数据清洗 黑马程序员 第五章数据的清洗与检验——阅读笔记
5.1 数据去重
数据去重又称重复数据的删除,通常指的是找出数据文件集合中重复的数据并将其删除,只保存唯一的数据单元,从而消除冗余数据。通常情况下,数据去重方法分为两种,分别是完全去重和不完全去重。
5.1.1 完全去重
完全去重指的是消除完全重复的数据,这里提到的完全重复数据指的是数据表记录字段值完全一样的数据。
1.打开Kettle工具,创建转换
通过使用Kettle工具,创建一个转换repeat_transform,并添加“CSV文件输入”控件、“唯一行(哈希值)”控件以及Hop跳连接线,具体如图1所示:

图1 创建转换repeat_transform
2.配置CSV文件输入控件
双击“CSV文件输入”控件,进入“CSV文件输入”配置界面,单击“浏览”按钮,选择要进行完全去重处理的CSV文件merge.csv;再单击“获取字段”按钮,单击“预览”按钮,查看CSV文件merge.csv的数据是否加载到CSV文件输入流中,具体如图2所示:
 图2 Kettle检索CSV文件和预览数据
图2 Kettle检索CSV文件和预览数据
3.配置”唯一行(哈希值)”控件
双击“唯一行(哈希值)”控件,进入“唯一行(哈希值)”配置界面,在“用来比较的字段”处,添加要去重的字段,这里可以单击“获取”按钮,获取要去重的字段,如图3所示:

图3 添加需要去重的字段
4.运行转换repeat_transform
单击转换工作区顶部的![]() 按钮,运行创建的repeat_transform转换 ,如图4所示:
按钮,运行创建的repeat_transform转换 ,如图4所示:
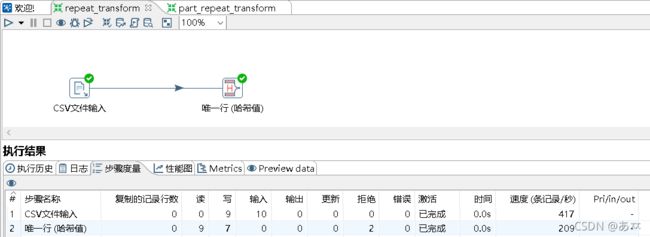
图4 运行转换repeat_transform
5.查看merge.csv是否消除完全重复的数据
选中“唯一行(哈希值)”控件,单击执行结果窗口的“Preview data”选项卡,查看是否消除CSV文件merge.csv中完全重复的数据,具体如图5所示:
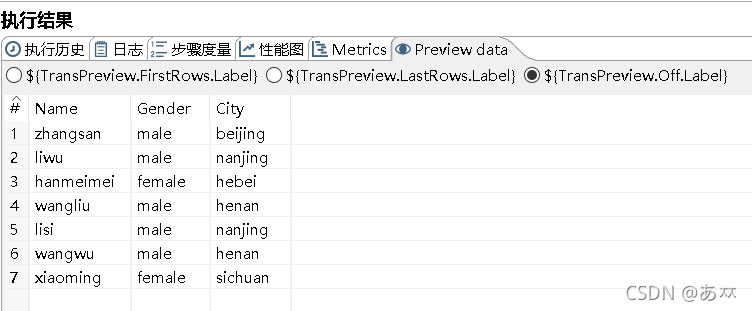
图5 查看是否消除CSV文件merge.csv中完全重复的数据
5.1.2 不完全去重
1.打开Kettle工具,创建转换
通过使用Kettle工具,创建一个转换repeat_transform,并添加“CSV文件输入”控件、“唯一行(哈希值)”控件以及Hop跳连接线,具体如图6所示:
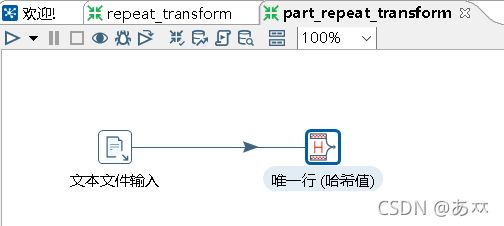
图6 创建转换repeat_transform
2. 配置文本文件输入控件
双击“文本文件输入”控件,进入“文本文件输入”配置界面,单击“浏览”按钮,选择要去重的文件people.txt;单击“增加”按钮,将要去重的文件people.txt添加到转换part_repeat_transform中,几天如图7,图8所示:
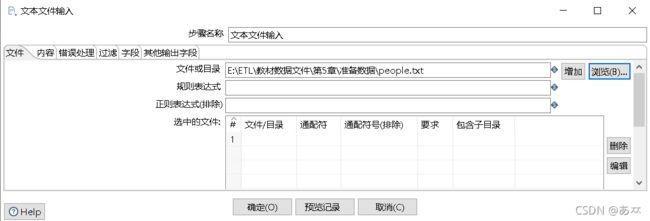
图7 选择要去重的文件people.txt 
图8 添加people.txt至转换part_repeat_transform中
单击“内容”选项卡;清除分隔符处的默认分隔符“;”,并单击“Insert TAB”按钮,在分隔符处插入一个制表符;取消勾选“头部”复选框,如图9所示:

图9 “内容”选项卡配置
单击“字段”选项卡;根据文件people.txt的内容添加对应的字段名称,并指定数据类型,单击“预览记录”按钮,查看文件people.txt的数据是否成功抽取到文本文件输入流中,如图10所示:

图10 “字段”选项卡的配置和预览数据
3.配置唯一行(哈希值)控件
双击“唯一行(哈希值)”控件,进入“唯一行(哈希值)”配置界面,在“用来比较的字段”处,添加要比较去重的字段,即Name、UserLevel、Phone字段,如图11所示:
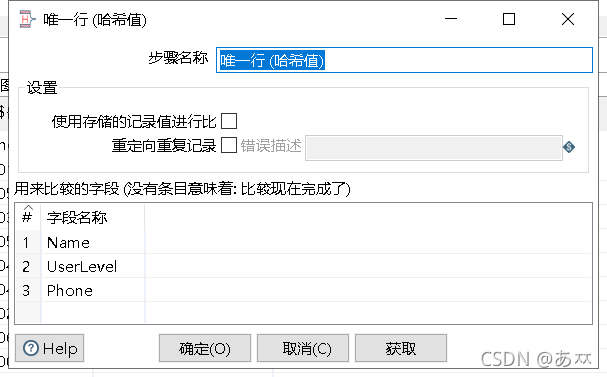
图11 添加要比较去重的字段
4.运行转换part_repeat_transform
单击转换工作区顶部的 ![]() 按钮,运行创建的part_repeat_transform转换,如图12所示:
按钮,运行创建的part_repeat_transform转换,如图12所示:
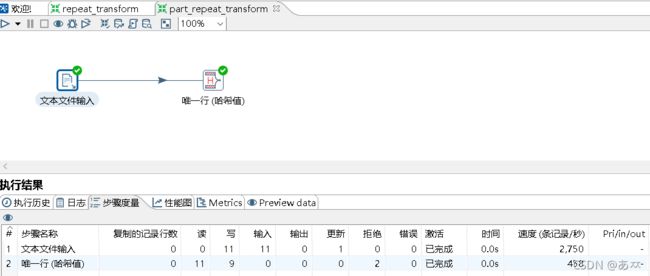
图12 运行转换part_repeat_transform
5.查看文件people.txt是否消除不完全重复的数据
选中“唯一行(哈希值)”控件,单击执行结果窗口的“Preview data”选项卡,查看是否消除文件people.txt中不完全重复的数据,如图13所示:
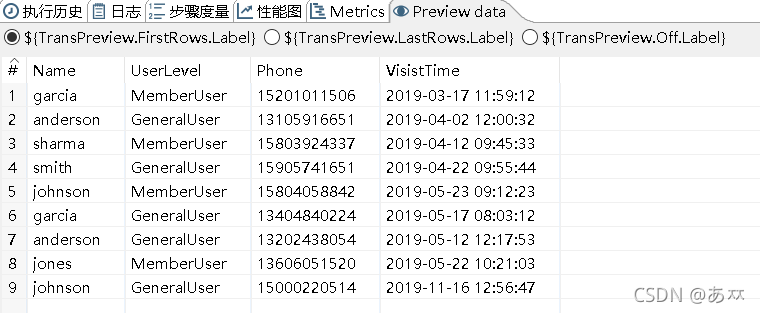 图13 查看是否消除文件people.txt中不完全重复的数据
图13 查看是否消除文件people.txt中不完全重复的数据
5.2 缺失值处理
缺失值是指数据集中某个或某些属性的值是不完整的,产生的原因主要有人为原因和机械原因两种,其中机械原因是由于机器故障造成数据未能收集或存储失败,人为原因是由主观失误或有意隐瞒造成的数据缺失。
5.2.1 缺失值清洗策略
制定合理的缺失值数据处理策略,不仅可以提升缺失值数据处理的效率,还可以使处理后数据的可靠性得到保证,提高最终分析结果的准确性。缺失值的处理方法很多,这里建议大家在清洗缺失值时,首先计算数据源字段缺失值比例,之后根据数据缺失率和重要性,指定不同的策略。
