【多目标跟踪论文阅读笔记——2021年CVPR论文粗读记录】
[阅读心得] 多目标跟踪经典论文——2021CVPR论文粗读记录
- 前言
- 一、学习策略类
-
- QDTrack
- 二、Temporal-Spatial 类
-
- TADAM
- Alpha-Refine
- TraDes
- CorrTracker
- 三、Motion-model 类
-
- Track Management & Occlusion Handling
- ArTIST
- 四、Siamese-based类
-
- SiamMOT
- SOTMOT
- TrSiam/TrDiMP
- 五、Graph-based类
-
- LPC
- GMTracker
- 六、BenchMark类
-
- CroHD
- DroneCrowd
- GMOT-40
- 七、多模态类
-
- MM-DistillNet
前言
日志:
12月15日:按照魏师兄的指导,逐步阅读2021年CVPR跟踪相关论文,粗读第一遍并整理其创新点、实现方法和诠释在此,争取3天内读完至少10篇。
12月16日:整理粗读完3篇,发现transformer机制的重要性,明天赶紧精读一下!
12月17日:整理粗读完1篇,学transformer,沐神讲的太好了,强烈推荐链接
12月18日:整理粗读完2篇
12月19日:学习了ViT,对视觉transformer理解提升
12月20日:精读了TransTrack,笔记链接
12月21日:整理粗读完2篇
12月22日:整理粗读完2篇
12月23日:整理粗读完1篇,精读了Trackor++(笔记链接)
12月24日:修电脑,停了一天
12月25日:整理粗读完3篇,只剩下2篇BenchMark类文章,就全部读完了!!明天一并弄完。
12月27日:哈哈哈再一次食言了,又拖了一天弄完,并且将论文按照主要改进依据进行了分类,方便后面查找,本文基本完成,下周目标读完自动驾驶领域相关论文并整理,留坑
一、学习策略类
QDTrack
[论文]Quasi-Dense Similarity Learning for Multiple Object Tracking
[代码]https://github.com/SysCV/qdtrack

创新点: 提出了一种多正样本的相似度学习方法,以此增强模型的区分特征(REID)能力,进而提升总体的跟踪性能。且本方法能够实现端到端训练,简化了训练过程。推理速度很快,在MOT17上可以达到FPS20+。
为什么: 作者认为目前MOT领域对目标外形特征的利用程度不够,只使用了稀疏的Ground True框来训练分辨外形特征,导致了学习效果不够令人满意。
怎么做: 首先,设计了一种学习规则,让更多样本投入外形网络(REID)的学习过程中,通过加大考虑的样本数量,提供了更多的正样本和困难负样本(hard negative),从而提高了外形特征的学习能力。此外,为了适应新的外形特征模型,在associate阶段设计了一种新的距离衡量方法Bi-direction Softmax,取代了之前用的余弦距离(Cosine)
二、Temporal-Spatial 类
TADAM
[论文]Online Multiple Object Tracking with Cross-Task Synergy
[代码]https://github.com/songguocode/TADAM

创新点: 在Trackor++的基础上,提出了一种同时增强 位置预测 和 特征关联 的模型,面对遮挡情况是具有更强的鲁棒性。此外,位置预测和特征关联的功能在此模型中是相互促进的,而不像先前工作中是分离的。在public detector下达到了SOTA的效果。
为什么: 作者提出目前提升DBT范式下跟踪主要有两个方向:一是增强位置检测、二是增强数据关联,但是之前的工作往往只进行一个方面或者两方面独立进行,作者通过举例论证了这样带来的提升是有限的,而二者应该相辅相成。
怎么做: Trackor++的position prediction基础上,考虑到同一目标在t帧时应用t-1的bbox进行回归时,框内可能遮挡物占主要,所以利用Target Attention模块和Distractor Attetion模块提取纯净的目标特征,保证bbox回归的准确性,减小飘逸。同时,采用特定的refference管理方法配合使用。
Alpha-Refine
[论文]Alpha-Refine: Boosting Tracking Performance by Precise Bounding Box Estimation
[代码]https://github.com/MasterBin-IIAU/AlphaRefine

