Advances in Graph Neural Networks笔记2:Fundamental Graph Neural Networks
诸神缄默不语-个人CSDN博文目录
本书网址:https://link.springer.com/book/10.1007/978-3-031-16174-2
本文是本书第二章的学习笔记。
我们学校没买这书,但是谷歌学术给我推文献时给出了一个能免登录直接上的地址,下次就不一定好使了,所以我火速阅读原文并做笔记。
因此常识性内容我就略去不写了,可以看我以前写过的详细笔记。
阅读体验是,内容概括比较全面,但是写得很含混,就跟通用大学教材一样……可以略读一遍来作为引导,但是以本书为教材的指望大概难以实现。不如cs224w和浙大GNN课程。
GNN中最具有代表性的图卷积神经网络将卷积操作从网格(grid)数据泛化到图(graph)数据上,分成以图信号处理角度切入的谱域(spectral based)和以信息传播角度切入的空域(spatial based)。GCN是这两种图卷积网络之间的过渡方法,近期空域方法更火(因为有效且灵活)。
本章将先从谱域视角介绍GCN,再介绍空域的GCN变体(包括inductive框架GraphSAGE、用注意力机制聚合邻居的GAT、对异质图做semantic-level attention的HAN)
(本书参考文献部分的序号与正文不匹配,我也懒得一一去查了,所以就不写参考文献了)
文章目录
- 1. 谱域GCN
- 2. inductive GCN→GraphSAGE
- 3. GAT
- 4. HAN
- 5. GCN启发出的其他GNN
- 6. 其他推荐阅读材料
1. 谱域GCN
CNN在视觉任务中成功的原因之一:卷积层能分层级抽取图像高维特征,通过学习一组固定尺寸的可训练局部滤波器(fixed-size trainable localized filters)提升表现能力。
图数据非欧,从谱域视角,基于图傅里叶变换定义图卷积,可以通过两个傅里叶变换后的图信号的乘积的逆傅里叶变换来计算:
图谱域卷积的定义:图信号与滤波器(以 θ ∈ R N \theta\in\mathbb{R}^N θ∈RN 对参数角矩阵)在傅里叶域的乘积:

借助normalized graph Laplacian的特征向量来求解。可以通过切比雪夫多项式来简化:


GCN模型对谱域图卷积操作做出了简化:将切比雪夫多项式卷积操作减到一阶(K=1),并近似 λ m a x ≈ 2 \lambda_{max}≈2 λmax≈2:

继续进行简化:

得到泛化后的图卷积表达式:

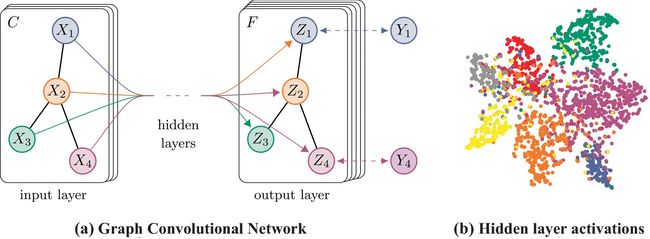
左图:半监督学习任务图解
右图:两层GCN在Cora数据集上用5%标签实现半监督任务学习,其隐藏层的t-SNE可视化。颜色表示文档类别
通过表达式实现学习任务:

2. inductive GCN→GraphSAGE
抽样、聚合新节点局部邻居特征,实现inductive节点表征。
可以mini-batch训练。
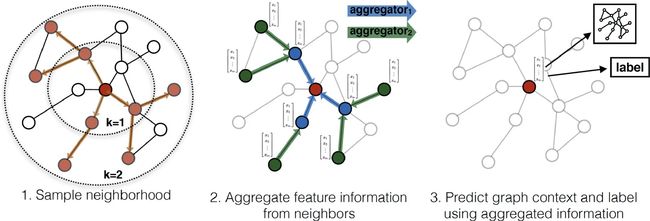