根据缺失值的范围制定对应的策略,通常情况下采用的策略如表1所示。
表1 根据缺失值的范围制定对应的策略
| 缺失值的范围 | 对应的策略 |
| 重要性高、缺失率高的数据 | (1) 尝试从其它渠道获取数据进行补全 ; (2) 通过对其它字段的数据进行分析、计算等方式获取合理值进行补全 ; (3) 去除字段但要在结果中进行标注; |
| 重要性高、缺失率低的数据 | (1) 通过对字段自身的数据进行分析、计算等方式获取合理值进行补全 ; (2) 通过自身的经验与业务知识对缺失值数据进行人为补全; |
| 重要性低、缺失率高的数据 | 直接去除该字段 |
| 重要性低、缺失率低的数据 | 可以不去处理或者进行简单的填充 |
5.2.2 去除缺失值
数据缺失分为两种:一种是行记录的缺失,这种情况又称数据记录丢失;另一种是数据列值的缺失,即由于各种原因导致的数据记录中某些列的值空缺。 去除缺失值数据通常分为两种情况:一种是删除存在遗漏信息属性值的对象的列,另一种是删除存在遗漏信息属性值对象的记录,从而得到一个完备的信息表。
1.打开Kettle工具,创建转换
通过使用Kettle工具,创建一个转换delete_missing_value,并添加“文本文件输入”控件、“字段选择”控件、“过滤记录”控件、“Excel输出”控件、“空操作(什么也不做)”控件以及Hop跳连接线,如图14所示:
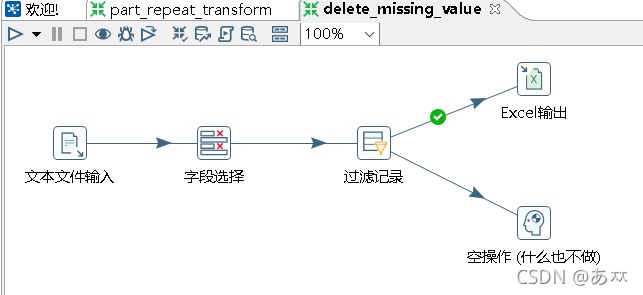
图14 创建转换delete_missing_value
2.配置文本文件输入控件
双击“文本文件输入”控件,进入“文本文件输入”配置界面,单击“浏览”按钮,选择要去除缺失值的文件revenue.txt;单击“增加”按钮,将要去除缺失值的文件revenue.txt添加到“文本文件输入”控件中,如图15、图16所示:
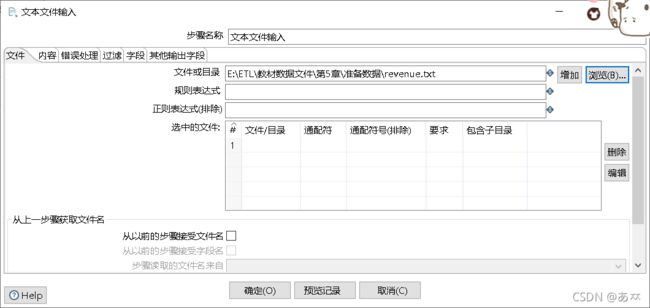
图15 选择要去除缺失值的文件revenue.txt

