28)#调整图片尺寸(四维)
尺寸调整完毕
使用模型判断
单张检测
import torch
import torch.nn as nn
import torchvision
import matplotlib.pyplot as plt
from PIL import Image
from torchvision import transforms
import numpy as np
import cv2 as cv
class module(nn.Module):
def __init__(self):
super().__init__()#继承父类的函数
self.conv1 = nn.Conv2d(1,10,5)# 输入通道1,输出通道10,卷积5*5
self.conv2 = nn.Conv2d(10,20,3)# 10 20 3*3
self.fc1 = nn.Linear(20*10*10,500)
self.fc2 = nn.Linear(500,10)#0到9十个数字 输出10
def forward(self,x):#定义了forward函数,backward函数就会被自动实现(利用Autograd)
input_size = x.size(0) # batch_size *1 *28 *28
x = self.conv1(x) # 输入 batch_size *1 *28 *28,输出 batch_size *10 *24 *24
x = F.relu(x) #激活函数 使其变为非线性函数
x = F.max_pool2d(x,2,2)#保持shape不变 输出 batch_size *10 *12 *12
x = self.conv2(x)#输出: batch_size *20 *10 *10
x = F.relu(x)
x = x.view(input_size,-1)#拉伸 20*10*10 = 2000
x = self.fc1(x)#输入:2000 输出:500
x = F.relu(x)
x = self.fc2(x)#输入:500 输出:10
output = F.log_softmax(x,dim=1)#计算分类后,每个数字的概率值
return output
def imag():
#白底黑字转换为黑底白字
src = cv.imread('1.jpg')#读取图片
gray = cv.cvtColor(src, cv.COLOR_BGR2GRAY)
ret, binary = cv.threshold(gray, 0, 255,cv.THRESH_BINARY_INV|cv.THRESH_OTSU)#白底黑字转换为黑底白字
cv.imwrite('new1.jpg', binary)#将图像数据写入到图像文件中
# 调整图片大小
im = plt.imread('new1.jpg') # 读入图片
images = Image.open('new1.jpg') # 将图片存储到images里面
images = images.resize((28,28)) # 调整图片的大小为28*28
images = images.convert('L') # 灰度化
transform = transforms.ToTensor()
images = transform(images)
images = images.resize(1,1,28,28)#处理完毕
# 加载网络和参数
model = module()#加载模型
model.load_state_dict(torch.load('model.ckpt'))#加载参数
model.eval()#测试模型
outputs = model(images)#输出结果
label = outputs.argmax(dim =1) # 返回最大概率值的下标
plt.title('{}'.format(int(label)))
plt.imshow(im)
plt.show()
imag()
多张图片使用模型检测
假设在代码根目录存在一个文件夹picture,里面有2个文件夹:original和Processed
original用来存放未处理过的白底黑字的图片
Processed用来存放将original里面照片处理后的黑底白字的照片
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
import matplotlib.pyplot as plt
from PIL import Image
import cv2 as cv
import glob
import os
class module(nn.Module):
def __init__(self):
super().__init__()#继承父类的函数
self.conv1 = nn.Conv2d(1,10,5)# 输入通道1,输出通道10,卷积5*5
self.conv2 = nn.Conv2d(10,20,3)# 10 20 3*3
self.fc1 = nn.Linear(20*10*10,500)
self.fc2 = nn.Linear(500,10)#0到9十个数字 输出10
def forward(self,x):#定义了forward函数,backward函数就会被自动实现(利用Autograd)
input_size = x.size(0) # batch_size *1 *28 *28
x = self.conv1(x) # 输入 batch_size *1 *28 *28,输出 batch_size *10 *24 *24
x = F.relu(x) #激活函数 使其变为非线性函数
x = F.max_pool2d(x,2,2)#保持shape不变 输出 batch_size *10 *12 *12
x = self.conv2(x)#输出: batch_size *20 *10 *10
x = F.relu(x)
x = x.view(input_size,-1)#拉伸 20*10*10 = 2000
x = self.fc1(x)#输入:2000 输出:500
x = F.relu(x)
x = self.fc2(x)#输入:500 输出:10
output = F.log_softmax(x,dim=1)#计算分类后,每个数字的概率值
