初学深度学习(一):初试Keras与多层感知机的搭建
初学深度学习(一):初试Keras与多层感知机的搭建
1. 创建环境和安装依赖
Anaconda作为一个Python的发行版,其中包含了大量的科学包和自带环境管理的工具Conda,推荐使用Conda和Pip这两种方式去构建项目。
1.1 创建虚拟环境
Conda是一个开源的软件包管理系统和环境管理系统,用于安装多个版本的软件包及其依赖关系,并在它们之间轻松切换。
现在创建第一个项目所需要用到的环境,我们将该环境命名为dlwork,采用Python3.6版本,打开终端,在命令行中输入 “conda create -n 环境名 python=版本号” 命令创建环境。
(base) jingyudeMacBook-Pro:~ jingyuyan$ conda create -n keras python=3.6
创建环境完毕后,需要激活已创建的环境,使用“conda activate + 环境名”的方式激活:
(base) jingyudeMacBook-Pro:~ jingyuyan$ conda activate dlwork
或者使用”source activate + 环境名“的方式进行激活:
(base) jingyudeMacBook-Pro:~ jingyuyan$ source activate dlwork
1.2 安装依赖
在新的环境下安装jupyter notebook,这边推荐使用“conda install jupyter”命令进行安装:
conda install jupyter
jupyter notebook安装完毕后,我们继续安装TensorFlow、Keras、OpenCV等一些环境依赖。
需要安装的依赖命令如下:
TensorFlow作为keras的backend,鉴于基础教程,本环境所使用的版本为CPU版本,后面的章节会讲述如何安装和配置GPU环境训练的安装,值得注意的是CPU版本下,使用conda安装的TensorFlow从1.9.0版本开始采用MKL-DNN,速度是与pip形式安装的TensorFlow相比和高达8倍,所以推荐使用conda install命令安装TensorFlow:
conda install tensorflow
Keras可以作为TensorFlow的顶层Api接口简化了很多复杂算法的实现难度,可以使用更简洁的代码实现神经网络的搭建和训练,安装代码如下:
conda install keras
OpenCV作为一款跨平台计算机视觉库,它在图像处理方面具有非常强大的功能,值得注意的是,新版的OpenCV4.x的版本与3.x的版本具有较大的差异,采用OpenCV3.4.20的版本:
pip install opencv-python==3.4.5.20
Pandas是基于NumPy 的一种工具,纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具,安装方法如下:
conda install pandas
安装完所有需要的依赖后可以使用“conda list”查看当前所安装的依赖情况
conda list
2. 构建项目
在指定的磁盘路径创建存放当前项目的目录,linux或macos可使用mkdir命令创建文件夹目录,Windows直接使用图形化界面右键新建文件夹即可,例如我们的存放项目的目录名为project01:
(dlwork) jingyudeMacBook-Pro:~ jingyuyan$ mkdir project01
创建成功后,在dlwork环境下,进入到project01目录下,打开jupyter notebook:
cd project01
jupyter notebook
新建一个新的ipynb文件,并且进入到文件中
![[外链图片转存失败(img-Ub64a9rS-1564022743021)(img1.png)]](http://img.e-com-net.com/image/info8/cc57defd1aba43cc9418d434560a5a8a.jpg)
3. MNIST数据集下载和预处理
我们所采用数据集为MNIST手写数字集,收集该数据集的人是“卷积神经网络之父”的Yann LeCun。MNIST数据是由几千张28×28的单色图片组成,比较简单,非常适合深度学习新生入门学习所使用。
3.1 导入相关模块和下载数据
导入所需要使用到的相关依赖模块
import numpy as np
from keras.utils import np_utils
from keras.datasets import mnist
import pandas as pd
import matplotlib.pyplot as plt
Using TensorFlow backend.