图16 添加文件revenue.txt至“文本文件输入”
单击“内容”选项卡;在清除分隔符处的默认分隔符“;”,单击“Insert TAB”按钮,在分隔符处插入一个制表符;取消勾选“头部”复选框,如图17所示:

图17 “内容”选项卡配置
单击“字段”选项卡;根据文件revenue.txt的内容添加对应的字段名称,并指定数据类型;单击“预览记录”按钮,查看文件revenue.txt中的数据是否成功抽取到文本文件输入流中,具体如图18所示:
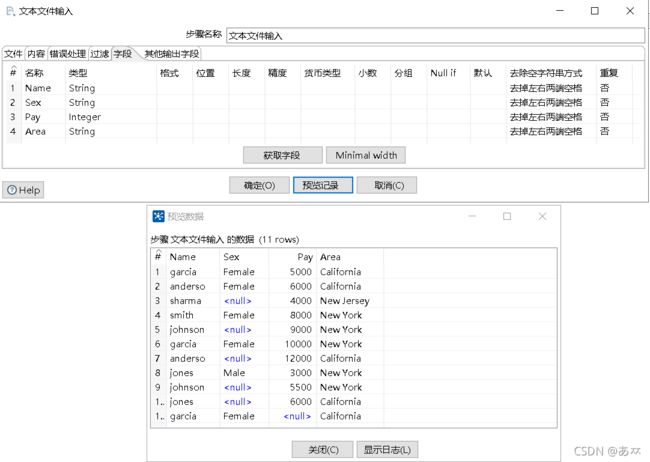
图18 添加字段和预览记录
3.配置字段选择控件
双击“字段选择”控件,进入“选择/改名值”界面,在“选择和修改”选项卡的“字段”处手动添加文本文件输入控件输出的所有数据字段,也可以单击“获取选择的字段”按钮,Kettle工具自动检索并添加文本文件输入控件输出的所有数据字段;在“移除”选项卡处添加要移除的字段名称,这里移除的是Sex字段,具体如图18、图20所示:
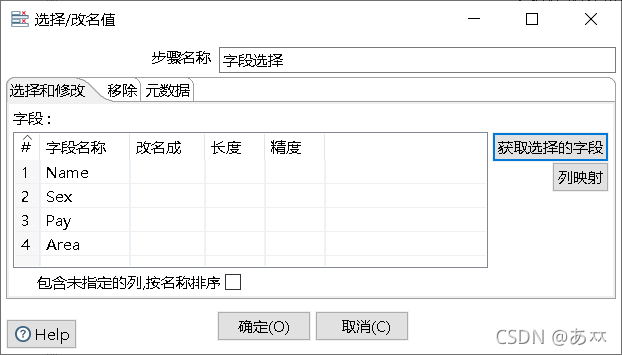
图19 添加字段
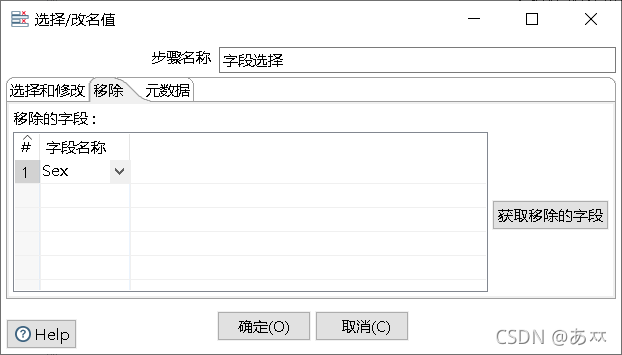
图20 添加要移除的字段名称
4.配置过滤记录控件
双击“过滤记录”控件,进入“过滤记录”界面,在“条件”处设置过滤的条件,过滤掉有缺失值的数据字段(这里是过滤Name、Pay和Area字段中的缺失值);单击左边“
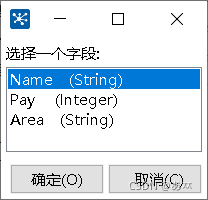
图21 “字段对”话框

