基于MATLAB的Kmeans聚类算法的仿真与分析
目录
一、理论基础
二、核心程序
三、测试结果
一、理论基础
K-means聚类算法是硬聚类算法,是典型的基于原型的目标函数聚类分析算法点到原型——簇中心的某种距离和作为优化的目标函数,采用函数求极值的方法得到迭代运算的调整规则。K-means聚类算法以欧氏距离作为相异性测度它是求对应某一初始聚类中心向量![]()
K-means聚类算法采用误差平方和准则函数作为聚类准则函数,误差平方和准则函数定义为:

和准则函数可以看出E是样本与聚类中心差异度之和的函数,样本集X给定的情况下E的值取决于c个聚类中心。E描述n个样本聚类成c个类时所产生的总的误差平方和。显然,若E值越大,说明误差越大,聚类结果越不好。因此,我们应该寻求使E值最小的聚类结果,即误差平方和准则的最优结果。这种聚类通常称为最小误差划分。
误差平方和准则函数适用于各类样本比较集中而且样本数目悬殊不大的样本分布。当不同类型的样本数目相差较大时,采用误差平方和准则。很可能把样本数目多的类分开,以便达到总的误差平方和最小。
K-means聚类算法步骤主要如下所示:

整个算法的基本流程如下图所示:
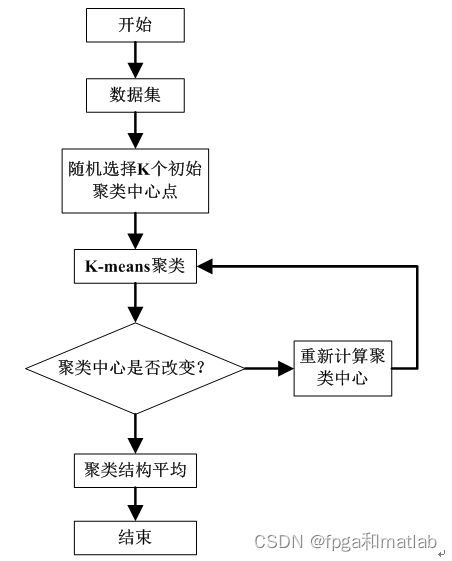
上述算法流程图说明,K-means算法首先需要初始化,即随机选择K个点作为聚类中心点;然后开始做循环操作,根据簇中对象的平均值,将每个对象赋给最类似的簇;然后开始更新簇的平均值,即计算每个对象簇中对象的平均值。
从上面的算法思想和流程,不难看出,k个初始聚类中心点的选取对聚类结果具有较大的影响,因为在该算法中是随机地任意选取k个点作为初始聚类中心,初始的代表一个簇。如果有先验知识,可以选取具有代表性的点。
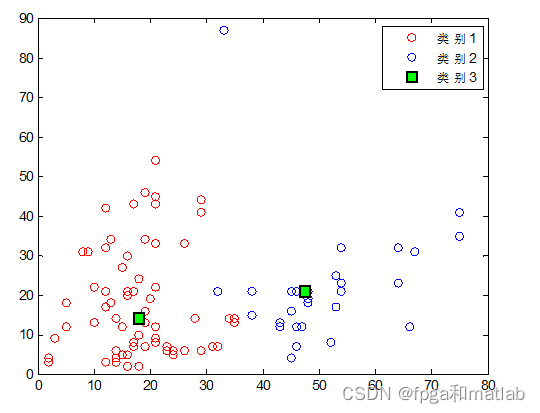
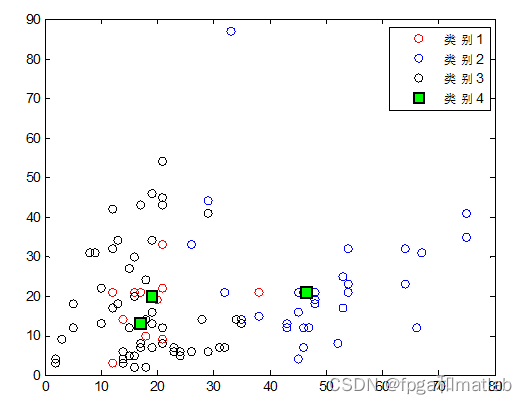
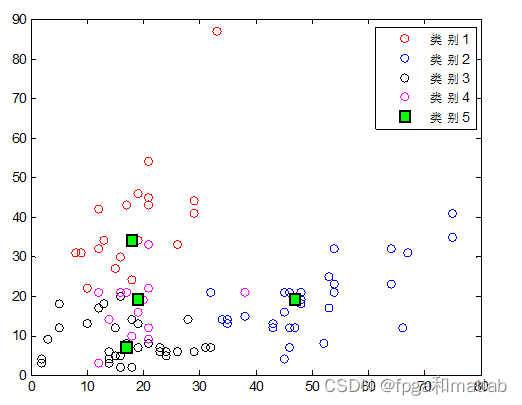
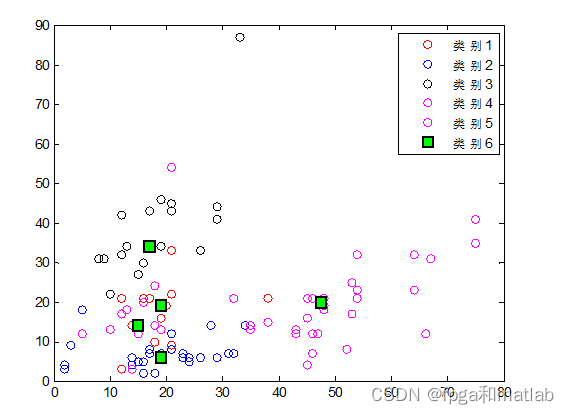
整个算法的复杂度为O(mkt),整个数据集中的对象数为m;把整个数据集划分为k类;聚类过程中的迭代次数为t;要求k 改进kmeans方案如下: 首先计算整个数据集合的平均值点,作为第一个初始聚类中心C1; 然后分别计算所有对象到C1的欧式距离d,并且计算每个对象在半径R的范围内包含的对象个数W。 此时计算P=u*d+(1-u)*W,所得到的最大的P值所对应的的对象作为第二个初始聚类中心C2。 同样的方法,分别计算所有对象到C2的欧式距离d,并且计算每个对象在半径R的范围内包含的对象个数W,所得到的最大的P值所对应的的对象作为第二个初始聚类中心C3。 从这三个初始聚类中心开始聚类划分。