【深度学习】计算机视觉(五)——神经网络详解
文章目录
- 卷积神经网络
-
- 1 基本概念及详解
-
- 1.1 卷积
-
- 1.1.1 基本概念
- 1.1.2 影响卷积的重要参数
- 1.1.3 特征图计算公式
- 1.1.4 卷积参数共享
- 1.2 池化
- 1.3 全连接
- 1.4 感受野
- 2 卷积神经网络的过程
-
- 2.1 前向传播的过程
- 2.2 反向传播【没学会,所以没笔记】
-
- 2.2.1 全连接的反向传播
- 2.2.2 卷积层的反向传播
- 2.2.3 池化层的反向传播
- 3 经典网络
- 4 反卷积
-
- 4.1 转置卷积
- 4.2 双线性插值
- 【待学习】循环神经网络(递归神经网络)
卷积神经网络
1 基本概念及详解
卷积神经网络(CNN)
卷积神经网络基本上应用于图像数据。假设我们有一个输入的大小(28 * 28 * 3),如果我们使用正常的神经网络,将有2352(28 * 28 * 3)参数。并且随着图像的大小增加参数的数量变得非常大。我们“卷积”图像以减少参数数量。
CNN的输入和输出没什么特别之处,例如可以输入一个28×28×1的图片(注意这里参数分别表示H、W、C,因为是灰度图所以通道为1)。
1.1 卷积
1.1.1 基本概念
在提取特征的时候,由于一张图片中不同的地方有不同的特征,背景和物体的特征是不一样的,物体各部位的特征也是不一样的。我们首先会对输入的图片进行分割处理,将其分成许多个区域,每个区域中都有多个像素点,例如:

我们如何确定每个区域的特征值?在神经网络中,我们的特征值就是权重参数来表示,而在这里我们会用到的也是一个权重参数矩阵,我们的任务是找到最合适的权重参数矩阵使得特征提取的效果最好。我们把权重参数矩阵也称为滤波器。
CNN中的滤波器与加权矩阵一样,它与输入图像的一部分相乘以产生一个回旋输出。滤波器尺寸通常小于原始图像尺寸。
例如有滤波器:
与图像中一个5×5×1区域的每个3×3部分相乘以形成卷积特征。注意计算方法不是矩阵计算,而是内积计算,是将两个矩阵对应位置的数相乘然后求所有乘法结果加和。
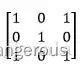

我们注意到每次计算都向后(下)移动一格,也可以自己设置步长控制向后(下)移动的距离。
计算得到的矩阵称为“特征图”。
灰度图像的计算特别简单,RGB图像也同理,根据之前学的我们知道RGB是分为三个通道,这里三个通道需要分别计算,然后将得到的三个通道的特征图相加即为最终结果。然而滤波器不只是二维矩阵这么简单,它是用三个参数存储的三维矩阵,前两个参数表示滤波器的行列数尺寸,第三个参数与通道的个数相等,也就是说对应不同的通道我们有不同的权重矩阵。
与神经网络一样,得到的特征图要加上偏置项(bias)b。
若我们用多个滤波器对同一张输入图片进行卷积操作(注意滤波器的尺寸必须一样),我们则可以得到多个特征图,然后将特征图堆叠在一起,此时得到的三维矩阵,前两个参数还是H、W,第三个参数表示卷积的深度(也就是第几层卷积)。
以上就是卷积的计算方法。得到的特征图堆叠成的三维矩阵,又可以作为输入进行再一次卷积,注意这里由于第三个参数C不再是原始数据的RGB通道,而是表示卷积层的深度,因此下一次卷积的时候,滤波器第三个参数也要与C的数值对应,这样才能保证每一层通道都对应有滤波器的一层。
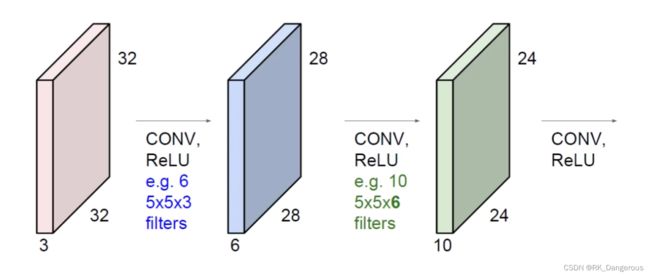
按照上面的讲解,便可以理解这张图中的内容。类似于神经网络中的隐藏层,我们可以不断地对上一层的输入进行卷积。
1.1.2 影响卷积的重要参数
- 滑动窗口步长
上面对于卷积的讲解中每次计算都向后(下)移动一格,也可以自己设置步长控制向后(下)移动的距离。当步长较小的时候,可以细粒度的提取特征,得到的特征比较丰富;当步长比较大的时候,得到的特征比较少。同时步长也会影响到结果的尺寸。
总之,步长的选择要根据实际任务,一般来说图像任务步长通常选择1。 - 卷积核尺寸
卷积核尺寸就是我上面说的那个滤波器前两个参数,显然也会影响结果的尺寸,同样,卷积核尺寸较小时提取特征是细粒度的,一般情况下选择3×3的尺寸。 - 边缘填充(Padding)
填充是指在图像之间添加额外的零层。

