深度学习03-keras实例介绍iris数据集+sklearn对比+模型结果分析
数据准备
导入数据
from sklearn import datasets
iris = datasets.load_iris()
type(iris)
iris.data#四个自变量
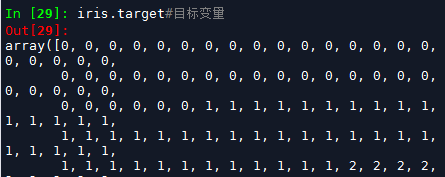
iris.target#目标变量

对变量进行标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
irisZX = StandardScaler().fit_transform(iris.data)

使用sklearn拟合
#MLPClassifier默认为shuffle=True 因此不需要事先打乱数据的顺序
from sklearn.neural_network import MLPClassifier
clf = MLPClassifier(activation = 'logistic',hidden_layer_sizes = (5),
solver = 'lbfgs',random_state = 1)
clf.fit(irisZX,iris.target)
clf.score(irisZX,iris.target)
拟合的score分数为0.9933
keras方法
数据转换
keras需要将因变量转换为哑变量
#将因变量转换为哑变量
from keras.utils import to_categorical
y = to_categorical(iris.target)
y[:5]

模型准备
直接上代码,先导入需要的包,然后建立模型,这里是顺序模型然后用add添加层的方法。第一层输入的尺寸为4(包含四个自变量),输出层为5,激活函数为sigmoid。第二层也就是输出层,每个样本需要输出三个值,激活函数为softmax,保证输出结果的取值在[0,1]之间。
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(5,input_dim = 4,activation = 'sigmoid'))
model.add(Dense(3,activation = 'softmax'))#softmax保证输出结果为[0,1]
model.compile(loss = 'categorical_crossentropy',
optimizer = 'rmsprop',
metrics = ['accuracy'])
可以看一下模型描述

模型拟合及预测
下面直接添加fit拟合模型,可根据需要是否显示日志
model.fit(irisZX,y,epochs = 50)
model.fit(irisZX,y,epochs = 50,verbose = 0)
model.fit(irisZX,y,epochs = 50,verbose = 2)

看一下模型效果:结果【测试集损失函数,预测准确率】

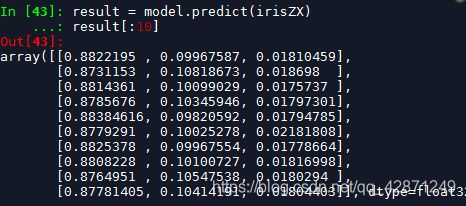
模型预测:直接用predict函数
模型结构的可视化
history将模型的accuracy和loss存贮起来
hist = model.fit(irisZX,y,epochs = 50)
hist.history
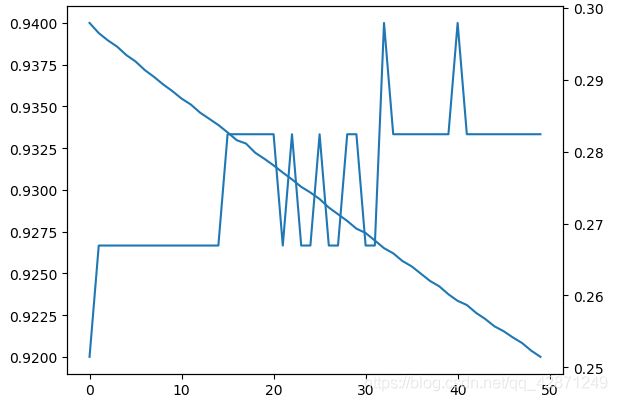
plt.plot(hist.history['accuracy'])
plt.plot(hist.history['loss'])
#画一起
plt.plot(hist.history['accuracy'])
ax2 = plt.gca().twinx()#使用第二Y轴
plt.plot(hist.history['loss'])
及时终止训练
当达到一定的要求时,可以让模型及时终止训练。使用EarlyStopping 函数

from keras.callbacks import EarlyStopping
stop = EarlyStopping(monitor = 'val_loss',min_delta = 0.1)
model.fit(irisZX,y,epochs = 500,
validation_data = (irisZX,y),
callbacks = [stop])