对于一个待分类的对象,计算它到现有聚类中心的距离,若(这个距离)<(现有各个聚类中心距离的最小值),则将这个待分类对象分到与它相距最近的那一类;如果(这个距离)>(现有各个聚类中心距离的最小值),则这个待分类对象就自成一类,成为一个新的聚类中心,然后对所有对象重新归类。 如果找到新的聚类中心,在重新计算聚类的中心后。对目前形成的K+1 个聚类计算 DBInew 的值,和未重新分配对象到这 k+1 个类之前计算的 DBIold进行比较,如果 DBInew 分为2类: 分为3类: 分为4类: 分为5类: 从上面的分类结果可知,采用传统的分类方法可知,由于无法确定分类数目的K的值,因此,在设置不同的分类结果之后,会得到不同的分类结果。 A05-27二、核心程序
clc;
clear;
close all;
warning off;
RandStream.setDefaultStream(RandStream('mt19937ar','seed',1));
Dat = xlsread('data.xls');
Feature = zeros(size(Dat));
Feature(:,2:end) = Dat(:,2:end);
KCluster = 6;
X = Feature(:,2:end);
cidx = func_cmeans(X',KCluster);
Feature(:,1) = cidx';
%计算五列重的权值最大的两个
W = mean(X,1);
[V,I] = sort(W);
%选择权值最大的两个进行画图
K1=I(end);
K2=I(end-1);
figure;
plot(X(cidx==1,K1),X(cidx==1,K2),'ro', ...
X(cidx==2,K1),X(cidx==2,K2),'bo', ...
X(cidx==3,K1),X(cidx==3,K2),'ko', ...
X(cidx==4,K1),X(cidx==4,K2),'mo', ...
X(cidx==5,K1),X(cidx==5,K2),'mo', ...
X(cidx==6,K1),X(cidx==6,K2),'co');
hold on;
if KCluster == 2
legend('类别1','类别2','聚类中心点');
end
if KCluster == 3
legend('类别1','类别2','类别3','聚类中心点');
end
if KCluster == 4
legend('类别1','类别2','类别3','类别4','聚类中心点');
end
if KCluster == 5
legend('类别1','类别2','类别3','类别4','类别5','聚类中心点');
end
if KCluster == 6
legend('类别1','类别2','类别3','类别4','类别5','类别6','聚类中心点');
end三、测试结果