创新点: 提出了一个即插即用的模块Alpha-Refine(AR),能够获得更精准的box估计,从而提升初始跟踪算法的性能,且保证实时性。
为什么: 认为尽可能多地获得且保存细节空间信息(detailed spatial information)是提升跟踪器box质量的必要条件,目前已有的模块做的不够好。
怎么做: 采用pixel-wise correlation 和 key-point style prediction head以更好地获得空间信息,采用auxilary mask head促进网络提取空间信息并推理更精细的box。
TraDes
[论文]Track to Detect and Segment: An Online Multi-Object Tracker
[代码]https://jialianwu.com/projects/TraDeS.html

创新点: 作者将代价度量(Cost Volume)引入MOT,提出了一种实时的联合检测和跟踪的模型TraDes,利用跟踪结果促进检测,从而使检测部分和跟踪部分共同促进。提出了一种联合跟踪、检测的新baseline。
为什么: 目前的Joint-Detection-and-Tracking范式主要存在两个问题:1)虽然Detect和Track的backbone是共用的,但是检测部分独立进行,没有从Track部分借力。 2)REID loss和Detection Loss存在矛盾,ReID强调扩大类内方差,而Det强调扩大类间方差、缩小类内方差,二者目的相反。
怎么做: 按点为单位提取reid embedding的特征图,对相邻两帧特征图计算四维Cost Volume,并通过CVA模块进行时空上的位移估计,随后利用得到的位移估计,将之前帧的特征图传播到当前帧特征图上,以增强当前帧特征,从而增强检测性能
CorrTracker
[论文]Multiple Object Tracking with Correlation Learning

创新点: 提出了CorrTracker网络,通过correlation learning的方式(quary-key机制),在空间上增加了对目标周围特征信息的利用、在时间上增强了对前序信息的学习,另外提出了一种自监督学习的方式训练模型。
为什么: 空间上,目前的跟踪算法仅仅利用目标本身的特征信息,对于目标密集,相似度高的场景很容易出错;时间上,目前的跟踪算法大部分仅仅检测的是当前帧图片中的目标,并没有充分利用时序信息
怎么做: 空间局部相关层+多级金字塔,时间相关性学习,自监督特征学习
备注: 赶紧去补一下transformer、quary-key机制,太菜了,具体原理看不懂!!!
三、Motion-model 类
Track Management & Occlusion Handling
[代码]Improving Multiple Pedestrian Tracking by Track Management and Occlusion Handling

创新点:
- 提出了一种新的遮挡处理策略,能够准确地建模出遮挡与被遮挡目标之间的关系,并且不依赖于单独的REID模型
- 改进了一种基于回归方法的轨迹管理策略,避开了漏检测问题,解决了轨迹从视野边界离开的问题。
为什么:
- 目前面对严重遮挡的场景,大多MOT方法使用REID模型应对。但是检测到的被遮挡目标中,存在遮挡物作为干扰,据此提取到的特征不足以作为可靠的reid信息使用。
- 目前轨迹管理大多使用一个阈值判断是否激活一条轨迹,但是运动模糊、多种遮挡、目标部分离开视野等情况也会导致低于阈值,从而漏掉跟踪
怎么做:
- 针对目标相互遮挡,设计一个几何约束:如果被遮挡目标的估计位置和再次出现位置相差不大就重新激活之前的ID,并且利用相机运动模型提高精度。
- 针对目标出框,设计一个几何约束:如果bbox在边界消失,而且速度向量朝外,就终止这个轨迹,防止新人进来之后还用这个ID
ArTIST
[论文]Probabilistic Tracklet Scoring and Inpainting for Multiple Object Tracking