在卷积时,输入图像中间的像素在滤波器移动时会重复多次被计算在内,对结果的贡献较大,而边缘部分的数据只经过一次计算,越往边界的点被利用的次数越少,这显然是不公平的。为了使边界点也能被多次反复利用,我们在边界的外面填充数据,使原本在边界的点现在处于里层,能够在一定程度上弥补边界信息缺失的问题。
为什么添加的是0而不是其他数值呢?因为在卷积时,如果添加了其他数也会在运算的时候对结果产生影响,我们只需要利用被“拯救”的边缘数据,其他部分的0与滤波器中对应的数据相乘还等于0。
至于填充的层数,一般填充一层就可以,也可以为了后续运算方便自定义,视具体情况而定。 - 卷积核个数
通过设置卷积核个数我们可以控制得到多少特征图(无论是中间需要堆叠的还是最后输出的)。注意卷积核中的值是不一样的。
1.1.3 特征图计算公式
最后附上特征图尺寸的计算公式:
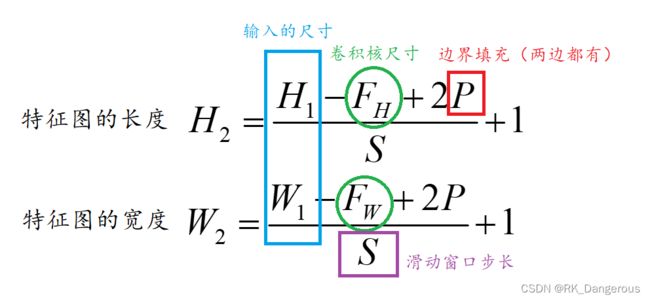
我是这样解读公式的:最后一个+1理解为,无论前面如何滑动,最后一次计算总是和输入网格的右边界对齐。因为最后一次是固定的,我们只需要在输入网格中减去一个卷积核的尺寸,然后看剩下的网格中足够我们移动几次,也就是看能有几次移动卷积核左边界,所以用H-F+2P得到剩余的网格,再除以s表示这些网格经得起几次平移,每次平移都会计算出一个特征值,再加上最右边的那次,就是总的特征值个数。
这样的理解只是为了便于公式的记忆,实际上它是挨着滑动的,直到卷积核窗口落在图像外面时,不再进行操作。所以就算有舍弃,也是舍弃最右边剩下的,不要混淆。
例如有一个14×14×1的区域,设置卷积核尺寸为3×3,padding=1,步长为2,根据公式算得H2=W2=7。图解如下:

下面用一个例题检验一下:输入数据是32×32×3的图像,用10个5×5×3的filter来进行卷积操作,指定步长为1,边界填充为2,问最终输入的规模为?
(答案是32×32×10)
1.1.4 卷积参数共享
如果给每个区域都选择不同的卷积核,那么数据的规模也是非常大的,而且容易出现过拟合问题。所以我们利用参数共享原则,对于每个区域使用的卷积核都不变。
例如,我们有一个32×32×3的图像,使用10个5×5×3的滤波器进行卷积操作,由于每个区域的使用的滤波器都一样,我们需要权重参数的个数为10*5*5*3=750,再加上每个特征图都需要一个偏置参数b,10个滤波器共需要10个b,所以一次卷积共需要760个参数。
1.2 池化
卷积得到的特征可能会非常多,我们使用池化(POOLING)对它进行压缩。注意池化可以改变特征图的长和宽,但是不能减少特征图的个数。
通常在卷积层之间定期引入池层。这基本上是为了减少一些参数,并防止过度拟合。
MAX POOLING
最常见的池化类型是使用MAX操作的滤波器尺寸(2,2)的池层,它将取原始图像的每个4×4矩阵的最大值。
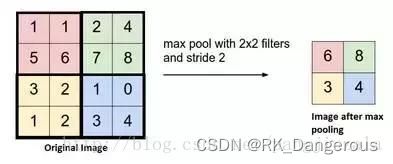
为什么选择最大值呢?在神经网络中,值越大说明我们认为这个特征是越重要的,选择最大的值就相当于我们只挑选那些重要的。
还可以使用其他操作(如平均池)进行池化,但是最大池数量在实践中表现更好。
1.3 全连接
全连接(Fully Connected,FC)网络结构在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”。映射到样本标记空间的作用。
全连接层将特征提取得到的高维特征图映射成一维特征向量,该特征向量包含所有特征信息,可以转化为最终分类成各个类别的概率。
我们可以把全连接层看成一次特殊的卷积,也是通过一个滤波器改变特征的形状的。例如我们有4096个3x3x5的输出,我们想得到4096×1的列向量,可以通过一个3x3x5的滤波器去卷积。(可能表述不准确,但是大致意思理解即可)
1.4 感受野
我们卷积是把一个滤波器大小的正方形区域的数据浓缩成一个数据,感受野就是对于某一个位置的数据向前推1次或多次卷积,即这个数据浓缩n次之前的尺寸。
比如一个5×5区域经3×3的卷积核卷积两次后得到的是1×1的区域,那么这个1×1的区域感受野就是5×5。

