语义分割学习总结(二)—— Unet网络
目录
一、网络结构
(一)左半部分(特征提取部分)
(二)右半部分(特征融合部分)
(三)代码实现
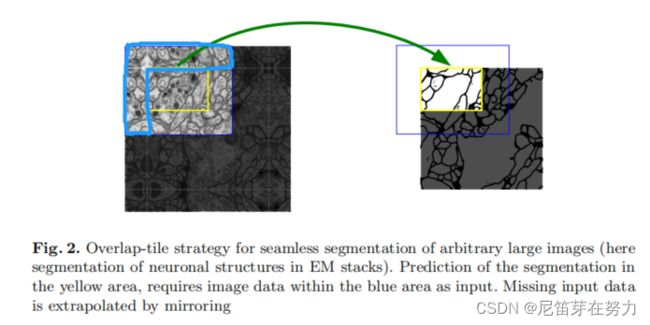
(二)重叠平铺策略
(三)加权损失
(四)随机弹性形变
一、网络结构
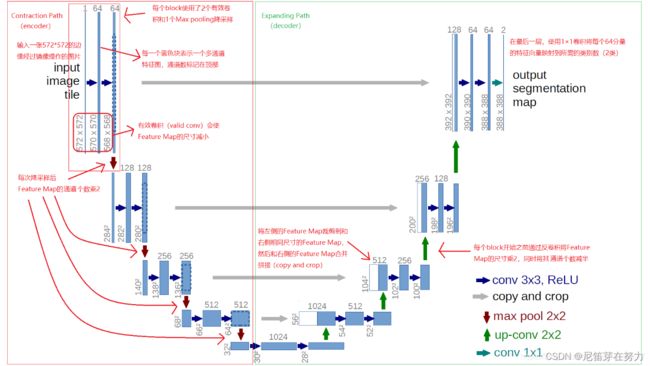
(图源来自网络)
这个结构的思想其实就是先对图像进行卷积+池化,进行特征提取,也就是U型的左半部分,然后对图像拼接+上采样,进行特征融合。
(一)左半部分(特征提取部分)
两个3x3的卷积层(ReLU)+ 一个2x2的maxpooling层构成一个下采样的模块,由下采样模块反复组成。每经过一次下采样,通道数翻倍。论文中用的是valid卷积(当filter全部在image里面的时候才开始进行卷积运算),因此每做一次valid卷积,由于没有padding,feature map的height和width会分别减少3-1=2个像素。
(二)右半部分(特征融合部分)
一个2x2的上采样卷积层(ReLU)+Concatenation(先crop对应左半部分输出的feature map然后与右半部分上采样结果相加)+2个3x3的卷积层(ReLU)反复构成,最后一层通过一个1x1卷积将通道数变成期望的类别数(论文中的channel2分别为前景和背景的mask,医学中就是细胞区域和黑色背景区域)。每一次上采样转置卷积之后,height和width都加倍,同时channel减半,用于和左侧的浅层feature map进行合并拼接。Unet相比更早提出的FCN网络,使用通道拼接来作为特征图的融合方式。主要好处是,浅层卷积关注纹理特征,深层网络关注更深更本质的特征,将浅层网络提取的特征和深层网络提取的特征融合可以使得特征“厚且广”,还有一个原因我认为是下采样操作会导致高频信息丢失,从而导致边缘的特征丢失,而上采样虽然能够获得更大的特征图,但是并不能对进行过下采样的特征图进行恢复,因此是缺少信息的,通过这种特征拼接多少可以找回一些丢失的边缘信息。
(三)代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class double_conv2d_bn(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=3,strides=1,padding=1):
super(double_conv2d_bn,self).__init__()
self.conv1 = nn.Conv2d(in_channels,out_channels,kernel_size=kernel_size,
stride = strides,padding = padding ,bias =True)
self.conv2 = nn.Conv2d(out_channels,out_channels,kernel_size = kernel_size,
stride = strides,padding = padding, bias = True)
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self,x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
return out
class deconv2d_bn(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=2,strides=2):
super(deconv2d_bn,self).__init__()
self.conv1 = nn.ConvTranspose2d(in_channels,out_channels,
kernel_size= kernel_size,
stride = strides,bias = True)
self.bn1 = nn.BatchNorm2d(out_channels)
def forward(self,x):
out = F.relu(self.bn1(self.conv1(x)))
return out
class Unet(nn.Module):
def __init__(self):
super(Unet,self).__init__()
self.layer1_conv = double_conv2d_bn(1,8)
self.layer2_conv = double_conv2d_bn(8,16)
self.layer3_conv = double_conv2d_bn(16,32)
self.layer4_conv = double_conv2d_bn(32,64)