导入keras时,如果出现“Using TensorFlow backend.”便表示系统自动将TensorFlow作为keras的backend。
使用mnist.load_data()下载MNIST数据集,初次下载时间会比较长,请耐心等待数据集下载完成。
(X_train_image,y_train_label),(X_test_image,y_test_label) = mnist.load_data()
![[外链图片转存失败(img-Oq4h0oTu-1564022743024)(img2.png)]](http://img.e-com-net.com/image/info8/fb7c9fc4c9ee4f34bded4ce96a203349.jpg)
Windows系统下的数据集会放在C:\Users\XXX.keras\datasets\mnist.npz
Linux和MacOS系统放在~/.keras/datasets/mnist.npz
如果因为网上原因无法下载或者速度过慢,可以直接到本书提供的网盘下载mnist.npz自行放置目录下
3.2 数据预处理
3.2.1 读取数据集的信息
成功下载数据集后,需要重新执行一次读取数据集代码,如果没显示需要下载,则表示读取数据集成功
# 读取数据集中的训练集合测试集
(X_train_image,y_train_label),(X_test_image,y_test_label) = mnist.load_data()
# 查看数据集中训练集合测试集数据的数量
X_train_image.shape, X_test_image.shape
((60000, 28, 28), (10000, 28, 28))
可以看到上述代码输出数据集中的训练集和测试集分别有60000和10000张28×28的单通道图片
3.2.2 查看数据集中图像和标签
为了更方便的理解数据集中所存在的图像与标签直接存在的关系,我们编写可视化脚本来输出图像与标签
# 定义一个可输出图片和数字的函数
def show_image(images, labels, idx):
fig = plt.gcf()
plt.imshow(images[idx], cmap='binary')
plt.xlabel('label:'+str(labels[idx]), fontsize = 15)
plt.show()
show_image(X_train_image, y_train_label, 4)

可以看到上面的代码查看的是训练集中的第5个数据集中的图像和所对应的标签,均为9。
为了更加方便数据集的查看,我们定义一个遍历多出图的函数
def show_images_set(images,labels,prediction,idx,num=10):
fig = plt.gcf()
fig.set_size_inches(12,14)
for i in range(0,num):
ax = plt.subplot(4,5,1+i)
ax.imshow(images[idx],cmap='binary')
title = "label:"+str(labels[idx])
if len(prediction)>0:
title +=",predict="+str(prediction[idx])
ax.set_title(title,fontsize=12)
ax.set_xticks([]);ax.set_yticks([])
idx+=1
plt.show()
使用show_images_set显示训练集的数据。prediction为传入预测结果数据集,这边暂时为空,idx为需要从第几项数据开始遍历,默认为num=10项
show_images_set(images=X_train_image, labels=y_train_label, prediction=[], idx=0)
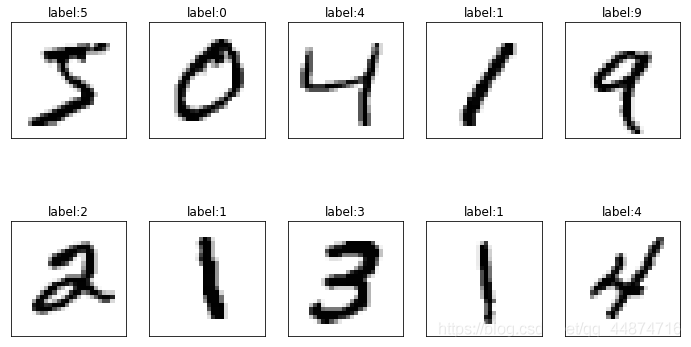
使用show_images_set显示测试集的数据。
show_images_set(images=X_test_image, labels=y_test_label, prediction=[], idx=0)
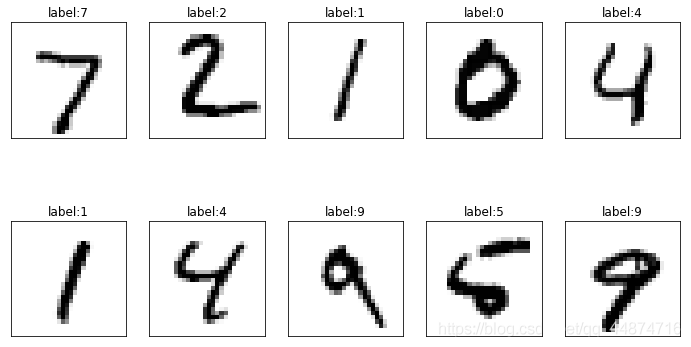
3.2.3 数据集图像预处理操作
将数据集中的图像(28×28)转换成一维向量再转换数据类型为Float32
X_Train = X_train_image.reshape(60000, 28*28).astype('float32')
X_Test = X_test_image.reshape(10000, 28*28).astype('float32')
将转换后的数据输出查看,这边查看第5项数据
X_Train[4]
array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 55.,
148., 210., 253., 253., 113., 87., 148., 55., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 87., 232., 252., 253., 189., 210., 252.,
252., 253., 168., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 4., 57., 242.,
252., 190., 65., 5., 12., 182., 252., 253., 116., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 96., 252., 252., 183., 14., 0., 0., 92.,