图22 “函数”对话框
字段Name的过滤设置如图23所示;
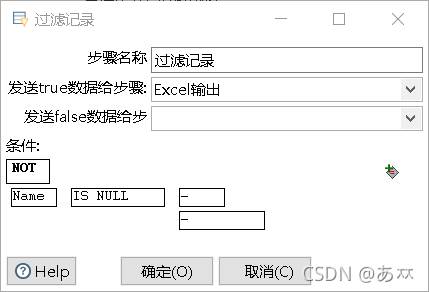
图23 字段Name的过滤设置
单击符号“+”增加过滤条件,如图24所示;单击“AND”,弹出操作符对话框,选择操作符(这里选择的是OR),如图25所示:


图24 增加过滤条件 图25 选择操作符
单击“增加条件”图中的“null = [ ]”,添加过滤字段,如图26所示;单击左边“
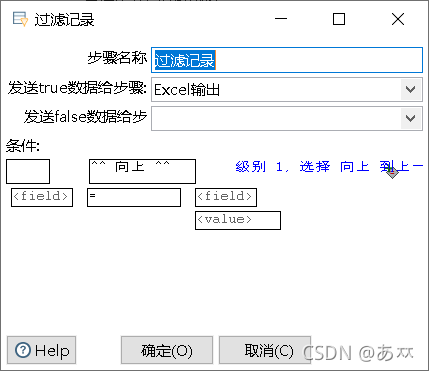
图26 添加过滤字段

图27 选择要过滤的字段Pay

图28 函数对话框

图29 字段Pay的过滤设置
单击“字段Pay的过滤设置”图中的符号“+”增加过滤条件;单击“AND”,弹出操作符对话框,选择操作符(这里选择OR),如图30所示;单击“增加条件”图中的“null = [ ]”,添加过滤字段;单击左边“
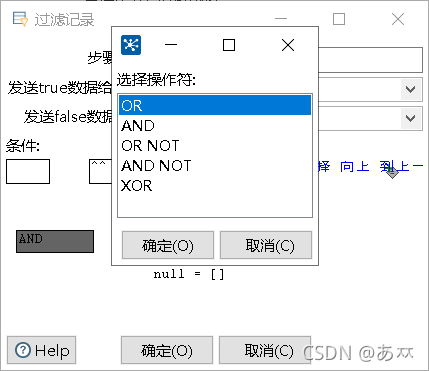
图30 选择操作符

图31 选择要过滤的字段Area
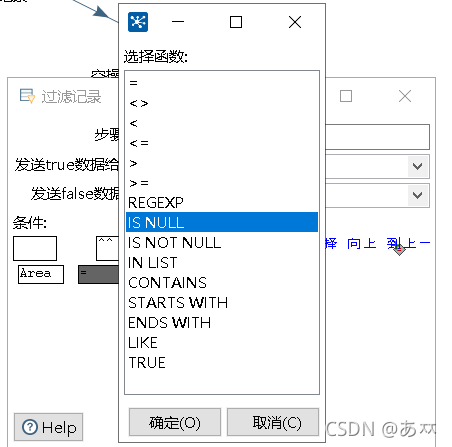
图32 选择过滤条件
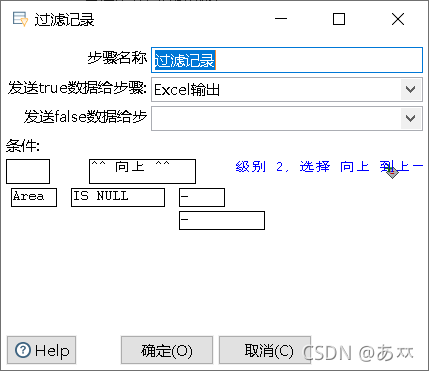
图33 字段Area的过滤设置