return output
def imag():
#处理图片 文件夹original里面的白底黑字处理成黑底白字
file_original = glob.glob(os.path.join('./picture/original/','*'))#读取original文件内所有图片
for i,image_original in enumerate(file_original):#遍历图片
src = cv.imread(image_original)#读取图片
image_original = cv.cvtColor(src,cv.COLOR_RGB2GRAY)#将图片转换为灰度
ret,binary = cv.threshold(image_original,0,255,cv.THRESH_BINARY_INV|cv.THRESH_OTSU)#图片反阈值处理
cv.imwrite('./picture/Processed/new{}.jpg'.format(i+1),binary)#写入prossed文件夹 并按顺序命名
#批检测
file_Processed = glob.glob(os.path.join('./picture/Processed','*'))#读取processed里面的图片
rows = len(file_Processed)/5 + 1#每行显示5个
model = module()#加载模型
model.eval()#测试模型
model.load_state_dict(torch.load('model.ckpt')) # 加载参数
for i,image_Processed in enumerate(file_Processed):#遍历Processed的图片
image = Image.open(image_Processed).resize((28,28))#加载图片并调整图片的大小为28*28
image = image.convert("L")#灰度化处理
transform = transforms.ToTensor()#转换为tentor
image_data = transform(image).resize(1,1,28,28)#将图片转换成tentor并调整大小
output = model(image_data)#使用模型处理图片
outputs = output.argmax(dim=1)#返回最大概率值的索引
plt.subplot(rows,5,i+1)#设置子图 每行5个
plt.imshow(image)
plt.axis('off')#去除坐标轴
plt.title("{}".format(int(outputs)),fontsize = 24)
plt.show()
imag()
glob.glob(os):#获取指定目录下的所有图片
plt.subplot:子图 三个整数是行数、列数和索引值
这个model的正确率有点低,后续再使用正确率更高的model
使用残差网络RESNET
代码如下:
# 1.加载必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
import argparse
# 2.超参数
BATCH_SIZE = 32#每批处理的数据 一次性多少个
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")#使用GPU
EPOCHS =4 #训练数据集的轮次
# 3.图像处理
pipeline = transforms.Compose([transforms.ToTensor(), #将图片转换为Tensor
])
# 4.下载,加载数据
from torch.utils.data import DataLoader
#下载
train_set = datasets.MNIST("data",train=True,download=True,transform=pipeline)
test_set = datasets.MNIST("data",train=False,download=True,transform=pipeline)
#加载 一次性加载BATCH_SIZE个打乱顺序的数据
train_loader = DataLoader(train_set,batch_size=BATCH_SIZE,shuffle=True)
test_loader = DataLoader(test_set,batch_size=BATCH_SIZE,shuffle=True)
# 5.构建网络模型
class ResBlk(nn.Module): # 定义Resnet Block模块
"""
resnet block
"""
def __init__(self, ch_in, ch_out, stride=1): # 进入网络前先得知道传入层数和传出层数的设定
"""
:param ch_in:
:param ch_out:
"""
super(ResBlk, self).__init__() # 初始化
# we add stride support for resbok, which is distinct from tutorials.
# 根据resnet网络结构构建2个(block)块结构 第一层卷积 卷积核大小3*3,步长为1,边缘加1
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
# 将第一层卷积处理的信息通过BatchNorm2d
self.bn1 = nn.BatchNorm2d(ch_out)
# 第二块卷积接收第一块的输出,操作一样
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
# 确保输入维度等于输出维度
self.extra = nn.Sequential() # 先建一个空的extra
if ch_out != ch_in:
# [b, ch_in, h, w] => [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x): # 定义局部向前传播函数
"""
:param x: [b, ch, h, w]
:return:
"""