252., 252., 225., 21., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 132., 253., 252.,
146., 14., 0., 0., 0., 215., 252., 252., 79., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 126., 253., 247., 176., 9., 0., 0., 8., 78.,
245., 253., 129., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 16., 232., 252., 176.,
0., 0., 0., 36., 201., 252., 252., 169., 11., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 22., 252., 252., 30., 22., 119., 197., 241., 253.,
252., 251., 77., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 16., 231., 252.,
253., 252., 252., 252., 226., 227., 252., 231., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 55., 235., 253., 217., 138., 42., 24.,
192., 252., 143., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 62., 255., 253., 109., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
71., 253., 252., 21., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 253., 252., 21., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 71., 253., 252., 21., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 106., 253., 252., 21.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 45., 255., 253., 21., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 218., 252.,
56., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 96., 252., 189., 42., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 14.,
184., 252., 170., 11., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 14., 147., 252., 42., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0.], dtype=float32)
可以清晰的发型上面输出的向量中,大部分的位置都是0,表示无颜色的区域,而0到255之间的数均为图像中代表的每一个灰度点的颜色程度。
在转换完图像后,我们对图像进行归一化处理,便是将0到255的数映射到0和1之间的数,这样可以提到模型训练精度。
X_Train_normalize = X_Train / 255
X_Test_normalize = X_Test / 255
通过查看归一化结果中,可以看到,在进行归一化并且输出数据后,之前所有0到255的数均映射到0和1之间的数,
X_Train_normalize[4]
array([0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.21568628, 0.5803922 ,
0.8235294 , 0.99215686, 0.99215686, 0.44313726, 0.34117648,
0.5803922 , 0.21568628, 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0.34117648, 0.9098039 , 0.9882353 , 0.99215686, 0.7411765 ,
0.8235294 , 0.9882353 , 0.9882353 , 0.99215686, 0.65882355,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0.01568628, 0.22352941, 0.9490196 , 0.9882353 ,
0.74509805, 0.25490198, 0.01960784, 0.04705882, 0.7137255 ,
0.9882353 , 0.99215686, 0.45490196, 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0.3764706 ,