self.layer5_conv = double_conv2d_bn(64,128)
self.layer6_conv = double_conv2d_bn(128,64)
self.layer7_conv = double_conv2d_bn(64,32)
self.layer8_conv = double_conv2d_bn(32,16)
self.layer9_conv = double_conv2d_bn(16,8)
self.layer10_conv = nn.Conv2d(8,1,kernel_size=3,
stride = 1,padding =1,bias = True)
self.deconv1 = deconv2d_bn(128,64)
self.deconv2 = deconv2d_bn(64,32)
self.deconv3 = deconv2d_bn(32,16)
self.deconv4 = deconv2d_bn(16,8)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
#print(x.shape) [10, 1, 224, 224]
conv1 = self.layer1_conv(x)
print(conv1.shape)
pool1 = F.max_pool2d(conv1,2)
conv2 = self.layer2_conv(pool1)
pool2 = F.max_pool2d(conv2,2)
conv3 = self.layer3_conv(pool2)
pool3 = F.max_pool2d(conv3,2)
conv4 = self.layer4_conv(pool3)
pool4 = F.max_pool2d(conv4,2)
conv5 = self.layer5_conv(pool4)
#print(conv5.shape) ([10, 128, 14, 14])
convt1 = self.deconv1(conv5)
concat1 = torch.cat([convt1,conv4],dim=1)
conv6 = self.layer6_conv(concat1)
convt2 = self.deconv2(conv6)
concat2 = torch.cat([convt2,conv3],dim=1)
conv7 = self.layer7_conv(concat2)
convt3 = self.deconv3(conv7)
concat3 = torch.cat([convt3,conv2],dim=1)
conv8 = self.layer8_conv(concat3)
convt4 = self.deconv4(conv8)
concat4 = torch.cat([convt4,conv1],dim=1)
conv9 = self.layer9_conv(concat4)
outp = self.layer10_conv(conv9)
outp = self.sigmoid(outp)
return outp
model = Unet()
inp = torch.rand(10,1,224,224)
outp = model(inp)(二)重叠平铺策略
该策略的思想是:对图像的某一块像素点(黄框内)进行预测时,需要该图像块周围的像素点(细蓝色框内)提供上下文信息,以获得更准确的预测。但是图像边界的图像块(黄色框内)没有周围像素,因此作者对周围像素采用了镜像扩充(比如粗蓝色框内的图像可以看出来是经过白线镜像对称得到的)。这样,边界图像块也能得到准确的预测。
(三)加权损失
该策略的思想是:为了更好的实现边界分割,对于细胞边缘的分割像素点加大了损失权重,使得网络更加重视边缘像素的学习。损失函数采用交叉熵损失函数的加权:
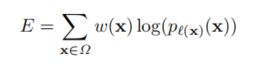
其中权重:
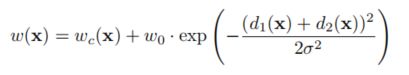
softmax:
![]()
(四)随机弹性形变
该策略的思想是:实际上是一种数据增强方式。数据增强能够有效的提高网络的不变性和稳定性,由于医学数据通常是非常少的,因此数据增强就变得异常重要。而对于显微图像主要需要位移和旋转不变性以及对变形和灰度值变化的鲁棒性,于是文中使用了随机弹性形变。
———————————————————————————————————————————
【参考】:
如何理解u_net中的overlap_tile策略? - 知乎
图像分割必备知识点 | Unet详解 理论+ 代码 - 知乎
数据增强:弹性变形(Elastic Distortion) - 知乎
以上就是全部啦,如有疑问和错误欢迎私信~