Neighborhood Sampler
GCN的输入:固定大小的整个图
GraphSAGE:对mini-batch中的每个节点选择固定数量的邻居
Neighborhood Aggregator
- Mean aggregator(近于GCN)
h v k ← σ ( W ⋅ MEAN ( { h v k − 1 } ⋃ { h u k − 1 , ∀ u ∈ N ( v ) } ) ) . \begin{aligned} \textbf{h}^k_v \leftarrow \sigma (\textbf{W} \cdot \textrm{MEAN}(\{\textbf{h}_v^{k-1}\} \bigcup \{\textbf{h}_u^{k-1},\forall u \in \mathcal {N}(v)\})). \end{aligned} hvk←σ(W⋅MEAN({hvk−1}⋃{huk−1,∀u∈N(v)})). - LSTM aggregator:将节点邻居随机打乱
- Pooling aggregator
A G G R E G A T E k p o o l = m a x ( { σ ( W p o o l h u k + b ) , ∀ u ∈ N ( v ) } ) . \begin{aligned} {\text {A}GGREGATE^{pool}_k} = {\text {m}ax}(\{\sigma (\textbf{W}_{pool} \textbf{h}_{u}^k + \textbf{b}), \forall u \in \mathcal {N}(v)\}). \end{aligned} AGGREGATEkpool=max({σ(Wpoolhuk+b),∀u∈N(v)}).
3. GAT
在GCN基础上添加attention机制,加权求和
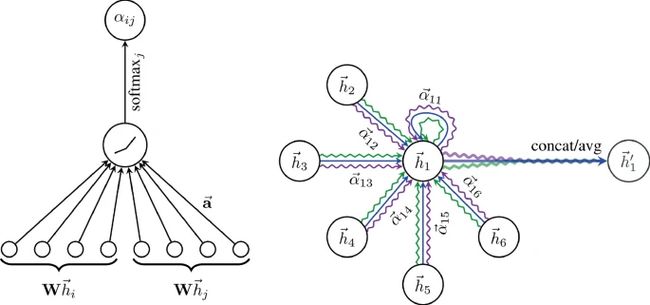
左图:注意力
右图:多头(3)注意力机制
attention机制总之就是在最终结果之上增加了一个权重计算机制,具体内容有时间和能力的话我再专门写个博客讲一下。
将节点对进行线性转换后,用单层前馈神经网络 a \mathbf{a} a得到标量attention coefficients(节点 j j j对节点 i i i的重要性):
e i j = attn ( W h i , W h j ) \begin{aligned} e_{ij} = \textrm{attn}(\textbf{W}\textbf{h}_i, \textbf{W}\textbf{h}_j)\end{aligned} eij=attn(Whi,Whj)
masked注意力机制 - 仅用邻居节点计算注意力:
α i j = softmax j ( e i j ) = exp ( e i j ) ∑ k ∈ N i exp ( e i k ) α i j = exp ( LeakyReLU ( a T [ W h i ∥ W h j ] ) ) ∑ k ∈ N i exp ( LeakyReLU ( a T [ W h i ∥ W h k ] ) ) \begin{aligned} &\alpha _{ij} = \textrm{softmax}_j(e_{ij}) = \frac{\textrm{exp}(e_{ij})}{\sum _{k \in \mathcal {N}_i} \textrm{exp}(e_{ik})}\\ &\alpha _{ij} = \frac{\textrm{exp}(\textrm{LeakyReLU}(\textbf{a}^T[\textbf{W}\textbf{h}_i \Vert \textbf{W}\textbf{h}_j]))}{\sum _{k \in \mathcal {N}_i} \textrm{exp}(\textrm{LeakyReLU}(\textbf{a}^T[\textbf{W}\textbf{h}_i \Vert \textbf{W}\textbf{h}_k]))} \end{aligned} αij=softmaxj(eij)=∑k∈Niexp(eik)exp(eij)αij=∑k∈Niexp(LeakyReLU(aT[Whi∥Whk]))exp(LeakyReLU(aT[Whi∥Whj]))
加权求和:
h i = σ ( ∑ j ∈ N i α i j W h j ) \begin{aligned} \textbf{h}_i = \sigma \left( \sum _{j \in \mathcal {N}_i} \alpha _{ij} \textbf{W} \textbf{h}_j\right) \end{aligned} hi=σ⎝⎛j∈Ni∑αijWhj⎠⎞
多头注意力机制:
h i = ∥ k = 1 K σ ( ∑ j ∈ N i α i j k W k h j ) \begin{aligned} \textbf{h}_i = {\Vert }_{k=1}^K \sigma \left( \sum _{j \in \mathcal {N}_i} \alpha ^k_{ij} \textbf{W}^k \textbf{h}_j\right) \end{aligned} hi=∥k=1Kσ⎝⎛j∈Ni∑αijkWkhj⎠⎞
最后一层:
h i = σ ( 1 K ∑ k = 1 K ∑ j ∈ N i α i j k W k h j ) \begin{aligned} \textbf{h}_i = \sigma \left( \frac{1}{K} \sum \limits _{k=1}^K \sum \limits _{j \in \mathcal {N}_i} \alpha ^k_{ij} \textbf{W}^k \textbf{h}_j\right) \end{aligned} hi=σ⎝⎛K1k=1∑Kj∈Ni∑αijkWkhj⎠⎞
attention可以提供更强的模型表示能力,一定的可解释性,而且可做inductive范式。
4. HAN
Heterogeneous graph Attention Network (HAN)
将GCN扩展到异质图上:官方的说法是通过学习node-level attention and semantic-level attention来学习节点和metapaths的重要性,其实就是先对每种metapath聚合所有邻居、然后再聚合所有metapath得到的表征(用了两种不同的注意力机制)、最终得到目标节点的表征。