0.9882353 , 0.9882353 , 0.7176471 , 0.05490196, 0. ,
0. , 0.36078432, 0.9882353 , 0.9882353 , 0.88235295,
0.08235294, 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0.5176471 , 0.99215686, 0.9882353 , 0.57254905,
0.05490196, 0. , 0. , 0. , 0.84313726,
0.9882353 , 0.9882353 , 0.30980393, 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.49411765, 0.99215686,
0.96862745, 0.6901961 , 0.03529412, 0. , 0. ,
0.03137255, 0.30588236, 0.9607843 , 0.99215686, 0.5058824 ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0.0627451 , 0.9098039 , 0.9882353 , 0.6901961 , 0. ,
0. , 0. , 0.14117648, 0.7882353 , 0.9882353 ,
0.9882353 , 0.6627451 , 0.04313726, 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.08627451, 0.9882353 ,
0.9882353 , 0.11764706, 0.08627451, 0.46666667, 0.77254903,
0.94509804, 0.99215686, 0.9882353 , 0.9843137 , 0.3019608 ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0.0627451 , 0.90588236, 0.9882353 , 0.99215686,
0.9882353 , 0.9882353 , 0.9882353 , 0.8862745 , 0.8901961 ,
0.9882353 , 0.90588236, 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0.21568628, 0.92156863, 0.99215686, 0.8509804 , 0.5411765 ,
0.16470589, 0.09411765, 0.7529412 , 0.9882353 , 0.56078434,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0.24313726,
1. , 0.99215686, 0.42745098, 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0.2784314 , 0.99215686, 0.9882353 ,
0.08235294, 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0.99215686, 0.9882353 , 0.08235294, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.2784314 , 0.99215686,
0.9882353 , 0.08235294, 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0.41568628, 0.99215686, 0.9882353 , 0.08235294,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0.1764706 ,
1. , 0.99215686, 0.08235294, 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.85490197, 0.9882353 ,
0.21960784, 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0.3764706 , 0.9882353 , 0.7411765 , 0.16470589,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0.05490196,
0.72156864, 0.9882353 , 0.6666667 , 0.04313726, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.05490196, 0.5764706 ,
0.9882353 , 0.16470589, 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. ], dtype=float32)
3.2.3 数据集图像预处理操作
label标签字段原本是0~9的数字,必须以One-Hot Endcoding(一位有效编码)转换为10个0或者1的组合,对应着神经网络最终输出层的10个结果。
y_TrainOneHot = np_utils.to_categorical(y_train_label)
y_TestOneHot = np_utils.to_categorical(y_test_label)
转换后我们提取数据集中的标签来进行比对
y_train_label[:3]