图34 设置的过滤条件
在“发送true数据给步骤:”处的下拉框中选择“空操作”,将包含缺失值的行数据放在空操作控件中;在“发送false数据给步骤:”处的下拉框中选择“Excel输出”,将没有缺失值的行数据输出到Excel文件中,如图35所示:

图35 发送true/false数据给相关步骤的配置
5.配置Excel输出控件
双击“Excel输出”控件,进入“Excel输出”配置界面,单击“浏览”按钮,选择要输出的文件路径,如图36所示:

图36 选择要输出的文件路径
6.运行转换delete_missing_value
单击转换工作区顶部的![]() 按钮,运行创建的delete_missing_value转换,如图37所示:
按钮,运行创建的delete_missing_value转换,如图37所示:

图37 运行转换delete_missing_value
7.查看文件file.xls
查看“Excel输出”控件输出的文件file.xls是否还含有缺失值数据,文件file.xls的内容如图38所示:

图38 查看文件file.xls
5.2.3 填充缺失值
数据挖掘中,面对的通常都是大型的数据库,它的属性有几十个甚至几百个,因为其中某个属性值的缺失而放弃大量其他的属性值,这种删除是对信息的极大浪费,所以产生了插补缺失值的思想与方法。常用的填充缺失值方法有均值填充、热卡填充、回归填充和多重填充。
1.打开Kettle工具,创建转换
通过使用Kettle工具,创建一个转换fill_missing_value,并添加“文本文件输入”控件、“过滤记录”控件、“空操作(什么也不做)”控件、“替换NULL值”控件、“合并记录”控件、“字段选择”控件以及Hop跳连接线,如图39所示:

图39 创建转换fill_missing_value
2.配置文本文件输入控件
双击“文本文件输入”控件,进入“文本文件输入”配置界面,单击“浏览”按钮,选择要去除缺失值的文件people_survey.txt,如图40所示;单击“增加”按钮,将要去除缺失值的文件people_survey.txt添加到“文本文件输入”控件中,如图41所示:

图40 选择要填充缺失值的文件people_survey.txt

图41 添加people_survey.txt至“文本文件输入”控件中
单击“内容”选项卡;在清除分隔符处的默认分隔符“;”,单击“Insert TAB”按钮,在分隔符处插入一个制表符;取消勾选“头部”复选框,若不取消,在进行数据抽取操作时会排除文件第一行的数据,如图42所示:

图42 单击“内容”选项卡配置
单击“字段”选项卡;根据文件people_survey.txt文件的内容添加对应的字段名称,并指定数据类型,如图43所示:
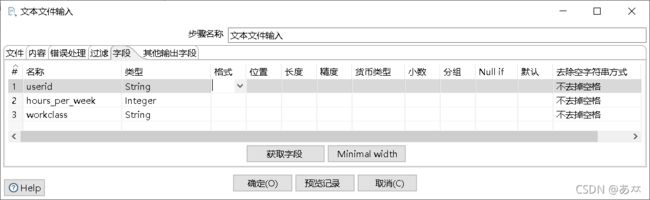
图43 添加字段
单击“预览记录”按钮,查看文件people_survey.txt的数据是否成功抽取到文本文件输入流中,如图44所示:
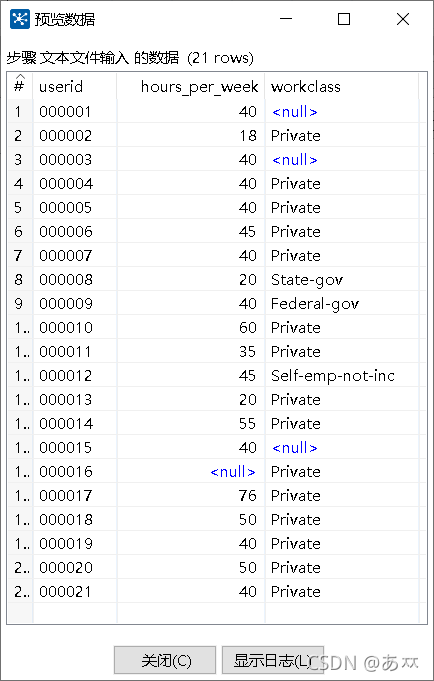
图44 预览数据
3.配置过滤记录控件
双击“过滤记录”控件,进入“过滤记录”配置界面,在“条件”处设置过滤的条件,由于从“预览数据”图中可以看出字段userid为000016用户的hours_per_week(即每周工作时间字段)存在缺失值,而它的workclass字段值为Private,因此我们可以将过滤字段设置为workclass、过滤值设置为Private作为过滤条件,如图45所示:

图45 设置过滤条件
在“发送true数据给步骤:”下拉框中选择“空操作”,将workclass字段值为Private的数据放在“空操作”控件中;在“发送false数据给步骤:”下拉框中选择“空操作(什么也不做)2”,将workclass字段值不为Private的数据放在“空操作(什么也不做)2”控件中,如图46所示:

图46 配置发送true/false数据给相关步骤
4.配置替换NULL值控件
双击“替换NULL值”控件,进入“替换NULL值”配置界面,勾选“选择字段”处的复选框,并在“字段”框添加字段为hours_per_week,值替换为44(44是字段为hours_per_week中所有值相加求的均值,这里指用44替换字段hours_per_week中的NULL值),如图47所示:
 图47 配置“替换NULL值”控件
图47 配置“替换NULL值”控件
5.配置合并记录控件
双击“合并记录”控件,进入“合并行(比较)”配置界面,在”旧数据源:”下拉框选择“替换NULL值”,“新数据源:”下拉框选择“空操作(什么也不做)2”;在“匹配的关键字:”部分,添加关键字段,即userid,如图48所示:
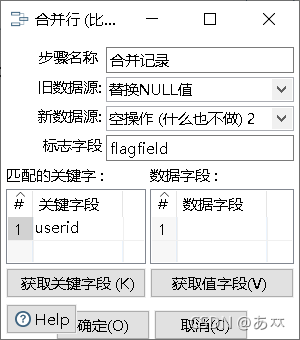
图48 配置“合并记录”控件
6.配置配置替换NULL2值控件
双击“替换NULL值2”控件,进入“替换NULL值”配置界面,勾选“选择字段”处的复选框,并在“字段”框添加字段为workclass,值替换为Private(这里用Private替换字段workclass中的NULL值),如图49所示:

图49 配置“配置替换NULL2“”值控件
7.配置字段选择控件
双击“字段选择”控件,进入“选择/改名值”配置界面,在“移除”选项卡处添加要移除的字段名称,这里移除的是字段flagfield,如图50所示:

图50 添加要移除的字段
8.运行转换fill_missing_value
单击转换工作区顶部的 ![]() 按钮,运行创建的fill_missing_value转换,如图51所示:
按钮,运行创建的fill_missing_value转换,如图51所示:

图51 运行转换fill_missing_value
9.查看文件people_survey.txt中的缺失值是否已填充
单击图39中的“字段选择”控件,再单击执行结果窗口的“Preview data”选项卡,查看是否填充了文件people_survey.txt中的缺失值,如图52所示:

图52 查看是否填充了文件people_survey.txt中的缺失值