meta-path
meta-path-based neighbors
先用node attention对每个metapath选择重要的meta-path-based neighbors,得到semantic-specific node embedding;再用semantic attention选择重要的metapath
Node-level Attention
先将各种节点映射到对应类型的隐空间,然后计算每个metapath下邻居的注意力机制,用多头注意力机制稳定训练过程:
h i ′ = M ϕ i ⋅ h i e i j Φ = a t t n o d e ( h i ′ , h j ′ ; Φ ) α i j Φ = s o f t m a x j ( e i j Φ ) = exp ( σ ( a Φ T ⋅ [ h i ′ ∥ h j ′ ] ) ) ∑ k ∈ N i Φ exp ( σ ( a Φ T ⋅ [ h i ′ ∥ h k ′ ] ) ) z i Φ = σ ( ∑ j ∈ N i Φ α i j Φ ⋅ h j ′ ) z i Φ = ∥ k = 1 K σ ( ∑ j ∈ N i Φ α i j Φ ⋅ h j ′ ) \begin{aligned} &\textbf{h}_i'= \textbf{M}_{\phi _i} \cdot \textbf{h}_i\\ &e_{ij}^{\Phi }=att_{node}( \textbf{h}_i', \textbf{h}_j';\Phi )\\ &\alpha _{ij}^{\Phi } =softmax_j(e_{ij}^{\Phi }) =\frac{\exp \bigl (\sigma (\textbf{a}^\textrm{T}_{\Phi } \cdot [\textbf{h}_i'\Vert \textbf{h}_j'])\bigl )}{\sum _{k\in \mathcal {N}_i^{\Phi }} \exp \bigl (\sigma (\textbf{a}^\textrm{T}_{\Phi } \cdot [\textbf{h}_i'\Vert \textbf{h}_k'])\bigr )}\\ &\textbf{z}^{\Phi }_i=\sigma \biggl ( \sum _{j \in \mathcal {N}_i^{\Phi }} \alpha _{ij}^{\Phi } \cdot \textbf{h}_j' \biggr )\\ &\textbf{z}^{\Phi }_i= \overset{K}{\underset{k=1}{\Vert }} \sigma \biggl ( \sum _{j \in \mathcal {N}_i^{\Phi }} \alpha _{ij}^{\Phi } \cdot \textbf{h}_j' \biggr ) \end{aligned} hi′=Mϕi⋅hieijΦ=attnode(hi′,hj′;Φ)αijΦ=softmaxj(eijΦ)=∑k∈NiΦexp(σ(aΦT⋅[hi′∥hk′]))exp(σ(aΦT⋅[hi′∥hj′]))ziΦ=σ(j∈NiΦ∑αijΦ⋅hj′)ziΦ=k=1∥Kσ(j∈NiΦ∑αijΦ⋅hj′)
Semantic-level Aggregation
直接对每个metapath的所有节点上的表征通过MLP后,tanh激活、线性转换、加总、归一化(除以节点数),然后对所有这些结果做softmax归一化。
w Φ = 1 ∣ V ∣ ∑ v ∈ V q T ⋅ t a n h ( W ⋅ z v Φ + b ) , \begin{aligned} w^{\Phi } = \frac{1}{|\mathcal {V}|} \sum _{v \in \mathcal {V}} \textbf{q}^T \cdot tanh(\textbf{W}\cdot \textbf{z}^{\Phi }_{v}+\textbf{b}), \end{aligned} wΦ=∣V∣1v∈V∑qT⋅tanh(W⋅zvΦ+b),
用得到的权重计算最终的节点表征:
z v = ∑ Φ ∈ { Φ 1 , … , Φ P } β Φ ⋅ z v Φ . \begin{aligned} \textbf{z}_v = \sum _{\Phi \in \{ \Phi _1,\ldots ,\Phi _P\}} \beta ^{\Phi } \cdot \textbf{z}^{\Phi }_v. \end{aligned} zv=Φ∈{Φ1,…,ΦP}∑βΦ⋅zvΦ.
5. GCN启发出的其他GNN
recurrent graph neural networks
graph autoencoders
6. 其他推荐阅读材料
直接建议左转我的其他博文。
- 《Advances in Graph Neural Networks》第1~2章读书笔记:这个里面还写了我没法看的第一章的相关内容。yysy,我觉得这篇写得比本书要好点,但都有一个很严重的问题,就是过于简略,就像论文里的preliminary,说了个寂寞,懂的人不用看,不懂的人看不懂。