我们希望一个特征是经过多方面因素的综合才得到的,所以我们希望感受野越大越好。
假设我们堆叠了3个3×3的卷积层(就是进行了3次卷积),并且保持滑动窗口的步长为1,其感受野就是7×7。但是如果我们直接用一个7×7的卷积核也可以得到77×7的感受野,这种情况该如何选择呢?假设我们需要得到C个特征图,如果用一个7×7×C的卷积核,我们需要的参数为C×(7×7×C)=49C²,如果用3×3×C的卷积核堆叠三次,我们需要的参数为[(3×3×C)×C]×3=27C²,显然后者不仅参数少,而且特征提取是更细致的。
2 卷积神经网络的过程
2.1 前向传播的过程
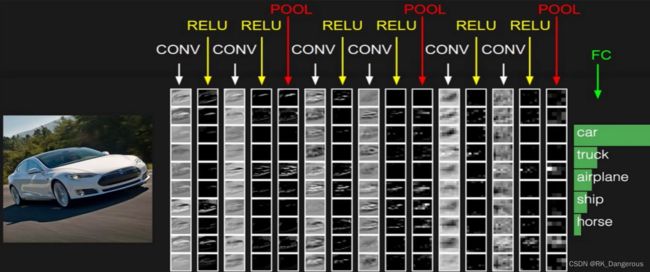
根据上图我们了解卷积神经网络的过程。类似普通的神经网络,每次卷积(CONV)之后都需要激活函数(通常是RELU),池化操作有规律地穿插在每次卷积中,最后通过全连接计算每个分类的概率。如果特征图的尺寸是32×32×10,由于上图是5分类问题,FC层会得到一个[10240, 5]的结构表示每个特征对应每个分类的概率。这就是大致过程,具体计算稍后详细学习。
首先说明一下,我们认为神经网络是有很多层的结构,在卷积神经网络中,只有具有参数的计算才能叫做“层”,例如卷积时有卷积核和偏置参数,所以卷积是一层;全连接中也有卷积核,所以全连接也是一层;而池化无参数、激活函数也无参数。故上图中的网络我们认为有7层。
我的一些感悟:
通过上面对过程的了解,我认为卷积神经网络更突出我们对每个特征值的判断,在普通的神经网络中,我们直接是把输入的一系列数据直接去与权重进行运算,虽然运算的过程可能会分成好几步,对于某些权重为0的位置虽然没有考虑进去,但是对我们来说就是视为一个整体去理解的。而在卷积神经网络中,我们总是能直观地感受到每个特征值,算出特征值后再去与对应的激活函数计算,都是在网格中然后对值去进行操作,直到最后全连接也是根据值去计算概率,整个过程都是针对特征去操作的。
卷积层可以有目的的学习线条、轮廓和局部特征
然而卷积神经网络和普通的神经网络不是对立的两个类别,我口中“普通的神经网络”应该就是全连接神经网络。卷积神经网络对特征处理之后,我们会得到一张图片的特征列向量(我自己取的名字),若特征列向量长度为n,你可以批量输入m张图像,得到一个具有n行m列的输入X。在全连接层中对我们新的输入“X”进行之前讲过的处理,经过若干个隐藏层和输出层计算概率。
2.2 反向传播【没学会,所以没笔记】
卷积神经网络一般会借助 TensorFlow 或者 PaddlePaddle 来开发,仅需要开发正向传播,反向传播会自动生成,所以一般不要求掌握。
2.2.1 全连接的反向传播
在之前的反向传播中,我没有详细地学习过反向传播是如何实现的,所以在这里我希望能够完全弄懂。
求和的公式:
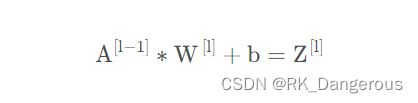
其中,上角标[l]表示第l层,上角标[l-1]表示l的上一层,即l-1层。A为上一层的输入即特征图,W为卷积核,b为偏置矩阵,Z为一次卷积得到的结果。注意:

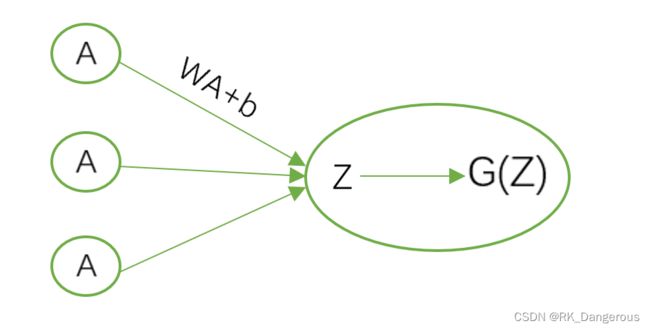
这是最后一层的输出,G(Z)是经过激活函数变换后得到的值。因为变量实际上是W和b,所以损失函数虽然是用G(Z)表示的,但是整理到坐标上面,实际上还是W和b作为坐标轴。我们要求损失函数的最小值,就要求出每个维度的最小梯度,即dW和db(d表示梯度)。如果损失函数用F(x)表示:

同理
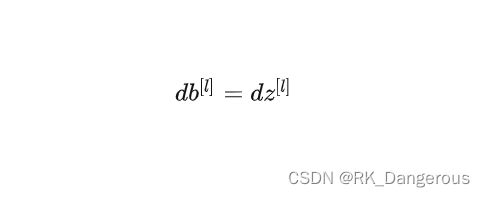
卷积神经网络由于表达式一样,所以算法也是一样的。


得到公式了,然后呢?
2.2.2 卷积层的反向传播
2.2.3 池化层的反向传播
3 经典网络
- AlexNet
2012年的常用网络,但是现在已经不常用了,我觉得熟悉名字即可。 - Vgg
Vgg有不同的版本,通常是16层或者19层的网络,它相对于AlexNet来说卷积核的大小比较小,也就是特征提取更细致。还有一个特点是,池化后通过添加特征图的个数去弥补特征图尺寸的减小。此外,由于它的层数和特征图增加、更加复杂,运算时间也很长。
Vgg层数的增加,使加入的非线性变换也随之增多(因为使用激活函数的次数变多)。 - Resnet(残差网络)
按照一贯的想法,深度学习肯定是越深学习效果越好,但是在卷积神经网络中,由于我们是进行特征的提取,在已经很拟合的基础上再去提取特征,再加上我们不断池化,反而不一定能获得更好的效果。
残差网络提出了一个“同等映射”,对于添加之后会降低我们正确率,即效果不好的卷积层,我们不使用它。但是已经添加的层,我们是没有办法删除的,那怎么办呢?
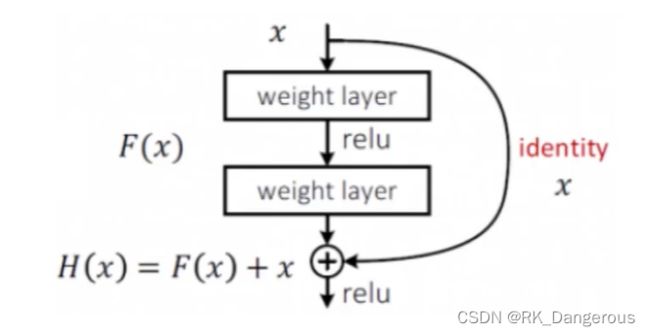
通过添加旁路,将可能会降低正确率的第n层(或不止一层)加上之前第n-1层已算出的特征值x,表示为n+1层的结果,在我们不断更新权重的过程中,如果发现这层起不到积极作用,只需要把这层的权重设置为0,在后续的卷积中这层就相当于被剔除了。
4 反卷积
反卷积又称转置卷积(Transposed Convolution)、上采样(Upsampled )。当我们用神经网络生成图片的时候,经常需要将一些低分辨率的图片转换为高分辨率的图片,如下所示:
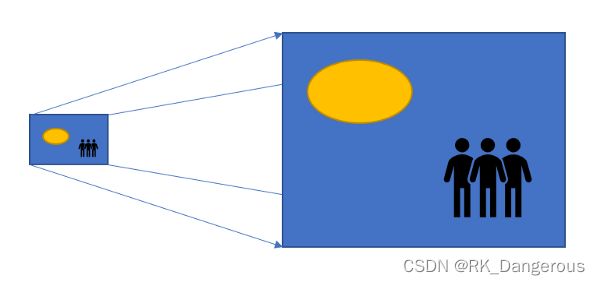
通过之前对卷积的学习,我们可以认为一个卷积操作是一个多对一(many-to-one)的映射关系,比如在一个3×3的卷积核作用下用输入图像的9个值计算得到1个值;而反卷积则是一个一对多(one-to-many)的映射关系,将输入矩阵中的一个值映射到输出矩阵的9个值。
如何进行反卷积呢?例如现在有卷积操作: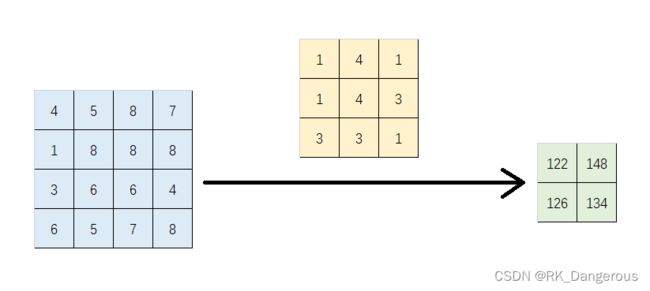
一个4×4的矩阵经3×3的滤波器后得到2×2的输出,我们通常是用滤波器在输入图像中滑动得到输出,但是将这个过程换种角度思考,把它与矩阵的乘法联系在一起。我们无法用4×4的矩阵与3×3的矩阵相乘得到2×2的矩阵,但是根据卷积的过程,我们理解到它是简单的乘法和加法操作,和矩阵的计算类似,所以我们把它变成另一种形式。以输出图像的第一个值“122”为例,我们设计一个1×9的卷积核与9×1的输入矩阵相乘,则可以得到1×1的输出。