创新点: 提出了一种基于随机自回归的运动模型,ArTIST。其能够显式地学习多模态下的自然运动轨迹。从而给行人轨迹打分并依次进行跟踪。该方法在面对漏检测、目标遮挡等情况时表现良好,IDs,IDF1等指标上达到了SOTA
为什么: 目前的DBT和JDT范式,都不能很好地在遮挡情况下保持ID,因而容易发生ID Switch现象。
怎么做: 对于完整轨迹(截至上一帧没有断),直接预测当前帧可能出现的概率分布。对于不完整轨迹,先用设计的运动模型尝试多种补全方式、取评分最高的补全后的完整轨迹预测当前帧可能出现的概率分布。随后将这些概率分布与当前帧检测框进行KM匹配。
四、Siamese-based类
SiamMOT
[论文]SiamMOT: Siamese Multi-Object Tracking
[代码]https://github.com/amazon-research/siam-mot
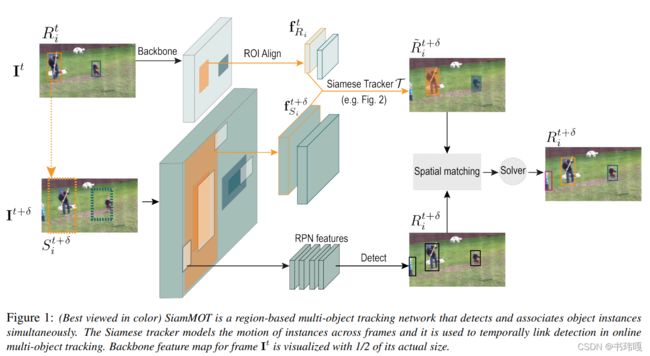
创新点: 受到单目标追踪下的Siamese系网络启发,设计了一个region-based的运动建模模型,有显式和隐式两种形式,并根据此motion model设计了多目标跟踪网络SiamMOT。证明了运动模型估计对MOT的重要性。
为什么: 现有的网络引入appreance之后不够快,不满足实时性,仅仅利用motion的话,SORT做的不够好,所以提出一种更好利用motion的网络
怎么做: 使用孪生网络来估计两帧之间的运动情况,其中隐式结构用到了MLP,显式用到了CNN
SOTMOT
[论文]Improving Multiple Object Tracking with Single Object Tracking

创新点: 将最近在SOT领域广泛应用的discriminative网络迁移到了MOT领域,在MOT20上表现超过SOTA,同时在性能和精度上表现优异
为什么: 目前主流的MOT方法(JDE, FairMOT)是依靠REID模型提取外观特征,但是在目标密集、干扰和遮挡频繁出现场景下会性能遇到了瓶颈。
怎么做: 将SOT中基于岭回归(ridge regression based)的辨别模型(discriminative model)迁移过来,在CenterNet的基础上添加一个SOT分支,为当前帧每一个target单独进行跟踪。
TrSiam/TrDiMP
[论文]Transformer Meets Tracker:Exploiting Temporal Context for Robust Visual Tracking
[代码]https://github.com/594422814/TransformerTrack

创新点: 提出了一种用于单目标跟踪领域,基于Transformer机制的模型,充分利用了视频跟踪中时序性的特点,多项指标达到SOTA
为什么: 视频帧与帧之间具有紧密的时序性关系,而目前的跟踪算法大多忽略的这一重要特性
怎么做: 利用Transformer机制能够学习时序语景的能力完成跟踪任务,将历史帧集合Template set作Encoder输入,将当前待搜索帧作为Search pacth输入到Decoder,两部分并行,最后用孪生网络(Siamese)的方式比对找到目标物体
五、Graph-based类
LPC
[论文]Learning a Proposal Classifier for Multiple Object Tracking
[代码]https://github.com/daip13/LPC_MOT

创新点: 提出了一种新的data association方法,基于自创的图生成结构和GCN网络。
为什么: 目前的association方法大多使用手工设计特征,既不方便,也不能很好地应对复杂场景。
怎么做: 使用一种自主设计的图帧间图生成方式,并且使用可学习的GCN网络完成对图affinity matrix的生成,最后基于一些跟踪任务的基本约束处理affinity matrix完成匹配。
GMTracker
[论文]Learnable Graph Matching: Incorporating Graph Partitioning with Deep
Feature Learning for Multiple Object Tracking
[代码]https://github.com/jiaweihe1996/GMTracker