array([5, 0, 4], dtype=uint8)
y_TrainOneHot[:3]
array([[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.]], dtype=float32)
比如第一项的标签数字5经过转换后变成0000010000
3.3 首次尝试搭建多层感知机进行训练
3.3.1 搭建模型
首先先搭建一个最简单的模型,仅有输入层和输出层,输入层的参数为 28 × 28 = 784;输出层为10,对应着数字的10个数
from keras.models import Sequential
from keras.layers import Dense,Dropout,Flatten,Conv2D,MaxPooling2D,Activation
# 设置模型参数
CLASSES_NB = 10
INPUT_SHAPE = 28 * 28
# 建立Sequential模型
model = Sequential()
# 添加一个Dense层,输入直接为
model.add(Dense(units=CLASSES_NB,
input_dim=INPUT_SHAPE,))
# 定义输出层,使用softmax将0到9的十个数字的结果通过概率的形式进行激活转换
model.add(Activation('softmax'))
WARNING:tensorflow:From /Users/jingyuyan/anaconda3/envs/dlwork/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
搭建好模型后,使用summary()可以查看模型的摘要
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 10) 7850
_________________________________________________________________
activation_1 (Activation) (None, 10) 0
=================================================================
Total params: 7,850
Trainable params: 7,850
Non-trainable params: 0
_________________________________________________________________
3.3.2 神经网络训练
多层感知器模型已经建立完毕,我们可以使用方向传播的方式进行模型的训练,keras的训练需要使用compile对模型设置训练的参数:
- loss:损失函数使用交叉熵损失函数cross_entropy进行训练
- optimizer:使用adam优化器的方式进行梯度下降算法的优化,可以加快神经网络收敛速度
- metrics:评估方式这里设置为准去率accuracy
# 设置训练参数
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
建立好了训练的参数后,开始训练。训练之前需要配置训练过程中的一些参数:
# 验证集划分比例
VALIDATION_SPLIT = 0.2
# 训练周期
EPOCH = 10
# 单批次数据量
BATCH_SIZE = 128
# 训练LOG打印形式
VERBOSE = 2
- epochs:设置训练周期为10轮
- batch_size:设置每一个批次传入128项的数据
- validation_split:验证集是用于模型每轮训练中,划分一部分进行测试,设置验证集比例为0.2表示将训练的数据和验证数据划分比如为8:2的形式,训练数据为60000项,所以划分出来的验证集就为12000项。
# 传入数据,开始训练
# verbose为表示显示打印的训练过程
train_history = model.fit(
x=X_Train_normalize,
y=y_TrainOneHot,
epochs=EPOCH,
batch_size=BATCH_SIZE,
verbose=VERBOSE,
validation_split=VALIDATION_SPLIT)
WARNING:tensorflow:From /Users/jingyuyan/anaconda3/envs/dlwork/lib/python3.6/site-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
- 1s - loss: 0.7762 - acc: 0.8076 - val_loss: 0.4124 - val_acc: 0.8963
Epoch 2/10
- 1s - loss: 0.3929 - acc: 0.8955 - val_loss: 0.3348 - val_acc: 0.9091
Epoch 3/10
- 0s - loss: 0.3402 - acc: 0.9076 - val_loss: 0.3087 - val_acc: 0.9167
Epoch 4/10
- 0s - loss: 0.3154 - acc: 0.9132 - val_loss: 0.2947 - val_acc: 0.9207
Epoch 5/10
- 1s - loss: 0.3014 - acc: 0.9160 - val_loss: 0.2847 - val_acc: 0.9212
Epoch 6/10
- 1s - loss: 0.2913 - acc: 0.9191 - val_loss: 0.2803 - val_acc: 0.9212