out = F.relu(self.bn1(self.conv1(x))) # 对第一块卷积后的数据再经过relu操作
out = self.bn2(self.conv2(out)) # 第二块卷积后的数据输出
# short cut.
# extra module: [b, ch_in, h, w] => [b, ch_out, h, w]
# element-wise add:
out = self.extra(x) + out # 将x传入extra经过2块(block)输出后与原始值进行相加
out = F.relu(out) # 调用relu,这里使用F.调用
return out
class ResNet18(nn.Module): # 构建resnet18层
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential( # 首先定义一个卷积层
nn.Conv2d(1, 32, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(32)
)
# followed 4 blocks 调用4次resnet网络结构,输出都是输入的2倍
# [b, 64, h, w] => [b, 128, h ,w]
self.blk1 = ResBlk(32, 64, stride=1)
# [b, 128, h, w] => [b, 256, h, w]
self.blk2 = ResBlk(64, 128, stride=1)
# # [b, 256, h, w] => [b, 512, h, w]
self.blk3 = ResBlk(128, 256, stride=1)
# # [b, 512, h, w] => [b, 1024, h, w]
self.blk4 = ResBlk(256, 256, stride=1)
self.outlayer = nn.Linear(256 * 1 * 1, 10) # 最后是全连接层
def forward(self, x): # 定义整个向前传播
"""
:param x:
:return:
"""
x = F.relu(self.conv1(x)) # 先经过第一层卷积
# [b, 64, h, w] => [b, 1024, h, w]
x = self.blk1(x) # 然后通过4次resnet网络结构
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
# print('after conv:', x.shape) #[b, 512, 2, 2]
# F.adaptive_avg_pool2d功能尾巴变为1,1,[b, 512, h, w] => [b, 512, 1, 1]
x = F.adaptive_avg_pool2d(x, [1, 1])
# print('after pool:', x.shape)
x = x.view(x.size(0), -1) # 平铺一维值
x = self.outlayer(x) # 全连接层
return x
# 6.定义优化器
model = ResNet18().to(DEVICE)#创建模型并将模型加载到指定设备上
optimizer = optim.Adam(model.parameters(),lr=0.001)#优化函数
criterion = nn.CrossEntropyLoss()
# 7.训练
def train_model(model,device,train_loader,optimizer,epoch):
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
model.train()#模型训练
for batch_index,(data ,target) in enumerate(train_loader):
data,target = data.to(device),target.to(device)#部署到DEVICE上去
optimizer.zero_grad()#梯度初始化为0
output = model(data)#训练后的结果
loss = criterion(output,target)#多分类计算损失
loss.backward()#反向传播 得到参数的梯度值
optimizer.step()#参数优化
if batch_index % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_index * len(data), len(train_loader.dataset),
100. * batch_index / len(train_loader), loss.item()))
if args.dry_run:
break
# 8.测试
def test_model(model,device,text_loader):
model.eval()#模型验证
correct = 0.0#正确率
global Accuracy
text_loss = 0.0
with torch.no_grad():#不会计算梯度,也不会进行反向传播
for data,target in text_loader:
data,target = data.to(device),target.to(device)#部署到device上
output = model(data)#处理后的结果
text_loss += criterion(output,target).item()#计算测试损失
pred = output.argmax(dim=1)#找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()#累计正确的值
text_loss /= len(test_loader.dataset)#损失和/加载的数据集的总数
Accuracy = 100.0*correct / len(text_loader.dataset)
print("Test__Average loss: {:4f},Accuracy: {:.3f}\n".format(text_loss,Accuracy))
# 9.调用
for epoch in range(1,EPOCHS+1):
train_model(model,DEVICE,train_loader,optimizer,epoch)
test_model(model,DEVICE,test_loader)
torch.save(model.state_dict(),'model.ckpt')
训练后效果明显变好