创新点: 提出了一种基于图神经网络的association方法,不仅考虑帧间的不同点的匹配,还考虑到了帧内不同点之间的联系作为匹配的依据
为什么:
- 目前的association方法大多会忽略轨迹、帧内目标的语义信息
- 端到端的association仅仅依靠网络拟合数据的能力,没有把基于优化思想的方法的优势结合起来
- 基于图的优化方法需要单独的网络提取特征,应对不同情况需要重新训练
怎么做:
- 数学上建立新的最优化公式,既考虑帧间相似度又考虑帧内不同目标的相似度做最优化方法。
- 使用GCN网络实现上述公式,并建立一种可微的图匹配层完成最后的匹配。
P.S. 需要一定的凸优化知识等数学功底才能理解这一方法的具体实现…
六、BenchMark类
CroHD

[论文]Tracking Pedestrian Heads in Dense Crowd
[代码]https://project.inria.fr/crowdscience/%20project/dense-crowd-head-tracking/
创新点:
- 提出了一个密集人群头部数据集,CroHD;
- 提出衡量跟踪器性能的新指标,IDEucl;
- 提出了对应的检测和跟踪baseline:HeadHunter(for Det), HeadHunter-T(for Track)
为什么: 随着行人跟踪场景中,人群的密度越来越高,会发生大量的重叠(occlusion)现象,这极大地影响了模型对行人这一整体的检测能力。因此希望重燃(rekindle)头部检测这条路。
怎么做:
- 数据集、评价指标总的来说是关于密集场景的行人头部目标的,略
- 检测网络中,backbone使用Context Sentitive Prediction结构、转置卷积上采样提高分辨率等方式解决head目标密集且相似、尺寸过小的问题
- 跟踪部分中,采用基于蒙特卡洛原理的 Particle Filter 估计目标位置,Enhances Correlation Coefficient Maximization补偿相机抖动,采用基于色彩直方图的reid模块提取外形特征
DroneCrowd
[论文]Detection, Tracking, and Counting Meets Drones in Crowds: A Benchmark
[代码]https://github.com/VisDrone/DroneCrowd

创新点:
- 建立了一个基于无人机视角拍摄的大型跟踪检测数据集,DroneCrowd
- 提出了一种检测、跟踪一体的网络STNNet作为baseline,适应无人机视角下密集目标的场景。
- 设计了一种新的损失函数, Neighbor Context Loss,能够对连续帧的相邻目标的关系进行学习,有助于检测和跟踪
为什么: 无人机视角下的跟踪、检测任务的主要挑战在于:目标的视角和尺寸变化大、背景复杂、小目标众多。但是目前这一场景下的数据集大多还停留在静止帧、独立图片组成的数据集阶段,没有包含时序信息的视频流图片构成的大规模数据集。
GMOT-40
[论文]GMOT-40: A Benchmark for Generic Multiple Object Tracking
[代码]https://github.com/Spritea/GMOT40

创新点:
- 提出了一个通用多目标检测、跟踪数据集——GMOT-40,包含了40条标注好的序列,由数目均衡的10个种类的目标组成
- 提出了one-shot的网络用于跟踪GMOT的baseline。不同于我们常规理解的MOT算法,这是一种model-free思想的跟踪。这种算法要求不需要预训练,给定第一帧的一个目标作为模板,后续找到并跟踪与模板同类的所有目标。
为什么: 目前的MOT算法大多专注于对特定的一类目标跟踪(如行人、汽车、细胞等),故经常会利用这一特定类别目标的运动模式(motion pattern)作为先验或者需要预训练模型来进行跟踪。这限制了MOT的应用范围和发展。
七、多模态类
MM-DistillNet
[论文]There is More than Meets the Eye: Self-Supervised Multi-Object Detection and
Tracking with Sound by Distilling Multimodal Knowledge

创新点: 通过对RGB、深度图像、热成像这三部分进行学习并知识蒸馏,再对声音信号进行自监督学习,最终利用多模态的手段进行多目标跟踪任务,以达到更好的鲁棒性。
为什么: 仅仅依靠RGB图像做多目标跟踪鲁棒性不好,出现遮挡等情况性能较差。
怎么做: 详见论文吧,这个感觉和标准的MOT有些距离,所以没细看,但是方向和立意我觉得都不错…