但是把输入图像拆成4个9×1的矩阵肯定很复杂,类似上图的操作,我们可以把用不到的值设置为系数为0,仍以输出图像的第一个值“122”为例。
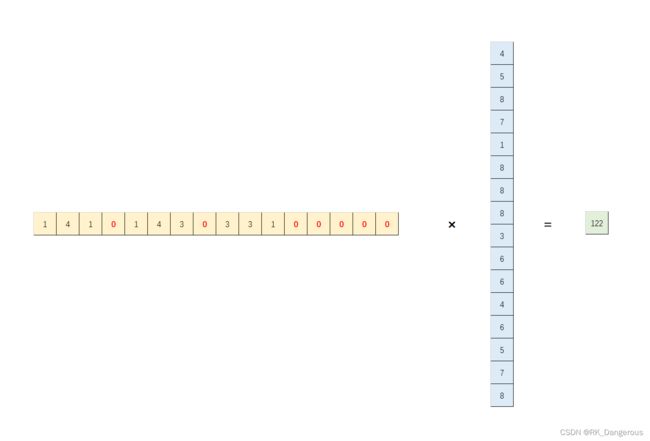
这样输入图像就可以统一,只改变卷积核补0的位置即可,其他三个输出同理,则我们可以用4×16的卷积核矩阵与16×1的输入图像矩阵相乘,得到4×1的输出矩阵。

如此得到的输出矩阵,变换为2×2即可。从这个角度理解卷积后,我们就可以更快地理解反卷积的过程。仍以这个例子,反卷积就是我们已知4×1的输出矩阵,要通过设计卷积核得到16×1的输入矩阵。按照矩阵的乘法规律,我们可以猜测用一个16×4的卷积核与4×1的输出矩阵相乘,即可得到16×1的输入矩阵。我们可以简单将原来4×16的卷积核进行转置去设计反卷积的卷积核,这也就解释了为什么反卷积又叫转置卷积(注意与逆矩阵不同,设置转置矩阵无法得到原始的输入图像,只是提供了矩阵形状,一般情况下卷积是不可逆的)。我也不知道该怎么解释把转置后的矩阵再变回最开始的3×3,反正也不重要,我就不详细阐述了,但是看了下面的过程就大概知道,它就是这么推出来的。
4.1 转置卷积

换回原来的角度,转置卷积其实和卷积一样,可以看成是通过填充0构造了一个更大的输入进行卷积。还是举之前的例子(由于之前得到的数值太大了,简化了一下):
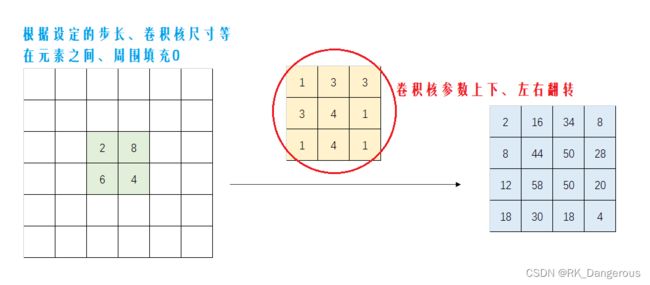
填充0的方式为:
- 在输入特征图的元素间填充
s-1行(列) - 在输入特征图的四周填充
k-p-1行(列)
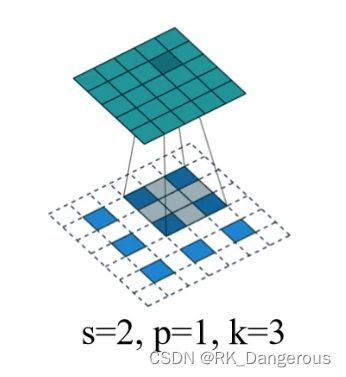
以本图为例,输入的是一个3×3的矩阵,s设置的步长不是卷积时的步长,而是指扫过原图(实际的蓝色区域)需要走的步长;p可以理解为正向卷积时的填充,由于当时填充了p个0层,所以在反向卷积的时候要输出填充前的特征图(即减去0层),所以p越大这里填充的0越少、输出的特征图尺寸越小。
输出的特征图尺寸:

化简后为:
4.2 双线性插值
我的理解,双线性插值的作用和转置卷积类似,能够放大图片(还原图片尺寸)。采用内插值法,即在原有图像像素的基础上,在像素点值之间采用合适的插值算法插入新的元素。
线性插值法(linear interpolation):
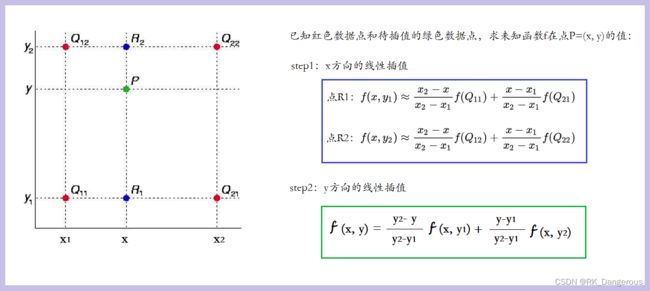
线性插值法是指使用连接两个已知量的直线来确定在这个两个已知量之间的一个未知量的值的方法。假设已知两个坐标(x0,y0)和(x1,y1),求该区间内某一位置x在直线上的值:

双线性插值:
双线性插值是插值算法中的一种,是线性插值的扩展。利用原图像中目标点四周的四个真实存在的像素值来共同决定目标图中的一个像素值,其核心思想是在两个方向分别进行一次线性插值。
【待学习】循环神经网络(递归神经网络)
22)循环神经元(Recurrent Neuron)
——循环神经元是在T时间内将神经元的输出发送回给它。如果你看图,输出将返回输入t次。展开的神经元看起来像连接在一起的t个不同的神经元。这个神经元的基本优点是它给出了更广义的输出。
23)循环神经网络(RNN)
——循环神经网络特别用于顺序数据,其中先前的输出用于预测下一个输出。在这种情况下,网络中有循环。隐藏神经元内的循环使他们能够存储有关前一个单词的信息一段时间,以便能够预测输出。隐藏层的输出在t时间戳内再次发送到隐藏层。展开的神经元看起来像上图。只有在完成所有的时间戳后,循环神经元的输出才能进入下一层。发送的输出更广泛,以前的信息保留的时间也较长。
然后根据展开的网络将错误反向传播以更新权重。这被称为通过时间的反向传播(BPTT)。
24)消失梯度问题(Vanishing Gradient Problem)
——激活函数的梯度非常小的情况下会出现消失梯度问题。在权重乘以这些低梯度时的反向传播过程中,它们往往变得非常小,并且随着网络进一步深入而“消失”。这使得神经网络忘记了长距离依赖。这对循环神经网络来说是一个问题,长期依赖对于网络来说是非常重要的。
这可以通过使用不具有小梯度的激活函数ReLu来解决。
25)激增梯度问题(Exploding Gradient Problem)
——这与消失的梯度问题完全相反,激活函数的梯度过大。在反向传播期间,它使特定节点的权重相对于其他节点的权重非常高,这使得它们不重要。这可以通过剪切梯度来轻松解决,使其不超过一定值。
参考:
深度学习入门基础概念
【神经网络】学习笔记九—学习率浅析
神经网络的归一化(batch normalization)
我居然3小时学懂了深度学习神经网络入门到实战,多亏了这个课程,看不懂你打我!!!
【深度学习】全连接层
深度学习系列5:卷积神经网络(CNN),图像识别的利器
反向传播算法详解
深度学习系列6:卷积神经网络的反向传播
反卷积详解
转置卷积(transposed convolution)
转置卷积(Transposed Convolution)
深度学习之----双线性插值,转置卷积,反卷积的区别与联系
【转】FCN中反卷积、上采样、双线性插值之间的关系
上采样、下采样到底是个啥