Epoch 7/10
- 1s - loss: 0.2841 - acc: 0.9205 - val_loss: 0.2742 - val_acc: 0.9249
Epoch 8/10
- 1s - loss: 0.2784 - acc: 0.9222 - val_loss: 0.2714 - val_acc: 0.9255
Epoch 9/10
- 1s - loss: 0.2738 - acc: 0.9231 - val_loss: 0.2688 - val_acc: 0.9255
Epoch 10/10
- 1s - loss: 0.2702 - acc: 0.9249 - val_loss: 0.2660 - val_acc: 0.9278
从上面打印的日志可以得知,经过10轮的训练会发现loss逐渐降低,准确率不断地在提升。
定义一个函数,绘制出训练过程中的数据,以图表的形式呈现
def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train histoty')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train','validation',],loc = 'upper left')
plt.show()
我们传入训练结果,绘制出训练过程中的准确率
show_train_history(train_history,'acc','val_acc')
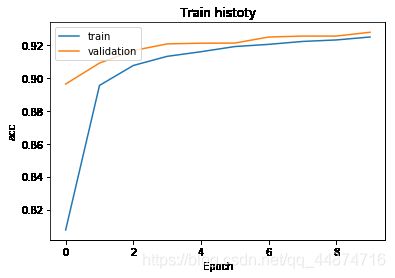
由图可得蓝色的线为准确率(acc)在每一轮的训练中都在不断的提。
继续使用绘制函数绘制出误差率的图像:
show_train_history(train_history,'loss','val_loss')
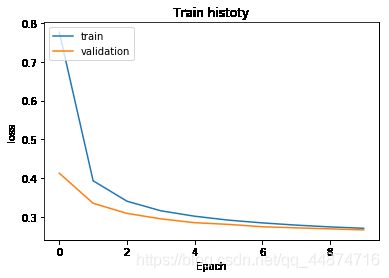
由图可得蓝色的线为误差率(loss)在每一轮的训练中都在不断的降低。
通过训练的日志可以看到该模型仅有0.92左右的准确度,下一节将添加隐藏层神经网络提高模型的精度。
3.4 增加隐藏层改进模型
3.4.1 搭建模型
从现在开始,将逐步建立多层感知机模型。输入层的神经元个数共有784个,隐藏层共有256个,而输出层则有10个,分别对应10个0~9之间的数字结果。
CLASSES_NB = 10
INPUT_SHAPE = 28 * 28
UNITS = 256
重新搭建模型,添加一个隐藏层,加深和加厚模型的深度和宽度。
# 建立Sequential模型
model = Sequential()
# 添加一个Dense,Deense的特点是上下层的网络均连接
# 该Dense层包含输入层和隐藏层
model.add(Dense(units=UNITS,
input_dim=INPUT_SHAPE,
kernel_initializer='normal',
activation='relu'))
# 定义输出层,使用softmax将0到9的十个数字的结果通过概率的形式进行激活转换
model.add(Dense(CLASSES_NB, activation='softmax'))
# 搭建完成后输出模型摘要
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 256) 200960
_________________________________________________________________
dense_3 (Dense) (None, 10) 2570
=================================================================
Total params: 203,530
Trainable params: 203,530
Non-trainable params: 0
_________________________________________________________________
- 隐藏层:共256个神经元
- 输出层:共10个神经元
- dense_1参数:784×256 + 256 = 200,960
- dense_2参数:256×10 + 10 = 2570
- 训练的总参数: 200960 + 2570 = 203,530
3.4.2 神经网络训练
多层感知器模型已经建立完毕,我们可以使用方向传播的方式进行模型的训练,keras的训练需要使用compile对模型设置训练的参数:
# 验证集划分比例
VALIDATION_SPLIT = 0.2
# 训练周期提升到20轮
EPOCH = 15
# 单批次数据量增加到300
BATCH_SIZE = 300
# 训练LOG打印形式
VERBOSE = 2
# 设置训练参数
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
将训练的轮数和批次进行适当增加
# 传入数据,开始训练
# verbose为表示显示打印的训练过程
train_history = model.fit(
x=X_Train_normalize,
y=y_TrainOneHot,
epochs=EPOCH,
batch_size=BATCH_SIZE,
verbose=VERBOSE,
validation_split=VALIDATION_SPLIT)
Train on 48000 samples, validate on 12000 samples
Epoch 1/15
- 2s - loss: 0.4466 - acc: 0.8794 - val_loss: 0.2219 - val_acc: 0.9395
Epoch 2/15
- 1s - loss: 0.1926 - acc: 0.9462 - val_loss: 0.1618 - val_acc: 0.9553
Epoch 3/15
- 1s - loss: 0.1383 - acc: 0.9612 - val_loss: 0.1339 - val_acc: 0.9625
Epoch 4/15
- 1s - loss: 0.1092 - acc: 0.9700 - val_loss: 0.1181 - val_acc: 0.9664
Epoch 5/15
- 1s - loss: 0.0878 - acc: 0.9756 - val_loss: 0.1065 - val_acc: 0.9684
Epoch 6/15
- 1s - loss: 0.0730 - acc: 0.9793 - val_loss: 0.0961 - val_acc: 0.9716
Epoch 7/15
- 1s - loss: 0.0614 - acc: 0.9829 - val_loss: 0.0928 - val_acc: 0.9718
Epoch 8/15
- 1s - loss: 0.0525 - acc: 0.9860 - val_loss: 0.0895 - val_acc: 0.9739
Epoch 9/15
- 1s - loss: 0.0439 - acc: 0.9885 - val_loss: 0.0861 - val_acc: 0.9744
Epoch 10/15
- 1s - loss: 0.0378 - acc: 0.9906 - val_loss: 0.0837 - val_acc: 0.9755
Epoch 11/15
- 1s - loss: 0.0326 - acc: 0.9921 - val_loss: 0.0816 - val_acc: 0.9749
Epoch 12/15
- 1s - loss: 0.0275 - acc: 0.9934 - val_loss: 0.0789 - val_acc: 0.9765
Epoch 13/15
- 1s - loss: 0.0233 - acc: 0.9951 - val_loss: 0.0809 - val_acc: 0.9754
Epoch 14/15
- 1s - loss: 0.0198 - acc: 0.9963 - val_loss: 0.0800 - val_acc: 0.9758
Epoch 15/15
- 1s - loss: 0.0174 - acc: 0.9967 - val_loss: 0.0793 - val_acc: 0.9759
通过日志可以看到,再引入隐藏层后,相比上一个仅有输入层和输出层的网络,该模型的准确率有所上升,损失有所下降。
使用上小节定义的show_train_history函数分别绘制出训练的准去率和损失率的图像:
show_train_history(train_history,'acc','val_acc')
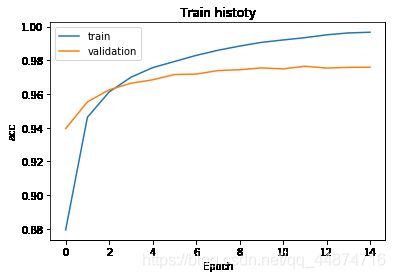
有图可得蓝色的线为准确率(acc)在每一轮的训练中都在不断的提升,但是验证集准确率(val_acc)在训练时后面的阶段却低于准确率。
show_train_history(train_history,'loss','val_loss')
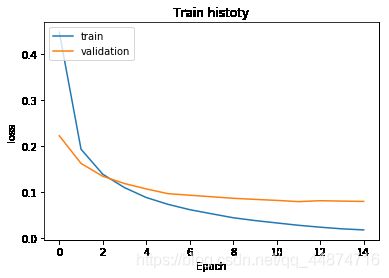
由图可得蓝色的线为误差率(loss)在每一轮的训练中都在不断的降低,而验证集误差率(val_loss)在训练时后面的阶段却高于准确率。
为什么在训练后面的阶段验证集准去率会低于准确率,验证集误差率会高于误差率?这里涉及到过拟合的现象。后面的章节会阐述。
3.5 对训练结果进行评估
3.5.1 使用测试集评估模型准确率
现在需要使用到之前所加载的测试集数据,测试集数据共有10000张。由于测试集数据是不参与到模型的训练的,通常用于模型训练完毕后,对模型的准确率进行评估时所使用的数据集。
定义一个scores用于存放所有的评估结果,使用evaluate函数,将测试集图片和标签传入到模型中进行评估测试。
scores = model.evaluate(X_Test_normalize, y_TestOneHot)
10000/10000 [==============================] - 0s 24us/step
测试预测完毕后打印出预测结果,首先打印出模型的损失和准确率
print('loss:',scores[0])
print('accuracy:',scores[1])
loss: 0.07091819015247747
accuracy: 0.9782
使用以上的多层感知机引入隐藏层后,训练的模型在测试集下预测的准确率可达到0.97。
3.5.2 使用模型将测试集进行预测
将测试集传入模型进行预测,这里我们分别使用predict和predict_classes,试着观察不同之处。
result = model.predict(X_Test)
result_class = model.predict_classes(X_Test)
分别输出预测的第5项数据的真实结果和预测结果
# 使用之前定义的显示图片的函数
show_image(X_test_image, y_test_label, 6)

可以看到第7项数据的图像和标签均为4
result[6]
array([0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], dtype=float32)
利用predict函数进行预测所输出的结果是一个向量,也就是上小节将标签进行处理的one-hot格式。
result_class[6]
4
可以看到,使用predict_classes进行预测的结果直接输出标签4,表示结果是第5个分类。
所以这边为了方便查看预测结果,我们则采用predict_classes的预测结果这个形式。
利用上小节定义的函数,查看多项数据的预测结果和真实结果,从第248项开始取后面的10项数据进行查看。
# 之前查看数据时第三个参数为空,现在有预测数据了,需要传入才可直观的进行比对
show_images_set(X_test_image,y_test_label,result_class,idx=247)

可以看出,上图的结果第1项数据存在预测错误,原始的值应该为4,却被神经网络误以为是6,由于这个手写字体较为潦草,所以难免会识别出错。
3.5.3 建立误差矩阵
上一节中,我们发现了在预测的过程中,模型是会有错误的情况出现的。比如上小节中我们发现潦草的写手数字4到了模型预测结果为6,有了这样的问题存在,我们如果需要找出其他类似这样的情况,观察哪些数字会存在比较大的误差,这时候我们需要建立误差矩阵也叫混淆矩阵,来进行显示误差图。
使用pandas自带的crosstab函数,将测试集的标签和预测结果的标签分别传入到函数中即可建立误差矩阵。
# 使用pandas库
import pandas as pd
pd.crosstab(y_test_label, result_class, rownames=['label'], colnames=['predict'])
| predict | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| label | ||||||||||
| 0 | 971 | 0 | 2 | 2 | 2 | 0 | 1 | 1 | 1 | 0 |
| 1 | 0 | 1127 | 4 | 0 | 0 | 1 | 1 | 0 | 2 | 0 |
| 2 | 4 | 1 | 1012 | 2 | 2 | 1 | 2 | 5 | 3 | 0 |
| 3 | 1 | 1 | 3 | 996 | 0 | 3 | 0 | 3 | 2 | 1 |
| 4 | 1 | 0 | 4 | 0 | 957 | 0 | 5 | 2 | 0 | 13 |
| 5 | 2 | 0 | 0 | 12 | 1 | 866 | 4 | 1 | 4 | 2 |
| 6 | 6 | 3 | 2 | 1 | 3 | 4 | 937 | 1 | 1 | 0 |
| 7 | 0 | 4 | 10 | 2 | 1 | 0 | 0 | 1005 | 0 | 6 |
| 8 | 3 | 0 | 11 | 14 | 2 | 8 | 1 | 4 | 929 | 2 |
| 9 | 5 | 5 | 0 | 9 | 6 | 2 | 0 | 4 | 1 | 977 |
仔细观察误差矩阵,可以看到,3和5的混淆次数最高,其次是9和4。
为了方便我们查看怎么样的数据会发现混淆,我们利用pandas创建DataFrame来查看混淆的数据的详细信息。
# 创建DataFrame
dic = {'label':y_test_label, 'predict':result_class}
df = pd.DataFrame(dic)
查看所有的预测结果以及数据项的真实值
# T是将矩阵转置,方便查看数据
df.T
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 9990 | 9991 | 9992 | 9993 | 9994 | 9995 | 9996 | 9997 | 9998 | 9999 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| label | 7 | 2 | 1 | 0 | 4 | 1 | 4 | 9 | 5 | 9 | ... | 7 | 8 | 9 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| predict | 7 | 2 | 1 | 0 | 4 | 1 | 4 | 9 | 5 | 9 | ... | 7 | 8 | 9 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
2 rows × 10000 columns
查看5和3混淆的数据项,这边我们选择查看下标为1670项的数据,看看图片的情况
df[(df.label==5)&(df.predict==3)].T
| 340 | 1003 | 1393 | 1670 | 2035 | 2597 | 2810 | 4360 | 5937 | 5972 | 5982 | 9422 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| label | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| predict | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
show_image(X_test_image, y_test_label, 1670)

可以清楚的看见,虽然1670项的图像真实值为5,但是它看起来又不太像5,有点像3。即使是人工辨别也有一定的困难性。
结论
本章通过多层感知机搭建最为简单的模型进行MNIST手写数据集的识别,在测试集下准确率可达到0.97,算是一个比较不错的成绩,但是在训练模型的过程中存在了过拟合和小部分误差的情况,下一章将描述如何决绝过拟合问题和进一步提升模型的准确率。